I did something like this when I was a kid, in QuickBasic. Not as sophisticated - it would just randomly create, append to, and delete files.
I tested it on floppy disks - if you let it run for a while, the remaining free space was so fragmented it was almost unusable. You could hear the poor floppy drive seeking like crazy just to open a tiny text file.
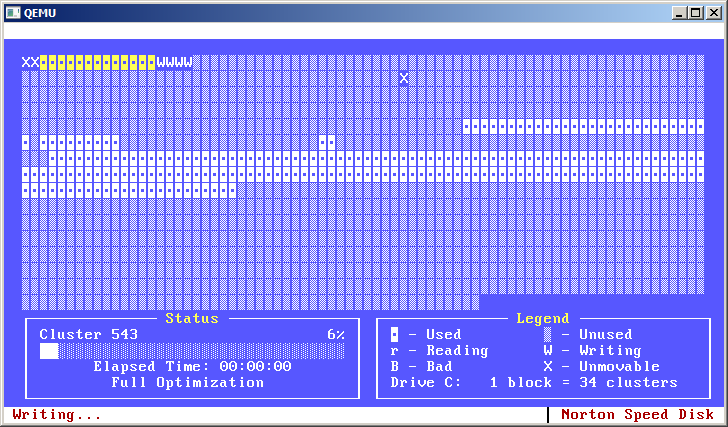
The fun part was defragmenting it afterwards - I miss the days of the graphical defrag that Norton and MS had.
My favorite ones would show you a grid representing all the clusters on the disk. You would see an open block for free space and a solid block for allocated space.
Then it would highlight a span of blocks to indicate reading.
Finally it would write those clusters elsewhere, indicating so with a different color.
Neat. I had one for DOS too that would go left-to-right instead of top-to-bottom, but I don't remember if it was a Norton tool or something else. It was mesmerizing to me as a kid to watch data moving around on the hard drive and the computer magically getting faster.
Defraggler is the only one I can think of off the top of my head. I love that kind of interactivity in applications, so much better than a loading bar.
I've usually done intentional fragmentation by filling disk with small files and deleting those while growing a new file to claim those blocks. Works basically with every file system.
Some examples where I've used such method.
On the other hand, your worst fragmented case still gets ~200MB/s with a random read, which is around the best case with a sequential read for most HDDs today. A 4k random read on a HDD will be 1-2MB/s at most.
Relatively speaking the SSD slows down to ~50% of its max speed with fragmentation, but the HDD will be down to around 1%. So fragmentation affects SSDs somewhat, but HDDs are affected much more severely.
(Which SSD was it, and how was the test setup? That's important for comparison purposes, as the layout of the filesystem blocks and how they correspond to the NAND eraseblocks/pages has a huge effect on what fragmentation will do.)
Embedded as in "32-bit ARM running Linux", or "8-bit microcontroller"? Either way, as someone who has written a FAT driver for embedded systems in the later category, that looks like it's far more code than it needs to be. Full read/write functionality can be done in approximately 800 (Z80) machine instructions. FAT is a linked list, and if you look at it that way, it doesn't take much code to manipulate one.
Append = find an empty cluster and link it into the chain for the file, then write into it. Create is similar except you start with a empty chain and also add an entry to the directory (which is like writing/appending to a file, because directories are files.)
When allocating next clusters you can reduce fragmentation significantly over the dumb "first fit" strategy if you scan the FAT to find contiguous free clusters and apply a next/best/worst fit. Even better if you add an API to allow tuning the amount of "gap" after a file when creating it, based on knowledge of how much it may expand in the future.
I believe that with good tuning and allocation heuristics, FAT32 can outperform the far more complex filesystems (ext*, NTFS, etc.) widely believed to be superior. One idea I've never gotten around to testing out is to modify the Linux FAT driver and do some benchmarking.
I believe that with good tuning and allocation
heuristics, FAT32 can outperform the far more complex
filesystems (ext*, NTFS, etc.) widely believed to be
superior. One idea I've never gotten around to testing
out is to modify the Linux FAT driver and do some
benchmarking.
I don't understand. Has anybody ever claimed that the more complex alternatives were actually faster?
NTFS and other filesystems that followed FAT32 are "superior" because they support things like journaling and more robust permissions... things that unavoidably incur (a least) a small performance hit.
It is targeted to ARM uC's and also works on AVRs with enough RAM and program space (yes I've tested it). Write support requires a significant amount of RAM; I think about six 512-byte blocks. When compiled in read-only mode, it should need no more than two.
One reason for the RAM needs is that I use a block cache and I take care do to "atomically" certain related operations (on the block cache level). These are things like marking a cluster as allocated, decrementing the number of free clusters in FsInfo, and linking the allocated cluster to the end of a chain. These things require multiple blocks to all be present in the block cache at the same time.
