Honestly this is the area I'm most excited about. SRS is just one facet---correct choice of input media, datatypes, and mental models are a big deal here.
I'm a math undergrad. And one thing that drives me crazy is how mich rewriting I do. What I want is a semi-tangible expression tree that I can manipulate and "snapshot" (to show my work) into Latex. The Latex rendering was easy, but figuring out what "core tree manipulation ux actions" are is another thing.
Similarly--am I the only one tired of typing? I'd kill for a gait analyzer or a haptic glove that let me program while walking through the park.
Some of this stuff sounds farfetched, but looking at emacs, or chorded stenotype machines, or paredit, really drives it home that we could be doing so, so much better, with very little new tech required.
When I was a kid I had mild synesthesia where I'd tie the words "fourth" and "favorite" with a feeling of "reaching." I still today associate clojure's map with spreading butter, or reduce with "rolling up." Chinese abacus math, developed to the point where thr actual abacus is no longer necessary, is a thing to behold. The human mind seems to make these connections easily and automatically. Why not leverage that?
I'd love if text became just the shared human-legible bytecode for our own personal interfaces.
(Check out this clip: https://m.youtube.com/watch?v=cHIo96yBf70 where some people get fed targeting data from an AI plugged into all the camera feeds---and note especially around the middle of the video how the girl customizes the interface on the fly)
I'm currently working on a structured editor which is at its core a customizable rewriting engine; you specify a grammar, and essentially all editor actions are rewrites on that grammar. My current target grammars are for simple LISPy languages because of the simplicity, but my original (and eventual) goal was/is as a tool for exploratory mathematics. I've always felt mathematical manipulation as more of tactile, synesthetic phenomena than a verbal/linguistic one; I feel like the current state of haptic input is not quite up to reifying this yet, though it is improving very rapidly these days! So I'm trying to tackle some of the software side, and seeing what can be done towards this goal with extant input devices.
Style checking that enforces a single representation for a given ast, seems now a thing in javascript land. One less worry for often-novice programmers.
Which makes code files simply an ast storage format. And makes people's text editors and language modes into an representational ast editors. So... it seems industrial use of semantic editing has finally begun?
Relieved of the impedance mismatch between code-as-ast and code-as-richly-expressive-text, perhaps there's an opportunity here to quicken the innovation and deployment of non-traditional editing? At a time when XR seems likely to be creating the next "great software rewrite".
I watched Andrew's talk recently, and I highly recommend it to other readers interested in the above topic. It's full of clearly expressed, interesting ideas.
When I read:
> What I want is a semi-tangible expression tree that I can manipulate and "snapshot" (to show my work) into Latex. The Latex rendering was easy, but figuring out what "core tree manipulation ux actions" are is another thing.
—in the parent comment, it was the first thing that came to mind.
> What I want is a semi-tangible expression tree that I can manipulate and "snapshot" (to show my work) into Latex.
It definitely seems like there's a gap in the computer-math ecosystem: you've got systems like LaTeX that are great for typesetting math you've already mostly figured out, and you've got systems like SymPy that are good if you want the computer to do the vast majority of the work, but I'm not aware of much in between.
It would be really cool if there was something like Photoshop for math, where you could work with expressions in a visual, semi-tangible way and the computer would give you "smart" tools to help you out.
Being a math undergrad puts you in the top 1% of the population in terms of the ability to manipulate symbols.
So your semi-tangible expression tree will only be comprehensible to maybe ten thousand users worldwide, at most.
This is why "worse is better" is a thing. Most of the population is at the middle of the bell curve, and they struggle with things developers find easy. Most of the developer population is to the right using tools and languages that are sort-of-workable but not particularly sophisticated.
The people who find symbolic thinking easy and natural are on the extreme right.
I think assistive AI has limited prospects for fixing this, because the XY problem and Dunning Kruger mean that people don't know what questions they need to ask. And to some extent symbolic perception relies on experiential qualia which most people don't have access to.
AI is going to be go big or go home. It will either be a physical prosthetic, giving users direct mental experience of patterns and data through brain stimulation, or it will be external and set up to anticipate and solve problems with only the vaguest strategic directions from a user.
Current technologies can't do much because UIs are low-bandwidth and can only do a limited amount to help people with average memories and average abstractive thinking. Which is why most apps and web pages are brochures/forms/shop fronts - familiar and uncomplicated models that don't require abstract thinking.
Daniel Dennett introduced the introducing notion of Intuition Pump, which I would say definitely qualify as transformative tools for thought.
They are thought experiments designed to focus attention on important features of a question and to deflect them from getting bogged down in hard-to-follow details.
1) We know that our minds can do so much more. Why? Review the various well-documented feats of memory/computation that people have been capable of. This is like seeing a fellow human run a mile in less than two minutes.
2) Question is: Why cannot these levels be attained by more people? My hypothesis is the way our brains are trained in childhood. Baby Mozart, etc. toys aside, the way baby brains gather information and are trained are limited by their bodily abilities, which are puny.
3) The answer seems to be to devise a way to feed information-reach, highly non-normal stimulus to young brains, e.g. using heads up displays. This is the method described in Mimsy Were the Borogoves (https://en.wikipedia.org/wiki/Mimsy_Were_the_Borogoves)
This sounds nightmarish and we also don't have the technology currently. But in the intense competition for colleges/high-schools and even middle schools who knows what can happen?
