On Mac Safari, holding shift and using the magic mouse to scroll up or down reverses the zoom direction.
This is both right (Shift-X is the reverse of X due to convention)
But is also wrong (Shift-Scroll is the macOS gesture for scrolling on maps where Scroll alone doesn't zoom in or out).
TLDR: I really wish Apple would adopt the "scroll up to zoom in" convention used by the rest of the free world.
I don't know if there's a named law, but the word for not knowing and believing that something remembered is a novel idea is "cryptomnesia".
Knowing that you know something by teaching is Feynman's method of understanding. Basically, on scanning, I don't particularly disagree with the content of the post. However, treating these things (many of which regularly show up here on HN) as being due to "14 years at Google" is a little misplaced.
But, hey, it's 2026, CES is starting, and the hyperbole will just keep rocketing up and out.
Off by 10+1. Someone who graduated college in 2000 = 25 + 22 (4 years of college from 18) = 47, not 57, and not anywhere close to the retirement age. It might be pedantry, but the original comment should have said 1990, not 2000.
Turns out that under the USA Code of Federal Regulations, there's a pretty big exemption to IRB for research on pedagogy:
CFR 46.104 (Exempt Research):
46.104.d.1
"Research, conducted in established or commonly accepted educational settings, that specifically involves normal educational practices that are not likely to adversely impact students' opportunity to learn required educational content or the assessment of educators who provide instruction. This includes most research on regular and special education instructional strategies, and research on the effectiveness of or the comparison among instructional techniques, curricula, or classroom management methods."
I'm afraid you misunderstand what it means to be "exempt" under the IRB. It doesn't mean "you don't have to talk to the IRB", it means "there's a little less oversight but you still need to file all the paperwork". Here's one university's explanation[1]:
> Exempt human subjects research is a specific sub-set of “research involving human subjects” that does not require ongoing IRB oversight. Research can qualify for an exemption if it is no more than minimal risk and all of the research procedures fit within one or more of the exemption categories in the federal IRB regulations. *Studies that qualify for exemption must be submitted to the IRB for review before starting the research. Pursuant to NU policy, investigators do not make their own determination as to whether a research study qualifies for an exemption — the IRB issues exemption determinations.* There is not a separate IRB application form for studies that could qualify for exemption – the appropriate protocol template for human subjects research should be filled out and submitted to the IRB in the eIRB+ system.
Most of my research is in CS Education, and I have often been able to get my studies under the Exempt status. This makes my life easier, but it's still a long arduous paperwork process. Often there are a few rounds to get the protocol right. I usually have to plan studies a whole semester in advance. The IRB does NOT like it when you decide, "Hey I just realized I collected a bunch of data, I wonder what I can do with it?" They want you to have a plan going in.
The CFR is pretty clear, and I have experience with this (being both an IRB reviewer, faculty member, and researcher). When it says "is exempt" it means "is exempt".
Imagine otherwise: a teacher who wants change their final exam from a 50 item Scantron using A-D choices, to a 50 item Scantron using A-E choices, because they think having 5 choices per item is better than 4, would need to ask for IRB approval. That's not feasible, and is not what happens in the real world of academia.
It is true that local IRBs may try to add additional rules, but the NU policy you quote talks about "studies". Most IRBs would disagree that "professor playing around with grading procedures and policies" constitutes a "study".
It would be presumed exempted.
Are you a teacher or a student? If you are a teacher, you have wide latitude that a student researcher does not.
Also, if you are a teacher, doing "research about your teaching style", that's exempted.
By contrast, if you are a student, or a teacher "doing research" that's probably not exempt and must go through IRB.
You would be correct, except that this is a published blog post. It may not be in an academic journal, but this person has still conducted human subjects research that led to a published artifact. It was just "playing around" until they started posting their students' (summarized, anonymized) data to the internet.
10G Ethernet would only marginally speed things up based on past experience with llama RPC; latency is much more helpful but still, diminishing returns with that layer split.
Possibly RDMA over thunderbolt. But for RoCE (RDMA over converged Ethernet) obviously not because it's sitting on top of Ethernet. Now that could still have a higher throughput when you factor in CPU time to run custom protocols that smart NICs could just DMA instead, but the overhead is still definitively higher
I really hope the user was running Time Machine - in default settings, Time Machine does hourly snapshot backups of your whole Mac. Restoring is super easy.
There is something wrong with this article, possibly just copyediting mistakes but it makes me question the whole thing.
For example, check out this mess:
> “Unfortunately, there is one significant issue with the aforementioned data: schooling. Seeing as the majority of work to date includes only aggregate data, it is impossible to account. The first concerns small N: seeing as most publish studies only include a handful of TRA data, there is a lot of room for error and over.
Unfortunately, there is a largely unaccounted for confound in this aggregate data which may make generalized analysis questionable: schooling.”
Good catch. Additionally, one of the authors on this is just a student at UWisc, and the other author is also not a professional researcher but instead an author of popular books.
This is not an ad-hominum, but does put into question the statistical training backgrounds of both of these authors to accurate assess the data.
