Author here. I'll be watching the comments and can answer any questions!
I do want to make clear that most of the optimizations discussed are implemented in the Go scheduler, which is where I discovered them. I wrote the article to call them out as they were not easy to discover.
It looks like the number of threads in the threadpool is fixed. If have 1 one thread in the thread pool, is it possible to dead lock it by queuing a Task A the blocks waiting for Task B to do something, where A starts executing before B?
Do you think it would make sense to dynamically adjust the number of threads in the pool? An example of a thread pool that dynamically adjusts the number of threads is .NET. The algorithm is described by Matt Warren[1] and a paper[2]. In addition to the C++ version Matt links to, there is a C#[3] implementation.
The expectation is that all code running on the Tokio scheduler does not block and does not do anything CPU intensive.
There is follow up work planned to allow annotating blocking / CPU intensive bits of code so that the scheduler can do something smarter (things like you linked).
The old scheduler already had such an annotation, but in the interest of shipping, this has punted in the new scheduler.
Is that expectation wrt. responsiveness guarantees? In other words, if I'm just interested in throughput are CPU intensive tasks a problem? For example, my expectation is that it would be appropriate to use the new Tokio scheduler to parallelize a compute intensive simulation workload (where inside a "frame" responsiveness is not a problem).
The Tokio scheduler uses cooperative multitasking (non-preemptive). So, if your task runs without yielding it can prevent other runnable tasks from executing.
Is there a recommended approach to dealing with the occassional cpu intensive task?
Supposing you were running an http server and most responses were very quick - but occassionally a request came along that required calculating pi to the n billionth digit.. (for example).. Would you need to farm that request to a separate process - or could you keep it in process but in a separate thread outside of Tokio?
My understanding of that PR is it relates to how the Go compiler does code generation. Rust takes a different approach and is about to ship `async / await` which is a different strategy.
Preemption is out of scope for Tokio as we are focusing on a runtime to power Rust async functions. So, for the foreseeable, Tokio will using "cooperative preemption" via `await` points.
IIRC: one of the issues with the original Rust stdlib greenthread implementation was that it's extremely difficult to preempt execution in a systems language. It's also quite difficult to add userland execution preemption without incurring significant performance penalties.
How do you preempt syscalls or FFI calls? (Go will almost certainly also have this issue with cgo modules)
I would be very surprised if preemptible Futures are something Tokio can or would implement.
What does systems mean here? There is a dirty trick with a NOP and self rewriting code that's quite cheap when not triggered. I think java does it that way.
Which NOP do you overwrite? Do you have to do this for all backward-jump-NOPs in all loaded executable code, or do you have to determine, which loop the thread in question is executing right now?
I noticed that you call `unsync_load` on the `AtomicU32`, which confused me, and I later saw that there is a custom `AtomicU32` in the loom library. Can you explain what `unsync_load` is and whether it will be provided by the atomics library in `std`?
`unsync_load` reads the memory as if it were a normal field (no atomic operation). The `std` atomic types already provide `get_mut` which gives access to the "raw" field when the caller has a mutable reference to the atomic. The mutable access guarantees there are no concurrent threads that can access the field, so it is safe.
The `unsync_load` is used because, at that point, two things are guaranteed:
- The only thread that mutates the field is the `unsync_load` caller
- All other threads will only read from that field.
Because of this, we can just do a "plain old" access of the field w/o the atomic overhead.
As for whether or not it should be in `std`, I don't know. It probably could, but it doesn't have to. It's a pretty "advanced" access strategy.
Can't you get some values "out of thin air" (partial updates of some bits.) Or some intermediate values?
(For example, can the compiler decide to use this memory location to store some unrelated temporary result, as it knows it will erase it soon with a final value and that no other threads is supposed to access this)
It's not undefined because the thread doing the reading is the same one that wrote the value in the first place, meaning there is no cross-thread behavior at the moment and therefore the memory model collapses down to the single-threaded model (where all atomic accesses are irrelevant).
The compiler cannot use the contents of an `UnsafeCell` for temporary storage. In general, `UnsafeCell` is how data can be shared across threads without synchronization.