I don't agree with this. One-off savants who can do some random task like remember the order of a deck of cards after seeing it once are just optimising all their energy towards something arbitrary but not actually that useful.
i.e. Feats of memory are a waste of effort when you can just write things down.
RE: Item 2, I think that unfortunately genetics has a strong, though not absolute role.
But on an more optimistic note I think the ability of technology to accommodate different learning styles will help unlock the potential of many people. I'm looking forward to seeing what innovations come from people who think in ways that are truly unconventional.
However, I think a very important underlying question is "what kind of intelligence are we actually going to need in the future?" I think it depends on who you ask.
Most Americans would probably say 'logical reasoning for working with computers so you won't have to worry about automation'.
But if Kai-Fu Lee was here I bet he would say 'creativity and artistic talent' since art is a human activity that is harder for a machine to grasp.
Either way, the capacity of the internet to proliferate bullshit means that everyone is going to have to learn epistemology whether they want to or not.
From the Hinton link: "Letters submitted to mathematical journals of the time indicate more than one person achieved a disastrous success and found the process of visualising the fourth dimension profoundly disturbing or dangerously addictive."
I wonder whether anyone in modern times has tried it, and how it turned out.
Particularly interesting to think about the memory feats of the ancients--who didn't even have computers. It really makes you wonder what kind of secret techniques ancient bards and philosophers used.
The ancient Romans and Greeks were known to use the Memory Palace technique, as other commenters here have mentioned. (It's mentioned by Cicero, in Ad Herrenium (of unknown authorship), and St. Augustine, among others.)
This was continued into the middle ages, by e.g. Christian monks, see Mary Carruthers' work [0], and the Rennaisance (e.g. Matteo Ricci), see e.g. Frances Yates.
For non-western uses of the memory arts, I'd recommend Lynne Kelly. She writes about aboriginal Australians' use of songlines, the African Luba people's use of lukasas, etc. (Lynne Kelly has done multiple podcast interviews that make for fascinating listen, as she's both an accomplished practitioner of the memory arts as well the history behind them.)
1) A lack of ability to outsource memory to the written word. I forget who it was, but either Plato or Aristotle was famously against writing because they said it would degrade human's capacity for memory (and "learning" if I recall correctly, though this was arguably wrong).
2) Perhaps even more importantly, the content of the time was shaped to the available medium. It's no accident that epic poetry from the oral tradition universally contains huge amounts of redundancy and pattern: meter, repeated adjectival phrases, character epitaphs or titles, etc.
I don't know if it's the same thing as (not only the philosophers, but also many great orators of ancient Greece/etc) the capacity to recite e.g. entire epic poems from memory, but have always found Vedic Chanting (Pathas) fascinating-
In the ancient near east people did not refer to literary works by means of a dedicated title, but by the first line of the composition, which is taken as an indication of origins in an oral tradition, esp. for the earliest works that were written down. When large portions of text have been committed to memory, reciting the first sentence is often enough to trigger a flow, a small but useful "technique" applied by e.g. hiphop lyricists.
This is still done today even if not with the same intention. When we don't remember a name of a song we repeat part of it "do you know this song? the one that says X..." It's natural
It's called "remembering things" and we all used to know how it works before we outsourced that to computers ;-p
Back in school we needed to rehearse latin vocabulary and lyrics of ancient stuff that I sometimes still remember today though I'm used to outsource this kind of data to computers.
I think the skills for this are still in us - it's just about the proper techniques to persist the information- and access it fast.
The techniques aren’t secret. You can buy books about them on amazon. It’s like memorizing the Iliad, Odyssey or the Koran, completely doable for a human of normal intelligence but a lot of work.
If you measure at the level of humanity instead of the individual human, the last two advancements for tools of thought were the mobile phone and the Internet. The Internet speeded up access to information and computing. The mobile phone made that information and communication always accessible.
Furthermore, the real revolution was in making both of these widely accessible. This nourishes and harnesses far more human potential.
There's a third revolution impending, when people learn to write their own ad-hoc software and build custom automations for themselves. This will require much simpler development tools, but we're almost there.
Apps sort of make this possible in a limited way, but it's common people is limited to whatever developers thought of. Therefore their needs are mediated by a caste of priests, which have access to the sacred knowledge for building and adapting the available tools.
A widespread literacy for building automations would change the current focus of smartphones for media consumption and multiply common people as builders of automations (with all its implications in society in terms of security and new dynamics of people interacting with automations of varying quality).
I still think excel is the leader in this category. Was looking at a roadmap produced in excel the other day, somewhat amazed of what the persons working on it had been able to produce with various workarounds to get it to their liking. It still a rather blunt tool though. But is has the right elements in place, data grids, a workable visualization canvas, some limited automation capacity to tie them together.
I’m thinking the same elements presented in an environment perhaps more like Scratch could work. A kind of whiteboard metaphor where objects are independently scriptable, ad some data flow modeling and data source capacity to that and there could be something a bit less blunt
> I still think excel is the leader in this category.
