Can someone enlighten me on what is the bottleneck for the transfer speed from hardware point. Is it the material used in the wire, or the transistors or some other thing? And, also since the transfer speed is continuously increasing, what are the improvements in the hardware over, say, last 10 years.
PCIe signals are generated by transceivers -- devices within chips that are specialized in signal conditioning e.g echo cancelling, emphasis/de-emphasis, dynamic impedance matching. These transceivers and the analog and digital techniques they implement get better with time. This is easily measurable by looking at the Bit Error Rate of data or by looking at eye diagrams (see slide 15). As data rates increase things like drive strengths, impedance mismatches, and a number of other properties of silicon will "close the eye" meaning the transmitted "0"s and "1"s are not different enough for them to be distinguished by a receiver enough of the time to successfully decode a packet. (PCIe is packet based, it's surprisingly somewhat similar to Ethernet). But essentially as our understanding and processes for manufacturing semiconductor devices increase, we're able to "open the eye" more, at which point the industry decides to increase data rates.
The TL;DR is that there's no silver bullet but lots of lead bullets. The big gains in PCIe from generation to generation are the result of accumulating lots of smaller gains in other places.
It helps that this isn't happening just for PCIe; there's lots of breakthroughs that benefit (and may have originated with) other high speed links.
The nature of problems is different, but fundamentally the two questions of "how to distinguish between 1 and 0 in the presence of noise" and "can the reciever and transmitter change state fast enough" apply.
Optical PCIe would be hugely handicapped by lack of a standard optical PCB construction method. You'd have to print waveguides onto the PCB. And then it stops working if you get dust in the socket.
Eventually yes, we can expect to see optical in desktops. Fiber connections are "better" but also much more expensive. The price should eventually come down as volumes increase. The main delaying factor is that copper is still good enough.
Multimedia is the driving force behind increased data usage, and I think we'll continue to need more throughput until we no longer get any benefits from higher resolutions (aka when we have substantially more pixels than rods and cones in our eyes). At the moment a phone with a 4K display saturates your eyes at any distance greater than 2 feet from your face. I think a 16x PCIe 4.0 link will likely provide more than enough bandwidth to generate fully immersive VR experiences, so the question then becomes... why and when will we need optical PCIe 5.0 to quadruple the datarate of PCIe 4.0...
I doubt this be true as HF is also modulated onto wire ... it's not the electron per se which wander but modulated HF. Sure, the carrying device is the electron buts it's not like a stream of water
Basically in the optical regime it won't be possible to propagate the E field in a conduit smaller than the wavelength. This is because a small conduit doesn't have the right boundary conditions to support fields (like trying to fit waves into a didgeridoo). So you're always going to have these massive, massive 1um structures compare to state-of-the-art nm scale semiconductors.
There are advantages of optics including that light moves faster than electrons (important for HPC where the figure of merit is latency in us between nodes, etc) and typically has higher fidelity. But the size of these structures is orders of magnitude larger than conventional semiconductors.
For PCIe with essentially baseband signaling and short links the bottleneck is in the transistors. It's in balancing the power requirements with cost/manufacturability of the link interface circuitry.
Both for power consumption and EMC reasons you want to minimize the maximum slew rate of the signal on the link (and thus the voltage) while on the same hand you need the voltage to stay large enough so that the receiver (which is for all purposes an analog design) can be implemented in widespread digital CMOS processes.
On the other hand both conventional parallel PCI and conventional (<=2.0) USB is limited by physical factors, which is in both cases the physical length of the link/bus and propagation velocity of the used wires (ie. speed of light divided by some small-ish constant). In both these standards this limit was intentionally introduced by Intel as cost reducing measure (in PCI's case this means that motherboard does not have to contain about 60 or so discrete resistors, real impact on cost of USB's implementation is somewhat questionable).
see nuand's response for some other interesting things; remember that it's baseband being transmitted over a bandwidth-limited channel, so equalizaiton and shaping of the pulses can significantly affect the throughput at a given BER.
