It actually works with openCL. I had to do a few changes to make it work on MacOSX, but I beleive the language barrier and the fact that his project is in a flux and I came out of the blue caused these few lines to not merge. Please see my fork of his dev branch, that works with 9.5dev: https://github.com/pg-strom/devel/pull/144
correction: those changes to compile on macox did get pulled so https://github.com/pg-strom/devel should build with openCL on your mac to link with 9.5dev.
edit:
His slideshare page http://www.slideshare.net/kaigai has even more recent presentations. I've only had time to skim much of slides, but it seems he's flip-flopped a couple of times between OpenCL and CUDA
If I simplify this & other news to the statement, “our GPUs are Turing-complete”, then one question seems to follow logically: When will our CPUs become multi-core on the scale of a GPU? Or is that a stupid question that only looks logical?
If you look at computing history, you'll find many parallels over the years. For example the Floating Point Unit started out as a co-processor, this massive unit you put next to your mainframe and plugged in.
Over several iterations it went from external, to part of the same chasis, then on to an expansion card, before eventually making its way on-die, until by the time the first Pentium came out, the thought of having a CPU without an FPU was preposterous (I remember kicking myself for having bought the 486sx 25 instead of the 486dx 25 that had the integrated FPU.)
We've seen a similar thing with GPUs. The original 3DFX was this card you had to use a loopthrough video connector with because it had no 2D capabilities. Slowly it got integrated with 2D capabilities, and then grew to be GPUs, before starting to transition onto the motherboard, before eventually making its way into Intel chips. I don't believe you can buy an i or Xeon series Intel chip these days that doesn't have a GPU integrated in it. It's not the most powerful thing, but it is usable via OpenCL.
Latency is a huge driver for most of that integration.
GPU's are an odd case because they need a lot of internal bandwidth and are minimally impacted by latency making external cards far more viable. And unlike sound cards they can easily eat more or less unlimited FLOPS.
GPU's were designed for a problem that is easy to make massively parallel. If we tried to make our CPUs like GPUs we'd end up with something not very useful for most of what we do.
Most CPU's these days already have a GPUs worth of core's onboard. So, about 5 years ago to answer your question?
The other answer to the rest of your question is probably about when the majority of software starts running entirely on the GPU.
So, let's take the Gefore GTX 980, a pretty heavyweight GPU right now. Tech specs say it has 2048 "CUDA cores" whatever that means. Well, a cuda processor is actually a SIMD core, and in this case, I think it's actually a 32 element wide SIMD core. Which makes the 980 actually contain 64 cores (Is that actually the number of cores, or just instruction schedulers)... Which is still a bit, but you can get a modern 18-core Xeon, which only puts us off in about a factor of 4 in core count.
So, the main reason for the gap at this point is functionality. The CPU does a lot of things that the GPU doesn't, and that all takes silicon that the GPU uses for extra ALU. Things like legacy instruction decode, instruction reordering, deep branch prediction pipelines, and a giant bucket of instructions that just aren't needed on the GPU, but many modern CPU targeted software really relies on for performance. And really, if the average piece of software properly took advantage of many-cores, we'd all have a ton of cores in our CPU. It much easier for CPU designers to bolt on another core than dealing with complicated branch prediction invalidation logic, or any other trick to make crappy code run well.
In all I think the gap is smaller than you think, and we will continue to see convergence, particularly as engineers start writing code better suited to the GPU, and rely less on the CPUs fancy performance tricks. But in all, there are some fundamental differences that make complete crossover tricky.
There are tradeoffs in design both between few and many cores and between optimizing cores for throughput versus latency and between optimizing for DSP-like code with predictable memory access and control patterns and business logic with lots of pointer chasing.
It's actually pretty easy to have CPUs on the scale of a GPU right now. A 15 core Xeon can put out 600 gigFlops of compute so you just need 10 of them to equal one Titan X. Now, those 10 Xeons take much more silicon area and power to generate that processing power than the Xeons but that's because they have all these branch predictors and out of order execution engines and such that mean that their performance falls of much more slowly as you throw them at problems that are more complicated than DSPish code.