Yes, definitely. The "reactive functional" programming paradigm of the spreadsheet is radically more understandable for end users than the imperative, as it doesn't require keeping a mental model of state changes in memory.
Fortunately, React has popularized this reactive functional paradigm and it is no longer confined to spreadsheets.
> I’m thinking the same elements presented in an environment perhaps more like Scratch could work
An approach of visual building blocks could help for learning, though Scratch is imperative so it has all the trappings that make a language hard to learn for non-programmers, plus all the inconveniences of editing a visual language (much more cumbersome than editing text).
I'd rather have a "structure editor"[1] for editing a textual language (like the spreadsheet, but with a tree representation instead of a grid one), which added enhanced visual representations over the base tree. You know, like the IDEs developers use, but with a functional reactive language that mixed code and data, like the spreadsheet does.
BTW, several people have created Javascript libraries that follow the simple design of Scratch primitives, so that those can be used within a textual environment.
Fair enough. I wasn’t thinking of the language actually, more of how they use the painting canvas. The fact that scripts belong to tangible things and not some abstract “background”. Compare VBA and formulas in excel. Formulas naturally belongs to their cells, which is simple, but vba exists in this ambient thing that requires an entirely different abstract model to grasp.
I don't know Shortcuts in depth; but the problem with "rule based" tools like this is that they typically don't allow users to build new abstractions, so they don't really count as general programming languages. (You can create first-level abstractions, but they compose poorly).
But yes, being able to create small automations over your own data is a start (see the large success of a tool like IFTT).
I second this. I believe apps like Coda/Notion will make a big difference in how people work, think and interact with their computer and mind.
Not everyone would invest the time and effort to build what is basically an extension of the mind with these tools, but the ones who do will have an edge in thinking/planning/coordinating/executing I believe.
Though I still have to find a Nocode platform that combines the powerful tracking tools of developer's IDEs with the simplicity for building automations in a functional language found in a spreadsheet.
As a long term user of Anki, I think the hype here is too much. Spaced repetition helps you learn facts, but that is such a limited representation of what learning something means. I get that the point of a mnemonic medium is to improve your memory, but the focus on memory in and of itself is reductive. Memorising things helps no one gain a better understanding. If anything, it’s just a way to avoid the mental effort of real comprehension (roughly analogous to a google search for a solution rather than solving a problem yourself).
Edit: I love Michael Nielsen’s work, but I don’t love his glorification of this tool.
I am one of those guys who had a 4.0 GPA in college but I never used spaced repetition because what I was doing seemed to work well enough. Post-college I tried it for learning japanese and it seems like a downgrade from my usual approach.
The best way to learn something is by contextualizing it. For example it doesn't matter if you forget a math formula if you know how to re-derive it. If the formula is truly important, every time you access it, the entire DAG of knowledge leading up to that formula will be "refreshed". This is a very natural spaced repetition that erodes from the edge of your knowledge graph since the basic building blocks are refreshed so often. New knowledge is extremely easy to acquire, and your graph can be "refactored" every so often.
The space repetition apps I have use doesn't have a similar concept of interrelationship. For example it's possible for you to learn the flashcards for "three" and "one" but not know the word for "two". This is insane way of doing things. You are just refreshing random isolated nodes. Not only does it make it a lot harder to learn (since random out of order information is harder to compress), the knowledge graph you build is a tangled mess that's not as usable and doesn't degrade gracefully.
The problem is that students are provided with almost no support in development of metacognitive skills.
They don’t even learn how to approach non-trivial but eminently solvable problems other people have posed, much less how how to “refactor” past understanding, how to investigate completely new subjects, how to hunt for problems to work on, how to manage projects that take longer than a day, etc.
I think SRS software can be profitably used, but it would take a lot of thought and planning. For example, an SRS software system which randomly assigned difficult exercises from different past chapters of a math textbook could be pretty helpful, to keep the student occasionally revisiting topics instead of working through a chapter in a week or two and never returning to it again.
The space repetition apps I have use doesn't have a similar concept of interrelationship. For example it's possible for you to learn the flashcards for "three" and "one" but not know the word for "two". This is insane way of doing things. You are just refreshing random isolated nodes. Not only does it make it a lot harder to learn (since random out of order information is harder to compress), the knowledge graph you build is a tangled mess that's not as usable and doesn't degrade gracefully.
I found it helpful to break content down into constituent parts, but also to make cards unify those constituent parts. So, there will be cards about individual facts, but also cards that relate those individual facts. And eventually cards that related the cards that related the cards that related the individual facts.
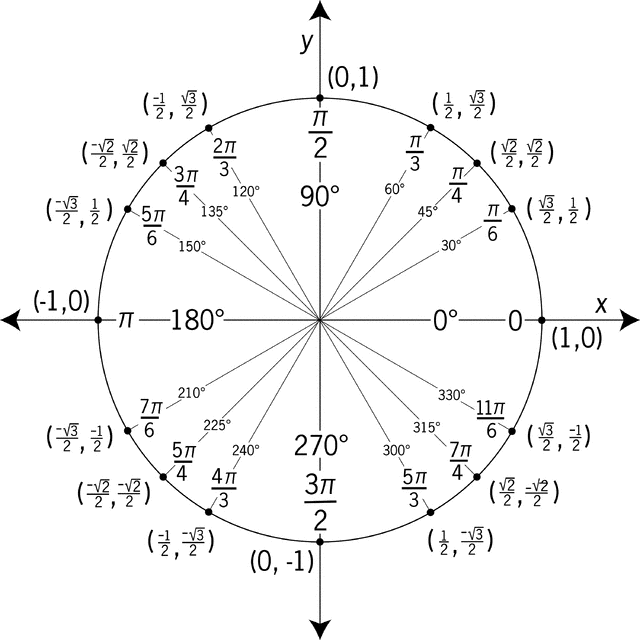
Also, I cemented my understanding and intuition of the Unit Circle using this approach.