I thought `UnsafeCell` is only exempt from the aliasing rules, not the memory model? I.e. the compiler can use it as it wants, if it can prove that it's not accessed in the meantime (which can be difficult without relying aliasing rules, but possible if the code is simple enough)
To be honest, I'm not entirely following what you see as the danger. The compiler can't generate code that randomly goes and writes at pointer locations.
I know rust is not C or C++, but we are not programming in x86 assembly, but for the language "abstract machine". And if the compiler infer that this memory location is not used by other threads because we don't use an atomic operation, it can perform optimizations that could result in subtle bugs. That's what undefined behaviour is.
Although in this case, I guess this is probably fine since the non-atomic read can't race with a write.
The code is correct both practically and formally. All unordeeed reads are reading values written by the same thread. Even if the writes are atomic there is no violation of the no data races rule.
x86 does do out-of-order execution however, so while it's true that you'll never read a half-written value, it's still important to use the atomic types to ensure that reads/writes across threads are performed in the right order.
Ordering::Relaxed guarantees atomicity (but not coherence). On 32-bit or 64-bit platforms, a (aligned) 32-bit read or write will always be atomic anyway.
An assembly-level read or write will always be atomic anyway, and in fact a relaxed atomic read/write typically compiles down to the exact same assembly as a normal read/write. However, there are compiler optimizations that can break atomicity, such as splitting accesses into multiple parts; using (relaxed) atomics instructs the compiler not to perform those optimizations.
What do you mean by coherence? If it is the property that all updates to a single memory location are seen in a consistent order by all threads then Relaxed guarantees that.
it doesn't. From cppreference (whose model Rust roughly follows): "Relaxed operation: there are no synchronization or ordering constraints imposed on other reads or writes, only this operation's atomicity is guaranteed"
Yes, a consistent ordering exists but that ordering isn’t necessarily what you think or want it to be. The consistency is present based off the order the reads and writes were executed in; you’ll never read back a value that wasn’t at some point stored there. Which can happen with non-atomic reads/writes, where you’ll read part of one write and part of the next. Reads can still be reordered before writes, as no memory barriers are issued.
Well that doesn't contradict anything that I have said :) My question remains - what do you mean by coherence? I argue that it is precisely the property that there is a consistent order of operations a single memory memory location so you can't say that Relaxed operations don't satisfy coherence.
You are correct. IIRC Coherency is the only property of relaxed atomic operations, as opposed of plain load/stores where concurrent modification and access is just UB.
Last time I spoke about this topic w/ the rust compiler devs, they mentioned there were some LLVM "bugs" with regards to optimizations and Relaxed, as in LLVM is too conservative.
Tiny comment: I think the sentence "However, in practice the overhead needed to correctly avoid locks is greater than just using a mutex." should be part of footnote 1, not the main text.
Assuming [this](https://github.com/fastflow/fastflow/blob/master/ff/buffer.h...) is the FFBuffer in question, it looks like it is spsc (which would not support stealing). Also, it would need some kind of synchronization to ensure consistency between the consumer & producer.
Yes, it's an implementation of the paper they're referencing - "An Efficient Unbounded Lock-Free Queue for Multi-core Systems". And they've build a framework around it (all queues implemented using this structure). Their benchmarks shows improvement (as shown in their paper). Might be interesting to use that in Rust.
But what I miss is a benchmark for various approaches (in Rust, C++ etc.) with trying to use multi core effectively. What I found is that some of the papers use https://parsec.cs.princeton.edu/overview.htm. Probably still better that what we have now - "X nanosec per push/pop".
The advantage of FF is that it is unbounded, but if you add the required mutual exclusion between pop and steal, it will be as expensive (if not more due to the extra complexity).
I thought this was super interesting; it's great to see a solid writeup.
The consumer-side mutex works pretty well, until you take an interrupt while holding it; then, you need to make sure you're using an unfair mutex, or you'll get a lock convoy.
I'm really impressed by the concurrency analysis tool; again for the threadpool, we used model-based-testing to write tests for every permutation of API calls, but we never got down to the level of testing thread execution permutations; that's amazingly good to see, and really builds confidence in their implementation.
> The first load can most likely be done safely with Relaxed ordering, but there were no measurable gains in switching.
This code is using an Acquire/Release pair, except it's Acquire/Release on different memory slots, which means there's no actual happens-before edge. This makes the Acquire/Release pair somewhat confusing (which tripped me up too in the first version of this comment).