FYI, Intel tried that with the aborted "Larrabee" project, so not a stupid question at all. It ended up being a too hard problem to solve. They reused the technology to make the Xeon Phi coprocessors which are basically PCIE computing "accelerators"; for a class of workload, and if you're willing to rewrite your code, they are faster and more power efficient than GPUs.
Although there are many companies trying to crack this many-core problem (Kalray, AppliedMicro, Adapteva, Cavium, Tilera), I'm not aware of any "successful" solution.
Reason #1: Many (most?) computational tasks are not easily parallelizable. The canonical analogy is making a baby:
- One woman can make a baby in nine months
- Nine women can make nine babies in nine months
- But nine women can't make a baby in one month
Each step of fetal development depends on the previous step. For a given single baby, you can't have one woman working on step #49 while another woman works on step #17.
A lot of computational tasks are similar. Think of the Fibonacci sequence: the computation of each number depends on previous results.
Reason #2: The overhead of communication and coordination. If you split up a task amongst 32 cores, those cores need to communicate with the parent process and perhaps with each other as well. This eats into your transistor budget.
Reason #3: Resource contention. It's nice that you can split up your memory bandwidth-intense task across 128 cores, but if most of those cores are just sitting around and idling because of memory bandwidth contention issues, you haven't gained anything.
Reason #4: It's hard. Programmers struggle to write parallel code. Some tools make it much easier of course.
Pedantic comment: you don't need the previous results to compute the nth fibonacci number; the recurrence has a closed form solution. It is not constant time to compute (unless you assume constant time, infinite precision arithmetic) in practice, but it can certainly be done without the prior terms.
The rest of this post is on point, though. Serialization bottlenecks (Amdahl's Law) prevent a lot of optimizations from making meaningful dents in real workloads.
GPUs were designed to run thousands of threads, CPUs to run only a few of them.
CPU cores do branch predictions and instructions reordering to save latency. GPU cores do not. When they need to wait, they instead pause the thread and resume some other thread on the same core.
GPUs were designed to execute the same code on many threads, CPUs to ran arbitrary code on each thread.
Each CPU core has instruction fetch, instruction decode, and branching modules. For GPU cores, there’s only one fetch/decode/branch modules per many cores (32 on nVidia).
This 2 factors are among the reasons why we have 4 cores in $200 mid-range desktop CPUs, and 1024 cores in $200 mid-range desktop GPU.
What NVidia calls a core and what Intel calls a core really aren't comparable. If you go by the Intel definition which is more or less "Capable of independantly issuing an instruction" then you might find 15 cores in a Xeon versus 24 SMM "cores" in the top NVidia chip. Going by the NVidia definition which is more or less "Things that can execute instructions from a queue" NVidia would have 3072 cores in it's top chip and Intel would have 120 cores or "execution ports" as they call them.
That's just a bunch of standard (ARM currently) boxes networked together with a special backplane that allows for DMA between different servers. Not really comparable to a GPU.
I was under the impression that to get the speed benefits of CUDA you had to coalesce memory access. Does anyone know how nested loop joins can use indexes without messing up the memory access coalescing?
What would be nice is a document which would explain how to convert queries to use the GPU as its best, a document which would not require its reader to be a GPU geek nor a Postgresql expert. A technology can only succeed when the average programmer can use it without doing much errors, or can find quickly a solution using google.
A technology can only succeed when the average programmer can use it without doing much errors, or can find quickly a solution using google.
I don't think that's true. A technology might only be able to become a mainstream product if the average programmer can use it, but there are a lot of niche products that most programmers will never use. That doesn't mean those technologies haven't succeeded.
If you only ever use things that are similar to the things you already know (e.g. things you can use without making errors) then you will only make very slow progress as a developer. You'll always be avoiding the things that are different to your existing skill set. Sometimes, if you want to use something radically different to what you already use, you have to put in the effort and learn something that is hard. You can't expect the technology to come to you.