> Also, I cemented my understanding and intuition of the Unit Circle using this approach.
What do you need to do to “cement understanding and intuition of the unit circle”?
The common diagrams shown in high school trigonometry courses – e.g. https://etc.usf.edu/clipart/43200/43215/unit-circle7_43215_m... – basically involve only 2 meaningful facts: a rhombus made of two equilateral triangles has a long diagonal with squared length of 3, and a square has a diagonal with a squared length of 2. (a) These are fairly easy to figure out, and once understood are quite easy to remember, and (b) all of the derived factoids are pretty much trivial.
Students are typically taught this material in a quite terrible way, unfortunately.
My point is that there’s very little there. People shouldn’t need to go to extensive effort or need a special system or method to learn 2 simple facts. Taking a simple thing and wrapping it in a big pile of obfuscation is a poor way to teach/learn. (That this is taught this way is not the fault of students.)
> The space repetition apps I have use doesn't have a similar concept of interrelationship.
I think this is a really important insight and a big problem I noticed as well. When I started working on my own space repetition app[1] I really wanted to enable and facilitate this kind of interconnection of concepts. I added a notes section in addition to cards and the ability to link/reference notes from cards, cards from notes, cards from other cards, etc.
I found this really helpful for example with Japanese. Having a sentence card for a vocab word that also links back to a long form note on the grammar being used in the card. Another example is kanji. Making cards for individual kanji as well as vocab cards that use those kanji and linking them together. Over time I was able to build up a huge web of interconnected information.
"these kinds of results should be taken with a grain of salt. The mnemonic medium is in its early days, has many deficiencies, and needs improvement in many ways... is this medium really working? What effect is it actually having on people? ... are there blockers that make this an irredeemably bad or at best mediocre idea? How important a role does memory play in cognition, anyway?"
The essay continues at great length in this vein, getting gradually into more and more detail. We have detailed discussion of common ways spaced repetition fails, of ways it may inevitably fail or needs to be redesigned (a different issue), of ways it falls short of the goal of understanding, of ways spaced repetition is a poor lens for memory systems, and so on. I haven't counted, but believe there's several thousand words in this vein.
The conclusion is that: (a) we are some ways from having really good memory systems; but if we did it would (b) likely to be extremely helpful, including in lots of ways people don't commonly appreciate; and (c) be far from a panacea. The essay has a lengthy discussion of points (a) and (c), in addition to (b).
I don't think it's reasonably characterized as hype.
Thanks for your response Michael, and my apologies for the temerity of my initial comment. At the end of four years of Med school, I am truly Anki fatigued (and a bit fed up with learning facts about rare diseases I may never see in practise). The points you highlight here I recall being present to a degree in Quantum Country, so I really don’t have a leg to stand on- apologies for directing my frustration toward your work.
I was curious to read the self-criticism section since I fall into the memory-skeptic camp myself.
And I did in fact find my main concerns referenced there, though my impression is that they weren't taken seriously.
One telltale sign is the condescending tone with which they're referenced:
> Bluntly, it seems likely that such people are fooling themselves, confusing a sense of enjoyment with any sort of durable understanding. ... You'd think their claim to have a broad conceptual understanding of French was hilarious.
The other signal is the convenient changeup of exemplar subjects, natural language vs. computer programming. In the above, for example, having a "broad conceptual understanding" of French is obviously useless—and yet having a broad conceptual understanding of topics in e.g. Computer Science is extremely useful because:
1) It's part of a map that allows you to jump deeply into related as areas if a demand for that knowledge actually arises.
2) The 'broad conceptual understanding' (if done well) is generally of 'basic principles,' which have an interesting property of being applicable to wide ranges of much more specific subject areas.
> Another common argument against spaced repetition systems is that it's better to rely on natural repetition.
A more fair angle on this argument is that it's better to rely on natural contexts instead of 'repetition'—this is the reason "brain training" apps fail, for instance. (SRS obviously isn't as bad as those, but it still certainly ranks lower than a 'natural context' in regards to imparting skill in that context.)
> For instance, it's no good (but surprisingly common) for someone to memorize lots of details of a programming language they plan to use for just one small project. ... But the truths of the last paragraph also have limits. If you're learning French, ...
This is another sneaky subject change. It's pointed out how using memory systems for learning programming languages is probably non-optimal. But then this next paragraph is supposed to show us the limits of the supposed non-optimality—but it never does, because it switches to talking about a natural language instead, using an argument about lacking interlocutors which is completely inapplicable to the programming languages example.
In any case, there are things about this project that I like very much, but I do still suspect there are subtle flaws in the premise of what this would end up making people better at, and the tone approaches Wolfram-esque levels of grandiosity that makes it hard to take seriously.
