Is anyone else thinking, what the f*ck? Are we in a new era of computing? It certainly feels that way when looking at these desktop class ARM chips, where performance doubled every year or so, just like back in the 80s and 90s.
Normally this wouldn't feel so ground breaking, but the stars are in alignment and all these improvements are hitting at the same time. We're seeing years of work and investment paying off (AMD, Apple, ARM, Nvidia, Amazon), new process nodes (TSMC), and new tech (Ray Tracing, DLSS, machine learning) all hitting at the same time.
And that's the big stuff! There's also the steady incremental improvements such as battery technology, SSD and RAM that are ongoing.
You also have an incumbent (Intel) who's lost their way. If they were as scrappy as they were 15 years ago this wouldn't feel like such a banner year.
Not to forget that apparently some of the people driving that scrappy team that had a big part in Intel's resurgence has been working on the M1.
This actually reminded me of how I got skeptical comments from people when I told them that my small and scrappy Pentium-M (P-M -> M1, HAH!) based laptop was almost as fast as their desktop P4 monsters in compiling code.
The P4 (and Netburst in general) was a true low-point for Intel. Intel is struggling with fab issues right now, but things were really bad from about '02 to '06, with the P4 not completely going away until '08.
I remember people using socket adapters to put Pentium M chips on their desktop. I also have very bad memories of my P4 Prescott around the same era. What an absolute trash pile of an architecture.
It wasn't actually that bad... Everyone likes to remember it as this massively power hungry beast with terrible performance. It was power hungry compared to what came later, but it did also provide some pretty good performance at the time - especially if you were the kind of tweaky nutter who liked to overclock.
Northwood was a relative bargain when you cranked the bus clocks up well beyond what it said on the box.
I'm not someone into the inner-working of chips much, but is "ray tracing" a new term used for something in microprocessors now? Or is this the same graphic "ray tracing" we were doing back in the 80's on Amigas and Atari STs?
We're crossing the threshold this year where real-time ray tracing in hardware isn't just some theoretical concept, it's actually useful and available in affordable consumer hardware (NVIDIA and AMD GPUs, as well as the PS5 and new Xbox all have it).
Yes, the NVIDIA 2xxx RTX series had it two years ago, but this is the year where it's actually viable and not so gimmicky.
It's also shipping in consoles this generation, which is going to drive a lot more games to actually implement it. When it's only being used by 5% of the PC userbase, maybe you don't bother doing that work. If cheaper GPUs can push that up to say 20% of PCs next year, you still might not.
But when every PS5 and XSX has raytracing hardware, suddenly it makes sense. That's going to be helpful for getting it supported in PC titles sooner.
We've been able to do realtime ray tracing in software since forever though and the shadertoys and whatnot have been full of hardware accelerated demos, that's not so interesting.
I remember playing with a number of demos on my intel core 2 duo macbook (not pro) a decade ago.
They weren't doing that in hardware real time accelerated at 4k resolution in AAA games. This year they are. That's a big leap from your core 2 duo demos.
The new GPUs have hardware specifically designed to do the type of math that raytracing does, such as ray/volume intersections, faster or more efficiently than generic shader hardware. Sufficient quantity (FLOPS) can become a quality of its own.
Realtime ray-tracing is a mix of hardware acceleration for ray intersections and de-noising. The de-noising approaches are certainly novel and not really analogous to previous methods, imho, though the accelerated bounding box hierarchies for accelerating intersections certainly appear in previous iterations.
I think this is the key answer, de-noising, using various neural techniques finally allowed acceptable images to be produced from sometimes <1 ray / pixel, where normally images produced at such densities were nearly unusable.
This is still not perfect and many ray tracing techniques rely on accumulation over time which limits certain images from working (I imagine raytracing a small particle cloud, or fast shifting objects to be a worst case scenarios)
It's the same graphical ray tracing, although with many modern improvements like path tracing for randomization of the ray bounces to efficiently approximate and converge on the correct lighting, and ML-powered denoising and upscaling algorithms that take low-resolution fast rendering and transform it to higher quality and detail.
Yeah. When I'm guessing how long something will last, I guess it's about halfway through its life unless I have really good information to the contrary. Intel was founded in 1968, so let's say it will shut down in 2072 (give or take...many...years). And Fortune 500 companies don't seem to totally shrink back to startup head count and revenue even when they go bankrupt—they might have significant revenue but even more expenses. So it seems pretty reasonable to guess Intel will be around with (at least) $20B of revenue in 2060, in spite of their rough patch today.
>>So in 2060 it will still be a huge company with $20B in revenue?
That's great for shareholders.
Meanwhile, keep in mind that IBM exited the consumer computing device market. If that's also in store for Intel then it's a bit pointless in the PoV of those in the market for consumer computing devices.
Note that the comparison is also compiling to ARM vs compiling to Intel, so its partly to do with the simplicity of the compilation process between the two architectures.
I'm also curious to learn where was the bottleneck in both tests.
I've read stuff about how the M1-packing MacBook Air shipped with a SSD whose burst write speed was far higher than the one shipped in older MacBooks. The bottleneck on build jobs tends to lie on disk access, specially with projects comprised of a significant number of small files whose build also outputs a bunch of small files.
This is one of the reasons behind doing builds on RAM drives.
If that's the case then these weird speedups might not be due to magic properties on Apple's M1 professor but due to the fact that the processor doesn't idle as much while waiting for all those reads and writes to finish.
Sequential performance is only one facet of overall SSD performance. Some older Apple SSDs weren't the greatest at random reads and writes - it's possible these new ones are quite a bit faster in that department, FWIW.
So though it's a new age in some ways, I don't think it will benefit many people. It will just increase the churn. Witnessing all the cries of "16GB of RAM isn't enough!" makes it quite apparent that software behaves like a gas rather than a liquid, and will expand to consume whatever hardware is available to developers.
I think that for consumer products, which these are targeting, software responsiveness, usability, and battery lifetime are by far the most important metrics.
These chips help with battery, and can hell with software responsiveness if there's is developer focus on it.
But what will probably happen is that development teams will buy the fastest computers they can, and then develop software that is mostly, somewhat adequately performing on this beefy hardware, then ship it to customers that are on weaker hardware.
This effect is especially pronounced for web software, where it's easier to make unresponsive interactions due to so many layers of software, especially with developer network connections usually being 10x-100x less latency than users.
The 8GB Macbook Air at $899 educational is faster, and will feel faster, than any laptop that anyone has owned or thought of owning at that price point.
Millions of buyers who need laptops for *-at-home activities will sing its performance praises on Sheets and Salesforce.
The "I need 16GB crowd" of content creators need more RAM and GPU but they are a tiny fraction of the market for laptops.
I guess my point is that any such gains are temporary and will soon disappear with the next release of software, or with the next website redesign.
MS Office apps, for example, are horrifically unresponsive on Macs. Switching the ribbon to a new view has 700-1000ms of lag on my 2.4 GHz i5. Maybe an M1 brings it to 350ms. Once MS developers start developing on an M1 laptop, the developers will change code, and it will slow down, and until it gets slower than it currently is, the code will not be optimized.
This is what I mean about software being like a gas rather than a liquid. Any new CPU performance will be consumed by developers because their threshold for performance optimization changes with each new performance improvement.
I run MS Office local apps on my 2018 MBP 15" 6-core. They are slow. I agree the M1 will never make them feel better. Neither will the M2 or M3. They will always be slow.
If they were ever going to be fast, they would already be fast. They are a software problem unto their own.
Searching on the Costco website has a 2-3 second delay between each entry for me.
I think there are two routes to making software faster for users: 1) intense education of developers and rewarding them properly for keeping software responsive, and 2) only letting them develop on 5-10 year old hardware. I'm not really sure 1) would work with many teams, but I'm pretty sure 2) would.
MS Office apps have always been (possibly intentionally?) horrifically bad on Mac. Not a great benchmark IMO.
The average Joe user just uses a browser and something like Spotify. Even most word processing by college students is in Google Docs now - very few people I knew bought MS Office for their Macs when I was in college 5 years ago, even with a $99 student license through the school.
It's a perfect benchmark because even 20 years later performance is only getting worse, rather than better.
Developers will use all available resources until their is pressure to be more efficient. This is not a critique of developers, this is the nature of software. Unless critical development time is spent making sure that software is responsive, it will only ever have barely acceptable performance.
Which is why new, faster CPUs have very little effect on users. Any performance gains will be gobbled up by new software frameworks that promise better use of developer time, but which may come at an absolutely tremendous cost of UI responsiveness.
Spotify, Slack, Office on Mac, hyper complex JavaScript web frameworks... all will continue to take more and more CPU cycles that are available.
Definitely agree with you. The current software were developed for a 2x slower spec, and tested, tuned against a 2x slower spec, the speed gain will disappear once the development platform changes to M1, however, there will be more functionality, more animation in interface, as it has happened in past years.
The CPU gains on ARM have been increasing consistently year over year for the past decade. People have posted benchmarks of the A11/ A12/ A13 versus Intel for a while so this has been pretty obvious. It's just surfacing because suddenly we have a desktop CPU with desktop software like compilers and other things where it's more obvious outside of benchmark tools.
Apple is just jumping onto their existing ARM track, once they migrate their product line, which has surpassed Intel. Once they've migrated all their lines to ARM, the performance gains will be more like they have been on the iPhone/ iPad over the past few years. Mostly 20-30%/ year.
IMO, this has little to do with it being ARM. 30 years ago ARM had a significant micro architectural advantage in performance per watt, but in this era of 10 billion transistor chips, that advantage has disappeared. x86_64 rationalized the x86 architecture and decode is such a small fraction of the power budget that it really doesn't matter anyways.
I'm no expert, but the only big architectural differences are a massively larger decoder and a reorder buffer that's several times as large as x86 designs.
If these are actually the reasons for the performance difference, and it's difficult to do these on x86 because of the instruction set, it seems to this amateur that ARM64 really does have an advantage over x86.
Does it? Apple's documentation seems to disagree [1]:
"A weak memory ordering model, like the one in Apple silicon, gives the processor more flexibility to reorder memory instructions and improve performance, but doesn’t add implicit memory barriers."
It's switchable at runtime. Apple silicon can enable total store ordering on a per-thread basis while emulating x86_64, then turn it back off for maximum performance in native code.
Couldn't Intel just come out with a new set of reduced-complexity instructions that run on a per-process basis based on some bit being flipped on context switches? Then legacy apps would run fine, but the new stuff would work too. This seems not that hard to address.
As I understand it, the challenge to making wider x86 chips is the mere existence of some instructions. Adding new instructions can't help with that. But I'm just repeating what I heard elsewhere:
> Other contemporary designs such as AMD’s Zen(1 through 3) and Intel’s µarch’s, x86 CPUs today still only feature a 4-wide decoder designs (Intel is 1+4) that is seemingly limited from going wider at this point in time due to the ISA’s inherent variable instruction length nature, making designing decoders that are able to deal with aspect of the architecture more difficult compared to the ARM ISA’s fixed-length instructions.
I find that odd. Don’t they have some sort of icache? Intel could decode into a fixed width Alternative instruction set inside the icache, then use a wider decode when actually executing.
Yes, they have a cache for decoded operations. It'll hold a certain number but it's sort of inefficient because the fixed width decoded instructions are a lot larger than the variable length instructions so it doesn't hold too many. Because it doesn't help on code with large footprints and not too much time in inner loops you don't necessarily want the number of ops you can get form it to be too much more than the width of the rest of the system if you want a balanced design.
The ISA differences between ARM and x86 do not account for the difference in performance, there are multiple factors here (process, ssd, memory bandwidth, cache, thermal reservoir, etc).
While this is wonderful for ARM in the now-term, we just moved from walled ISAs to a plurality of ISAs, compute just became a bulk commodity in a way that it could not with an x86 duopoly.
Anyone can now take off the shelf RISC-V designs that are currently at > 7.1 coremarks/mhz and get them fabbed on Glofo or TSMC. If you need integrator help, you can use the design services of SiFive.
There’s not a shred of evidence RISC-V can approach the levels of performance discussed in this thread. There’s a lot of “big implementations can potentially do X” hand waving in RISC-V land, and not much real silicon to show for it.
Chalking it down to ARM doesn’t cut it... other companies make ARM chips too, including Qualcomm. Most Android phones run ARM, and given they outnumber iPhones heavily you’d expect massive improvements. But this is better than putting Qualcomm’s best chip into the Mac.