Furthermore, I don't see anything in here that relies on the head load here being an Acquire. This Acquire would synchronize with the Release store on head in the pop operation, except what's being written in the pop is the fact that we don't care about the memory anymore, meaning we don't need to be able to read anything written by the pop (except for the head pointer itself).
This suggests to me that the head load/store should be Relaxed (especially because in the load literally all we care about for head is the current pointer value, for the length comparison, as already explained by the article). The tail of course should remain Release on the push, and I assume there's an Acquire there on the work-stealing pop (since you only list the local-thread pop code, which is doing an unsynced load here as an optimization). I don't promise that this is correct but this is my impression after a few minutes of consideration.
I'm not done with the article yet ;) (BTW I just updated my comment, not sure if you saw the first "another comment" addendum but I got it wrong and rewrote it)
If I have the time tonight I'll try to look over the PR. No promises though.
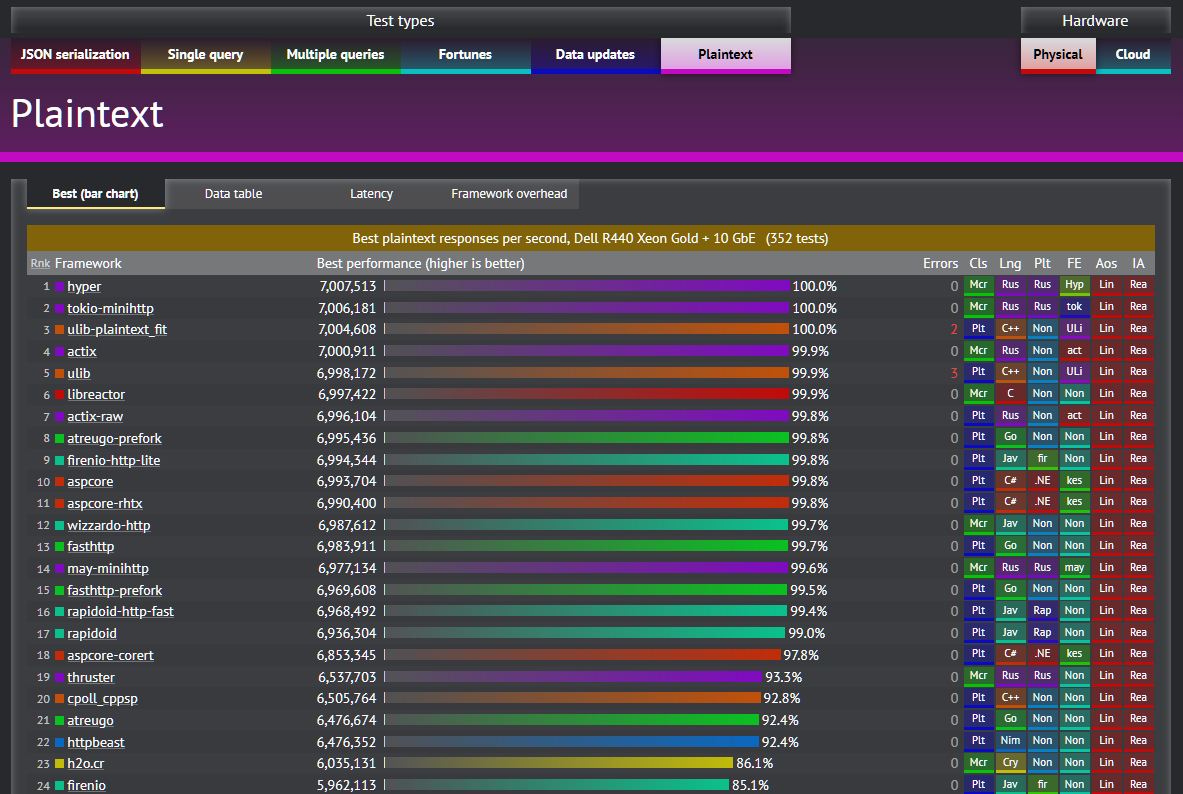
FWIW: Hyper is among several that are bandwidth-limited by the 10-gigabit Ethernet in our (TechEmpower) Plaintext test. We hope to increase the available network bandwidth in the future to allow these to higher-performance platforms an opportunity to really show off.