>> Bluntly, it seems likely that such people are fooling themselves, confusing a sense of enjoyment with any sort of durable understanding. ... You'd think their claim to have a broad conceptual understanding of French was hilarious.
The way people learn French (or any language) is not by memorizing atomized vocabulary definitions on flash cards, but by listening to / reading a large amount of comprehensible input, which is to say, meaningful grammatically correct sentences in their context. Memorizing vocabulary might help some self-studying language students bootstrap enough very basic understanding to make a wider variety of inputs comprehensible, in the absence of a teacher or properly-designed curriculum, but in and of itself does not comprise learning the language.
People who encounter a large amount of appropriate-level language in context do end up with what might be called “intuitive understanding” of language (or maybe “subconscious understanding”; “conceptual” is not a great label, IMO). They know how to recognize and later how to form grammatical sentences because they have been exposed to a wide variety of such sentences. They learn the subtle connotations of words (beyond the definitions offered in an English–French dictionary) by seeing the words used many times in context. Etc.
From what I have read, speaking per se is just not that useful at the earliest stages (at least the first several months) when learning a language.
>> It seems plausible, though needs further study, that the mnemonic medium can help speed up the acquisition of such chunks, and so the acquisition of mastery.
This whole argument basically boils down to speculation.
I've googled generally and verbatim with various quotes from above and your name, and cannot find the essay. It sounds interesting. Can you post a link please.
In the essay, the importance of dependency on previous concepts is touched upon multiple times.
I essentially see 2 distinct "problems" or tasks that would need to be done in this specific respect (without downplaying the value of other factors): 1) it takes effort to encode the dependency relationships, 2) even if someone puts in a lot of work for a specific subject or domain to encode the dependency relationships, we need to modify the tools to take advantage of this knowledge.
I would propose as a next testbed, one takes the MetaMath database (set.mm), since dependency of a theorem on other theorems or axioms can be extracted in automated fashion. So I would love to see a tool (a working title could be Anki/MetaDrill or "autodidact" was the title I had in mind) that presents me with the following exercises:
type 0a, 0b: given ascii characters select LaTeX symbol (a) and vice versa (b) [for example ".-" for negation etc...]
type 1: given theorem/hypothesis/axiom/definition abbreviation name: produce the statement
type 2: given theorem/hypothesis/axiom/definition statement: produce the abbreviation (the reverse of exercise type 1, both can be easily extracted from an instance of a verifier that has parsed the set.mm database)
type 3: given a couple of input statement, and an output statement: produce the theorem abreviation that justifies this step (can be easily done by randomly selecting a target theorem from those scheduled for the user to know, then searching all proofs in the database for steps that reference the target theorem, each reference to the theorem is a utilization or example application of the theorem)
type 4: given a theorem: produce the list of theorems directly used in its proof (this one depends on the proof used, so that it is possible to find proofs that don't rely on those in the database, but is easy to generate for the proofs proposed in the database: just enumerate all the references in the proof of this theorem)
type 5: given a theorem (by abbreviation or by statement): produce a proof (the previous series of exercises should provide all the prerequisites, and the last exercise above would contain a lot of hints to reproduce the proof) it is possible to find an original proof, and the MetaMath verifier can be used to check the user's proof!
the exploration or presentation of new axioms, definitions, theorems, can be limited to those "in view" to the user, using the dependency graph of theorems, so only a minimal number of new concepts is introduced at a time. I.e. this prevents the user from being bombarded with uncontextualized facts like "the connected sum of a torus with a sphere is a torus" without first learning about addition of rational numbers...
once a large number of people can quickly get up to speed with MetaMath, they will see the utility of spaced repitition, and understand that formalization is the way forward, since formalization automatically forces you to be explicit in dependencies, and forces people to state their beliefs as exactly as possible, or alternatively as quickly as possible (be bold), but such that others can prove errors in their conjectures by providing proof that the bold person happened to introduce an inconsistency.
But the biggest advantage of logical formalization of knowledge is that all the above exercises can be automatically generated, no one needs to produce flash cards! not only can they be generated automatically, they can be generated as a function of the past performance of the user on those exercises, instead of waiting a long period of time before retesting prerequisites 2 or 3 levels deep, we can test already seen knowledge that relies on it, and upon failure schedule the immediate prerequisites it relies on 1 level deeper, most of which will succeed, but one of which will typically fail again prompting it's lower level prerequisites to be tested (2 levels deeper from the original failure) to finally prompt a last failure, upon which the 3rd level lower prerequisites are reached but all succeed, just like how a professor in an oral exam probes where exactly the student got stuck. This allows to test for gaps in working memory to be detected without explicitly testing all the lower levels, just like the blood test during the second world war: at some point an expensive but very sensitive test was developed, and instead of testing the soldiers individually, their blood was mixed then tested, and in this manner it was possible to cheaply scan for positives and only zoom in when a group had a positive. I can not find the link to the relevant wikipedia page sadly.
The key insight that Nielsen is advocating for is to use spaced repetition for concepts, not just facts. Understanding comes first, and then you deliberately try to cement a rich network that understanding in your long term memory. Personally, I’ve found this a revolutionary approach to learning.