Qualcomm seems to be stagnating just like Intel at the moment, it will be a few years until high performance ARM chips come to non-Apple devices, unless Microsoft can strong arm them for their Surface line
I'm guessing the high performance ARM chips for non-Apple devices will be coming from Nvidia or Samsung in the future
Yes, ARM is one piece of many. (Commented about this above)
Though I suspect if Qualcomm were able to source a TSMC 5nm chip, it would be more competitive with Apple than Intel is at this point though. Apple has a lot of other things going for it where Qualcomm lags (the Secure Enclave, graphics performance, audio and photo processing, the neural engine etc etc)
Debatable. Qualcomm operates under a strict transistor budget because their chips lack a dedicated customer willing to pay what it costs to develop an ultra-wide CPU like this. Apple knows they're going to sell 100+ million of whatever core they make so they're able to more easily amortize and justify the costs of development.
Intel gets no such benefit of the doubt. I have no idea what on earth is going on over there.
What I was trying to get at is that the ARM designs plus the TSMC fabs are a big part of Apple's success here. The pieces are out there where someone else could put together an ARM based package that's more competitive with Apple. In retrospect, maybe it's more likely to see something like this from Nvidia than Qualcomm.
Even then, it's hard to say how competitive that CPU would be. Just based on Microsoft's Surface with it's half-assed Qualcomm CPU, it seems feasible though.
I think another shock here is that a lot of people discredited the ability of ARM cpus as well.
Back when the iPad Pro with the A10X came out, Apple claimed it was faster than half of all Laptops sold and people in the PC space were yamming on and on about how numbers don't show how much better x86 cpus are at 'desktop stuff' and that ARM cpus can't equal x86, even with the same thermal envelope and shouldn't ever be compared.
Ironically, many are now stating that the reason why they are so good is because of ARM, which isn't true either lol.
>people in the PC space were yamming on and on about how numbers don't show how much better x86 cpus are at 'desktop stuff' and that ARM cpus can't equal x86, even with the same thermal envelope and shouldn't ever be compared.
It needs 30W at 4 cores 3.2Ghz. Ryzen needs around 5W per core but it's on a worse process. The entire system does use less power than a x86 system but that has nothing to do with the processor. It's more about how the SoC is arranged and that RAM is (almost) on the same package. It means they can get away with higher bandwidth and lower power consumption for the entire system.
The idea that it's all about the processor is completely wrong. Yet all we have heard is how fanboys cry it's going to be 3x faster than desktop CPUs because of misleading TDP numbers.
As far as we know, all four large cores at max plus the 4 small is ~20W. Whole chip max power use is 30W including GPU and the ML processor. Ryzen also blows a lot of power on things other than cores but AMD is absolutely the closest to this however. The hard thing for them is that the Big/Little arch is a huge advantage for battery use at idle. I would say the game being played here is that Apple is betting on this to scale all the way up for fast burst but they know that the real advantage is that their cores can also scale much much lower than anything out there. Less about magical performance gains and more about remarkable power use paired with much better power management lessons learned by making smartphones. Qualcomm could do this too if they actually cared about it.
I'll be more interested if the M1 can compile something 2x quicker than the i9 when the compile time on the M1 exceeds 30-60 minutes rather than being less than a minute.
EDIT: to be clear, I expect the M1 to feel faster than the i9 for the vast majority of users, however the headline is "in a real world Rust compile", implying that this is a more valid test than synthetic benchmarks. I take issue with that, as I don't really consider something that compiles in less than 2 minutes on 6 year old hardware to be a much more useful test than the benchmarks.
We already know the A-series of chips performs incredibly in short workloads. We have no information yet on how it performs under sustained workloads.
>> We already know the A-series of chips performs incredibly in short workloads. We have no information yet on how it performs under sustained workloads.
What makes you think that given sufficient cooling, it will not perform exactly the same as the M1 in the MBA but sustained? It’s not like the ARM architecture changes anything in the thermodynamics of cooling cpus compared to an x86 chip, right?
I’d wager that under load an i9 with passive cooling wouldn’t even last 30 seconds without throttling below even its base clock, if it doesn’t just shut down to prevent frying itself
It's in the same ballpark of power efficiency as AMD's x86 chips. It's slightly more efficient because of 7nm vs 5nm but if you scale it up to desktop frequencies it's going to consume the same amount of power as Ryzen CPUs.
Yes but the point is that Apple doesn't need to scale the M1 up to desktop frequencies, because it already is faster than x86 in single-threaded workloads, at lower clocks and significantly lower power. To scale up the multithreaded performance they just have to increase the core count and scale the cooling system accordingly, ie: exactly like you would have to for x86. A decent desktop cooler can dissipate enough heat to run CPU's with 100+ Watt TDP's, while the M1 in the current Mac Mini sits around ~20W estimated if you discount the RAM.
So again, what would make anyone think that an M1 with decent cooling would not be able to maintain the current ST performance indefintely, or a hypothetical 8+8 or even 16+16 core M1X or M2 with a TDP of 100W and top-notch cooling solution would be impossible?
Multicore scaling on M1 doesn't appear to be as efficient as that on Ryzen - for example, the 4200U is able to beat the M1 in multicore tasks at quite a similar power draw, but gets soundly beaten in single core. Ryzen's big advantage over previous multicore implementations was infinity fabric - so clearly there's more to scaling than just the actual compute cores.
Don't forget that scaling up is also not just about frequencies, there are also packaging considerations - the CPU dies have to actually be able to dissipate the heat generated, and the package itself has to be able to do so as well. I'd expect that this is something AMD and especially Intel have a leg up over Apple with - although, considering they've already tread that ground it makes Apple's job a bit easier too.
It's an Apple chip that will only ever be in Apple computers.
Asking about how it would do in a computer with sufficient cooling is about as relevant as asking how it would do in a computer with a usable keyboard or OS.
It's a shame we have a headline proudly announcing that the M1 is 2x faster, when the reality is it's about 8% faster when doing a similar real world test for longer.
What's also hugely impressive is that under better cooling conditions, it's also 25% faster.
None of these numbers capture headlines like 2x sadly, but that's still massively impressive.
I think this just shows how little improvement there has been over the last years. However, getting twice the performance with a fanless design looks interesting, even if there is throttling after a while. For what I do, I don't regularly wait for compiles that take ages, but having a silent computer without losing performance is a net win.
Curiosity got the best of me too and I ran the test on my late 2013 MBP, 2.3 GHz i7, 16 GB ram. Compilation took 44 seconds and the fans didn't even spin up (with 23 ºC ambient temperature).
A little further down the thread [0] he gives the actual numbers, which are around 20s on the M1, which puts the i7 [1] at around 40s.
I'm not sure how much of this is Rust specific, but for my own projects I haven't noticed a big difference between my mbp, an old i7-3930k and a newer i5-8500. The MBP is somewhat slower, but it only has 4 cores while the others have 6.
This is the Apple equivalent of a Tesla showing up and out competing much more expensive cars on the performance. It feels like a huge disruption and probably Apple’s chance to gain significant PC market share.
> the Apple equivalent of a Tesla showing up and out competing much more expensive cars on the performance
Which was Tesla's equivalent of Jobs walking on stage with the iPhone, itself an homage to his iMac G3 turnaround, in turn a recapitulation of his promotion of the Apple II.
I’m guessing the performance improvements derive from integrating the memory onto the same chip (instead of using external memory), not from ARM (although power savings come from ARM). So we will probably see a new era of laptop SoCs, but that also means coupling RAM with CPU (or maybe you can mix and match the on-chip RAM with external RAM?).
“One aspect we’ve never really had the opportunity to test is exactly how good Apple’s cores are in terms of memory bandwidth. Inside of the M1, the results are ground-breaking: A single Firestorm achieves memory reads up to around 58GB/s, with memory writes coming in at 33-36GB/s. Most importantly, memory copies land in at 60 to 62GB/s depending if you’re using scalar or vector instructions. The fact that a single Firestorm core can almost saturate the memory controllers is astounding and something we’ve never seen in a design before.”
The memory bandwidth you get on the M1 is around what you would expect from a dual channel desktop with good RAM. So basically twice as fast as competing laptops.
I'd make a bet on Intel not turning around without new leadership at least willing to fling a gravitationally-significant pile of money at TSMC in the short term and significantly improve their pipeline in the medium to long term. They're so far behind now they're basically betting on everyone else screwing up. It's not just their position, though, it's their rate of change... their chip releases aren't getting faster as fast as AMD's or ARM's are, not by a long way.
I thought this for a few seconds and then realized these sorts of benchmarks are lacking obvious controls (i.e. compiling for different architectures as noted by others).
If you want a more realistic sense of how the M1 performs relative to x86 peers in raw, equivalent workloads, there are some cinebench numbers appearing out there:
I am way more interested in non-accelerated, deeply out-of-order instruction processing capabilities if we are talking about a "new era of computing". Being able to compile to ARM faster than x86_64 and having super fast HW codecs for processing special unicorn byte streams are not very compelling arguments in this context.
Show me an ARM chip scaled up to the same power+price budget as an Epyc 7742, throw them both at a 24 hour SAP benchmark, and then I will start paying attention if the numbers get close.
People are celebrating a kickass electric bicycle doubling the range of all the existing ones, and you demand to be shown it scaled up to the same power+price budget as an open pit mining truck, hauling dirt in three shifts. It might or might not happen, but the electric bicycle is still impressive.
Well, it's more like people celebrating an electric scooter that has twice the range of the electric bike.
Not saying it isn't a novel form of transport or equally useful in most cases, but... we're comparing a very stripped-down SoC to systems that have vastly more complexity for several different reasons - not least the ability to support more modular CPU/memory/GPU configurations.
Rework the existing x86 cores that we have into similar configurations and we'll likely see pretty substantial efficiency gains there too.
Couldn't agree with you more. For the first time in who knows how long, I can confidently say that we made a leap into a new generation of computer power. It's a huge step up from the small marginal improvements we've been seeing over the past few years.
Who knows, they might continue to offer an Intel MBP for years to come, or even add Windows ARM support if it commands enough demand. The other manufacturers have no mote here.
Windows arm is not real windows. It's not a substitute. Apple might command it's developers like a herd, moving them to whatever fancy new thing they make but windows is much more fragmented with 20+ years of backwards compatibility and tons of unmaintained software that won't be magically ported.
Current Windows on ARM seems promising with its x86 emulation so far, but still has a lot of room for improvement. Combined with the Windows 10 S sandboxing old windows apps I can see Microsoft catching up again in a few years once we have more widely available high power ARM processors.
In IT though, I don't expect any changes over to ARM hardware for another decade. I know where I work we have plenty of legacy cruft which would probably run into some weird edge cases if emulated on ARM.
Qualcomm chips are not that far behind Apple's, and Microsoft has Windows on ARM ready for a while now. Those performance advantage won't be there for long.
I think the bigger question is what does this spell for x86-64?
Uh, unless there's some new Qualcomm chip I haven't heard of, the Qualcomm chips are all being utterly crushed by Apple's offerings in geek bench and specperf.
Guess we'll see (maybe) in December (Snapdragon 875 will be announced December 1st at Qualcomms Digital Summit) - or a bit later, but the 875, now also on 5nm, supposedly will be quite a bump. Leaked (supposed) benchmarks show 30%+ improvement, which would be A14 territory.
I also have my doubts, but would be great for the market. (New Exynos 2100 supposedly also being up there.)
Qualcomm chips don't have on-chip DRAM at the highest clock rate possible. If they did the same things Apple is doing in that way, the performance advantage of M1 shrinks. There's no real "magic" in the M1 or Apple, it's a reality distortion field that is hitting everyone right now. It's entirely possible to outperform the M1, there just hasn't been a need to do that until now - no major OS would have benefitted from an ARM on steroids before now so there wasn't even a need for it.
Where have you asked me more than once? Please point me to that. If so, then I'm sorry, but I don't remember being told anything like that before this comment.
It's pretty amazing to me that you consider that comment "mean". How do you ever interact with the world if such a benign comment is considered "mean"? I'm serious, I just can't understand how that comment is "mean". Please try to explain it, because it makes no sense to me. Is any criticism at all considered "mean" now? Can anyone point out flaws in someone else's comment or post without being called "mean"?
> I think the bigger question is what does this spell for x86-64?
Not much?
People are acting like M1 destroys x86, but as AnandTech showed in the recent benchmark, M1 is trading blows with Zen 3 in single thread performance while having much larger core and process advantage (5nm vs. 7nm) thus being actually more expensive to produce.
Plus I would like to remind people that there were points where PowerPC Macs were extremely impressive, and that didn't magically reorder the world because existing software and OS ecosystems mean a hell of a lot more than just straight performance.
The only Zen 3 chips are desktop class, so Apple’s first generation ultra book oriented processor is trading blows with the best line of desktop processors. That’s a pretty big deal!