In the Round 18 Plaintext results that the OP linked to [1], you can see a pretty clear convergence at ~7 million requests per second, which I've screen captured in [2].
How can you tell how each test is bottlenecked? Is it something as simple as saying that if the processor isn't at 100% utilization then the bottleneck is somewhere else?
I read a long time ago about how the linux kernel handled incoming packets in a really inefficient way that led to the network stack being the bottleneck in high performance applications. Is that no longer true?
I'd love to learn more about this whole area if anyone has any good links.
It's generally possible to go 3x-10x faster than Linux if you make some tradeoffs like dedicating cores to polling. See https://www.usenix.org/node/186147 and https://wiki.fd.io/view/VPP/What_is_VPP%3F Moore's Law excuses a lot of sins, however, so on the latest servers Linux is probably adequate up to 100 Gbps for most use cases.
So the theoretical optimum is 14.88 Mpps (millions of packets per second). That's with the smallest possible payload. You need to divide that by two because the test involves both a request and a response, which gives you 7.44 million requests per second as the theoretical maximum.
The best tests max out around 7 M rps. This gives an implied overhead of about 6%, which corresponds to the HTTP overhead.
You're right.
But I assume the benchmark basically implements a ping-pong game instead of DoSing the server to see how many requests actually survive (I could be wrong).
The benchmarks test something very specific: A ton of tiny requests on keepalive connections. Those tiny requests are not very IO efficient, and therefore 10GBit/s is already a lot.
However if you would add a benchmarks to download 10MB static files the network utilization would likely go a lot up - even if the same frameworks are used.
From a QA perspective, I feel like you buried the lede on this Loom tool. Benchmarks are nice, but confidence is an elusive thing when it comes to non-trivial concurrency.
I'll be spending some time on the CDSChecker and dynamic partial-order reduction papers.
Warning, since I've never written line of Rust code never mind working with Tokio I might be just full of it. If that's the case please forgive me ;)
From a short glance my understanding of Tokio is that at high level it is an execution environment that basically implements data exchange protocols based on asynchronous io.
Then they say the following: Tokio is built around futures. Futures aren’t a new idea, but the way Tokio uses them is unique. Unlike futures from other languages, Tokio’s futures compile down to a state machine
So the question here is why not to expose generic state machine framework (FSM/HSM) which can deal with those protocols but is also very useful for many other tasks as well?
> So the question here is why not to expose generic state machine framework (FSM/HSM) which can deal with those protocols but is also very useful for many other tasks as well?
Short answer is: you can.
Tokio is more like "node.js for Rust" or "the Go runtime for Rust".
The bit about Tokio & futures is how you use Tokio today. Tasks are defined as futures, and Rust futures are FSMs. So, a protocol can be implemented as a FSM completely independently of Tokio / futures and then used from Tokio.
In Tokio's next major release (coming soon), it will work with Rust's async fn feature (which is also about to hit stable).
So, a protocol can be implemented as a FSM completely independently of Tokio / futures and then used from Tokio
But that was the point of my question. Since you've already built that FSM framework inside, why not to expose it? Or I guess it might be too specialized for your particular case.
No; it re-exports the standard futures. Its purpose is two-fold: one, it's where futures were experimented with before they got into std, and two, it's where extra functionality can live. We only put what was absolutely necessary into std.
Not quite. The futures crate, version 0.1, contained a definition of the `Future` trait and a bunch of the combinator methods. This was iterated on a lot. Eventually, the bare minimum traits were added to the standard library.
The futures crate, version 0.3 (released under the name `futures-preview` right now with an alpha version number), contains the helper methods for the standard library's trait.
A major part of the FSM generation is a language feature in Rust, (async/await), not a feature of Tokio. (I'm assuming we are speaking about the incoming version 0.2 here.) Tokio just leverages it. On the other hand, Tokio and the surrounding ecosystem have built all kinds of helpers around that, mentioned in the sister comment.
My guess is that they don't want to have to maintain a separate stable public API for what is currently some internal mechanics. Maybe in a few years when the FSM is more or less set in stone, someone will expose it.
