This is a great question, I also want a way to search the internet but exclude all major media domains as well as any company over a certain size. So I just want to search through old blogs, SO, non-corporate social media, weird forums, etc.
There are so many cool things I remember reading on the web like 10-20 years ago that still exist that are so buried now on Google they might as well not exist. Nowadays searching any topic seems to always lead you to CNN and Microsoft and Facebook and other huge corporations. Search results are just becoming more sanitized and beige and meaningless every day.
For years, my trick for finding interesting content was to go to, say, the 7th page of Google results, and start there. This doesn't work anymore -- it's SEO-optimised listicle blog posts all the way down.
My trick now is to use Twitter to discover interesting people, and follow them there. Granted, it's not a search engine, but it's at least given me the ability to discover weird things again.
One of the things I enjoy doing on Twitter is posting up something I'm working on, and then clicking through to all the profiles of the people who like, comment, or retweet my work. I stumble across an incredibly diverse range of people by doing this, many with conflicting opinions to my own, and many who belong to strange subcultures that I don't understand, but who were all drawn to my work for one reason or another.
I think there's definitely a danger of crafting a bubble for yourself if you choose to use it that way, but as a tool for discovering people making cool stuff who otherwise wouldn't cut through the noise on something like Google search, I haven't found anything better.
Many times I have thought about what could happen if Twitter asked you to recommend up to 3-5 people you value, and write a tweet-sized (or shorted) recommendation.
Over time you would get a 'pagerank for people' and could do awesome stuff with that, like 'You don't know XYZ, but 3 people you trust trust her, and this is what they tell about her:' ...
I was about to ask about dmoz.org. But apparently it's dead. We could probably do something with bookmark sharing à la Delicious. Good dead things for a better future.
Heh, I was trying to do research on coronaviruses (of which COVID-19 is one of many coronaviruses), but Google sanitized the result and only showed me "official" COVID-19 resources and buried the broader coronavirus resources.
Giving you the benefit of the doubt, and assuming this isn't just pedantry, especially since you're getting downvotes (because I assume everyone thinks this is just pedantic correction) I looked it up.
In the context of "trying to do research on coronaviruses" your comment appears to be not only correct but an important distinction, rather than the pedantry it appears to be.
From Wikipedia: "...more lethal varieties [of coronaviruses] can cause SARS, MERS, and COVID-19."
And...
"Severe acute respiratory syndrome coronavirus 2 [SARS-CoV-2] is the strain of coronavirus..."
Which can be further abbreviated as C19. I have seen this in personal chats and wonder how long it will be before it gets into newspaper headlines where space is at a premium in print editions.
I know you are relaying the public information accurately, but I wish authorities pushed better names. Like calling the virus "the virus that we know has a corona and causes these symptoms" and the disease "the disease caused by this virus that has a corona and that causes these symptoms" is circular. Also, it is not true that it is entirely a respiratory syndrome. There are serious non-respiratory symptoms, extent of which we are to discover. Finally, if it is a syndrome causing virus, by definition we wouldn't have the crisp boundaries of a disease around it, which indeed we don't.
If these were names for services and classes that came in a code review, how many would really approve?
[retracted] and I hope this is just a misunderstanding. As the director of the World Health Organization (WHO) said, 2019-nCoV is a novel (new) coronavirus.[0] The CDC defines coronavirus as a virus that was not previously known — check the FAQ, “what is a novel coronavirus?”[0.5]
They changed the name of this coronavirus to reflect the disease more accurately to COVID-19.[1]
The CDC has a list of other coronavirus’ that have existed.[2]
Edit: Since there seems to be a misunderstanding from everybody’s part on this as it’s referred to as both and often interchangeably in a mainstream setting, take a look at John Hopkins guide: https://www.hopkinsguides.com/hopkins/view/Johns_Hopkins_ABX...