As another commenter below notes, a recommendation is to spend one second reviewing each card. Thus, your cards are generally quite simple. This can very easily lead to a patchwork of simple details, but no glue holding them together. I’ve come to believe that the mental effort it takes to understand something should be prioritised over memorisation. If you’re relatively busy and spending a lot of time doing Anki cards, you may be limiting your opportunities for this kind of challenge.
I don't see why cards need to be quite that simple. I generally take about 10-15 seconds for reviewing each card. A lot of my cards are why/how/what questions (typical examples: "Why are bras covariant?"/"How are Green's functions used in solving linear differential equations?"/"What is Q-Learning?") The problem with skipping memorization of concepts after having understood something is that two months later, you'll have forgotten those concepts. So, all that effort will have been in vain. I typically don't create much more than 10 cards a day, or maybe 20 on a day where I'm taking in a lot of information, and I typically have less than 50 cards to review. It's really not a huge time investment - especially if you're "busy".
> The problem with skipping memorization of concepts after having understood something is that two months later, you'll have forgotten those concepts.
The key realization, for me, is that conceptual understanding, intuitions, and key insights are themselves just pieces of information that can be memorized.
E.g.: Q: How to derive Bayes' Theorem? A: Write P(A and B) two different ways.
Understanding beats rote learning every time: it's always possible to reconstruct the learning. You can generalize and customize it.
But how much quicker if you also have that at your fingertips!
Perhaps, a bit like writing a very clear and well thought-out solution on SO... and later googling for it.
If you're only using Anki to memorize facts, you aren't using it correctly. You need to get more creative with the card-creating process. For example, instead of just memorizing the definition of a term, create cards like this:
- "Describe [term] in one sentence/two sentences/three sentences."
- "Describe [term] without using the words [common words used to typically describe it]."
- Imagine you are explaining the concept of [term] to a small child. How would you do it?
And so on. The power of Anki is the underlying memory algorithm, not simply the memorization process. You can understand and remember anything if you organize the data in the correct way.
I understand your point but I disagree. Just memorizing does not help, but memorizing definitely increases the ability to gain understanding.
Connections required for understanding start to happen automatically when you start thinking about things you remember. If you don't remember the facts and fine details, your understanding will be shallow. Deep understanding requires going trough the facts and finding connections. Sources outside the head, like books, notes, Wikipedia and Googling can't make the connections. They are dead outside the mind.
Of course, if you are memorizing trivial facts, it does not help.
I'm in agreeance. In this case, I don't think SRS offers a lot of benefit, i.e. the tool isn't the hard part, it's the content you put into it.
EX: I recently (5ish months) started moving Kindle highlights to Anki. I've found my ability to retain the facts has increased but it is also directly correlated with how I designed the card (cloze, length, etc).
I think we should put more focus on extracting key points for later learning rather than focus on automating the review of those points.
here is a different idea: we don’t need [new] tools for though. Our entire history is made up of using tools to basically enhance our abilities - mental, communication, design you name it. Our native possibilities are quite limited (eg you cannot hold a list of more than 5-7 things in your head at once). We figured this out a long time ago and have tooling to augment these abilities. Writing, Language, Computers they are all tools that literally make us superhuman.
I can easily imagine much more things simultaneously:
1, 2: 2 cars are parked at the side of the road
3: a third car is driving and going to pass the 2 parked cars.
4: a cat runs out from between the parked cars on the street
5: a dog chases the cat
6: with a pulled taut leash
7: pulling the dog's owner on the sidewalk out of balance,
8, 9: causing the owners hat to fly off, and her groceries to fall out of her free arm
10: a fourth car crashes into the surprised car
11: an elderly couple looking at the scene in pure horror
...
Now if you meant we could only hold 5 or 7 scenes or complex thoughts at once, then yeah, that could be true depending on the complexity of those thoughts or scenes.
Extremely boiled down TL/DR: The author's invention is a spaced repetition system built into an essay, so instead of having the cards isolated, the cards are embedded in the text itself.
At a technical level, that's certainly innovative, but I'm doubtful about whether it's actually an improvement on classical SRS. In my experience, one of the most important things for an SRS deck is speed of reviewing: a given card should take less than 1 second to review and rate. This is necessary if you're going to maintain decks with tens of thousands of cards. I find my brain does a remarkable job of reconstructing the surrounding context, so having the cards embedded in the original text would just be a time sink for me, I think.
From reading earlier discussions of the quantum computing tutorial, I am pretty sure most of its readers do not even use classical SRS in the first place.
Yes, I was struck by the really exceptional and beautiful presentation/layout of OP's page. Perhaps the real contribution is less "build a better mousetrap" and more "market the hell out of mousetraps". If OP can show more people the light of SRS, that will be fantastic!
Programmers/computer scientists will make better progress on "transformative" "tools of thought" if they spend a few years collaborating with psychologists/sociologists/political scientists/economists/historians on their problems first.
Those that do will have a leg up over those that dont.
Right now it's like watching people working on calculus without spending enough time on algebra and geometry.
The premise of the article doesn't make sense. Tools can only train thinking ability, they cannot extend it. Thinking and reasoning must be fixed at the root.
