I agree this is the interesting part of the project. I was disappointed when I realized this art was AI generated - I love isometric handdrawn art and respect the craft. But after reading the creator's description of their thoughtful use of generative AI, I appreciated their result more.
Niagara is amazing. It's quite different from other launchers, so either it works for you or doesn't. It perfectly matches what I was doing before, which was searching for apps by name to launch them.
Haven't tried KISS, just looked at screenshots. Niagara tries to be slightly customizable and aesthetically pleasing. I've been using (and paying for) it for years. Its plenty lightweight to be snappy on even older model phones.
The article has a quote from the investment director saying it is not symbolism. "The decision is rooted in the poor U.S. government finances, which make us think that we need to make an effort to find an alternative way of conducting our liquidity and risk management"
Wow they were flying at 27,000 feet for a lot of that. I was wondering how they'd get over the Rockies but had no idea they'd go all the way up there. Obviously they need oxygen and the plane has to be designed to fly in that thin of air, but just how hard is that?
Not hard and the glider needn't be special; most already have a stunning glide ratio. I've been up in lesser wave in a clunky old trainer. You do need to coordinate with ATC to keep separation from jets. And the oxygen rig does has to be more serious than a nasal cannula above 18000 ft.
It's remarkable that the ordinary DNS lookup function in glibc doesn't work if the records aren't in the right order. It's amazing to me we went 20+ years without that causing more problems. My guess is most people publishing DNS records just sort of knew that the order mattered in practice, maybe figuring it out in early testing.
I think it's more of a server side ordering, in which there were not that many DNS servers out there, and the ones that didn't keep it in order quickly changed the behavior because of interop.
(Yes, there are other recursive resolver implementations, but they look at BIND as the reference implementation and absent any contravention to the RFC or intentional design-level decisions, they would follow BIND's mechanism.)
People probably ran into this all the time, but no single party large enough to have it gain attention produced the failure state.
If a small business or cloud app can't resolve a domain because the domain is doing something different, it's much easier to blame DNS, use another DNS server, and move on. Or maybe just go "some Linuxes can't reach my website, oh well, sucks for the 1-3%".
Cloudflare is large enough that they caused issues for millions of devices all at once, so they had to investigate.
What's unclear to me is if they bothered to send patches to broken open-source DNS resolvers to fix this issue in the future.
The last time this came up, people said that it was important to filter out unrelated address records in the answer section (with names to which the CNAME chain starting at the question name does not lead). Without the ordering constraint (or a rather low limit on the number of CNAMEs in a response), this needs a robust data structure for looking up DNS names. Most in-process stub resolvers (including the glibc one) do not implement a DNS cache, so they presently do not have a need to implement such a data structure. This is why eliminating the ordering constraint while preserving record filtering is not a simple code change.
Doesn't it need to go through the CNAME chain no matter what? If it's doing that, isn't filtering at most tracking all the records that matched? That requires a trivial data structure.
Parsing the answer section in a single pass requires more finesse, but does it need fancier data structures than a string to string map? And failing that you can loop upon CNAME. I wouldn't call a depth limit like 20 "a rather low limit on the number of CNAMEs in a response", and max 20 passes through a max 64KB answer section is plenty fast.
I don't know if the 20 limit is large enough in practice. People do weird things (after migrating from non-DNS naming services, for example). Then there is label compression, so you can have theoretically have several thousand RRs in a single 64 KiB response. These numbers are large enough that a simple multi-pass approach is probably not a good idea.
And practically speaking, none of this CNAME-chain chasing adds any functionality because recursive servers are expected to produce ready-to-use answers.
It’s not remarkable, because it’s the way all DNS servers work. Order is important in DNS results. It’s why results with multiple A records are returned in shuffled orders: because that impacts how the client interprets the results. Anyone who works with DNS regularly beyond just reading the RFCs ought to recognize this intuitively.