My concern is not with performance but the seemingly energy consumption advantage. If Arm chips perform just as well (or as we've just seen, better) than x86 chips while sipping much less power, why would anyone want x86 on mobile devices?
Are there any workloads that requires or perform better with x86?
This is clear only when you compare against an obsolete Intel which is known to be throttling power hog.
The difference might be way smaller or non-existent once we see some comparisons with latest AMD offerings (especially when we have also CPUs with comparable process).
Yeah, Anandtech's dive revealed some interesting benchmark results - such as the Zen 2 4200U part being quite close in both performance and power consumption (a little higher) to the M1 in heavily multithreaded tasks, but getting stomped in both aspects in single-threaded ones.
The M1 isn't a tiny power-sipping mobile part - it sucks power down just like AMD's 15W TDP CPUs do. The efficiency gains Apple are getting here are likely to be the result of several factors, only one of which are the CPU cores themselves.
They could have used 5600X with virtually the same single core performance as well.
You also can't compare manufacturing cost and retail cost. But given AMD cores are both smaller and manufactured on older process, it's probably safe to assume AMD ones are cheaper to manufacture.
I was waiting for AMD Zen3 to build a new desktop. But now that these tests are out, I am very, very tempted to go with Apple again. The Mac Mini numbers look comparable enough and it will be cheaper than an equivalent Windows machine (never thought I'd see this timeline).
As they should be. Windows laptops have been embarrassingly stagnant for over a decade; they just copy Apple's innovations. This isn't an innovation that they will be able to release in their next product refresh. They're going to have to invest significant amounts of capital.
I don't know but the fact that Windows on ARM is completely locked down and only lets you install applications from the Microsoft Store made me abandon Windows as a platform for good.
Satya Nadella just tweeted about their new Pluton processor. I have a feeling it won't get the same hype as the M1 but they are clearly already trying to defend.
THIS.
I saw multiple headlines calling it a processor, which may be somewhat true but it's not a General purpose processor and certainly is not a CPU. Yes, Apple's T2 chip has an A8 in it, but they don't call it a processor.
I lot of people are having a hard time grasping or accepting.
“But this benchmark has these issues”, “but this is hardware accelerated, so it's not a fair comparison”, etc. I think when enough benchmarks and real world usage have been run, it will sink in.
What did people expect? They've been killing it with 5W fan-less chips for years. Have you seen how confident Apple is in those videos?
I love everything about the move to Apple Silicon with the exception of the decision to put memory on-die or in-package (not sure how it is configured). They call it 'Unified Memory'. It makes a lot of sense but I don't know if they are going to be able to pack enough memory in there.
A lot of folks are fixated on CPU performance lately (which is rad) but I think that there is a tendency to ignore memory. I have 32gb of RAM on my Macbook Pro and finally feel like it has enough. You can't get an M1 configuration right now larger than 16GB which is a table-stakes baseline dev requirement today.
One, this is repeating the iPhone vs Android comparisons. iPhones with 4GB RAM feel faster and get more work done than Androids running Qualcomm ARM with double that amount of RAM. The faster IO becomes the cheaper paging becomes, and macOS and iOS have a lot of work done to handle paging well.
Two, this is the entry level processor, made for the Air, which is what we get for students, non-technical family members and spare machines. Let’s see what the “pro” version of this is, the M1X or whatever. We already know this chip isn’t going to go as is into the 16 inch MacBook Pro, the iMac Pro or the Mac Pro. I’d like to see what comes in those boxes.
I get what you're saying, I'm also looking forward for the even higher performing machines with 12 or 16 core cpus (8 or 12 performance cores + the 4 efficiency cores?), 32gb ram option, 4 thunderbolt lanes, and more powerful gpus. Wondering exactly how far apple can push it, if this is what they can do in essentially a ~20TDP design.
On the other hand it's quite funny that the title of this article is "16-inch MBP with i9 2x slower than M1 MacBook Air in a real world Rust compile" and the comments are still saying "yeah but this is entry level not pro".
Apparently Pros are more concerned about slotting into the right market segment than getting their work done quickly :)
I may be wrong, but the ecosystem does not really change here right? I mean, memory management should be roughly the same between x86_64 and arm regarding the amount of ram used, so I guess 16gb of ram under old macbooks is the same as 16gb under the new ones
All else being equal, yes, but the memory is faster, closer to the chip, has less wiring to go through, and because of vertical integration they can pass by reference instead of copying values internally on the hardware. The last one is big - because all the parts of the SoC trust each other and work together they can share memory withing having to copy data over the bus. That coupled with superfast SSDs means that comparisons aren't Apples to oranges, excuse the pun.
16GB of memory on-die shared by all the components of an SoC is not the same as 16GB made available to separate system components, each of which will attempt to jealously manage their own copy of all data.
I'm not a hardware person, but I do software for a living. Your comment makes things much clearer.
You're saying that the effective difference in having the shared memory is that you get more data passed by reference and not by value at the lower levels?
If that's true, then you get extra throughput by only moving references around instead of shuffling whole blocks of data, and you also gain better resource usage by having the same chunks of allocated memory being shared rather than duplicated across components?
That’s how I understand it, yes. I’m not into hardware either, going by engineering side of the event. In the announcement, there some parts shot at the lab/studio, where the engineers explain the chip. Ignore the marketing people with their unlabelled graphs, the engineers explain it well.
But yes, they’re basically saying because this is “unified memory”, there’s no copying. No RAM copies between systems on the SoC, no copies between RAM and VRAM, etc. because the chips are working together, they put stuff on the RAM in formats they can all understand, and just work off that.
Going by the engineering explanations in the announcement video. See the segments shot in the “lab” set. They’re actually pretty proud of this and are explaining the optimisations quite candidly.
"Controlling the ecosystem" and "integration" and such are just wishful-thinking rationalizations. Chrome and Electron will use however much RAM they use; Apple can't magically reduce it. If you need 32GB you need 32GB.
My guess is that it's an ARM build of Electron - unless they've been working to bring the iOS version over? That would be a huge win.
Even if this is Electron, I suspect this still great news for anyone that needs Slack. The Rosetta 2 performance of Electron would likely be a dog and Slack is a very high profile app with a lot of visibility.
Yeah, that’s partly true. Applications that allocate 1000GB will need to get what they ask for. No getting around bad applications. The benefits are more in terms of lower level systems communicating by sharing memory instead of sharing memory by communicating, which is always faster and needs less memory, but needs full trust and integration.
> You can't get an M1 configuration right now larger than 16GB which is a table-stakes baseline dev requirement today.
Everyone on my team has been using 15" MacBook Pros with 16GB RAM for the past 3 years. I suspect most developers run with 16GB of RAM just fine.
I'm not arguing "16GB is fine for all developers everywhere!", but it's absolutely not a hard requirement. I suspect for a lot of us, the difference in performance between 16GB and 32GB is trivial.
Regardless, the thing which is kind of stunning about this chip is that they are getting this kind of performance out of what is basically their MacBook Air CPU. Follow on CPUs—which will almost certainly support 32GB RAM—will likely be even faster.
> Regardless, the thing which is kind of stunning about this chip is that they are getting this kind of performance out of what is basically their MacBook Air CPU.
Or to put it a different way: this is the slowest Apple Silicon system that will ever exist.
Laptop or desktop: likely, but even if the next Apple Watch will be faster, which I doubt, their smart speakers and headphones probably can do with a slower CPU for the next few years.
Is there a name for this trait of bringing unnecessary precision to a discussion, I wonder?
I mean, contextually it’s obvious that the previous poster meant this is the slowest Apple Silicon that will ever exist in a relevant and comparable use case - i.e. a laptop or desktop. And the clarification that yes, slower Apple Silicon may exist for other use cases didn’t really add value to the discussion.
And I’m not even being snide to you - I’m genuinely interested whether there’s a term for it, because I encounter it a lot - in life, and in work. ‘Nitpicking’ and ‘splitting hairs’ don’t quite fit, I think?
I don't have a name for it, but I agree that it should have a name. It's a fascinating behavior. I nitpick all the time, though I don't actually post the nitpicks unless I really believe it's relevant. Usually I find such comments to be non-productive, as you mention.
And yet, even though I often believe nitpicks to be unnecessary parts of any discussion, I also believe there is a certain value to the kind of thinking that leads one to be nitpicky. A good programmer is often nitpicky, because if they aren't they'll write buggy code. The same for scientists, for whom nitpicking is almost the whole point of the job.
It's just an odd duality where nitpicking is good for certain kinds of work, but fails to be useful in discussions.
Everything I have seen from Apple talks about Apple Silicon as the family of processors intended for the Mac, with M1 as the first member of that family.
I know other people have retroactively applied the term “Apple Silicon” to other Apple-designed processors, but I don’t think I’ve seen anything from Apple that does this. Have you?
I think if you have a very specific role where your workload is constant it makes sense. I am an independent contractor and work across a lot of different projects. Some of my client projects require running a full Rails/Worker/DB/Elasticsearch/Redis stack. Then add in my dev tools, browser windows, music, Slack, etc... it adds up. If I want to run a migration for one client in a stack like that and then want to switch gears to a different project to continue making progress elsewhere I can do that without shutting things down. Running a VM for instance ... I can boot a VM with a dedicated 8GB of ram for itself without compromising the rest of my experience.
That is why I think 16GB is table stakes. It is the absolute minimum anyone in this field should demand in their systems.
Honestly the cost of more RAM is pretty much negligible. If I am buying laptops for a handful of my engineers I am surely going to spend $200x5 or whatever the cost is once to give them all an immediate boost. Cost/benefit is strong for this.
All of this is doable in 16GB, I do it everyday with a 3.5GB Windows 10 VM running and swap disabled. There are many options as well such as closing apps and running in the cloud.
Update: Re-reading your above comment I realized I mis-read your post and though you were suggesting 32GB was table-stakes... which isn't quite right. Likewise much of below is based on that original mis-read.
I'm not convinced that going from 16GB to 32GB is going to be a huge instant performance boost for a lot of developers. If I was given the choice right now between getting one of these machines with 16GB and getting an Intel with 32GB, I'd probably go with the M1 with 16GB. Everything I've seen around them suggests the trade-offs are worth it.
Obviously we have more choices than that though. For most of us, the best choice is just waiting 6-12 months to get the 32GB version of the M? series CPU.
I've seen others suggest that 32GB is table-stakes in their rush to pooh-pooh the M1.
I, personally, am a developer who has gone from 16GB to 32GB just this past summer, and seen no noticeable performance gains—just a bit less worry about closing my dev work down in the evening when I want to spin up a more resource-intensive game.
I agree with this. I don't think I could argue it's table stakes, but having 32GB and being able to run 3 external monitors, Docker, Slack, Factorio, Xcode + Simulator, Photoshop, and everything else I want without -ever- thinking about resource management is really nice. Everything is ALWAYS available and ready for me to switch to.
People have been saying this kind of thing for years, but so far it doesn't really math out.
Having a CPU "in the cloud" is usually more expensive and slower than just using cycles on the CPU which is on your lap. The economics of this hasn't changed much over the past 10 years and I doubt it's going to change any time soon. Ultimately local computers will always have excess capacity because of the normal bursty nature of general purpose computing. It makes more sense to just upscale that local CPU than to rent a secondary CPU which imposes a bunch of network overhead.
There are definitely exceptions for things which require particularly large CPU/ GPU loads or particularly long jobs, but most developers will running local for a long time to come. CPUs like this just make it even more difficult for cloud compute to be make economic sense.
As someone who is using a CPU in the cloud for leisure activities this is spot on. Unless you rent what basically amounts to a desktop you're not going get a GPU and high performance cores from most cloud providers. They will instead give you the bread and butter efficient medium performance cores with a decent amount of RAM and a lot of network performance but inevitable latency. The price tag is pretty hefty. After a few months you could just buy a desktop/laptop system that fits your needs much better.
Larry Ellison proposed a thin client that was basically a dumb computer with a monitor and nic that connected to a powerful server in the mid 1990s.
For a while we had a web browser which was kinda like a dumb client connected to a powerful server. Big tech figured out they could push processing back to the client by pushing JavaScript frameworks and save money. Maybe if arm brings down data center costs by reducing power consumption we will go back to the server.
I would turn that around. What kind of development are you doing where you feel 32GB is "Barely enough"?
Right now I primarily work on a very complex react based app. I've also done Java, Ruby, Elixir, and Python development and my primary machine has never had 32GB.
More RAM is definitely better, but when I hear phrases like "32GB is barely enough", I have to wonder what in the hell people are working on. Even running K8s with multiple VMs at my previous job I didn't run into any kind of hard stops with 16GB of RAM.
