pyspider comes from a vertical search engine project. we have two issues:
- 100+ websites, they may change the template or down sometime.
We need a dashboard to monitor the changes and the fails.
- update in 5 minutes, when the website updated, we need follow that in 5 minutes.
We are using a update time from index(list) page to tell the changed pages.
And pages should been updated after about 30 days in case of we missed something.
A powerful scheduler is needed.
obviously, I hadn't got the right way to do so with scrapy. I'm not very familiar with scrapy. So I can't say something pyspider can do but scrapy not.
And yes for centralized queue which is in scheduler. It's designed to satisfy about 10-100 million urls for each project.
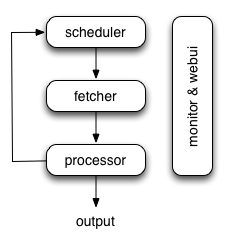
scheduler, fetchers, processors are connected with rabbitmq(alternatively). Only one scheduler is allowed. But you can run multiple fetchers or processors as needed.
Will it be a good fit if I, running on a hundred servers, need to scrape just the home page of a million sites? No analysis of the pages, that is done later.
There is a phantomjs fetcher that can render the page as WebKit did.
Furthermore, you can have some JavaScript running before/after page loaded to simulate a mouse click.
Yes, the scheduler, fetcher, processor is stand alone here, they are running in different process. But they are sharing some common libs.
I haven't made a decision how to put them into a single package, and running together.
pyspider is running original python code, something like portia is a code generator (Apologize if I'm wrong, I have not use it). So it can been made as another WebUI module.
But for flexible, I have no idea how to make it right currently. So, We have a css selector helper, but no plan for a complete tool.
I am not trying to offend you, but I really don't understand when someone says "yes and no". I hear it more and more these days. Is this becoming a cliche? It can be "yes" or "no", not both together. "yes and no" is "no" for me.
Don't know about other languages, but in german this phrase is pretty common when there is no clear yes or no answer. Like "yes to some extend but not completely"
{kind=link}