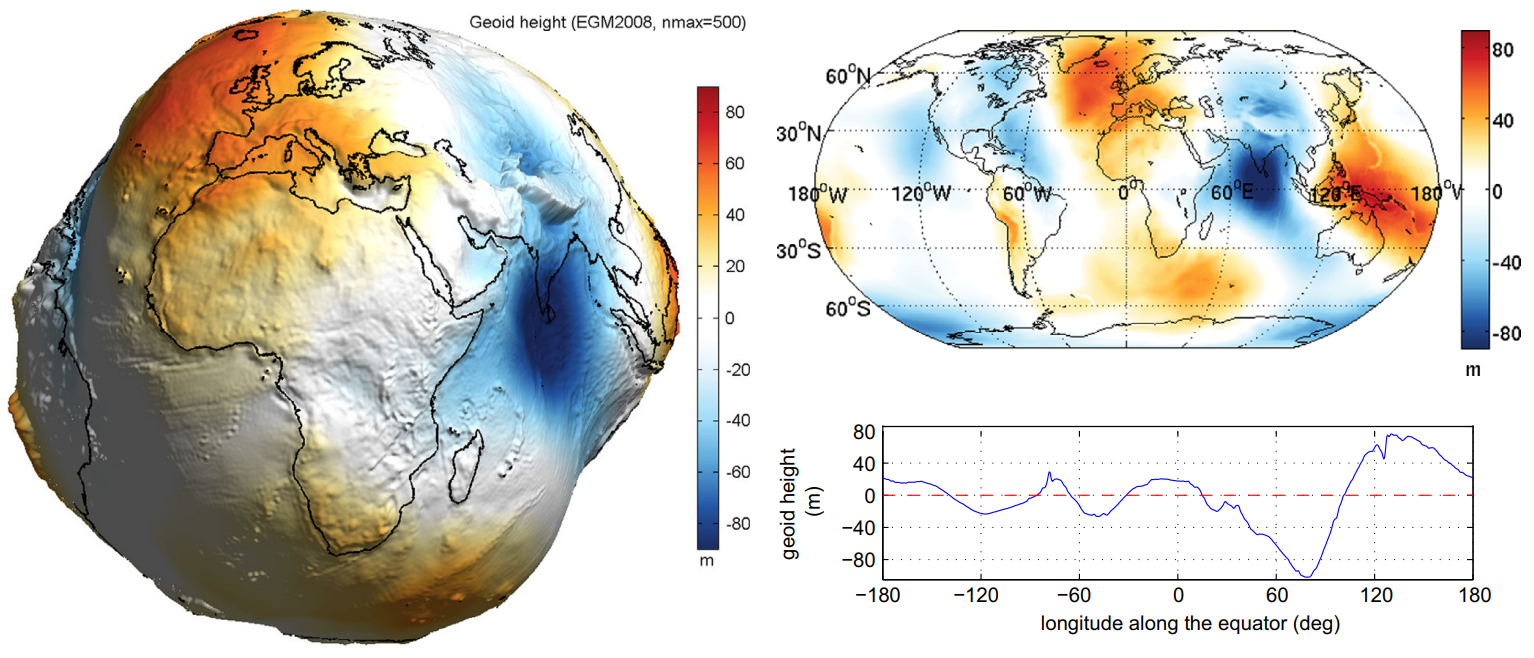
For anyone not reading the article, she did fundamental work measuring the geoid, the non-spherical corrections to Earth's shape that is fundamental to very accurate GPS positioning.
I think it's a littly funny he characterizes "Had the right flavor for every different context" as an advantage. It drives me crazy that Markdown is not the same everywhere and I'm still regularly getting confused about *bold* or **bold** or *italics*. (Curse you, Slack's weirdo version.)
I respect Anil's argument that the extensibility has helped it be adapted to different contexts, and in practice the looseness of it doesn't cause a problem. I do wish CommonMark had more traction (and acceptance and use of the name Markdown). It'd be nice to have a standard, at least for the basic stuff.
That's exactly what we used in on usenet (except,without rendering unless you were using a nice GUI reader, not just tin/rtin)
The problem is that that's too many characters to reserve (they all have to be escaped when you want the actual character) making the resulting text look awful in plain text mode.
They are not reserved characters. They only express a special format when used in that way : a space on its left, and a character stuck to its right AND somewhere down the road : its twin with a character stuck to its left and a space on its right. I built an editor doing just that more than two decades ago, and it works fine.
So *this* and /that/ express formatting, but not 4 * 5 nor 4*5 nor 4/5 nor m/s.
In the contexts where Markdown is most often used, the distinction between bold and italics isn't really important. So long as *this* or **this** gets rendered in a way that conveys emphasis, the meaning is preserved.
Single-asterisk for bold is not Markdown. I believe Slack calls their thing "markup". I also find it annoying. So annoying that I just learned Slack's keyboard shortcuts instead.
Slack messages are formatted in mrkdwn <https://docs.slack.dev/messaging/formatting-message-text/#ba...>. Completely unrelated to Markdown, superficial resemblance only. If there were trademarks in play you’d absolutely attack them for trademark infringement.
But what you type isn’t even mrkdwn, but rather an input mode that supports most of the same syntax.
It took me a long time to see the variations as a plus and not a minus; as a veteran of the RSS-vs-Atom wars, I was long an advocate of Technical Correctness(tm) like any good coder. But the years since then have made me a lot more amenable to what I think of as a sort of Practical Postelism, which I guess is like applied worse-is-better, where we realize the reality is that we'll _always_ have forks and multiplicities, so we should see it as a feature instead of a bug. It's like accepting that hardware will fail, and building it into the system.
I mean, HTML itself is well specified in the streets, and infinitely different flavors in the sheets. I don't _like_ that, the part of me that writes code _hates_ that. But the part of me that wants systems to succeed just had to sort of respect it.
Ah, Anil, but have you fought the plaintext syntax wars yet?
Jokes apart, regular, standardised, visually-suggestive syntax is a key reason I've stuck with org-mode despite its limited acceptance in the world at large.
The many flavours of markdown make it /less/ portable than org syntax, in my experience. As the post below says, "Pandoc lists six different Markdown flavors as output formats." This is not great for collaboration --- now we need some sort of middleware or advanced editor to help people work with more than one syntax format. Besides, mixing syntax in the same document is a boo-boo, because parsers only work at file-level, not semantic token level.
Owing to this, at times, I go as far as to /author in orgmode, but share in markdown/ (org-export), and slurp back and forth (tangle / detangle).
I had no idea any of this stuff worked well enough to actually run modern games. The FEX emulation layer. The eGPU. It's not how fast this stuff runs that impresses me, it's that it runs at all.
{kind=link}
reply