I'm curious (genuinely) how you define thinking in a way that it's unaffected by the dominant mediums of communication and culture. Maybe you can recommend some reading material?
In my view 'critical thinking' is real thinking. There is a lot of misinformation and a lot of what we perceive as knowledge is in fact rhetoric. You need to learn to take everything with a grain of salt; sometimes that means you need to unlearn things along the way. Doubt is important.
I think it's good to read a variety of books with opposing viewpoints or with viewpoints which contradict popular ideas.
For non-fiction, the books 'Black Swan' and 'Fooled by Randomness' by Nassim Taleb were eye-openers for me. Also, I found an interesting synergy between Nassim's books and the book 'Thinking fast and Slow' by Daniel Kahneman (which is a book about human psychology).
Also, I enjoyed reading 'Lords of Finance: The Bankers Who Broke the World'.
I don't read much fiction but it can be interesting sometimes. I read 'Brave New World' by Aldous Huxley many years ago and it's a book that appears to be becoming more relevant with time. I find that watching foreign films can also help to diversify my thinking.
Most of critical thinking is awareness of uncertainty. It is abductive reasoning. It's about 'most likely' conclusions and 'best explained by' situations. Which is why:
> You need to learn to take everything with a grain of salt
That's uncertainty. And once you are in the realm of uncertainty (which is almost always), society and culture take a large role in affecting your decisions.
A tool for thought helps navigate that uncertainty, so you have a better understanding of systems, which likely translates to making better decisions.
This was a fascinating and wonderful read. As someone who also works on tools for thought, here's my review and criticisms. The material is long so this will be longish too.
Review
The bulk of the essay is on what the authors refer to as "the mnemonic medium". A mnemonic medium, of which they use their work, Quantum Country, as a motivating case-study is an essay format which embeds flash cards containing carefully constructed questions and combines them with spaced-repetition to improve recall of the presented material.
The authors argue very convincingly that memory is an important and undervalued aspect of expertise. Much of the initial struggle in learners is from a lack of basic fluency in the vocabulary of an area. They show, including with supporting data from the aforementioned work, that this significantly increases recall of material (nearly all if the reviews were done properly). Even if you want creativity and think you can just look things up as needed, having the material readily available in memory will serve as a potent catalyst to one's creativity. The over-head is reasonable, they estimate 4 hours to read the material and ~100 minutes of spaced review to achieve months or more of retention on material.
They talk about the more typical sense of mnemonics, such as the method of loci and memory palaces. Such methods they argue, do not generalize well to different learning domains, especially more abstract areas.
They also point out the weaknesses of their method. Including requiring general motivation, a reason to learn the material and difficulty of crafting good atomic connected questions. Finally, they discuss why not much progress has been made in the area (funding of public goods problem), other mediums such as video and the executable book/notebook format and what inspirations can be drawn from video-games interface-wise and art generally from an evocative and emotional perspective.
Criticism
The simplest criticism is if the results will generalize. The topic matter on the technical aspects of quantum computing has already selected for a probably uncommon sort of person.
It is the authors' stated goal that they produce a method with broad applicability. Although they spend some time on the weaknesses of their approach, they could have spent a bit more on nearby failures. Engelbart had a bootstrap program, where each set of tools propelled us to ever more powerful augmentations. One major problem Engelbart found was that once people reached proficiency at one level, they had no interest in further gains. The complexity of peripherals has gone down over time (from multibutton mice and chorded keyboards to pointing with fingers) and people simply were not interested in learning complex peripherals. Some discussion of the difficulties faced by http://witheve.com/ at getting something with broad applicability and lessons from it would have been informative.
There is much work to be done in ending the dumb users trope and also in educating people that many things worth doing will be difficult. Engelbart often pointed (he was against voice as a primary control) out that you can't talk your way down a ski-slope yet people are happy to learn the difficult task of skiing. How to get that engagement generally?
The next major criticism is the difficulty of content creation. Writing a text is already difficult but writing one that is clear and with carefully crafted embedded questions will be much more difficult again. We can see hints of this in the quite low publishing rate of the Distill publication where a large aspect of the low rate is due to the difficulty of content creation. We are still several generations out from tools which ease the creation of interactive and tasteful (where interactivity is actually illuminating rather than a distraction as is often the case) executable notebooks.
The authors mention differential geometry as an example. Such texts are difficult not only from subject matter but also because they are often presented in a user hostile manner. With key information, including on notation, left out. This has been fine historically because these books are meant to be used in a supporting environment with lecturers and assistants. However, learning these autodidactically adds in an immense artificial layer of difficulty from ambiguity. It seems like an obvious thing but material written in a clear manner with no external support needed is already rare. Going beyond that will be a tall ask.
The fairly self-contained aspect of quantum computing might not transfer to differential geometry. To do that properly, one would also need to have material for adjacent topics such as multilinear algebra, differential forms, calculus of variations (for some motivating problems), analysis and some topology. That is a very large stack to get through and can be quite discouraging for the learner even with the dream of near perfect recall. The time investment might scale differently too and might require more of a fraction of study time.