Gen1 to Gen2 doubled the clock rate from 2.5 Gb to 5.0Gb. Gen2 to Gen3 increased the clock to 8 Gb, but also reduced the encoding overhead (from 8->10 to 128->130). There were some tweaks to the electrical level of things as well.
The electrical level isn't too magic, but there are still a lot of things that have to be tuned (the chapter on tuning in the Mindshare book on PCIe is about 100pp). For a commodity consumer bus, the relative reliability and speed of PCIe is kind of a miracle.
I'm not even remotely qualified to answer. But anyway, a charge moving down a wire makes a magnetic field. Sending little packets of 0 or 1 means there's a lot of little fields forming and collapsing around the wire. Motherboards are very small, so that field may be big enough to push up against the field of the next wire. That's the bottleneck. electrons in a conductor are crazy fast (i think a big fraction of c). The problem is sending enough of them that you get a meaningful signal, but not so many they interfere with their neighbors.
i'd guess the speed improvements come from much more precise timing and voltages, so you can get better guarantees about interference. if voltage is +/-10%, that field will be bigger, and interfere more. If the timings are +/-10% the field will be there when you don't want it to for the next signal.
Anyway, i'm sure there are much more knowledgeable people who can give you much better insight, but i think that's the physics 101 kinda answer.
Electrons in the conductor are actually kinda slow, it's on the order of millimeters or centimeters per second. It's the electromagnetic field propagation that is fast. That is, if you have a conductor cable, and apply voltage to it, the individual electrons inside it will proceed very slowly, but they all will start moving almost at the same time along the length of the wire.
PCIe uses differential signaling which should approximate AC so the electrons do not have a net movement down the wire at all, they more or less just wiggle back and forth. In reality there is likely some DC bias resulting net migration but a signal trace should be very low current; you're probably looking at electron drift velocities in the range of a 1-2 millimeters per hour if were to hand-wave a guess.
The way I like to visualize it is a line of billiard balls. You smack one end and all balls move a bit maybe one place over but the force (charge) moves through them moving the last ball. (Yes charge isn't force but can be made into a electromotive force EMF via inductors, coils etc.).
This is also a flawed analogy as the whole line of balls will still move slow. It's more like tiny balls on a loudspeaker. When you apply energy to the loudspeaker a pattern depending on energy on frequency will develop. It's more the speed at which this pattern can change rather the speed of movement of the individual balls
I'm thinking more along the lines of the spot where the balls were is a hole which the balls now occupy. The balls moving isn't the point I was trying to make it was the force from one end to the other. Not the greatest analogy I'll admit.
I'm not sure I understand what you're saying it almost sounds like you're referring to impedance.
Electrons move fast, though not nearly as fast of the speed of light. However, they don't go in a straight line. So if you mark a single electron and look at it from afar, you will see it move very slowly. But if you look closer, you will see it jiggling around with a slight bias toward a direction.
What goes at nearly the speed of light is the "message" that electrons should move a certain way. If you want an analogy, if you blow into a flute, even though the air is moving slowly, the sound travels fast.
You're both right. Individual electrons can move at high speeds (not c), but the overall flow of electrons in a wire is very slow. This happens because individuals move in random directions but the group has a slow push with the current.
Imagine people going to the shopping mall. Once in a while someone goes in and an hour or two later they come out the other door 10m away. But they travelled a lot more than 10m. You just didn't notice from outside.
> Individual electrons can move at high speeds (not c)
My memory may be off but as I recall the fermi speed in copper is only around 0.5% of c, rather far off. What does propagate at speeds on the order of c is the EM field, which is what most people are actually talking about when they think of electricity moving down a wire. But, it's still something around ~60% of c in a copper transmission line.
one possible way to think about it is to realize that all wires can be modeled as a transmission line (most accurately) with finite (but non-zero) R(esistance), L(inductance) and C(capacitance) components.
signals propagate over the transmission line as a wave by alternatively transferring energy from electric to the magnetic fields i.e. between L & C.
which is where the delay comes from...
it is fairly trivial to derive the wave propagation equation for the above model (assuming ofcourse that leakage conductance is zero). when considering lossy transmission lines though, things get quite complicated, but you can always (almost) get away with numerical techniques...