Thank you for posting articles like these.
I feel a bit relieved seeing how its not demigods with decades of in-domain experience who create sometimes huge, monumental modules or building blocks of whole languages, but instead: actual human beings who might have been short on options, time or bought into some technical debt in the process of creating something useful.
First of all, great article! Lots of interesting details and great explaination.
A few questions:
Did you consider work sharing or work requesting instead of work stealing (the global queue is a form of work sharing of course)? With work requesting you can avoid the required store/load on the pop path. Of course work requesting is not appropriate if the scheduler need to protect against the occasional long running job that doesn't yield to the scheduler in time to service a work request with appropriate frequency, but assuming this is rare enough, an expensive last resort work stealing path could be done via asymmetric synchronization (i.e. sys_membarrier or similar), keeping the pop fast path, well, fast.
Is there any way to make (groups of) tasks be constrained to a specific scheduler? This is particularly useful if they all need to access specific resources as there is no need of mutual exclusion; this works well in applications were executors are eterogeneous and have distinct responsibilities.
Because of the global queue and the work-stealing behaviour, absolutely no ordering is guaranteed for any task, is that correct?
I find surprising that you need to reference count a task explicitly. Having implemented a similar scheduler (albeit in C++), I haven't found the need of refcounting: normally the task is owned by either a scheduler queue or a single wait queue (but obviously never both). In case the task is waiting for any of multiple events, on first wake-up it will unregister itself from all remaining events (tricky but doable); only in the case were is waiting for N events you need an (atomic) count of the events delivered so far (and only if you want to avoid having to wake up to immediately go to sleep waiting for the next event). Also this increment comes for free if you need an expensive synchronization in the wake-up path.
That's all so far, I'm sure I'll come up with more questions later. Again great job and congratulations on the performance improvements.
> Did you consider work sharing or work requesting instead of work stealing
Not really. It did cross my mind for a moment, but my gut (which is often wrong) is the latency needed to request would be much higher than what is needed to steal. I probably should test it though at some point :)
> assuming this is rare enough, an expensive last resort work stealing
It's not _that_ rare. Stealing is key when a large batch of tasks arrive (usually after a call to `epoll_wait`). Again, I have no numbers to back any of this :)
The idea is to steal only if request fails to return work in a reasonable time frame i.e. if a job is keeping the scheduler busy for more than a minimum amount of time.
I also have no number to back it up (we deal wit a relatively small numbers of fds at $JOB and we care of latency more than throughput), but I do not buy epoll_wait generating late batches of work: it seems to me that you should only be using epoll for fds that are unlikely to be ready for io (i.e those for which a speculative read or write has returned EWOULDBLOCK), which means you should not have large batches of ready fds. Even if you do, the only case you would need to steal after that is if another processor run out of work after this processor returned from epoll wait (if it did before, it should have blocked on the same epoll FD and got a chunk of the work directly or could have signaled a request for work), which might be less likely.
Anyway at the end of the day a singe mostly uncontested CAS is relatively cheap on x86 especially if the average job length is large enough, so maybe it is just not worth optimizing it further, especially if it requires more complexity.
> I find surprising that you need to reference count a task explicitly.
This is likely due to how the task and waker system is defined in Rust. A Waker is kind of a handle to the task, whose lifetime is indefinite. Some code can have a handle/Waker to a task which already has finished long ago. One way to make sure the handle is still valid is to reference count it. Since in the Tokio system the Waker/handle and the tasks internal state are actually the same object, this means the combined state gets a reference count.
Rust, as a systems language, doesn’t include a large runtime. It’s about the same size as C or C++‘s. But if you want to do asynchronous IO, you’ll need a runtime to manage all of your tasks. Rust’s approach is to include the interface to make a task (futures and async/await) into the language and standard library, but lets you import whatever runtime you’d like. This means that you can pull in one good for servers, one good for embedded, etc, and not be partitioned off from a chunk of the ecosystem. And folks who don’t need this functionality don’t have to pay for it.
Tokio is the oldest and most established of these runtimes, and is often the basis for web servers in Rust.
So yeah, “the node event loop as a library” is a decent way to think about it.
> Rust’s approach is to include the interface to make a task (futures and async/await) into the language and standard library, but lets you import whatever runtime you’d like.