One data point: when I was consulting a year ago, I had to run two fully virtualized desktops just to use the client's awful VPNs and enterprise software. Those VMs, plus a regular developer workload, made my 16GB laptop unusable. Upgrading to 32GB fixed it completely.
Desktops can use less memory than folks many folks think. I have a VM of Windows 10 in 3.5 GB running a VPN, Firefox, Java DB app, and ssh/git. For single use, memory could be decreased.
I think the art of reducing the memory footprint has been lost. Whenever I configure a VM for example, I disable/remove all the unused services and telemetry as the first step. This approaches an XP memory footprint.
That's not what this discussion is about. 16GB is definitively limiting if you run VMs but 32GB should be plenty. If you need more then either you are running very specialized applications which means your own preferences are out of touch with the average developer or you are wasting all of the RAM on random crap.
If you do machine learning or simulations with big datasets and lots of parameters it does become an issue, but I will admit I could just as easily run these things on a server. I don’t think I’ve ever maxed out 32gb doing anything normal.
Sounds like folks never want to close an app. It could be a productivity booster if you want to spend the money and electricity, but is rarely a requirement.
Keep in mind that so far Apple has only started offering M1 on what are essentially entry-level computers. I think it's likely there will be a 32GB Unified Memory version for the 16" MBP (which maybe will become available on the 13" or Mac Mini too).
I think M1 would not be able to achieve the performance and efficiency improvements if the RAM were not integrated, so they'll stick with Unified Memory for the time being. I don't think this will be as tenable for the Mac Pro (and maybe not even iMac Pro), but those are probably much further from Apple Silicon than anything else, so we'll see what happens.
I agree with you completely. I am looking forward to the next offering and hope that they have a plan for more memory.
In the meantime I wonder if they are going to do dual (or more) socket configurations. I was just thinking to myself imagine a Mac Pro with 8 of these M1 chips in it all cooled by one big liquid heat block. That thing would rip.
I can't imagine them not doing it. If they were satisfied that 16GB was sufficient, I would've expected them to also refresh the 16" MBP with M1. I think the fact that they didn't is a good indicator that something about M1 isn't ready for the big boy league, and my guess is RAM will factor into that.
My guess is that the second generation (M2?) will improve performance with little efficiency gain and will include up to 32GB "Unified Memory". And then binning will be used to produce the 16GB and 8GB variants.
> I wonder if they are going to do dual (or more) socket configurations.
Whoa, that's something I hadn't thought of! I wonder if M1 is amenable to that kind of configuration. That would be pretty neat!
(This should be a reply to an older comment of yours and I realise it's probably bad form to be posting it here, but I couldn't find any other way to contact you)
A few weeks ago you made a comment (https://news.ycombinator.com/item?id=24653498) where you mentioned a PL Discord server. Could I get an invite? I can be reached through aa.santos at campus.fct.unl.pt if you'd rather not discuss it in public/if you'd like to verify my identity.
Sorry to everyone else in the thread for being off-topic.
Hello! Yes, HN's lack of notifications really poses a problem in situations like this. Sigh.
However, the answer to your question is fortunately a simple one: the Discord server mentioned is run by the /r/ProgrammingLanguages community over on Reddit [0]! If you go to that page (might need to be on a desktop browser because ugh) and look in the sidebar/do a search for "Discord server", you'll find a stable invite link.
Alternatively, I can just provide you with the current link [1] and note that it may not work forever (for anybody who finds this comment in the future).
Seems to me, off chip RAM becomes a new sort of cache.
If Apple sizes the on chip RAM large enough for most tasks to fly, bigger system RAM can get paged in and performance overall would be great, until a user requires concurrent performance exceeding on chip RAM.
The thing I worry about is that the whole appeal of the Mac Pro is upgradeability — you can replace components over time. So integrated RAM would be problematic since that's a component people definitely like to upgrade.
But with your idea... I dunno, if they could pull that off that would be super cool!
Yeah I think so too. If they can execute from off chip Ram, perhaps with a wait state or whatever it takes, for a ton of use cases no one will even notice.
It will all just effectively be large RAM.
Doing that coupled with a fast SSD, and people could be doing seriously large data work on relatively modest machines in terms of size and such.
A very simple division could be compute bound code ends up being on chip RAM, I/O bound code of any kind ends up in big RAM, off chip.
I mean, as far as Apple computers go... yeah, these are absolutely entry level. And $700 (new M1 Mac Mini starting price) is really pretty reasonable even compared to other options, honestly.
> memory on-die or in-package (not sure how it is configured). They call it 'Unified Memory'
It’s in the package; RAM on the die is called “cache”.
“Unified memory” has nothing to do with packaging. It’s the default for how computer memory has worked since, well, the 1950s: all the parts talk to the same pool of memory (and you can DMA data for any device).
That’s why the term of art for, say, GPUs having their own memory, is called NUMA (“Non-Uniform Memory Access”): unified is the default.) *
M1 is a remarkable chip and Apple doesn’t claim that UFA is some invention: they just used the technical term, just as they say their chips use doped silicon gates. It has become unusual these days and worth their mentioning, but it’s simply ignorance by the reporters that elevated it to seem like some brand name.
In a NUMA system all the memory is in the same address space even if it's faster for a core to talk to some places than other. Traditionally GPUs work in a completely different address space and doesn't use virtual memory. Yes you can DMA to it but if you DMA a pointer it will break on the other end.
According to anandtech the memory throughput is off the charts at 68.25GB/s [1]. That's twice as fast as high speed ddr4 memory (DDR4-4000 at 32GB/s).
In other words: they totally trounced and took it to the next level with regards to memory, because they can. If anything, memory control is their biggest advantage. Scaling the amount of ram won't be an issue. Increasing the bandwidth perhaps, but it'll still be way quicker than what Intel or AMD offer. This seems like something their next gen M2 version could tackle as a somewhat low hanging fruit.
It's twice the speed of one module of high-speed DDR4 memory. Mainstream consumer PC platforms all support dual-channel memory. Dual-channel DDR4-4266 would provide the same theoretical bandwidth as the M1's 128-bit wide collection of LPDDR4X-4266.
Intel's LPDDR support has been lagging far behind what mobile SoCs support (largely because of Intel's 10nm troubles), but their recently-launched Tiger Lake mobile processors do support LPDDR4X-4266 (and LPDDR5-5400, supposedly).
Just to be pedantic DDR4-4266 is non-standard and so won't be found in any mainstream OEM's laptops. LPDDR4X-4266, soldered to the board instead of socketed and with a lower voltage, is indeed an official thing though.
Right, JEDEC standards for DDR4 only go up to 3200. But 4266 is within the range of overclocking on desktop systems and only a few percent faster than the fastest SODIMMs on the market, so it's at least somewhat useful as a point of comparison.
LPDDR memories are developed with more of a focus on per-pin bandwidth than standard DDR because mobile devices are more constrained on pin count and power. But Apple's now shipping an LPDDR interface that's just as wide as the standard for desktops, and reaping the benefits of the extra bandwidth.
FWIW the latest-gen consoles supposedly have memory bandwidth in the hundreds of GB/s. The PS5 supposedly reaches 448GB/s, and the XBX 336 to 560 depending on the memory segment.
None of these systems seem to have on-die memory. Not sure about the XBS, but from the official teardown the PS5 doesn't even use on-package memory: https://www.gamereactor.eu/media/87/_3278703.png
And Apple certainly didn't wait for SoC to use soldered memory.
Yes, but as other threads commented, this is not particularly new. It's similar to how games consoles have been designed.
It's a natural evolution, especially when MacBook Airs and the ilk are not really user upgradeable in the Intel form anyway. It's much harder for regular PCs to make this leap because one party doesn't have as much control.
Putting the memory into the SoC seems to be a lot of how they're getting this amazing performance: the memory bus is now twice as wide as anything else.
But yes, it means that Apple is going to have to either really start jamming more and more into there, or develop a two-tiered approach to memory where slower "external" RAM can supplement the faster "internal" RAM.
My guess is that they are releasing the M1 right now because it's the smallest SoC they're going to make and its yields are just barely enough to be viable. Once they get better yields on the 5nm process, they will start making the larger, more yield-sensitive SoCs with more RAM in them.
The ram is not on the same chip/die as M1, it's another chip that's put in the same package. Increasing RAM will not affect apple's yields at all since the RAM dies are not made by apple and are not 5nm
I don't think that makes any sense, considering that the RAM is not on the same die as the processor. It's on the module, yes, but they're not making it on the same process.
I realize this image is a schematic representation rather than an actual photograph, but here it is.
The point being made is that the processors that they will package with more memory are going to exist on larger dies. When you increase die size you decrease yield so you need to have a mature process.
> The point being made is that the processors that they will package with more memory are going to exist on larger dies.
Are they? I don't think this is how AMD does things—all their desktop and Threadripper processors are constructed out of 8-core chiplets. The higher-core count processors just use more chiplets per package, not necessarily larger dies. If Apple's already putting multiple chiplets on one package (core + RAM), I wonder if they'll use the same approach to scaling.
But why would you offer your i3 with 32GB when you know you are going to make i5 and i7 processors soon? Apple could offer 32GB here but choose to not offer every configuration at every level.
That is a great idea. I think the software is going to be the hard part. You would need some kind of heuristic or software to manage moving memory between those two locations. That is just my initial thought I could be totally wrong.
Every modern general purpose computer already has multiple layers of memory. This would just be an additional layer. The virtual memory subsystems in the OS will handle this. At the end of the day it's just caches all the way down. A workstation with 16GiB of "on-chip" memory would be like a huge L4 cache for the say 512GiB of "standard" DDR4.
I really like OSTEP's chapters on virtual memory if you're interested in reading more[1].
Yet, is it a requirement in a memory hierarchy to copy the lower level in the upper one? Like, all the stuff in you L1 cache has to be also in your L2 cache. E.g. if you would have 32gb of external DDR it would add only 16gb more to the packaged 16gb?
It's definitely not, and in fact swap on a modern OS doesn't work that way. Something can be only in physical RAM, only in swap, or (when "clean"/unmodified vs the copy in swap) in both (allowing it to be dropped from physical RAM quickly). So one obvious approach would be to simply use the external RAM as swap.
Relatedly, I've heard of using Intel Optane as "slow RAM" for cold pages, and I think the idea there is also that it'd be in one or the other but not both. (Optane can be thought of as very expensive/fast flash or very slow/cheap RAM.)
Pretty sure this is already a thing for NUMA systems, e.g. an Intel system with a pair of N-core processors. Each processor gets "its own" half of memory. Memory which belongs to the other processor is slower to access.
See also Linux cpusets (cset command), which can be used to control which NUMA nodes a process has access to.
macos already has capabilities for compressing memory used by applications before finally giving up and paging it out. It seems plausible they could extend the code that supports that feature to push memory to external (or allocate it there in the first place if utilization isn't expected to be hot), and only pull it back after utilization indicates there is a benefit.
Perhaps this will encourage programmers to write true native applications again instead of wrapping web scripting languages in a browser and calling it a day.
I'm referring to the second point about memory that OP made. You know, having to allocate 700MB of memory in order to run an electron chat application.
This is more of a failing of the runtime that Electron uses and how it (ab)uses that runtime. Browsers were never meant to be run once per application. Sciter JS was supposed to be an Electron replacement but it didn't pan out. With some luck c-smile will stay motivated enough to finish it and once it gains traction there will be another attempt to opensource it.
Not everyone lives in the first world. Not everyone has a new computer.
It is this sort of hubris that likely explains my feeling that personal computing has regressed in many ways for the average individual over the recent years. I'm not talking about the hacker who can run surf+i3 on their cyberdeck, I'm talking about the person with an 8-year old computer bought on sale or a 4-year old smartphone.
RAM is only cheap because people don't waste it. If every application was written with Electron or every executable was a Java program (including CLI commands) you would cry and beg for more memory efficiency.
It's certainly in package rather than on the same chip. The process required to make DDR is different from what you use to make the core's logic. The DRAM chips might be literally stack on top of the CPU chip, though. Apple does things that way in the iPhone IIRC.
It's not due to the on package or the united memory. M1 is using industry standard 128bits lpddr4. On package is still using regular dram chips. What seemingly is the advantage is the firestorm cpu has much wider pipeline and capable doing more load and store in-flight at the time. Also the cache is also able to provide low latency and the bandwidth numbers. Intel or amd is able to achieve similar performance in memory bound workloads if they designed the logic on cpu for that workload.
Not to mention the e-waste and the inability for users to upgrade their own devices.