Not precisely sure wrt PCIe 4.0, but I'd speculate that bandwidth limits of copper on FR4 is surely one contributing factor, driven by a cost-sensitive consumer market. Cost-optimized interconnect solution may also be another.
Somewhat related, I've noticed comm tech tends to follow a fairly consistent evolution: new enabling material/process, improvements to interconnect, algorithm optimizations, repeat.
I'm no expert on pcie signaling, but I have some general idea,
problems are how to take care of the electromagnetic noise, that's why PCIe uses differential pairs wiring (both positive and negative wires are next to each other on board) instead of single-ended (single wire with common ground, negative) which were used in original PCI and PCI-X so the if some noise hits the first wire, same noise hits the second differential wire.
improvements in coding and decoding the signals with error correction also help recovering any errors caused by the electromagnetic noise.
Engadget reporting is so … underwhelming for a site with such financial backing.
The associated graphic is some random “Maximum PC Magazine via Getty Images“ thing. You mean they have nobody that can take a photo of the inside of a PC?
Then the source of the article is not PCI-SIG itself but a TechReport article: https://techreport.com/news/32064/pcie-4-0-specification-fin... which, frankly, is much more packed with info and deets. In contrast to Engadget there's a nice info-graphic showing the evolution in bandwidth over the years _plus_ there's a table with PCI specs 1 through 5. Finally the source there is PCI-SIG itself: http://pcisig.com/ and from there you can root through the spec revisions: http://pcisig.com/specifications/review-zone – being as someone else pointed out here "PCI Express Base Specification Revision 4.0, Version 0.9" and "PCI Express Base Specification Revision 5.0, Version 0.3"
I mean I do like Engadget, I've been going there years, but sometimes I ask myself why I do. Their tech event live-blogs are pretty damn decent I guess but I wish their articles had more meat on them like ArsTechica or AnandTech or TechReport or …
And they got the reason why manufacturers are going to move to PCIe 4 wrong. It has nothing to do with bottlenecks to video cards and everything to do with freeing up lanes. Pretty awful article.
> Engadget reporting is so … underwhelming for a site with such financial backing.
Yeah seriously. I couldn't believe this line:
"Backward compatibility means that manufacturers won't have to redesign old systems, either"
What does that even mean? That you can take a PCI-e 4.0 device and plug it into an older slot? Isn't that universally the case with computers, otherwise the bus would be called something else...
I'm unaware of any hardware vendor that puts effort into redesigning a product they're already shipping, if not to resolve a deficiency (and even then, it'd better be important to re-spin the hardware).
Though it may be that expensive high-end VR could be the luxury home theater of tomorrow, and you put 4 GPUs in a box to get 90FPS 8K seamless VR. Faster PCIe could be nice to have in that case.
Multi-GPU is kind of a meme for anything besides HPC. Graphical applications currently don't support it very well, if at all. And it means you're basically duplicating the scene across multiple GPUs, which is a lot of money burnt on VRAM.
New PCIe specs will likely only affect data transfer like for storage applications, at least for the time being.
Multi-GPU doesn't exist for anything other than ML or HPC.
While Vulkan fully supports it. Metal and DX12 don't.
The real issue for real time AR/VR/144FPS+ is knowing what you can/can't offload, what's the transfer latency, etc. this will change based on cards, generations, CPU's, library versions, Driver versions, vendors.
It is a nightmare.
Even SLI/XFire when you know there are identical cards, and drivers. You still see ~10-20% pref gain for 50% more resources.
I've wondered if it would be possible to design a dual GPU setup to handle VR applications more efficiently? VR tends to be kind of hard on current GPUs due to needing to render the scene from two viewpoints. With a dual GPU setup you could effectively dedicate one GPU per eyeball.
