It's hilarious that people describe their anecdotal experience of being in a calorie deficit as a proof that "intermittent fasting works".
This was never the question, but whether intermittent fasting brings additional weight loss benefits as compared to calorie deficit with frequent meals.
My anecdotal experience from 20y of bodybuilding and doing ~3 cuts a year: for cutting, I tried IF, 6 meals a day, low fat, low carb, high fat true keto, balanced... everything works. And works equally well - this is backed by numerous studies. The only difference is the impact on health parameters (different will get worse on low fat vs high fat), satiety, and how easy it is for someone to sustain the diet and stay in a deficit. This will depend on the lifestyle and personal preferences. So my preferred way to cut is high protein, low carb, essential fats, a ton of fiber. When building muscle I go high everything but balanced.
Anything else and more is sectarianism and people bragging about their choices not having verified their true claimed efficacy or benefits.
> Anything else and more is sectarianism and people bragging about their choices not having verified their true claimed efficacy or benefits.
Everybody's looking for a silver bullet and wants to advocate for their specific one by tearing competing theories down. The reason that IF works is because it's more difficult to eat at a caloric surplus when you can only fill your stomach for 8 hours a day. Full stop. There might be modest ancillary benefits but as far as weight loss it really is as simple as calories in versus calories out. There are tons of variations on this theme dependent on goals and tolerance for discomfort but simple math wins ten times out of ten.
For the layperson IF or keto or something similarly extreme is effective but difficult. It requires strict adherence to a lifestyle that impacts one's social life and makes eating prepared foods difficult. Worst of all it leads to impromptu cheat days in moments of weakness that spiral out of control and negatively affect consistency. For people trying to lead a normal life I personally think eating at 80% TDEE with 1:1:1 macros is the most sustainable - you eat at your leisure, get sufficient protein for lean muscle mass and still eat carbs for energy and fun. It's basically "eat less, have a protein shake." Combine this with some light cardio and body weight/kettlebell stuff while watching TV and you'll see great functional fitness gains in addition to quick and steady weight loss.
Of course it's hard to build an online quasi-religion around moderation so this type of thinking isn't mainstream despite its efficacy.
Totally agree, you have to figure it out for yourself. Not only do these diets affect people differently, they also affect each individual differently throughout their life. IF might be great when you are 45 but no good when you are 20.
I really struggled to get lighter a few years ago and what ended up working finally was cutting my protein way down. After repeated failures with high protein/low carb, I finally just went for low protein despite no diet recommending it. It worked great, I lost muscle but it made satiety way easier and my body naturally seemed to shift to a lighter composition.
I still don't see any diets recommending that. It seems like a useful tool, especially given how "fitness" nowadays is lifting weights and chugging protein, there are going to be a ton of dudes in their 30s/40s who put on a boatload of muscle in their youth and now are struggling to get lighter using all the recommended high protein diets. If you don't give the muscle up satiety is going to make it an insane battle.
> The only difference is the impact on health parameters (different will get worse on low fat vs high fat), satiety, and how easy it is for someone to sustain the diet and stay in a deficit.
That was never the question or point. It was that’s it’s easier to adhere to intermittent fasting and consume less calories. So if you simply did a study comparing intermittent fasting vs general calorie restriction and didn’t control for calories then intermittent fasting would win. Controlling for calories completely misses the point
I share the sentiment. I haven’t used it in a while (at work use different languages and in the last few years my personal coding is only Python script/Jupyter notebook bite-sized), but anytime I hop into it, it immediately "clicks" and gives a comfortable feeling, despite changing over years.
A perfect language for medium sized relatively clean and mature personal or small team projects.
Frictionless, pleasant, not thinking too much how to express things (and still managing to write them reasonably idiomatic), tends to support clean encapsulated code, quite rich environment/libraries, great tools (debuggers, profilers), safe, relatively fast, not many foot guns, zero build setup, on small project zero build times, trivial to create good functional simple UI, can get fancy dynamic with reflection when I need "magic".
Basically not many pain points that would make me rage quit and almost everything I'd want is simple to achieve.
Original author here and it's been a while since I have read such word salad nonsense, sorry. Why people who have no idea or expertise comment on articles?
GenerateMips API constructs a mip chain by using box/bilinear (equivalent for factors of two) log N times.