I wonder what the performance cost was of having standard memory modules. I suspect it wasn't significant and this is more of a move to prevent upgrade and increase consumption and waste.
This is another reason I really don't ever want to own another Apple device. They want more and more control over the system and they keep moving to policies that reduce the ability of regular people to repair. The performance benefit doesn't really seem worth it if I can't run any other operating systems except macOS on it.
Standard memory modules which were soldered onto the mainboard?
Given how Macbooks have had soldered memory packages for ... 8 years now, I don't think moving the memory onto the SoC was to lock out upgrade potential. It doesn't make upgrading any less possible than "completely impossible", and probably (slightly) reduces the overall cost/complexity of the board, slightly reducing the material cost/impact.
FWIW, in the future I imagine most processors will look like the M1, with additional memory available over a serial bus like OMI, used in POWER10. The "unified memory" will effectively serve as a giant cache for the CPU/GPU with slower peripheral memory used as a backing store.
Even if you could boot other OSs, you forget that there are no drivers written for them. Windows and Linux both would be unusable for potentially years after launch.
It would certainly help if Apple would release specs, or even just liberally-licensed XNU driver sources, but Linux has certainly gotten drivers without manufacturer help before.
That's a pretty significant step up from what they were previously shipping, right? The 16" MBP page says it has "2666MHz DDR4". Are any other major (laptop or desktop) manufacturers using LPDDR4X-4266 or LPDDR5-5500?
I agree completely since for large projects 16GB is barely enough to run Bazel. I know that's kind of sad but often Bazel wants to load large graphs into memory. Combined with the fact that the graphics are stealing part of main memory, I don't think I'm going to be happy with 16GB. I ordered one anyway, but I don't expect to be too psyched about the reality of it when it gets here.
I'm afraid I lost the source, but this morning I was reading about some fairly in-depth Xcode benchmarks, the dev was saying that there was almost no hit in performance when it hit swap, and speculated that Apple might be getting ready to move past the concept of RAM altogether in a few years. Sounds a little bonkers to me, but the bus to the SSD is no joke
Next gen consoles and Nvidia rtx io is kind of doing that with graphics textures. Textures are memory mapped but stored in nvme storage. When GPU reads a texture, it first looks in the ram, if not found in the ram, the controller talks to nvme controllers to load from storage.
If you think about it, gen4 pce nvme can reach 5GB/s doing 16k ramdom reads. The bandwidth is getting close to ddr2/3 territory.
And new storage tech like 3dxpoint will have ram like access latency to improve small io perf.
You will always still need ram, but you can be more efficient at how to use the ram.
I'm still a little unclear on whether he means "concept of RAM" in a marketing sense, discrete RAM, or a model closer to L3 cache. regardless, pure speculation
Isn't fast on-die/on-package (not sure either) memory access a key factor for Apple's gigantic performance leap, though? With memory pre-soldered on small notebooks for years now, it's not much of a difference for consumers anyway once more than 16GB becomes available.
I'm not sure that the soldering does much to improve memory access.
The anand tech M1 article measures memory latency at more than 90ns [1], which is almost twice what I see for AMD and Intel benchmarks, at 50ns and 70ns [2]. If these are not comparable measurements, I'd love a correction!
It seems to me that there's significant room to improve the memory subsystem for Apple Silicon to reach parity with desktop RAM performance.
What people seam to forget is, that SOC is the future, and an upgrade should be as simple as switching one chip. This also comes with a lot of benefit with locality and performance.
No. That's a stupid idea for desktop. Not everyone needs 64GB of RAM, but some of us do - and that would be an expensive and awful upgrade to have to throw out your CPU with 32GB RAM on-chip just to put in the same CPU with 64GB on-chip. It makes absolutely no sense.
So you're talking about taking a $300 CPU chip and turning into a $500 or $800 chip depending on how much RAM is on the SOC. But the fact still remains that the vast majority of the RAM sits idle while the CPU processes through relatively small chunks of it at a time, which is what cache is for. If anything I'd rather see more cache RAM on the CPU itself than having to pay for a CPU + RAM on the same SOC. The performance gain from combining CPU + RAM on the same "SOC" is not that great enough to warrant doing that as an approach for all computers - Apple is doing this mostly because it saves them money. There's a lot of push back from power users about expandability not even being an option anymore. But 99% of Apple's customer base doesn't have any need for expandability or power-user features, or having the fastest silicon available because they only use it for facebook, facetime, or a few other basic applications. And that's fine. I won't be buying one though.
It's a radical decision yes, but also so very Apple-like. And I wonder how much of this wild architecture change is also behind the improved performance here.
People claim if you switch off to Safari the memory footprint goes down. Of course, if you're an FE dev, that comes with more ... challenging ... dev tools. YMMV.
Haha! I somehow became sated with 16GB on my laptop. Now any of my workloads which require more would simultaneously want higher cpu, so those loads get pushed to a different machine entirely. So I'm curious what is the use case for 16GB+ with a laptop cpu.
For some people the main advantage of a laptop is the posssibility to move to spots where there's no or very bad connection. In those cases it becomes really useful to be able to run all your workloads on it, even if much slower.
Virtual memory. I mentioned it in this context because running out of physical memory means the machine starts swapping, which often results in a very undesirable slowdown.
I actually feel like 16GB is pretty much the sweet spot. I've built a desktop PC recently and didn't bother with 32GB and haven't had any troubles. The only time I've run into limits is when I was doing things like running games and big IDEs at the same time which seems like a waste in any case regardless of how much RAM is available.
For me on windows, multiple virtual desktops, browser (chrome for work, ff for personal) IDE's and VMs (ubuntu running in wsl, and any docker containers) made 16gn unuseable for me
And that's before I decided to boot up a game with all of the existing applications
For me the £50 is well worth not having to care about pruning applications constantly!
I recently got introduced to great suspender here and Chrome with separate accounts doesn't use much resources because tabs get backgrounded.
Yes, you would still have to juggle if you really dont want to close your IDE, or lower judge how much RAM that docker container really needd, but also understand that OS’ and software allocate a huge portion of all available memory no matter what you have in the machine. Like you think you need 32gb for snappy performance and it is rational idea that all your processes absolutely need sequential memory blocks, but it isnt that true.
I honestly think you would just be smarter about your use of resources again.
With these benchmarks I am starting to lean more towards 32gb itself being the compromise. Simply because it doesnt cause you to budget resources, a luxury, but at the expense of these other benchmarks? And in the worst case we just have to wait a year or two before 32gb is offered in the M series package?
I wonder if they have improved their memory compression with this new release as well. Would have compare apples to apples for various applications to see the effect.
Memory usage shouldn't change that much for a similar task. It's just that paging stuff in and out is much more performant when the system is under pressure. Right now with the least amount of M1 native software available, most of it will be allocating memory natively without garbage collection.
Apple's strategy has been to avoid generational/tracing GC which reaps big benefits in terms of memory usage. It'll be interesting to see more feedback from devs running a broader range of software. It's likely people will hit apps on the long tail that use GC, and similar schemes, which will cause them to complain about memory issues. Running old apps under Rosetta 2 will be another source of complaints.
These machines are optimized for the mass market. Although they can out perform many existing machines with 8 and 16 GB of RAM, there is the huge opportunity and demand for 32GB+.
The real competition is no longer Intel. Its AMD. Or if you're just buying Apple because you like them then there is no competition, you buy what they offer.
I like fanless systems so I'll be watching Apple closely.
I can't help but chuckle whenever I read these comments on HN about how doomed Intel is.
Intel just does this. Every now and then, they get so far ahead that the rest of the market just totally disintegrates, which allows them to screw around and juice up their margins while failing to actually innovate. Their brand is so strong it takes years for it to erode, even when they do suck, and when they have actual competition they've got plenty of cushion to keep selling old designs while they catch up.
The reality of semiconductor tech is that most people are not paying enough attention to understand when a company is doing well and when it's doing poorly. AMD stock was trading in the single digits well after the company was firing on all cylinders. Intel has encountered major bumps in the road since the early days of 10nm, yet research analysts and technologists alike were praising Intel all over the place until recently.
I wouldn't call it a KO until Intel 7nm chips come out. At that time, we'll see if this is a comeback story or just another IBM.
> Keep in mind you're trying to pin magical properties on a brand, and meanwhile people and technologies come and go.
Sure, things change! But Intel is huge, and it's got a track record of repeatedly weathering setbacks and missteps only to come back with market dominance.
Maybe it's really going to be all about Apple and AMD while Intel plays catch-up for generations to come - I just feel like it's a bit premature to come to that conclusion.
Delays aren't necessarily underperformance. Let me offer an example.
If Boeing had delayed the rollout of the MAX 8, or even simply reduced the production rate, it may have been able to identify and rectify the MCAS failure mode, thus preventing suspension of the MAX aircraft. In retrospect, they could have delivered more aircraft prior to the pandemic and avoided many of the order cancellations that it brought.
Sometimes, it's better to go slowly and get things right than to forge ahead at full steam. We won't know if these 7nm delays are good or bad for Intel, until 7nm actually rolls out.
It is an underperformance relative to their previously published roadmaps. There may be other reasons than just mismanagement for those delays, but they're still delays.
Intel has had problems with architectural cul-de-sacs before certainly. But they had other architectures on the back burner they could go back to to recover when things didn't work and they still had their process lead to keep them in the game. Recently, though, Intel's architecture work has been at fine but their process has been the thing having trouble. Maybe they'll be able to get 7nm working properly first try despite the problems at 10nm but I'm not sure given the attrition in their process team after the 14nm death march.
I don't know, this feels different. Intel's competition is bloodthirsty and attacking from all sides. Intel has nothing in the pipeline and just keeps dropping the ball (don't forget Intel's lack of penetration in the mobile market).
This feels more like Microsoft getting blindsided by Google, Apple and Amazon amongst others. Intel isn't going anywhere any time soon, but their reign as king of the mountain may very well be over.
Right, and I think some benchmarks I've seen this morning indicate that it throttles during more intensive tasks. The Pro benchmarks better, the only difference being the fan.
All CPUs throttle, all of the time. It's been years since anyone shipped a high-performance processor without a closed-loop dynamic thermal control system.
If your CPU always runs at its steady-state temperature that means it sucks and it leaving performance on the table. A CPU that can run at a steady 3 GHz (or whatever) should be capable of 5+ GHz momentarily given the right initial conditions.
You're choosing the argument first and then trying to justify it post hoc. That's the downside of having these conversations in thread format; it's easy to disagree, and tough to acknowledge that the other guy can be right about some things and wrong about others.
Sure, the critical path setup and hold time limit clock speeds, but that's not the reason for throttling a chip that can turbo at a higher clock. Even if it were, certain operations with a shorter critical path could run at faster clock even when hot.
If thermals weren't the dominant factor, you wouldn't need better cooling to overclock.
My perspective (correct me if wrong):
Hot semiconductors can damage themselves, and this becomes more important as the lithography shrinks. Binning is designed to identify which silicon can be pushed harder and which is not quite up to the task.
I agree with the other guy that if your CPU always runs at its steady-state temperature that means it is leaving performance on the table.
I think Apple have screwed themselves over a bit here by sticking ARM-based Apple silicon in their lower-end/entry level devices first.
I mean what's the point in spending £5k on a fully tricked out 16-inch MBP, as I'd been considering, when an entry level Macbook Air or Mac Mini is going to run rings around it?
The reason I'm not going to buy one of these lower end Macs (the Mini would be the best fit) is that I can't stick enough memory in one, and the Air obviously doesn't really have any ports.
So the upshot is I'm not going to be spending any money with Apple anytime soon.
OTOH, if they'd started at the high end, I'd be looking at spending £5k on a tricked out laptop with absolutely unbelievable performance and as much memory and storage as I want/need, and would be entirely happy to do so because I'd feel like I was getting decent value for money rather than being taken for a mug.
> Apple have screwed themselves over a bit here by sticking ARM-based Apple silicon in their lower-end/entry level devices first
This is the Innovator's Dilemma [1] Apple built its success on avoiding.
> if they'd started at the high end
They'd have to R&D through the M1 to something more advanced. It would go to market later to be bought in smaller volumes by pickier customers.
Usually, this is a good strategy. Scaling is expensive. Starting small at the highest unit volumes subsidises scaling. But Apple is uniquely unconstrained here. Starting with the most technically forgiving makes sense.
You may not buy an Apple product now. But you will wonder "what will Apple's high end product be" when weighing a competitor's offerings.
>> I think Apple have screwed themselves over a bit here by sticking ARM-based Apple silicon in their lower-end/entry level devices first.