I suppose the asynchronous design also contributes to the code and RAM size (though I did not actually measure the code size or compare it to other drivers). It may look like more that it really compiles to. Anyway would be very surprised if you show me another asynchronous driver - I couldn't find any!
Also consider that my code supports VFATs (decoding only, file creation is not supported anyway).
The design is intentional, I have sacrificed some RAM/program size for asynchronous operation and better reliability in case of random write failures (because of the block cache, all writes can reliably be retried later, avoiding corruption as long as they eventually complete).
Update: I estimate the code compiles to about 10kB with gcc for Coretex-M3 using -Os. This is certainly within limits of most ARM uCs and many AVRs.
You got further than me. I got stuck trying to find the files themselves in a disk image. I think the code is in my junkcode repo on GitHub. My end goal is ext4, and then on to a FAT32 over USB gadget hack to bring back mass storage support to Android.
What did you use as your main source of documentation while developing?
Request for benchmarks: I'd like to see what effect this has on, say, WinXP boot time, or maybe some database benchmark. In fact, there's no need to get so fancy. Let's see how much this slows down computing a file's checksum, or maybe copying a file.
It's pretty horrendously bad on spinning rust - you get very, very close to 100% fragmentation, so the disk has to seek for each cluster. A lower bound average on seek time is probably something like 4ms, so your max transfer rate is going to be limited to 125 * cluster size. Depending on the disk size[0] the cluster size may be up to 32KB, so we're looking at maybe 4MB/sec best case. I'd guesstimate it'd increase boot time by somewhere between 10x and 40x.
In theory, you could make the disk performance even worse by alternating between the beginning and end of the disk, though you may need to do a little tweaking to ensure this doesn't inadvertently allow read-ahead to help.
That might not work given that the drive might have more than one platter. You'd probably want to know how many heads the drive has to determine how to stripe it in the most inconvenient way possible. I think going beginning to middle on a single platter and back for each file would be the best way to get the worst performance for each file. That'll make sure it has to seek for each subsequent block and it can't inadvertently get read-ahead since it has to back track all the time, and the separation should be far enough that it won't get it on the in order blocks either.
EDIT:
Just realized that I don't think this can be done through normal means. I think it'd need a pathological FAT file system driver to do it, and you'd have to build the image ahead of time to do it.
"Some bands of old-time hackers figured out how to induce disk-accessing patterns that would do this to particular drive models and held disk-drive races."
You might assume that it would have no effect, but an SSD reads data in a block. If the size of each fragment is smaller than a block then it will definitely slow it down.
But it depends on how large a block is on the SSD.
I think SSDs call them pages. Some brief googling seems to indicate that 16KB is a common page size, so if the cluster size is also 16KB it's probably not too bad.
Having been out of the FAT32 disk environment for a while, is fragmentation determined by non contiguous sectors on the drive? Do the methods reading data from the drives consider the number of heads/platters involved for performance gains? A file would not need to be contiguous necessarily per platter but some logic employed would map it to where following sectors would pass under a drive head at the same time.
Granted that would not work out for SSD, but I know next to nothing on their addressing
>Do the methods reading data from the drives consider the number of heads/platters involved for performance gains?
In general no, at least not since the early 80s. Although you still hear about cylinders, heads, and sectors, spinning hard drives have effectively been a black box to OSes for 30 years and will internally remap sectors wherever they feel like it (and lie about it if you ask them).
The result is that while you can be reasonably confident that sector 33566 is followed by sector 33567 and reading both will not involve seeking, things like reading the whole cylinders at a time are not worth the effort since you don't know where the sectors are.
I can see it used to test defragmentation programs. Fragment the disk into random pieces and then run your defrag program on it and see how long it takes to organize it.
Probably fail spectacularly, as it seems to make modifications to the FAT32 data structures directly. A more generic fragmenter might interact with a file system via pathological file access patterns, but this doesn’t take that approach.
Empty comments can be ok if they're positive. [...] What we especially discourage are comments that are empty and negative—comments that are mere name-calling.
Any positive comment is fine, unless you are retorting to a negative one in which case you need to explain more.
If making a negative comment you should explain, i.e. "I think this is bad because ..." rather than "This is bad.". If you have a valid point you are helping by raising it.
Similarly when retorting to a negative point with a positive view, "I disagree because ... " is good but just "You are wrong." simply unhelpful noise.
So feel free to provide positive encouragement when you think something is awesome!
{kind=link}
I tested it on floppy disks - if you let it run for a while, the remaining free space was so fragmented it was almost unusable. You could hear the poor floppy drive seeking like crazy just to open a tiny text file.
The fun part was defragmenting it afterwards - I miss the days of the graphical defrag that Norton and MS had.