Trilinear interpolates across three dimensions, such as 3D textures or mip chains. It is not a method for downsampling, but a method for filtering that interpolates two bilinear results, such as two bilinear filters of mip levels that were generated with "some" downsampling filter (which can be anything from box to Lanczos).
Anisotropic is a hybrid between trilinear across a smaller interpolation axis under perspective projection of a 3D asset and multiple taps along the longer axis. (More expensive)
> Trilinear interpolates across three dimensions, such as 3D textures or mip chains
I meant trilinear interpolation across the mip chain.
> generated with "some" downsampling filter (which can be anything from box to Lanczos)
In practice, whichever method is implemented in user-mode half of GPU drivers is pretty good.
> It is not a method for downsampling
No, but it can be applied for downsampling as well.
> under perspective projection of a 3D asset
Texture samplers don’t know or care about projections. They only take 2D texture coordinates, and screen-space derivatives of these. This is precisely what enables to use texture samplers to downsample images.
The only caveat, if you do that by dispatching a compute shader as opposed to rendering a full-screen triangle, you’ll have to supply screen-space derivatives manually in the arguments of Texture2D.SampleGrad method. When doing non-uniform downsampling without perspective projections, these ddx/ddy numbers are the same for all output pixels, and are trivial to compute on CPU before dispatching the shader.
> More expensive
On modern computers, the performance overhead of anisotropic sampling compared to trilinear is just barely measurable.
The problem is that your suggestion is strictly worse and unnecessarily complicated for the case discussed in the article. If you want to downsample 2x, 4x, etc, then that's just one level in the MIP hierarchy, no need to compute the rest. The point of the article however is to explain how one level in that MIP chain can be computed in the first place.
If you want to downsample 3x or fractional, then interpolating between two MIP levels is gonna be worse quality than directly sampling the original image.
Perspective (the use case for anisotropic filtering) isn't discussed in the article, but even then, the best quality will come from something like an EWA filter, not from anisotropic filtering which is designed for speed, not quality.
If someone believed they will earn 2-5x better than in academia, with full freedom to work on whatever interests them, and no need to deliver value to the employer... Well, let's say "ok", we have all been young and naive, but if their advisors have not adjusted their expectations, they are at fault, maybe even fraudulent.
Even being in elite research groups at the most prestigious companies you are evaluated on product and company Impact, which has nothing to do with how groundbreaking your research is, how many awards it gets, or how many cite it. I had colleagues at Google Research bitter that I was getting promoted (doing research addressing product needs - and later publishing it, "systems" papers that are frowned upon by "true" researchers), while with their highly cited theoretical papers they would get a "meet expectations" type of perf eval and never a promotion.
Yet your Google Research colleagues still earned way more than in academia, even without the promo.
Plus, there were quite a few places where a good publication stream did earn a promotion, without any company/business impact. FAIR, Google Brain, DM. Just not Google Research.
DeepMind didn't have any product impact for God knows how many years, but I bet they did have promos happening:)
You don't understand the Silicon Valley grind mindset :) I personally agree with you - I am happy working on interesting stuff, getting a good salary, and don't need a promo. Most times I switched jobs it was a temporary lowering of my total comp and often the level. But most Googlers are obsessed with levels/promotion, talk about it, and the frustration is real. They are hyper ambitious and see level as their validation.
And if you join as a PhD fresh grad (RS or SWE), L4 salary is ok, but not amazing compared to costs of living there. From L6 on it starts to be really really good.
> I am happy working on interesting stuff, getting a good salary, and don't need a promo
People who don't contribute to the bottom line are the first to get a PIP or to be laid off. Effectively the better performers are subsidizing their salary, until the company sooner or later decides to cut dead wood.
> full freedom to work on whatever interests them, and no need to deliver
> value to the employer...
That was an exaggeration. No employee has full freedom, and I am sure it was expected that you do something which within some period of time, even if not immediately, has prospects for productization; or that when something becomes productizable, you would then divert some of your efforts towards that.
It wasn't an exaggeration! :)
The shock of many of my colleagues (often not even junior... sometimes professors who decided to join the industry) "wait, I need to talk to product teams and ask them about their needs, requirements, trade-offs, and performance budgets and cannot just show them my 'amazing' new toy experiment I wrote a paper about that costs 1000x their whole budget and works 50% of time, and they won't jump to putting it into production?" was real. :)
They don't want to think about products and talk to product teams (but get evaluated based on research that gets into products and makes a difference there), just do Ivory tower own research.