I’m pretty sure Apple already has an 8+8 core version with 32GB+ RAM in their lab that runs at higher clocks and blows the doors off the performance of these M1 chips, and they are simply going for maximum shock effect by releasing this ‘low-end’ chip first then tighten the screws to Intel and AMD even further when they release the MBP and iMac with an M1X chip or whatever they will call it.
Well, just to provide a positive opinion, isn't it nice that a company puts baseline good hardware in their consumer grade product that more people can afford, and gives the option for add on better features? (I mean, with the acknowledgement that baseline = relatively expensive with Apple)
Rather than dumbing down / intentionally hobbling a product so they can sell it for cheaper or segment the market and extract maximum profits.
I think it could be a capabilities issue. An ARM equipped Mac is a non-starter for me because my workstation is driven with a dock that has 2x 4K displays connected to it, ethernet, USB hub, etc.
I'm not willing to part ways with my 2nd external display and I'm sure a lot of professionals with my setup would also consider that a deal breaker.
They probably wanted to get something public so developers could start cranking out compatible apps ASAP so when the bulk start buying this hardware for production use, everything is fully baked.
You mean "the current M1-equipped Macs are a non-starter", then. I have no doubt that either the first or second generation of Apple's high-end chips will support 2 external displays.
There is simply too much complex, professional software that will take time to be ported to ARM versus the relative straightforward needs of entry-level users e.g. Go, Photoshop, Docker.
And they need a large install base to push developers to invest the necessary resources.
Adobe has a native M1 Photoshop in beta now and plans to port Premiere after the first of the year. You may be overestimating the effort to “port” to M1. For most apps, it is just a new compile target and a bunch of regression testing.
These machines are Apple’s volume in Macs. The MacBook Air, in particular. And today, Apple gets to tout their best-seller is dramatically faster and has dramatically better battery life.
I don’t think it will make a huge difference for their profits unless the (modest for the mini, significant for the 13” MBP, nonexistent for the MBA) price cuts significantly move more volume. Apple is notorious for sticking to consistent profit margins and stuffing in as much value as they can to meet their target price points. I would expect that their margins on the MBA are ~20-25%, and ~30% on the rest of the Mac line, just as it’s been since at least the original iMac.
Yes, but that a temporary situation and likely to be resolved in 6-12 months.
Some customers will still choose the older models due to various concerns.
-Some customers will hold off out of fear of incompatible software.
-Others will hold off because they need to run boot camp or x86 VMs.
-Others will need extra RAM or Ports.
Others will have no such concerns and will embrace the new.
Putting M1 into low-end devices before Christmas gets the device into the hands of users, solving a chicken-and-egg problem by motivating developers to roll out software that runs natively on M1.
The people who care most about using specific applications that are designed for x86, are the same people who buy the upper-end MBP13 and the MBP16. It makes sense to flesh out the software ecosystem and snag a free iteration on M chips before moving those devices to Apple Silicon.
I don't think the M1 chip is a great choice for the 16" MacBook Pro. It's designed for lower power devices. It may do well on certain workloads like compilation, but may even regress (in terms of performance, not performance-per-watt) on other workloads.
Their future iterations would be much better suited to a higher power device.
It does create this weird short-term demand planning issue, but plenty of corporate customers are buying Intel Macs in large numbers right now (this past quarter was huge) because they want to avoid the bumpy initial years of the transition and stay on Intel until the app ecosystem is stable.
> I don't think the M1 chip is a great choice for the 16" MacBook Pro. It's designed for lower power devices. It may do well on certain workloads like compilation, but may even regress (in terms of performance, not performance-per-watt) on other workloads.
What workloads do you think won't run better in some manner (faster, lower power consumption, etc.)? It's a general purpose CPU. Apple's own benchmarks talked about a broad range of use cases and the public experience and benchmarks are demonstrating this.
There are obvious performance considerations. With a fan, these M1 CPUs have a higher thermal range and sustained performance. This is the thing that's going to be important in the equivalent of the 16" MacBook Pro. They should have the cooling and battery capacity already in the current form factor. The question is do they have the M1 with many more cores, a new variant of the M1, or do they have some more exotic configuration? Only time will tell.
Corporates buying Macs are going to have to decide if their work can be done on these new models. There is no option but to test it. It'll suit some dev environments, but others (e.g. docker-heavy web shops) will have to stick to Intel for now. There are practicalities like needing to replace broken machines and upgrade from slower 2016/2017 models in many places that means it'd be silly to do a wholesale conversion. iOS and Mac dev shops will have much better flexibility in upgrading, but they are in the minority.
Bigger picture, the new M1 models are great for getting solid machines in the hands of the masses without being revolutionary. Devs can get to work on migrating software without the launch running on like the Mac Pro update did (that was a faux pas from Apple that they seem to have recognized.) It leaves open the possibility that next year we may see a complete form factor update across all laptop lines at Apple. It's to Apple's advantage that they delay that because it's high cost (retooling manufacturing) and high risk (the market doesn't like the product change).
I agree with the bulk of what you're saying -- especially about practical considerations involving the software ecosystem and advantages of moving slowly, but I do believe there are some workloads where I'd prefer a hotter machine with more (and not shared) memory.
I think one of the advantages of M1 is its single-thread access to lots of RAM. That advantage kind of starts to fall off when your workload is heavily multi-threaded, which is often the case for buyers of larger machines with more compute cores.
I also believe that the advantages of low power consumption (or equivalently, thermal efficiency) fall off a little bit when you have a larger thermal envelope, because with a larger device (A) you can fit better cooling, and (B) bursts of compute take a longer time to bring the device to throttle temperatures.
Apple's own benchmarks of the M1 are not compared against the 16" MacBook Pro. They aren't yet offering Apple Silicon on the 16" because it isn't clearly better than the current Intel version, and would have elicited comparisons that aren't as glowing.
I'm thinking specifically games, CAD, and video editing. Even Final Cut Pro workloads (running natively) seem to be faster on a 16" MacBook Pro than on an M1 13" MacBook Pro based on the initial reviews on YouTube today. Sure, an M1 machine could do it consuming less power, but who cares? People buy a 16" because they want speed.
I think they will need redesigned high-performance cores for the 16" and the higher-end 13" [or 14"]. Simply using more of them probably won't cut it.
And MacBooks are not just used in dev environments. They're used in education, finance, media, government, and many other sectors - and some of them do want to be the last to switch. If the performance gains aren't dazzling, they can't be convinced to switch sooner. And if they stay on Intel, they can even be convinced to move back to Windows.
I don't think it matters. They get good margins on all their hardware. Some people will still need the pro hardware or can just switch, and then switch again when the 16" has ARM.
> Some people will still need the pro hardware or can just switch, and then switch again when the 16" has ARM.
I don't know: at pro level prices I'm not sure how many people will switch and then switch again. That's a lot of money and a lot of depreciation on the flip. Granted, I'd been about to spend £5k on a laptop, which is a lot, but I'd expected it to last me 5 years or more. I'm not about to spend that money on a machine that seems to have been substantially rendered obsolete before it's even left the factory.
I have to fight the urge myself, but that's a weaker strategy in these times. I've always invested in upgrades to lengthen the life of my laptops (I'm typing on on a 2015 rMBP 13.) It's probably better to spend £2500 now and £2500 in a few years with how things are going to change with ARM.
Go hard and go low to make CERTAIN that this transition is for the best.
If this were the high-end, some folks could have say: "Yeah, sure cost the same than i9 but you fork $$$$$$$, when go low you will get less and still pay $$$$".
IMO, the Mac Mini is the most peculiar purchase of the recent M1 upgrades as normally the tradeoff to the stationary form factor means much better performance; but here the M1 Mini has similar performance with the M1 Macbook Pro.
Sorely disappointed that the Mini is limited to 16GB. That alone makes it feel obsolete, because 16GB is the new 8GB with as much desktop virtualization I find myself doing.
Maybe they tried and the yield isn't there. There could be more memory and cores in the design right now and they are just having to disable some of it, for example.
I am a jerk. Trolling aside, I'm always a bit skeptical about the application, and roll my eyes (same as when people freak out about the processor on their smartphone). If you're sure it will make a difference though... you'd be like the one person out of ten that upgrades and sees a substantial improvement. Guess I can't help myself, and will accept my downvotes.
I hope so. I'm sitting at 68% memory utilization on a 16GB MBP _without_ any VMs running.
Everytime a manufacturer limits a new model in 2020 to a max of 16GB, I wonder if they really understand with high end work laptops or desktop are really being used for.
I'm at the point where I need a new Macbook Pro and I can't help thinking I want the last generation of the x86_64 architecture, not the first generation of something new. Those have never paid off for me.
At work, Intel would clearly be better. We do a growing amount of Docker work destined for Intel machines. But at home it's fuzzier, since I've been playing with k3s on a cluster of Pi clones. It's going to come down to games, I think. Although I haven't had much time for them lately.
Interesting, although seems like they kind of buried the lede. Surely the go toolchain and Electron should already work find on Rosetta? Getting some new Mac Minis for CI should only take a week or two.
What's unclear from this is if the hypervisor even supports everything they need or if they're waiting on Apple for more features, and how much work it'll require on their end to support the new hypervisor. Since Docker for Mac is closed source I think we're just waiting on the company for it as well. I wonder if we're looking at a month, 6 months, or multiple years?
To be fair, a developer-worthy M1 machine is still going to be 'a little while'. But once that machine is out the previous model quickly ceases to be an option, so I have to sort it out based on speculation.
It depends on your work. Since many developers are using cloud services for serious testing, an awful lot of people are just fine with 8GB for Docker + VSCode + Firefox/Chrome + Slack. There are people who need massive in-memory models or huge compilations but that’s far from universal.
I would like to know how many 8gb ram, 16gb ram and 32gb ram laptops sold apple, I suspect the 32gb market size is not as big as people seems to think. I user docker, virtual machines and a lot of chrome, and have plenty headspace with 16gb.
> It's going to come down to games, I think. Although I haven't had much time for them lately.
I've moved to consoles for games. Rarely I play a game on my Mac anymore. When you sit behind your desk all day for work. Playing games in that same environment and posture gets tiring. The console brings the games to the living room TV in a much more confortable setting.
We've got a Windows 10 box at every TV. Aside from games, it's just so much faster and ad-free compared to using a Smart TV/Roku/Apple TV/etc. They're also easier to operate with a Logitech K400r keyboard and touchpad. Add an XBox controller and a decent GPU and it's just like using a console but with cheaper games.
You don't need to build an expensive gaming PC either. My 4 year old i5/GTX1070/16gb/SSD still plays all the games I want it to. I can even play at 4K. I expect this $900 machine to last me at least a couple more years.
If you just want to watch YouTube/Netflix/etc on your couch and do some very light gaming though, check out what you can get for ~$200 - https://www.amazon.com/gp/product/B07B8VX5HZ
I've done this a decent amount myself, but one thing I've been disappointed by is mod support.
Since PCs aren't locked down platforms, you can mod games whether they added support originally or not - But on Consoles, only a rare few games support it.
There are ways to jailbreak consoles and add external mod support, but the process is so esoteric and user-hostile that most console games will have few or any mods written.
Totally agree. Largely quitting PC gaming has been a productivity boon for me. I think somehow the activity being at the same machine I use for work drains my work energy, and for whatever reason the console experience is sufficiently different that it doesn't feel like the same activity.
Huh interesting, I feel very uncomfortable sitting on the couch and find it promotes unhealthy, hunched over posture as opposed to the ergonomic desktop chair.
Also with things like Paperspace and up coming game streaming services it really feels like it won't matter all that much for the times you want to play games on the Mac.
Also remember that with the M1 Macs you'll be getting some access to all the games released for iOS of which many are not the IAP types and are worth playing.
I don’t know what your work setup is, but if you like having dual screens you should either pick one of the Intel models up now or be ready to wait a year or two for support
I'm unhappy with my MacBookPro16,1 I think it's slow, they keyboard is worse than that of my 2013 machine, the touchbar is useless and only produces heat.
the fans are spinning 24/7 when an external monitor is connected. and a lot of the time the machine hangs.
my next machine won't be an macbook pro. 3000€ for a machine that can't handle my load is simply not worth it. especially since machines with more power and have linux/windows costing only around 2500€.
From experience compiling C++ a build can easily take 10 times longer depending on the optimizations flags that are enabled. The bulk of the time is spent in deep optimizations that may be architecture and CPU specific.
Wouldn't be surprised if compiling on a different architecture is multiple times faster because the compiler is not as optimized or doesn't have the same default flags.
If the compiled application runs faster or similarly fast I think it's fair.
The point is to develop and run binaries. If X86 with SSE4 takes a lot more CPU time to compile binaries with acceptable performances compared to ARM, it's a win for the ARM architecture.