For the creators, by the time you get to multimedia, and the need to do this is an accessible (accessible to blind, deaf, etc) manner, an already difficult task becomes nearly unmanageable. Perhaps, narrow AI tools (the authors do point this out too but also see Rainbows End by Vinge for a fictional take on this) will ease some of this but basic UX and API design for interactive education will also be pivotal and are sorely lacking. I do not believe the authors sufficiently acknowledge this.
The authors seem to make the mistake that experts will be the best authors of such media. I am skeptical of this. Very few experts maintain the empathy required to communicate with novices. I suspect the best approach and this is hinted at by the author with their example of Norvig's notebook, is someone either with exceptional empathy or who has just mastered the material, recording notes for themselves and then sharing. But it will take a while yet before such tools are in place.
Finally, the authors also discuss BCIs. Their examples of new modes of thought suffer from the same criticisms they have for the Logo programming language and creating properly motivated and connected questions, perhaps worse. From what little we know, this will not be just a matter of interfacing with visual areas but also with broad wide reaching networks in the intraparietal sulcus, inferior temporal cortex, angular gyrus, hippocampus and frontal areas just for a start. These are all involved in complex problem solving and will differ in detail from person to person. How to get a non-superficial interface beyond super low latency I/O is a great challenge and simply beyond the horizon of what is today imagineable.
This is as long as I'd feared it would be but I hope someone finds it useful.
Had a feeling it was the quantum country guy from the start, besides focusing on just techniques on the brain and mnemonics we also need to see the various inhibitors, it was earlier posted here in HN https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6429408/
I have this idea that refuses to leave me alone, but I don't really have the time and dedication to investigate it, so I'll just give this one away here:
I believe a lot of effort in reading stems from parsing: words can be ambiguous in sense ("ball" could mean a spherical object or a festive event; "work" could mean a result of working, or it could be the verb [they work], or it could be an imperative [work!], ...). So disambiguating sentences containing words of degeneracy G1, G2, G3, ... have a total disambiguation space of G1 x G2 x G2 x ... interpretations. Then there is also grammatical disambiguation.
There was the recent paper showing how transformers effectively provide each instance of a word with not just it's sense but also its grammatical position encoded as vectors, with the root at the origin, its children a unit distance away, and their children another unit distance away from their parent etc... This turned out to be essentially the Pythagorean theorem.
Now let's make another oversimplification: let's pretend the human ear hears volume logarithmically (or at least understands the logarithmic scale for intensity, very plausible since different resonators emit exponentially decaying sound with half-lives that depend on the properties of the object [transmission at the boundary conditions]). On top of that make the assumption that the discernible frequency bins form essentially a constant Q transform (i.e. equal temperament bins, a good but rough approximation, see Plomp and Leveldt). This insinuates we can present a vector as a list of decibels for each frequency bin. My choice for audio is mostly because it would take 0 effort for the listener to align the auditory sensors: even if we rotate or move our heads very fast, there will be no appreciable doppler effect to a speaker, let alone headphones. If we chose visual intensities or graphs, we would have to either look at the same point on the screen for prolonged periods of time, or alternatively shift the image in our brains.
So the idea would be to have a fraction of the frequency bins correspond to the sense vector, and the rest of the bins for the grammatical positioning vector. Then sequentially play the vectors in a sentence (or in any order really, since in theory the grammatical position is encoded in part of the spectrum).
We could create multiple choice questions by playing a sentence (senses and grammar positions), then repeating the sound of a word of choice's sense without grammar frequency bins, and have the user select the right word in a different sentence, to make sure we are recognizing the sense specifically.
Then "hear" pre-parsed texts, but scramble the word order to force the user to rely on the grammar vector component of each word.
Then, later, generate sentences that are ambiguous without grammar vectors: the unordered set of {cat, mouse, sees, the, the} "rendered to sound" twice with different grammar vectors: once with the meaning "the cat sees the mouse" and once with the meaning "the mouse sees the cat" and the user cas to connect the sentence audio to the right written sentence, to verify the user is interpreting the grammar vectors.
Who knows how fast we could be hearing text? Could we learn to hear text as fast as we can see and abstract visual scenes, if parsing is done for us by transformers? "A picture says a thousand words"
{kind=link}
I'm a math undergrad. And one thing that drives me crazy is how mich rewriting I do. What I want is a semi-tangible expression tree that I can manipulate and "snapshot" (to show my work) into Latex. The Latex rendering was easy, but figuring out what "core tree manipulation ux actions" are is another thing.
Similarly--am I the only one tired of typing? I'd kill for a gait analyzer or a haptic glove that let me program while walking through the park.
Some of this stuff sounds farfetched, but looking at emacs, or chorded stenotype machines, or paredit, really drives it home that we could be doing so, so much better, with very little new tech required.
When I was a kid I had mild synesthesia where I'd tie the words "fourth" and "favorite" with a feeling of "reaching." I still today associate clojure's map with spreading butter, or reduce with "rolling up." Chinese abacus math, developed to the point where thr actual abacus is no longer necessary, is a thing to behold. The human mind seems to make these connections easily and automatically. Why not leverage that?
I'd love if text became just the shared human-legible bytecode for our own personal interfaces.
(Check out this clip: https://m.youtube.com/watch?v=cHIo96yBf70 where some people get fed targeting data from an AI plugged into all the camera feeds---and note especially around the middle of the video how the girl customizes the interface on the fly)