Why is this better than having one official, standardized, optionally importable runtime?
1. official - it's not clear how this would be better; that is, the team is not likely to have more expertise in this space than others do
2. standardized - it is standardized, as I said, the interface is in the standard library
3. optionally importable - this is fine, of course, but so are these, so this attribute isn't really anything better or worse.
But I don't think this is the biggest strength of this approach, the big strength is that not everyone wants the same thing out of a runtime. The embedded runtimes work very differently than Tokio, for example. As the post talks about, it's assuming you're running on a many core machine; that assumption will not be true on a small embedded device. Others would develop other runtimes for other environments or for other specific needs, and we'd be back to the same state as today.
From what I know about Akka, I believe Akka does more than Tokio. For example, Akka manages a supervision tree. I believe Akka is trying to be more of an actor system where as Tokio is just trying to provide an asynchronous runtime for Rust.
Isn't node a single threaded event loop, while this and Go use multiple threads and queues to support multiple threads and processors?
They even went into that with the comparison with Seastar.
If this is better than Seastar, someone should start on porting ScyllaDB to Rust. Does Rust have a userspace TCPIP stack like Seastar? I think that is the other major advance Seastar uses for speedup.
Yes, it's confusing that Akka does both Futures and Actors (that it's well-known for). I've used and really liked Akka Futures so would probably much like Tokio.
Oh man, I really wish ya'll had chosen a name other than "Loom" for your permutation tool. Loom is also the name of a project to bring fibers to the JVM.
Really cool. Tokio is the core of Linkerd (https://linkerd.io) and I am really excited to see exactly what kind of impact this will have on Linkerd performance. A super fast, super light userspace proxy is key to service mesh performance.
The result is pretty impressive. Go's scheduler is not this good. When my Go GRPC servers get up near 100,000 RPS their profiles are totally dominated by `runqsteal` and `findrunnable`.
Weird. In one of my Go explorations I wrote a naive trade algo backtracker which ingested 100,000 datapoints per second from SQLite on commodity hardware.
I'd expect something highly specialized such as GRPC server to perform better.
True. But in my case the code also distributes these datapoints to multiple threads, computes technical indicators and simulates tradings while gathering statistics to finetunne parameters.
The only optimization I've done was to ditch maps wherever I could. They were dominating flamegraphs.
This is why I expected GRPC to perform better. But I agree it depends heavily on what's being done.
"Because synchronization is almost entirely avoided, this strategy can be very fast. However, it’s not a silver bullet. Unless the workload is entirely uniform, some processors will become idle while other processors are under load, resulting in resource underutilization. This happens because tasks are pinned to a specific processor. When a bunch of tasks on a single processor are scheduled in a batch, that single processor is responsible for working through the spike even if other procesors are idle."
The trade off of this is high performance over uniform utilization, which is a better goal than loading cores evenly. And all you have to do to make use of it is a bit of thought about your load distribution, but you also have plenty of thought budget here by not having to think about synchronization. Stealing work from other queues is not going to be faster, it's going to be wasted on synchronization and non-locality overhead and would require you to do synchronization everywhere, not a good direction to pursue.
Other parts of the Rust ecosystem have had great luck using work-stealing queues. There's a talk about how Rayon did this[1] and a good article about using it in Stylo[2], a new CSS engine written by Mozilla.
The thesis of Practical Parallel Rendering was that any useful task distribution strategy requires a work stealing mechanism because you are leaving serious amounts of responsiveness on the table if you don't.
With an infinite queue, the same number of tasks per second happen either way, but the delay until the last task you care about finishes can be pretty substantial.
as far as i understood (though i have to admit i didn't understand much) you can use different schedulers.
i haven't had a closer look at rust in general, async and tokio, but i suspect you can use the different schedulers in the same codebase. can someone comment on this?
if that was the case one might use a different runtime for more uniform workloads to maximize throughput, while using tokio for general purpose async work.
After all this time, I'm amazed at how many people still think that cooperative multitasking is always the best strategy.
Cooperative multitasking works great as long as everyone is cooperating. Guess what? Cooperation is a voluntary act. If people are ignorant of their impact or min-maxing between five different 'top priority issues', they aren't going to stay on top of it at all times and in all things.