It's missing KingOfCoders point of these comparisons being all within the Apple ecosystem. MacBooks infamously have cooling problems and macOS is precisely balanced for battery life on Apple hardware, not AMD Hackintoshes with no speed limits. What happens to these benchmarks if you jettison the Apple overhead entirely?
Is this cross compilation to x86 or a native compile to Arm? That could be playing an important role if it's easier to optimize and emit code for one architecture versus the other.
Maybe, but architecture-specific stuff is a relatively modest part of compiling. And in any case, if you're going through compile-test-run cycles, the fact that it might be easier/quicker on ARM is hardly a ding against it.
if what you care is your edit-compile-run cycle, what matters is how long does it take to compile it to the architecture where you'll actually run the app, which for interactive builds where speed matters most is supposedly your local machine.
Anyone else worried that while these performance improvements are really good, that this is further locking people into Apple's ecosystem? No self-repairs, no bootcamp support, etc
The new hardware is cutting edge cool. But very proprietary, so not for me.
I'm curious about it. Its the first time in a long time that custom silicon outperforms the volume X86 manufacturers. For a long time custom chips (Sparc/ PA-RISC/Alpha) where the fastest, till commodity x86 chips took over being faster and cheaper and those chips are extinct. I think it helped that there were multiple vendors of these X86 CPUs.
But competition is good for us. As long as there is competition we'll get better performance for less power usage/cost.
Apple silicon is not a riskless. Apple need to continue to execute on design and hope that their manufacturer can get the yields they need. Its on the newest chip making process, so if there is a hiccup in the supply it could cause problems. (I think of the harddrive supply drying up 10 years ago because of earthquakes.). Nvidia is buying ARM now, so who knows what might happen if agreements need to be negotiated. It can give them a advantage, but they have to keep executing.
Unless apple buys TSMC and every other digital foundry then yeah that's a distinct possibility. Otherwise no, there are many reasons to use a slower, outdated architecture whether for its open nature or support.
I feel bad for intel if anything. While they're not out, it doesn't bode well for their future.
Nearly universal praise for the M1 versus it's predecessor but I don't see how this really changes Apple's position the way he implies. Their machines are still far more expensive than Windows and can't use high-powered GPUs like AMD/Nvidia. The people who choose PC, still have the same incentives to do so. For most users, the faster performance will probably not be very noticeable. The reduced power consumption is the biggest draw in my eyes.
Far more expensive than Windows laptops? I haven’t looked in a year or so, but last I checked, to get a Windows laptop with a good screen and build quality, you would also need to spend close to (or likely more) than 1,000 USD.
Yeah that's the reality. It's true that Apple hardware is expensive, but the reality really is that you can buy less expensive and also cheaper products than Apple sells. But if you want to buy something of the same quality as an Apple product, you're paying Apple-like prices.
There are cheaper Android phones than the cheapest iPhone, but if you want iPhone-like specs and vendor support and build quality, you're paying $600-$1000 just like Apple charges. You can buy $200 Windows laptops or Chromebooks but if you want the MacBook-like performance and vendor support and build quality, you're paying $1000-$2000. Compare the excellent Galaxy S to an iPhone, or the excellent Dell XPS (or X1 Carbon or Surface etc) to a Macbook and you'll find similar excellent performance and similar excellent build quality for a similarly expensive price.
The reality is that Apple only competes in the higher end of the markets. There are cheaper options but anything that's directly comparable to an Apple product is going to be priced similarly to an Apple product.
iPhone-like performance at least - an iPhone will feel at least as snappy and performant as a flagship Android, but typically with 1/3 of the RAM (flagship androids have up to 12GB of RAM).
> Their machines are still far more expensive than Windows
Previous criticism was that you could get an equivalently powerful Windows device for cheaper from other manufacturers - This likely tips the scale and means that these Macbooks are very competitively priced considering their performance.
Then on top of that, you get battery life and build quality that runs circles around the closest competitor - so it does represent a really compelling offer on paper.
As far as price competitiveness, the MacBook Air is now so far ahead that the “high” price is almost irrelevant.
There is no such thing as a fanless PC laptop with anything close to the same performance or battery life. It literally doesn’t exist at any price.
I mean, people are going to be buying this thing on the education store for $899. This isn’t a $2000 machine we are talking about here. This is college student territory.
“I don’t see how this changes Apple’s position,” I’m having a good laugh at that!
HP x360 13 with Ryzen - 799 and you have a 2-in-1 that you can use at work and play recent games at home. Install Docker and run Linux if you like that option.
Do people actually care about GPUs in their laptops? It seems like any semi-serious gamer would have strong incentives to have a desktop (modular, the prestige of building you own rig). And anyone using GPUs for compute is just going to remote into some server.
The difference is that you can buy something specced to your needs. Most users and even most developers won't be bottlenecked by even an i5. Getting a quad-core Windows/Intel laptop with a 1080 screen, 16GB and upgrade slots for RAM or disk, plus all the output ports for an external monitor is easily under $1000 for even a name brand. My $800 Acer does fine and has an onboard ethernet port because my most resource-intensive application that I use daily is Zoom. And it has an entry-level Nvidia card.
Can we not drag the standard trolling points into another thread? Anyone who’s done the numbers for real knows that “far more expensive” hasn’t been accurate since the 2000s and, well, the AMD GPUs in many Macs would suggest that you’re not very interested in making an accurate comparison.
Most people have multiple factors in their buying decisions. This means that Apple is able to avoid giving a negative on performance for people who value battery life and heat, and the competition will, as it always has, benefit everyone by punishing Intel for the mismanagement which has left everyone getting less for their money.
>Nearly universal praise for the M1 versus it's predecessor but I don't see how this really changes Apple's position the way he implies. Their machines are still far more expensive than Windows
It was never about being cheaper or the best bang for the buck.
Mac was always playing at the expensive end of the market, for people who want/appreciate (most of) what they get (macOS, the hardware/software integration, the ecosystem, the design choices, the better components at various levels - screen, trackpad, the sturdy unibody construction, the sound, the battery life, etc), including some compromises (e.g. lighter and more battery over more powerful graphics cards, simplified product line vs endless configurations and decision fatigue, etc), plus the ability to run commercial apps like FCPX, Adobe Suite, MS Office, and (for those few that care) a UNIX underneath.
Now the Mac has all that, plus a very fact CPU, it can customize for the OS even further, build extra coprocessors and SOC goodies, have crazy battery life at great performance, and even lower cost or higher margins.
Maybe I'm a hater, but I absolutely hate the mac trackpads. Physical left and right-click are so much more comfortable for me. That being said, 90% of PC manufactures are imitating Apple on that note. I also think things like unibody construction and the general design aesthetic are nice, but it's a luxury. And it's not really that valuable of a differentiator when they look the same. By contrast I have a 6 year old white plastic chromebook that my kids have dropped a dozen times and the chassis has multiple cracks held together with tape and it still runs fine. Cost $140 brand new in 2014. Software compatibility is slipping away as a differentiator as well. Web design in particular has shifted away from Adobe and Sketch to products like Figma that are web-based. Ditto for office software like G Suite/O365. The value of mac-only software is shrinking.
> Their machines are still far more expensive than Windows
Are they? I just checked now for US prices:
13‑inch MacBook Pro (Intel Core i5) 32GB = $2059
13-inch Dell XPS (Intel Core i7) 32GB = $2099
These are both the cheapest options available for my desired configuration (32GB RAM and 13-inch screen), and MacBook has far superior build quality, trackpad and OS.
Probably for different specs MacBooks are comparatively more expensive (if you need powerful CPU or GPU) but for a "developer" use (where my main constraint is RAM, i.e. the number of apps I can have open at once) Apple isn't actually that expensive.
The performance per dollar has improved (for some applications, anyway) while it hasn’t for Windows. Perhaps that will drive some transition from Windows but even if it doesn’t, it will incentivize existing Mac users to upgrade. Note also that applications will probably become more bloated and sluggish as happens every time hardware improves, which will make those applications even worse on Windows and older Macs, thus incentivizing adoption of newer macs.
I agree this doesn't really change Apple positioning and won't immediately impact the desktop market. That said, I think its a big kick in the ass to Microsoft and certainly Intel, and hopefully it forces them to compete. Its certainly making me take a closer look at Rasberry Pi and other ARM compute module boards for my homelab. Apple is going to drive ARM software and compiler support as well as broad adoption among developers. Exciting times.
For Apple, it‘s not about attracting new customers but about reducing costs (on the software side and also in licensing costs for the CPU) to increase profits.
Profits are a factor but Apple has always thought more long term: Intel has been preventing them from shipping things on-time (sometimes year+ delays) and they’re limited to what Intel implements in many areas. It’s not as bad but similar to the way that the Android watch market dried up when Qualcomm chose to keep shipping 2014 chips which ruled out most of what designers might want to build.
This gives Apple complete control of their product direction and especially the ability to build unique features which aren’t easy to match - Dell’s design is limited to the combinations which Intel offers unless they pony up a large amount of R&D and get Microsoft on-board but Apple can customize their integrated chips for the exact thermal/size/power characteristics they need.
That’s a big commitment but it’s something they’ve been very successful at in the mobile space so I wouldn’t bet against them.
I'm glad to see some real-world individuals testing this. Will be interesting to see a "post-mortem" on why the M1 has done so well, and where the limits will be in the future (ie: how far can you get with DRAM-on-die?)
In the M1 processor, DRAM is on-package, but not on die. (Even large eDRAMs sharing a die with logic don't currently reach to gigabytes.) How far can DRAM-on-package go? NVidia just released a GPU with 96 GB of HBM on package (80 GB enabled, 16 GB disabled for yield reasons), with 30x the bandwidth (!!!) of the M1 processor. This wouldn't be a low power or low cost solution, but for something like a future generation Mac Pro, it gives a good intuition for how far you can go with today's technology.
Perhaps it's sonething like the following:
Say for instance, it cost intel $50 for a piece of silicon and sells it to apple for $300. In apples designs, they could incorporate Nearly any cost of silicon and wouldn't affect The built sales price, because it's fairly decoupled from what they charge?
I'm going to go with a combination of the 5nm feature size, simplified instruction set, an architecture that's low-power by default so it doesn't need to be throttled for heat/power, and the use of many types of specialized cores to better match workloads with cpu power. It's a modern architecture in the way that x86 just isn't as a 40-year-old architecture that has to maintain backwards compatibility.
Every layer in the storage hierarchy is "just a cache" in front the layer below it, so the naming is somewhat arbitrary. L1/L2/L3 caches are transparent from the perspective of the processor - it only sees a change in access times to main memory.
Any advancement in the storage hierarchy means reducing latency at one level or increasing the amount of memory at that level.
Most caches would use SRAM instead of DRAM, but the technology used doesn't define its role. Microcontrollers often have only embedded SRAM, serving as main memory.
Yes. The best-known exception is IBM's recent(-ish) power processors, which use large eDRAM as a last-level cache. As far as I know, there's no widespread use of eDRAM on processors smaller than 14 nm.
Compiling shit and running tests is what you do when you're working on a software project in Rust. If suddenly your workflow is twice as fast, it's noticeable and this is the only thing that tweet claimed imo.
The title is wrong. Tweet Author issued a correction - he tested an i7, not an i9:
"Ok twitter sucks for corrections BUT: The chip i tested is the: Intel 9750H and this is an i7 NOT an i9. However the single core compute is about the same, and i'm not maxing out on cores. So the ballpark speed increase is quite similar."
Here is The Verge's test with 30 minute Cinebench loop.
It seems that from now on the only difference between Air and Pro is that Air throttles down to about 70 % in sustained mode while Pro's cooling keeps up.
And Apple's last fanless laptop, the lovely 2017 Macbook 12, has a very worthy successor. I now wonder, if/how the throttling changes when plugged into 4K display, as this caused MB12 to run out of thermal headroom in tens of seconds.
(Also, even thermally throttled M1 destroys my current 4C/8T 4 GHz Haswell i7 desktop, which is beyond powerful for everything I need. M1 = 7700 pts, M1 throttled = 5300 pts, Haswell i7 = 4600, and Macbook 12 = 1400).
Does anyone know what the state of Linux on Mac is since the introduction of the T2 chip and now this? Do people still run Linux on Mac and how has the experience been?
TechCrunch give figures for compiling WebKit on the 13" Pro in their review: https://techcrunch.com/2020/11/17/yeah-apples-m1-macbook-pro... - the gains are not as drastic, but it is still faster than the 16" and as fast as a Mac Pro, while using hardly any battery.