If not ad-hominum, what is it then? I mean, you did not provide any substantiated reason why would their research be false but you went straight to pin-point their experience, or lack thereof.
FWIW I find this research to align on my thoughts about the IQ - IQ is not a constant but a function of multiple variables, where one of the variables is most likely an education.
For instance, I am pretty sure that drilling through the abstract mathematical and hard engineering problems to some extent during the high-school but much more during and after the University, develops your brain in such a way that you become not only more knowledgeable in terms of memorizing things but develops your brain so that it can reason about and anticipate things that you couldn't possibly do before.
> but does put into question the statistical training backgrounds
This is true of virtually all university research. Statistics is far more nuanced than what a semester course can teach you. And the incentives to publish can cause bad actors to use poorly defined surveys or p hack or whatever.
> and the other author is also not a professional researcher but instead an author of popular books.
This makes the awkward wording even more confusing. I don't understand how a professional author who appears to speak English very well would write so poorly and not follow up with edits.
The language is consistent with ESL writing, in my experience.
The strange thing is that the corresponding author and the co-author appear to be english speakers, as far as I can tell. I googled the primary author and found a YouTube channel where someone by the same name speaks clearly about neuroscience. Maybe I'm looking at another person with the same name and middle initial who also happens to speak about neuroscience and brain development?
Why not do an empirical A/B test: Set up two honeypots (or perhaps 2000 for statistical significance). A gets zero updates, B gets all updates immediately. See which ones get pwned faster.
I am baffled by Apple's incompetence here. In the past years I've seen:
* iTunes/Music app randomly reassign my Album artwork, with different (incorrect) art showing up on different devices!
* Reminders app: shared reminder lists can end up with the name of a different list
* Ghost photos that are deleted from my phone, and come back later.
* Maps, when I say "navigate to $friend" set a route that ended in my own driveway.
To me, these bugs suggest a fundamental design flaw, perhaps they are using a simple Integer as an index rather than a UUID?
Or maybe the database schema are solid, but there's some sort of race condition in their synchronization frameworks and the data is getting scrambled in RAM?
Whatever it is, it's absolutely insane that in 2025 these kinds of bugs are happening.
I completely agree about there being a fundamental design flaw.
I still use Macs because data on a physical disk seems perfectly reliable, but I've been bitten by so many of these bugs in their apps. iCloud files completely disappear, then reappear a day later. Highlight a couple chapters of a PDF in Preview, then reopen the file and they're gone because iCloud thinks the older unhighlighted version is newer or something. Madness. I don't touch any of these Apple services/apps anymore.
There's very clearly a fundamental bug in whatever sync framework they seem to share across everything. It's bad enough to have data disappear entirely or deleted data reappear, but then when data shows up in the completely wrong place, and this has been happening for years and years and still isn't fixed... I don't know what to think.
You're right. There's no other word for it but "insane". They can engineer their A-series and M-series microchips, but it's been over a decade now and their sync is still fundamentally broken.
> There's no other word for it but "insane". They can engineer their A-series and M-series microchips
There are certainly other words for it. Lazy, anticompetitive, disinterested, any of those are more plausible than all of Apple being insane. They sold you a microchip that you knew you wanted, now they are beholden to little else. For over a decade, Apple didn't even offer the iOS APIs for third-parties to implement cloud storage. They know you need their software services, regardless of how shit they are.
Insanity would be a pretty satisfying explanation. Fickleness fits a lot better with Apple's track record though.
Apple's hardware is top class, but the software has always been lacking. The only time I've seen both in perfect synergy was when the iPod was released (and even then there was iTunes). Not even the iPhone reveal had that.
Apple stole my entire music library. I have had one library going back to the first release of iTunes on Windows (2003?) — thousands of songs, most of them CD rips.
I then subscribed to Apple Music and relied on its matching function. After switching from an Intel Mac to an M2 and redownloading my library from remote, it now believes that each and every song in my library are rented Apple Music copies. Even those it shows as having been added in 2003.
Some songs are missing; some go missing, then inexplicably come back months later. Worse: so far I have found around a dozen which have been replaced by different versions.
The thing is, in many cases, these products and teams are very siloed from each other. I suspect, having worked in one of these teams, that some of the issues comes from this siloing. Lessons learned aren't shared, and it can be difficult to build integrations.
* prompts in settings for adding an account recovery contact that never go away, even after months and months of successfully setting it up multiple times.
* OS account profile picture can barely stay associated with the most recently picked option. Happens for non-iCloud local accounts on Mac, happens when I change profile pictures on iOS for iCloud… weird.
* OS account update screens on iPad, iOS, and watchOS will forget that they are in the middle of updating if you navigate away from the settings screen. Thankfully, today they at least recover from it (it’s probably still happening in the background), but it takes several long seconds of spinning for the settings page to remember that it was doing an update two seconds ago before I navigated away from it.
* similar to your ghost pictures bug, deleting a large media file from a media player app moves it to recently deleted, but you can sometimes end up in situations where you can’t permanently delete the file, or it doesn’t show up anywhere but still takes up space. (Talking about 20GB-80GB file sizes where it makes a big difference on OS storage space)
Some of these bugs have been around for a VERY long time.