The cost of freedom is eternal vigilance, and the quarterly roadmap doesn't list it. Which is why we use preemption most of the time. It reduces the blast radius at the cost of some efficiency.
All this is just the preemptive versus cooperative argument wearing new hats.
Preemption and cooperation are unrelated to any of it, you can have affinity or lack thereof with either of them. This is about misunderstanding of trade offs, as if work stealing can somehow fix slow broken shared memory multithreading model. It can't, the only way to fix it is to get away from it.
Amortized cost algorithms are everywhere, including (or perhaps especially) in concurrency management code. Is there a memory allocator in any threaded programming language today that doesn't use a variant of thread local allocators? Getting two or three orders of magnitude out of a solution is not something to sniff at.
These queues each execute tasks sequentially. The library provides for multiple queues to run in parallel. All of these scheduling problems and patterns begin to look fundamentally similar if you stop getting hung up on the implementation details. Separate queues have worse 'behavior' than shared queues, which have worse behavior than sequential operation. Except for the extremely real and very huge problem of utilization. Avoiding utilization problems by forcing that mental work onto the callers is exactly the argument of cooperative multitasking; you could make it work, if you were as smart as we are.
Transferring a block of tasks at one go reduces the use of concurrency primitives. But now your worst-case behavior is worse. Solution? Provide way to avoid worst-case behavior. Even if it's more expensive, it only runs infrequently, so the cost is still amortized.
Usually these libraries strongly recommend that your jobs be working with independent data. So I don't buy the shared memory argument. There are in fact tasking libraries in other languages, like Node, that push the tasks off into a separate process, and yet still have the same class of concerns.
You are arguing that if they put more thought into the usage that the library wouldn't need to do the work.
That's not how software works. Blaming others for not thinking hard enough is what fragile smart people do to prop up their egos, instead of getting to the hard work providing real solutions. Essentially, all of these problems were identified in the 70's, and yet there's still plenty of R&D dollars in this space because this shit is hard. Being flip about it is not helpful.
It sounds like you might be arguing the relative merits of preemptive multitasking in some generic case rather than the specific domain tokio operates in.
Tokio is a lot about IO. The resources the scheduler is waiting for will almost exclusively be network and file operations.
There is a risk that a task does some long running CPU work on the back of a future or uses sync network/file operations. Maybe a preemptive scheduler could help then, but I'm not convinced by your argument that tokio needs to optimize for this.
From the article: "While it is possible to design a system where resources, tasks, and the processor all exist on a single thread, Tokio chooses to use multiple threads. We live in a world where computers come with many CPUs. Designing a single-threaded scheduler would result in hardware underutilization. We want to use all of our CPUs."
Sorry, the article must not have been clear. If you can point out where in the article you got the impression there were multiple processors per thread, I can try to update the article to fix.
I just got a bit into the “One queue, many processors” section and that’s where I got confused. Knowing it’s one processor per CPU is the information I needed. Thanks!
Not OP, but I had to go back and double check that this was true when I saw that the Hyper benchmark at the bottom only used 1 thread. Wouldn't you want to test on multiple?
The Hyper benchmark uses multiple threads. When I ran the benchmark, I modified the version found in Hyper's github to use both the old multi-threaded scheduler and the new multi-threaded scheduler.
Not to be snarky, but the easiest way to get a 10x speedup is to make the previous one 10x too slow. 10x feels pretty good until you find out it was really 40x too slow. I say this only because getting 100x improvements on naive designs has led me to be suspicious of 10x improvements. The principle is that where 10x was available, more is there.
The writeup doesn't mention design choices in Grand Central Dispatch. Is that because we have moved on from GCT, or because it's not known?
Also worth noting that the 10x improvement is for tokio's own benchmarks, and even there only in one of the four. The hyper benchmark saw "only" a 34% improvement.
There were no unchecked facts in the original post. It is a fact that I have got 100x speedups, and it is my personal experience that 10x speedups rarely come close to exhausting the opportunities.
It is a fact that I did not notice any reference in the article to GCD or the techniques that have made it a success.
{kind=link}
I do want to make clear that most of the optimizations discussed are implemented in the Go scheduler, which is where I discovered them. I wrote the article to call them out as they were not easy to discover.