One of many reasons why Google invented Transformers and many components of GPT pre-trainint, but ChatGPT caught them "by surprise" many years later.
Well there are a few. The Distinguished Scientists at Microsoft Research probably get to work on whatever interests them. But that is a completely different situation from a new Ph.D. joining a typical private company.
Someone correct me if this is wrong, but wasn't that pretty much the premise of Institute for Advanced Study? Minus very high-paying salaries. Just total intellectual freedom, with zero other commitments and distractions.
I know Feynman was somewhat critical to IAS, and stated that the lack of accountability and commitment could set up researchers to just follow their dreams forever, and eventually end up with some writers block that could take years to resolve.
> you are evaluated on product and company Impact, which has nothing to do with how groundbreaking your research is,
I wonder... There are some academics who are really big names in their fields, who publish like crazy in some FAANG. I assume that the company benefits from just having the company's name on their papers at top conferences.
One unique and new feature of Slang that sets it apart from existing shading languages is support for differentiation and gradient computation/propagation - while still cross-compiling generated forward and backward passes to other, platform-specific shading languages.
Before, the only way to backpropagate through shader code (such as material BRDF or lighting computation) was to either manually differentiate every function and chain them together, or rewrite it in another language or framework - such as PyTorch or a specialized language/framework like as Dr.Jit, and keeping both versions in sync after any changes.
Game developers typically don't use those, programming models are different (SIMT kernels vs array computations), it's a maintenance headache, and it was a significant blocker for a wider adoption of data-driven techniques and ML in existing renderers or game engines.
It does!
Both platform-specific compute shaders as well as cross-compilation to CUDA. The authors even provide some basic PyTorch bindings to help use existing shader code for gradient computation and backpropagation in ML and differentiable programming of graphics-adjacent tasks: https://github.com/shader-slang/slang-torch
(Disclaimer: this is the work of my colleagues, and I helped test-drive differentiable Slang and wrote one of the example applications/use-cases)
It's interestingly disingenuous that many claim of GLP-1 agonist miraculous effects on all kinds of health problems, where the same problems are "simply" solved by getting on a calorie deficit and lean. Liver, kidneys, heart, etc. If you have a non-alcoholic fatty liver disease and are obese, getting leaner will heal it. All those impressive results are on obese or diabetic people. So it is not only not a surprise, but also dishonest marketing or ignorance.
Don't get me wrong - those are miraculous drugs. First real non-stimulant low side effect appetite suppresion that will help millions. But let's wait for honest research on lean people before spreading marketing on how it improves overall health.
Also, how nobody mentions the need for increasing the dosage and tolerance build-up (just check reddits how much people end up having to take after months of continuous use). You cannot be on it "for life".
The increasing dosage is to tritrate up to a dose not because you gain tolerance. There are patients on GLP-1 for over a decade. Also maintenance and weight loss dosages are different: see the dosing charts for ozembic vs wegovy which are exactly the same drug.
Even if folks gain tolerance that doesn’t seem overly concerning. Mental health drugs also have tolerance issues and changing medicines every few years, while it has challenges for the patient, is an accepted part of long term psychiatric treatment.
Just a narrow comment, but type 2 diabetes certainly isn't limited to the obese. Many lean people develop issues with blood sugar that can't be controlled with diet alone.
A friend's son, who is an EMT, was recently diagnosed with type 2 diabetes at the age of 21. He doesn't drink or eat sweets, except on holidays, and works out five days a week. Suddenly, he started feeling sick, was vomiting, and ended up in the ER, all within three days. It can really hit you like a truck.
This is my #1 question on GLP-1: are we just seeing how humans do much, much better by being lean vs. the direct result of the drug?
A lean current-epoch human -- with our food abundance, access to modern medicines, higher standards of life, lower risks of injury, etc -- is likely going to be markedly healthier than a non-lean current-epoch human or a lean human from a prior age where medicine/food/etc was worse.
> where the same problems are "simply" solved by getting on a calorie deficit and lean
Except that there apparently is mounting evidence that GLP-1 agonists also address some issues that are not generally addressed by just restricting calories. TFA touches on this briefly: "The weight loss involved with GLP-1 agonist treatment is surely a big player in many of these beneficial effects, but there seem to be some pleiotropic ones beyond what one could explain by weight loss alone."