That's actually not true. I believe with the latest generation of Nvidia cards (10 series) they made rendering multiple similar viewpoints dirt cheap by tweaking the hardware and the rendering pipeline.
From the arstechnica review on the 1060: "GPU Boost 3.0, Fast Sync, HDR, VR Works Audio, Ansel, and preemption make a return too , as well as the ability to render multiple viewpoints in a single render-pass."
From my limited understanding, VR is difficult because of the tolerances required. For regular gaming, slight frame drops were annoying, but didn't break the experience. Thus, it was reasonable to ship a game that was able to hit 60fps 99% of the time, and just write off the remaining 1% of the time. For VR, not only do we need to hit at least 75fps, the tolerance for frame drops is much much lower (a stutter while you're watching a monitor is annoying, the same stutter in VR could make you lose your balance). To aim to hit 75fps and guarantee that you'll hit that 99.9%, 99.99%, or 99.999% of the time is where the difficulty lies. I'm sure most of the HN audience has experience with just how difficult it is to tack on an additional 9.
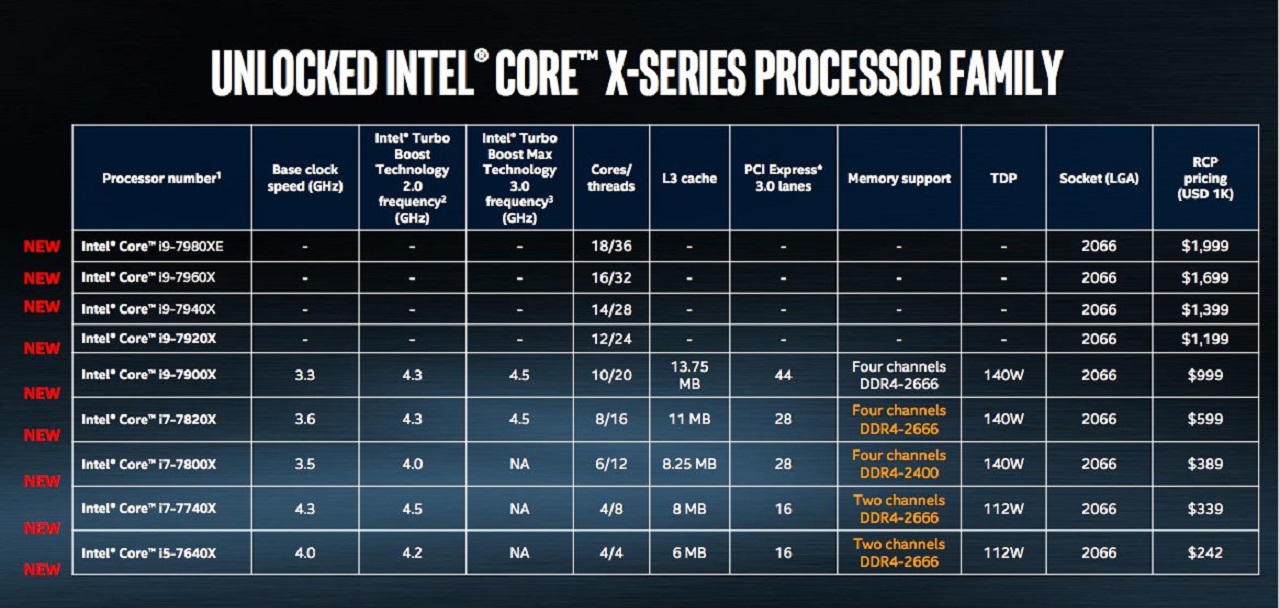
Linus Tech Tips has a rant about how Intel is trying to segment the market by only offering more PCI-E lanes on the most-expensive CPUs despite mobo support with their new X299 platform (they've done this in the past as well): https://www.youtube.com/watch?v=TWFzWRoVNnE
Basically, if you want the full 44 lanes, you have to get the top-spec processor for $1k ($1k for the cpu itself). The i9s above the 7900x don't even have details yet, since Intel is working on adapting their Xeons to their new HEDT platform to keep up with AMD. Here's the breakdown: https://www.cinema5d.com/wp-content/uploads/2017/05/Intel-co... I've also heard speculation that they're crippling the lanes on cheaper chips because they're so worried about cannibalizing their server market. Don't expect ECC support on these either. Honestly, if any Xeon BIOSes and CPUs supported unlocked multipliers, they'd be a better deal, but I get that overclocking and max stability don't really mix. OR they could totally wow everyone and come out with some 5.0Ghz (all-core) 16-core chip that isn't overclockable any further but can run ECC. Sell THAT for $2k to workstation users and rich gamers. Make it 2P capable as well in case you need 32 cores. Maybe AMD will do it with ThreadRipper, which BTW has 64 PCI-E 3.0 lanes ( https://www.pcper.com/news/Processors/Computex-2017-AMD-Thre... ).