>how to convert queries to use the GPU as its best, a document which would not require its reader to be a GPU geek nor a Postgresql expert
Uh, isn't this like asking "how do I do calculus without being a calculus geek"? I mean it's specialized - how do you get around being a "GPU geek" if you're coding for a GPU "at its best"?
A technology can only succeed when the average programmer can use it without doing much errors, or can find quickly a solution using google.
Well, if you want to be successful like PHP, sure that's true.
For me, I'd sooner sue something which works well when used by a person who's taken the time to learn what they're doing. It's not important to me what a person of median skill and effort can accomplish: there's only so many things the average engineer is going to be able to learn, for whatever reason.
I like it that there's lots of robust criticism in the comments, but I think people are maybe being a little pessimistic. This is pretty exciting, isn't it? GPUs have sped things up in a lot of technologies, and I'm intrigued to see what they can do for databases.
It's all in-memory, so not I/O-bound. Rows are processed in parallel with PGStrom (in 15MB chunks), while Postgres does it sequentially in one thread. Apparently moving the data around is fast enough not to matter.
Think of GPUs as excelling at MapReduce, either they do the same operation on many data points or they reduce the data by combining them in an aggregate. The query listed is taking an avg on a variable # of joins. Each join is doing a sequential search which can be a lot faster if you can process this in parallel and then when you find the right data you want to aggregate, you are then doing the aggregate. Both are incredibly faster in parallel.
The gpu was designed so you can, lets say, move all vertices in a character's body 1 inch forward, you would need to process this one translation for potentially thousands of vertices. It was also designed to do bitmap operations very quickly where you need to get the same image, but smaller so the GPU would combine nearby pixels to provide a good heuristic of what that same image would look like further away.
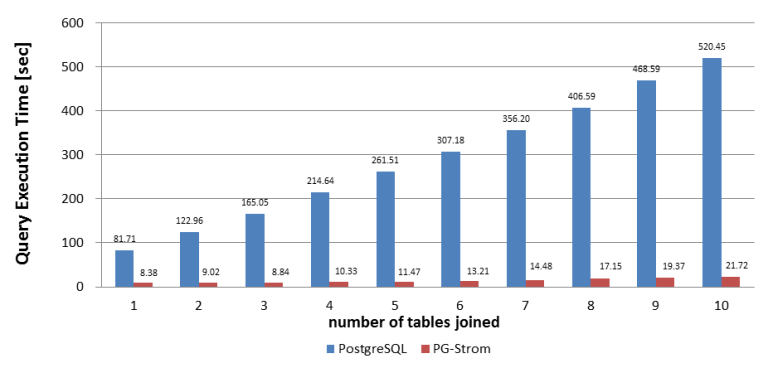
Joining a large number of tables is a sweet spot for PGStrom where in which there are a lot of parallelizable computations. For a lot of queries it can actually be slower.
Hopefully the query planner would choose whether or not to use PGStrom for a specific query.
Many interesting queries in normalised databases involve a lot of joins. In a BCNF database most interesting queries use 3 or more joins. Whether or not I believe the microbenchmarks is another thing :)
And the use of GPL license which means that this code cannot be contributed upstream to PostgreSQL itself because it uses a more liberal license: http://opensource.org/licenses/postgresql.
Unfortunately most of the discussion seems to be going down in Japanese.
That said if you don't mind just reading diffs you can get an idea of the state of the project by taking a gander at their github: https://github.com/pg-strom/devel
Probably queries that have a lot of brute-force comparisons involving full table scans. "select foo from bar where baz > 30" with no index, for example.
(Source: I've done a fair bit of experimentation in GPU queries in the domain of CSS selector matching.)
Interesting thought. I was assuming that the impressive performance figures based on joining 10 tables together would be making use of indexes, because with full table scans it might be difficult to keep the GPUs fed with data.
In the article linked, they show a multi-way join on integer keys, which is able to leverage accelerated integer comparison (presumably.) I'd imagine a whole range of GIS queries also have the potential to be sped up by GPU offloading.
{kind=link}
correction: those changes to compile on macox did get pulled so https://github.com/pg-strom/devel should build with openCL on your mac to link with 9.5dev.