I seem to recall seeing claims that they reduce COVID-19 mortality even controlling for BMI (possibly because they inhibit systemic inflammation), reduce alcohol consumption, and even (though I think just anecdotally) may help overcome gambling addiction.
I don't know that you have to be disingenuous to both be enthused about these medications AND wish we'd never created the super-processed, super-sugary, make-people-crave-them-and-overeat-them modern American diet. Once you fuck with your gut biome for long enough it's not "simple" to solve it. It's incredibly difficult both discipline and metabolism-wise.
It's not.
a) compression can be lossless.
b) RAW is not about storing literal photons ADC measurements. It always has "some" processing as those always go through an ISP. We can obviously discuss which processing is the cutoff point and it will differ for different applications, but typically this would include things like clipping, sharpening, or denoising. And even some pro DSLRs would remove row noise or artifacts in supposedly "RAW" files!
If you can change the exposure or WB - it is what is the minimum practical/useful definition of a RAW.
>If you can change the exposure or WB - it is what is the minimum practical/useful definition of a RAW.
No. No it is not at all. Are you a photographer? I am not talking about processing before the photo is saved, I am talking abot the compression of the save file.
Are you trying to tell me that these are the same?
RAW
"A camera raw image file contains unprocessed or minimally processed data from the image sensor of either a digital camera, a motion picture film scanner, or other image scanner. Raw files are so named because they are not yet processed, and contain large amounts of potentially redundant data"
JPEG-XL
Lossless compression uses an algorithm to shrink the image without losing any IMPORTANT data.
Lossless compression is not about importance of data. Lossless is lossless, if the result of a roundtrip is not EXACTLY IDENTICAL then it is by definition not lossless but lossy.
Maybe you're confusing with "visually lossless" compression, which is a rather confusing euphemism for "lossy at sufficiently high quality".
JPEG XL can do both lossless and lossy. Lossless JPEG XL, like any other lossless image format, stores sample values exactly without losing anything. That is why it is called "lossless" — there is no loss whatsoever.
Yes, I am an (amateur) photographer for the last 27 years, from film, DSLRs, mirror less, mobile. And I worked on camera ISPs - both hardware modules, saving RAW files on mobile for Google Pixel, as well as software processing of RAWs.
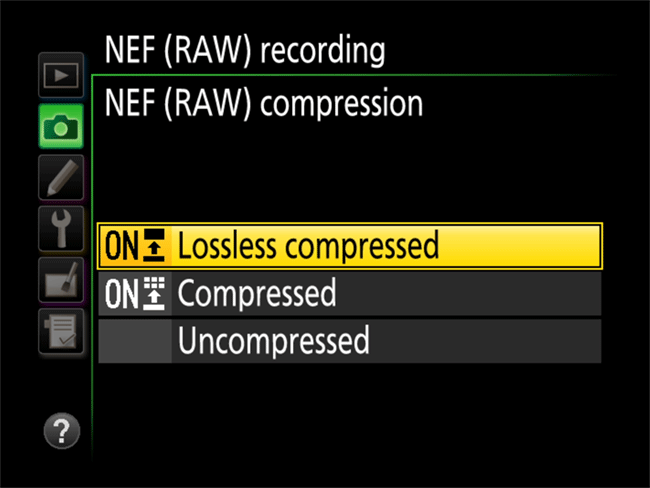
"Lossless Compressed means that a Raw file is compressed like an ZIP archive file without any loss of data. Once a losslessly compressed image is processed by post-processing software, the data is first decompressed, and you work with the data as if there had never been any compression at all. Lossless compression is the ideal choice, because all the data is fully preserved and yet the image takes up much less space.
Uncompressed – an uncompressed Raw file contains all the data, but without any sort of compression algorithm applied to it. Unless you do not have the Lossless Compressed option, you should always avoid selecting the Uncompressed option, as it results in huge image sizes."
Why make the distinction if there is no difference?
Apple is COMPRESSING the image. Period. RAW photos can be compressed, but if they are then they are "RAW Compressed" Files, not "RAW" files.Apple is not saying you are shooting RAW Compressed, it says you are shooting ProRAW photos, which is slick marketing because everyone thinks they are shooting RAW photos but ProRAW is not RAW. The iPhone 12 gave you a choice to shoot RAW or ProRAW, but my iPhone 13 ProMax only allows the ProRAW option. I have no option to avoid Apple processing my photos anymore.