Video card for games maybe, but if you look at modern network interfaces, like this board (http://www.mellanox.com/related-docs/prod_silicon/PB_Connect...) the bottlenecks in gen3 are pretty apparent. They are also pretty apparent in storage as well, partially because no one wants to create a x16 .M2 form factor interface to keep up with xpoint. Each time a new flash interface is created, someone releases a product capable of saturating it within a short period of time. But beyond that, consider the bandwidth of current flash arrays.
But returning to video cards, in GPGPU configurations transferring data between the board and system memory can quickly become a bottleneck.
Bottom line, is that gen4 is about 3 years late. PCI specs (or more generally x86 IO interfaces) seem to consistently lag their requirements. Hence why we lived with AGP (or VLB for that matter)..
Eh... for the everyday use PCIe 3.0 x4 is aplenty. If you wanted to help the everday user then make these new PIO slots standard https://world.taobao.com/item/535467249119.htm?spm=a312a.770... and once you have the GPU parallel to the MB, make the coolers user replaceable so that you can put a tower cooler on your GPU. What lunacy is that we have 12-16 cm edge cubes containing like a kg of metal and two-three fans in a push-pull to cool ~150W CPUs but the 250W GPU cooling system struggles for air. x4 is enough in practically all cases just don't forget to feed 75W into it...
Once that's done add a few more x4 slots. Even consumer CPUs have enough lanes for it, no need to waste x16 on the GPU. TB3 is x4, U.2 is x4, everything big and useful is x4 so more of that is helpful. The only thing that needs x8 is like HPC and 40Gbps+ Ethernet both of which are clearly server land.
4 3.0 lanes may be enough for a GPU, but if you're using a 3.0 capable GPU on a 2.0 system, you'll need 8 lanes. So my guess for why GPUs have 16 lane connectors is for backwards compatibility. What motherboard manufactures could do is use open ended x4 slots. But from what I've observed, people don't seem to know that you can put an x1 card into an x4 slot
And the future is actually less bandwidth requirement:
> Performance doesn't even drop with newer DirectX 12 and Vulkan games, including titles like "DOOM," which are known to utilize virtual texturing ("mega textures," an API feature analogous to Direct3D tiled-resources). If anything, mega textures has reduced the GPU's bandwidth load on the PCI-Express bus.
So: 3.0 x4 will be plenty for the foreseeable future.
So why would anyone use 4.0? Or 4.0 is more like a stop gap for HPC, Network applications? Where the need for higher bandwidth interconnect is urgently needed. Intel don't even plan to have 4.0 on selected CPUs until late 2018. And AMD are moving to 4.0 until 2019.
I wonder if it could be the case that 5.0 will end up shipping mostly in HPC configurations to compete with various proprietary connector offerings, while 4.0 is what the consumer space sees for some time.
It's also possible that the timing is a result of them expecting far more stalls in the process for 5.0 than cropped up, though there's obviously still plenty of time.
It's all fun and games until you need a vendor ID. Because we have a bandwidth of hundreds of megabytes per second, but UUIDs are apparently still to expensive.