But the weird thing is I don’t see them in 3rd party apps.
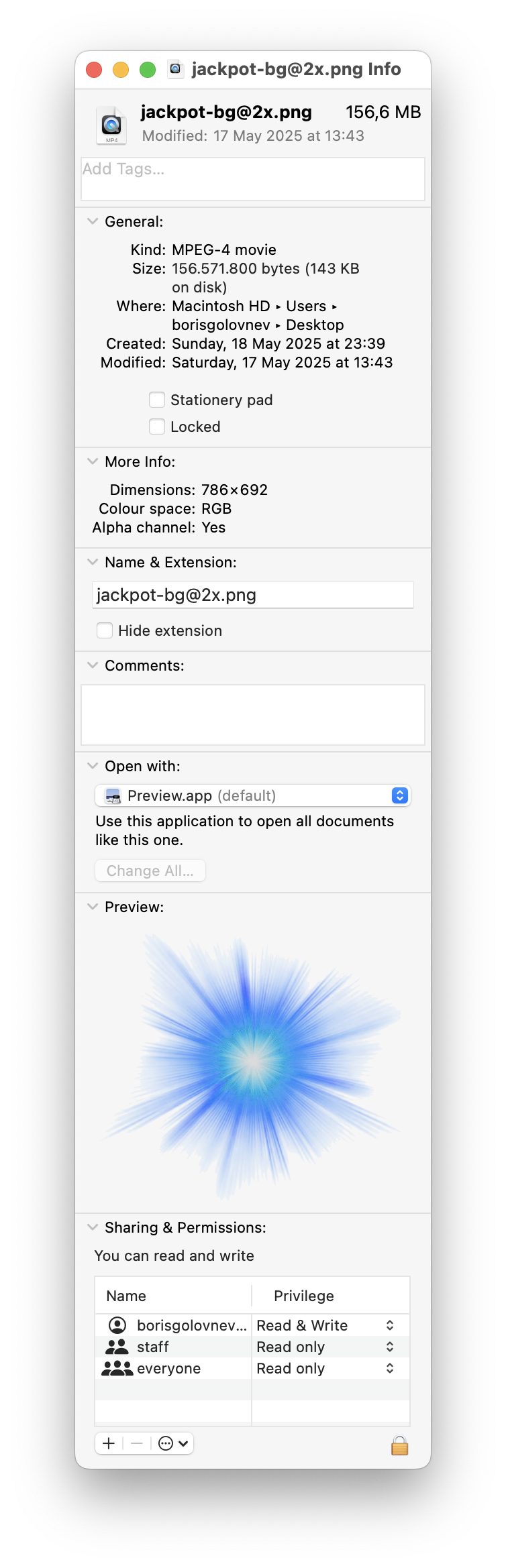
Finder being unable to show file information and instead showing something that looks like file information but is completely wrong is scary and sad. And it has been like this for months.
Like here, none of the data in the General part matches the actual file. More info is correct, Preview is correct, so I know I did in fact click the correct file.
http://bn5i3r.s3.amazonaws.com/Screenshot-2025-09-17-at-17-0...
Happens randomly so I don't know how to report this (and from experience I know that reporting bugs to Apple is completely useless).
Its probably a good thing in a way if someone learns this lesson in a lesser painful way. You need to manage your own files and backups and content. Data portabillity is the opposite of what they want and try to further abstract away until people dont even know what a file or folder is. Its so easy, you dont even have to lift a finger until you decide you want or need to leave. Thats when you realize its sometimes impossible to take it with you
Clipboard has been unstable on every OS (especially on Desktop - and I mean Linux, Windows and Mac), and I think part of the culprit is apps like Teams and Discord, if you Ctrl + C by mistake on an empty text box, IT COPIES THE EMPTY TEXT BOX effectively wiping your clipboard. It's the most irritating UX and it took me years to figure out. Always right click copy and right click paste, you'll notice it works 100% of the time as it used to.
That’s a really interesting solution to copy-pasting between devices, which is one of them features Apple has that I rely on a tonne even though it’s horribly unreliable. I wonder if anyone has a similarly clever way to copy from mobile to your computer.
KDE Connect provides some tight integration, including (optional) clipboard sharing, media player controls, features to do presentations, mouse and keyboard.
I use it as a remote control to adjust volume during movies from the phone to the computer playing them for instance.
Copying empty text is a configurable flag in some linux environments, at least, but I'm not sure if that behavior is faithfully preserved in teams / discord / etc as I've never really had it on.
On Linux you can just select the text and simply paste it using middle click. It works everywhere on Xorg, on some environments on Wayland. And it will only copy what you selected... everytime.
{kind=link}
This is both right (Shift-X is the reverse of X due to convention) But is also wrong (Shift-Scroll is the macOS gesture for scrolling on maps where Scroll alone doesn't zoom in or out).
TLDR: I really wish Apple would adopt the "scroll up to zoom in" convention used by the rest of the free world.
reply