It is semantics but words matter. If something is off with the compression algorithm or the processing how would you know?
More, if the difference did not matter, why does Sony go out of the way to explain the difference?
If a computer compresses and expands the image using an algorithm you are not getting back the same image. Period. I do not care if you perceive it to be the same, it is not the same.
> Why make the distinction if there is no difference?
There is a difference, which is that the compressed lossless version is smaller and requires some amount of processing time to actually be compressed or uncompressed. But there is zero difference in the raw camera data. After decompression, it is identical.
> If a computer compresses and expands the image using an algorithm you are not getting back the same image. Period. I do not care if you perceive it to be the same, it is not the same.
It is the same. You can check each and every bit one by one, and they will all be identical.
No, but it’s also a painting instead of a digital file, so different considerations apply (maybe the copy wouldn’t be strictly identical, maybe the value is affected by “knowing that Van Gogh is the one who applied the paint to the canvas” or by the fact that only one such copy exist), and this is therefore a false analogy.
If you copy the number written on a piece of paper to another piece of paper, is it the same number? Yes, it is, and a digital photograph is defined by the numbers that make it up. Once you have two identical copies of a file, what difference does it make which one you read the numbers from?
Or are you arguing that when the camera writes those numbers to the raw file, it’s already a different image than was read from the sensor? After all, they were in volatile memory before a copy was written to the SD card.
It's the other way around - in hearing, phase is almost irrelevant. At medium frequencies, moving head by a few centimeters changes phase wand phase relationships of all frequencies - and we don't perceive it at all! Most audio synthesis methods work on variants of spectrograms and phase is approximated only later (mattering mostly for transients and rapid frequency content changes).
In images, scrambling phase yields a completely different image. A single edge will have the same spectral content as pink/brown~ish noise, but they look completely unlike one another.
Makes sense! My impression that phase matters from audio comes from when editing audio in a DAW or anything like that. We are very sensitive to sudden phase changes (which would be kind of like teleporting very fast from one point to another, from our heads point of view). Our ears kind of pick them up like sudden bursts of white noise (which also makes sense, given that they kind of look like an impulse when zoomed in a lot).
So when generating audio I think the next chunk needs to be continuous in phase to the last chunk, where in images a small discontinuity in phase would just result in a noisy patch in the image. That's why I think it should be somewhat like video models, where sudden, small phase changes from one frame to the next give that "AI graininess" that is so common in the current models
I have an example audio clip in there where the phase information has been replaced with random noise, so you can perceive the effect. It certainly does matter perceptually, but it is tricky to model, and small "vocoder" models do a decent job of filling it in post-hoc.
Seems you have not worked with ML workloads, but base your comment on "internet wisdom", or worse, business analysts (I am sorry if that's inaccurate).
On GPUs, ML "just works" (inference and training) and are always order of magnitude faster than whatever CPU you have.
TPUs work very well for some model architectures (old ones that they were optimized and designed for) and on some novel others can be actually slower than a CPU (because of gathers and similar) - this was my experience working on ML stuff as an ML Researcher at Google till 2022, maybe it got better but I doubt. Older TPUs were ok only for inference of those specific models and useless for training. And anything new I tried (fundamental part of research...) - the compiler would sonetimes just break with an internal error, most of the time just produce terrible and slow code, and bugs filed against it would stay open for years.
GPU is so much more than a matrix multiplier - it's a fully general, programmable processor. With excellent compilers, but most importantly - low level access that you don't need to rely on proprietary compiler engineers (like TPU ones) and anyone can develop something like Flash Attention. And as a side note: while a Transformer might be mostly matrix multiplication, many other models are not.
If you had worked with ML, you'd know that this is not true. It's actually more like the opposite. It also has nothing to do with the chips themselves. Things don't magically work "because GPU", they work because manufacturers spend the time getting their drivers and ecosystems right. That's why for example noone is using AMD GPUs for ML, despite them offering more compute per dollar on paper. Getting the software stack to the point of Nvidia/CUDA, where things really do "just work", is an enormous undertaking. And as someone who has been researching ML for more than a decade now, I can tell you Nvidia also didn't get these things right in the beginning. That's the reason why they have no real competition today (and still won't for quite some time).