But yeah, that's what I meant by USB being better than PCIe. At the very least the specs are publicly downloadable.
Would be interesting if the new standard was just multiple USB-C connectors for the cards. One, two, four or eight of them depending on the bandwidth requirements.
The alignment issues of multiple on-board plugs would just be a headache waiting to happen. Even with SMT components typically aligning themselves during solder flow, there's always discrepancies in manufacturing and components go ever so slightly out of whack. On the GPU side, those would probably be straight because they'd be laid flat against the board, perpendicular to the motherboard. The motherboard mountings would be the problematic ones.
You could plug all the sockets into a large retainer (mimicking the role of a GPU) during soldering to ensure they're spaced correctly.
Doesn't sound as solid as a socket though, they support some weight of the card in addition to carrying data. I'd be concerned about USB sockets getting torqued off if you looked at them wrong while installing a card, or if you took out the mounting screws without having the card properly supported.
USB-style sockets could require less force to insert than a typical card, so they're less likely to break, but that's also a function of design. A plastic sleeve to guide the card into place and ensure a good fit isn't that hard a concept.
Force to insert it isn't what I'm worried about, it's snapping it off with perpendicular force. Double height GPUs are heavy and most of that's supported by hanging off the socket.
True, you could still run the PCB footprint out to the edge and have a support socket on the motherboard to grab it.
Then we could eliminate the cost of the USB components by building contacts into the support socket that connect to pads on the PCB!
I dunno, ease of inserting and removal just isn't on my list of desires for a GPU. I install one maybe every 2 years, and I don't want to worry about it falling out and smashing around inside my case if I pick up my computer or something.
Whatever mounting shenanigans are necessary to lock it in place with weaker connectors feels like a solution looking for a problem. The somewhat high force of PCIe slots is a feature, not a bug.
The socket compoonents would have to be manufactured as one part that's soldered down into existing holes not unlike how the slot itself is a single component.
USB-C is a fancy and quite complicated standard that is complicated mostly because it can negotiate varying link protocols and because it can handle being connected in two or four different orientations [1]. For PCIe slots, it's always PCIe and it's always plugged in the same direction, so USB-C wouldn't buy much.
[1] USB-C to USB-C cables don't have the symmetry they appear to have. Each end can be independently upside down.
to clarify your [1], if I take two connected devices, unplug the cable, and plug it back in, reversing each of the two plugs, then that is a different configuration from what I started with?
Would this, or current technology, be fast enough to have a (professional grade) Oscilloscope as a PCIe card? It's my understanding (I don't work around top of the line so I'm probably wrong) that even the best scopes don't have particularly amazing interfacing with regular PCs because of low data bandwidth with their interfaces.
How is this possible? I assume GT per second is transfers not bits. You can't do any kind of handshake at that rate over more than a centimeter or two. Do they allow multiple requests to be issued before the first transfer is complete? The speed of light is definitely coming in to play here as an upper limit.
It is bits. It's full duplex, each side has dedicated receive and transmit lanes. And for example PCIe x16 is 16 lanes. Each transfer is an encoded bit. PCIe 3.0 and 4.0 require 130 bits to encode 128 bits (PCIe 2.0 required 10 for 8). So 16 GT/s would be ~1.97 GB/s (in Bytes). The primary thing this standard is doing is stepping up the communication speed using better chips (which is why it's so easily backwards compatible).
PCI Express works more like Ethernet than classic PCI or a parallel bus like Wishbone. There's no per-bit (or even per-byte) handshaking between devices; they communicate with packets over a longer time span.
In this context, a transfer is almost the same thing as a bit. For each 8 bits of useful payload PCIe sends 10 bits of encoded payload. The GT counts the total number of sent bits, which include this 20% overhead. So actual userful bitrate is 0.8 * GT.
It would seem to me that 2x is not such a huge jump to warrant 6 years (compared to USB 3 => 3.1) and that it is not the bottleneck anyway. But we might be approaching the speed limits on PCIe (as in transistor size).
{kind=link}