Very impressive stuff. I only got a new 16" last year but a lot of my time is spent compiling, I might find it hard to resist upgrading next yera when they announce more Pro models.
This feels fishy somehow; we need a more thorough in-depth look at exactly what is being compiled in both instances (I've seen projects that build half the object files on different architectures). It's likely not a 1:1 comparison on actual amount of code being compiled and linked.
It will be awesome if accurate, but I think we need more data.
There's been XCode benches on some of the reviews (see: https://youtu.be/XQ6vX6nmboU?t=186), seems like the M1 beats even the iMac Pro, and is as fast as a Ryzen R9 3950X hackintosh (although I suspect that they're both reaching the point where compilation is entirely I/O bottlenecked)
Now can we get nVidia drivers back for MacOS? Give me the ability to run an nVidia eGPU natively in Mac OS and I'll keep buying apple for the foreseeable future! Sure, my remote box with a "proper" gpu is fine, but Mac OS will always be the best medium between Linux and something that's actually useable day to day. I love linux, but god could I not use it as a daily driver.
Apple laptops have finally regained a hardware edge.
About a decade ago I overcame my Apple skepticism and moved from Windows to Mac because the MacBook Air simply had better hardware that I couldn’t find for the same price in the Windows world. Apple laptops lost their hardware edge many years ago and are only now winning it back with Apple Silicon.
If your workload never requires more than 20 seconds of compiling, then throttling will never be an issue. I suspect for most modern developers, short, frequent compiling is a more common use-case than 10m+ builds. For video editors and other pros, it's different, but since Apple's CPU offloads a lot of the video & audio processing to secondary processors, I don't think that will be an issue either.
Here is The Verge's test with 30 minute Cinebench loop.
It seems that from now on the only difference between Air and Pro is that Air throttles down to about 70 % in sustained mode while Pro's cooling keeps up.
(Also, even thermally throttled M1 destroys my current 4C/8T 4 GHz Haswell desktop, which is beyond powerful for everything I need.)
He ran it to the point of throttling and it slowed down less than the gains, about 25% slower than fastest speeds. Also brought up the very good point that if you compile (and do other tasks) fast enough, you don't actually need to throttle so the point can, in the real world, be moot.
Does anyone know if there is a video encode benchmark available yet? These can be tricky to perform because you need to take into account the quality and size of the output. I assume x264/x265 are not optimized (yet) for M1. I wonder if M1 is designed for that workload at all (encode, not decode).
I mean, I haven't heard anything one way or another, but I would be willing to bet that Apple, who a) knows that their computers are heavily used by the video industry, and b) has been making iPhone chips with hardware-accelerated encoding and decoding for several years now—the chips upon which the M1 is based—has included that capability in the M1.
I'm just about to buy an X1 Carbon on Black Friday. I really dont want a MacBook air, but the screen and M1 speed/batt seem too good.
Maybe I should just wait. Ryzens will hopefully be coming more steadily next year and Intel should be cutting prices. 2021 is going to be a good year for hardware.
Apple has already launched the Macbook Pro 13" M1 which does come with a fan for probably less throttling. The 16" version wasn't updated so I'm thinking they're planning something special for those.
The 16" MBP will presumably get a bigger version of the same thing; this one is 10W vs the 45W TDP Intel chips that those currently use, so they could just double it (or more).
I wonder how this is possible. I suspect that the i9 was designed for high-TDP usage, and thermal throttling just kills performance. That would mean that the MBP offering an i9 was mostly marketing.
My i9 16" MBP power throttles long before it thermal throttles. FWIW I find the thermals actually quite good, I've never had issues with over-temp but I have daily issues with it hitting the 100W limit and getting throttled down to 1GHz until I unplug the 3rd monitor.
This is a super bad benchmark for many reasons, target architecture is different, underlying cache, storage device, bus width and possible optimizations are all different. Compile time in such a situation means next to nothing without isolating all these factors and what's left is then attributable to the M1 vs Intel difference. That would be a lot of work though and would not make for such a catchy and clickable title.
This is really awesome to see, but also kind of scary and depressing when you realize that the company leading the way in processors is Apple: anti-competitive, developer-hostile, and anti-consumer (except when it benefits them).
Just look at how their new laptops have underwhelming and ludicrously overpriced memory configurations ($0.78125/gb vs $0.12598/gb for a WD_Black m.2 on Amazon), with no ability to extend them yourself.
There's a native ARM Rust compiler that supports Apple's silicon, so while they don't say, my assumption was that this was native rather than emulated.
A twitter post is pretty irrelevant for performance review. We don't have any number (is it 1s vs 2s ?), especially given that this "project" is pretty small (about 150kloc).
M1 pushes users further to mobile phone mentality - no more universal computing, data interoperability. Welcome to a massive vendor lock.
I doubt it will run any modern games.
The next laptop I purchase for home use will be a linux laptop. Hopefully linux on a laptop has gotten a lot better than my last couple experiences with it. Apple products have just taken such a steep turn for the worse over the years, I can't justify paying that amount of money for such poor quality.
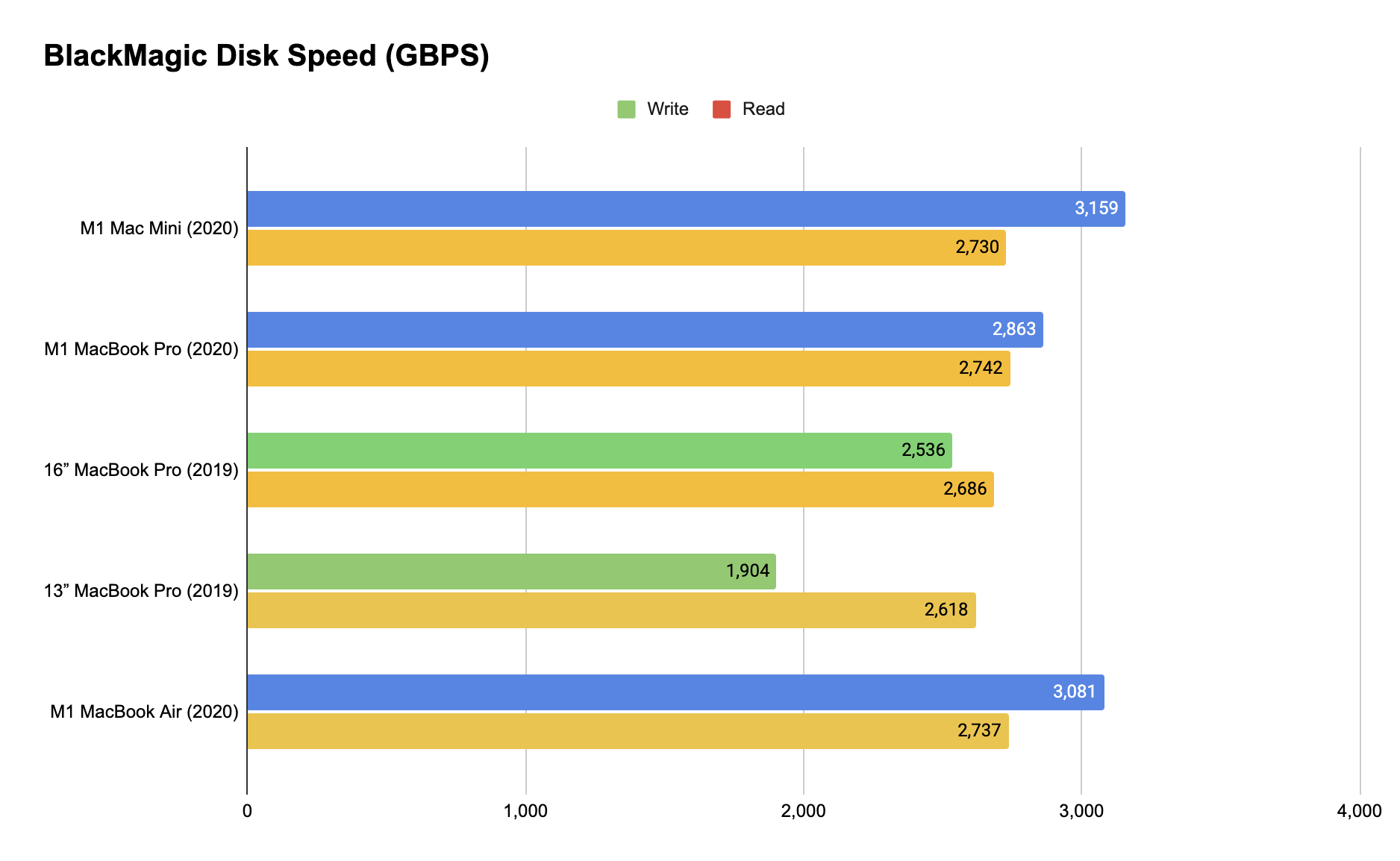{kind=link}
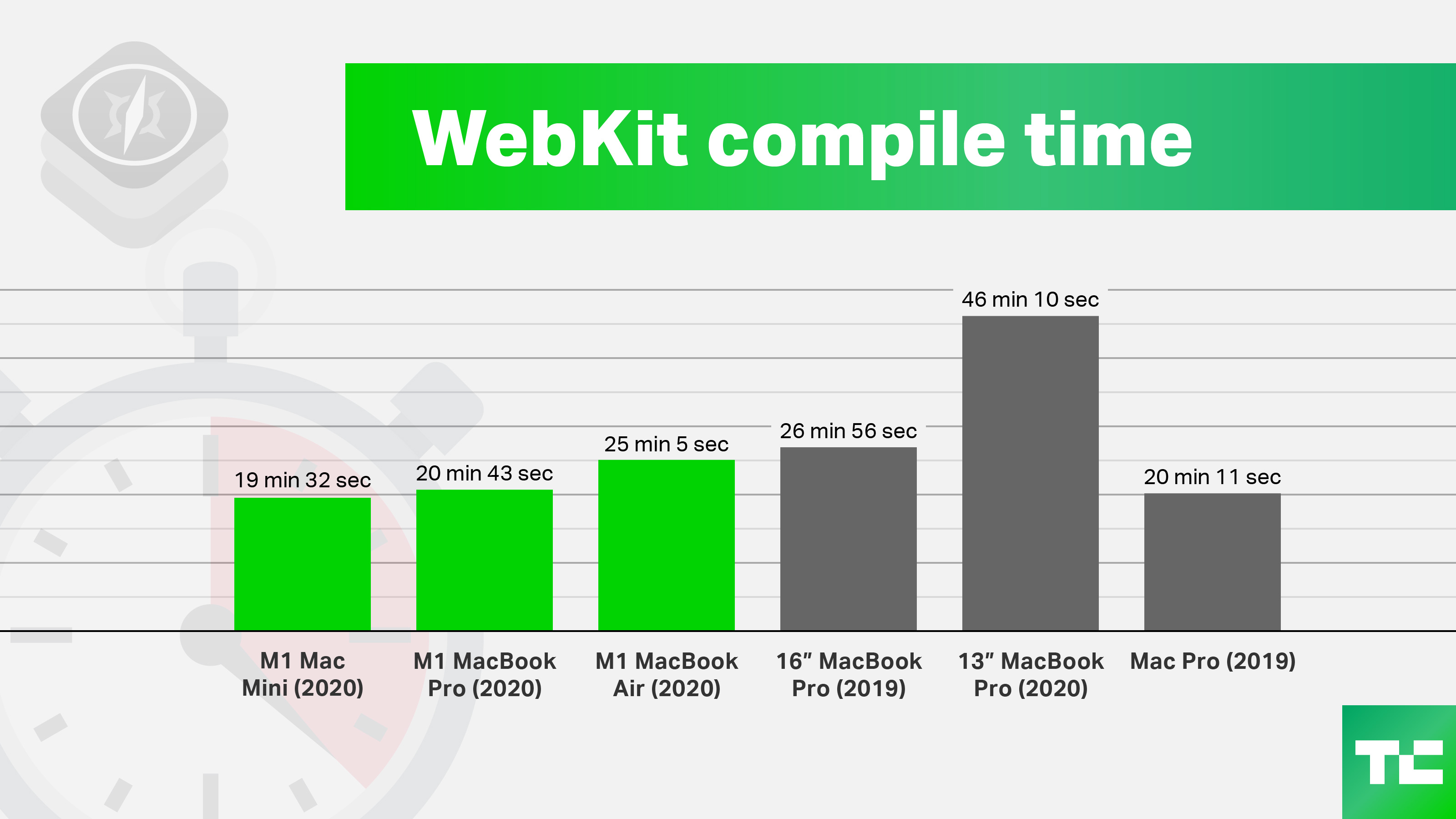{kind=link}
{kind=link}
{kind=link}