> That's why for example noone is using AMD GPUs for ML
You're right, they are behind, but to say that nobody is using it, is not truthful. AMD HPC clusters are being used [0] and [1] for AI/ML.
The larger issue is that AMD has only been building HPC clusters for the last period of time. Now, with the release of MI300x, we have Azure and Oracle coming online with them now. Disclosure, my business is also building a MI300x super computer as well, with the express goal of enabling more access to developers.
>AMD HPC clusters are being used [0] and [1] for AI/ML.
Funny how you can immediately tell when the business people made these decisions and not the tech people. This is exactly what I would have expected from an organization like the Navy. On paper it does sound great and the Navy bean counters probably loved this. But they are in for a rough awakening.
The best I can say is that my thoughts and prayers go to the ML engineers who will actually have to deal with this. Those companies literally couldn't pay me enough to put up with it. They will likely only attract people who care about the salary and the position instead of getting things done. I've seen it with other colleagues before. These numbers of yours are completely worthless without someone who is willing to put in 5 times the work for the same or worse results.
People choose jobs and tools for a variety of reasons. I don't feel the need to cast judgement on them over it.
The numbers I gave aren't worthless, nor does it take 5x the amount of work. I also don't think that going with a single source for hardware for all of AI is very smart either, especially given the fact that there are serious supply shortages from that single vendor. No fortune 100 would put all their eggs in one basket and even if it was 5x the work, it is worth it.
Hey, this is a good comment. I've only toyed with ML stuff, but I've done a lot with GPUs. I hope you can find my "step back" perspective as valuable I find your up close one.
My chief mistake in the above comment was using "TPU", as that's Google's branding. I probably should've used "AI focused co-processor". I'm not talking exclusively about Google's foray into the space, especially as I haven't used TPUs.
My list of things to ditch on GPUs doesn't include cores. My point there is that there's a bunch of components that are needed for graphics programming that are entirely pointless for AI workloads, both inside the core's ALU and as larger board components. The hardware components needed for AI seem relatively well understood at this point (though that's possible to change with some other innovation).
Put another way, my point is this: Historically, the high end GPU market was mostly limited to scientific computing, enthusiast gaming, and some varied professional workloads. Nvidia has long been king here, but with relatively little attempt by others at competition. ML was added to that list in the last decade, but with some few exceptions (Google's TPU), the people who could move into the space haven't. Then chatGPT happened, investment in AI has gone crazy, and suddenly Nvidia is one of the most valuable companies in the world.
However, The list of companies who have proven they can make all the essential components (in my list in the grandparent) isn't large, but it's also not just Nvidia. Basically every computing device with a screen has some measure of GPU components, and now everyone is paying attention to AI. So I think within a few years Nvidia's market leadership will be challenged, and they certainly won't be the only supplier of top of the line AI co-processors by the end of the decade. Whether first mover advantage will keep them in first place, time will tell.
It's been talked to death but non-CUDA implementations have their challenges regardless of use case. That's what first-mover advantage and > 15 years of investment by Nvidia in their overall ecosystem will do for you.
But support for production serving of inference workloads outside of CUDA is universally dismal. This is where I spend most of my time and compared to CUDA anything else is non-existent or a non-starter unless you're all-in on packaged API driven Google/Amazon/etc tooling utilizing their TPUs (or whatever). The most significant vendor/cloud lock-in I think I've ever seen.
Efficient and high-scale serving of inference workloads is THE thing you need to do to serve customers and actually have a chance at ever making any money. It's shocking to me that Nvidia/CUDA has a complete stranglehold on this obvious use case.
A great summary of how unserious NVIDIA's competitors are is how long it took AMD's flagship consumer/retail GPU, the 7900 XT[X], to gain ROCm support.
{kind=link}
My anecdotal experience from 20y of bodybuilding and doing ~3 cuts a year: for cutting, I tried IF, 6 meals a day, low fat, low carb, high fat true keto, balanced... everything works. And works equally well - this is backed by numerous studies. The only difference is the impact on health parameters (different will get worse on low fat vs high fat), satiety, and how easy it is for someone to sustain the diet and stay in a deficit. This will depend on the lifestyle and personal preferences. So my preferred way to cut is high protein, low carb, essential fats, a ton of fiber. When building muscle I go high everything but balanced.
Anything else and more is sectarianism and people bragging about their choices not having verified their true claimed efficacy or benefits.