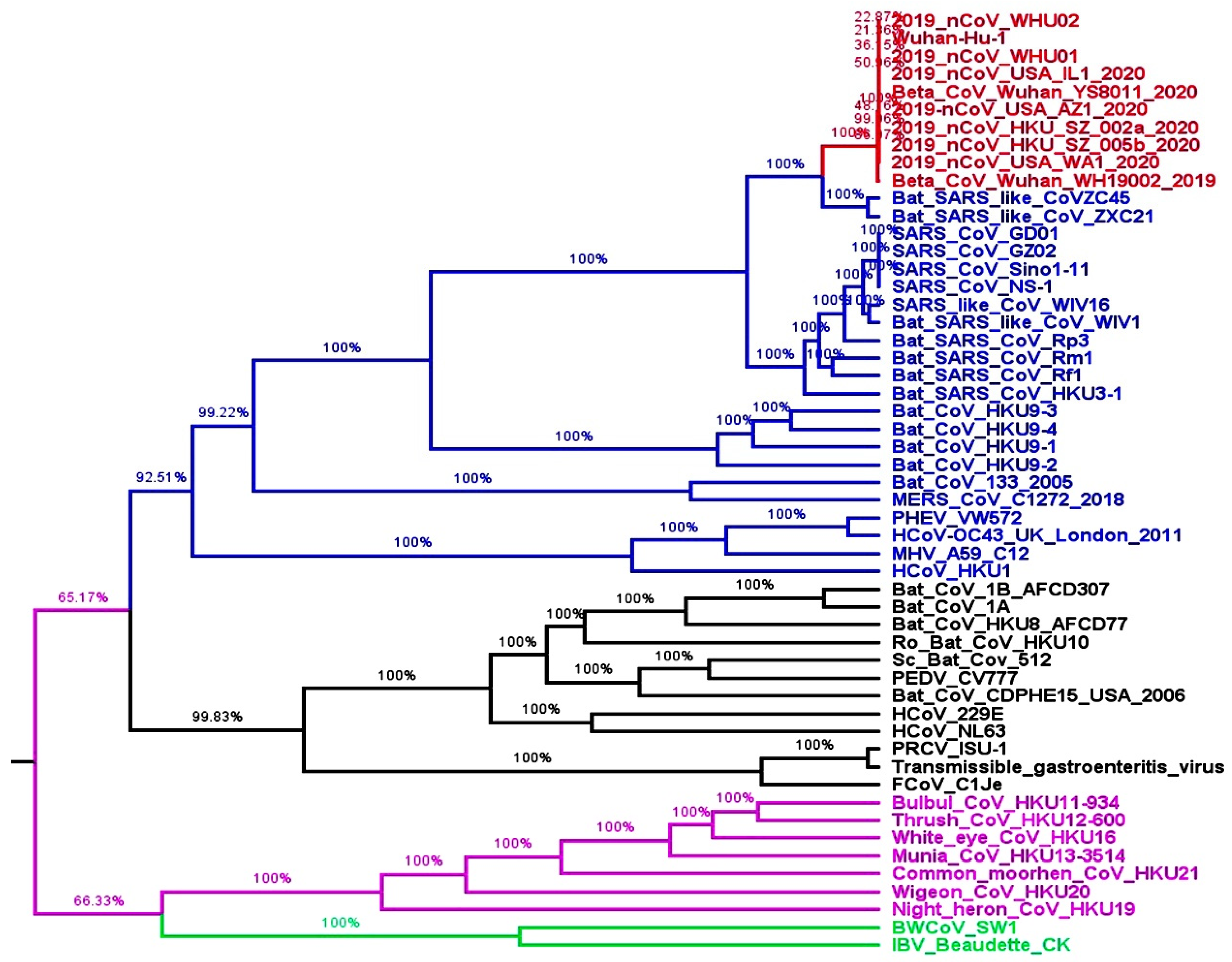
Excuse the incivility, but no. SARS-CoV-2 is not a strain or type of SARS-CoV. The viruses share ancestors, but SARS-CoV-2 did not come directly from SARS-CoV. SARS-CoV and SARS-CoV-2 are in the category of beta coronaviruses[0].
"The whole genome-based phylogenetic analysis presented that two Bat SARS-like CoVs (ZXC21 and ZC45) were the closest relatives of SARS-CoV-2."[1]
While we're on the topic of linguistic pedantary, strain isn't exclusive to direct mutations from a parent genome. Strains, like much of biological taxonomy, are a human abstraction to make communication of the idea of -- in this case -- "a virus sharing similar properties to coronaviruses that cause severe acute respiratory syndrome" -- albeit this is a very simplified definition for the sake of brevity.
SARS is caused by SARS-CoV-1 and COVID-19 is caused by SARS-CoV-2.
Rather, if we would like to be absolutely correct about these classifications, we would say SARS-CoV-1 and SARS-CoV-2 are both strains of SARSr-CoV (Severe accute respiratory syndrome related coronavirus), which in itself is a species, an abstract concept used to group related organisms into a convenient umbrella term.
There is no "eukaryote" organism the same way there is no "SARSr-CoV" organism. The added "r" was a recent addition when COVID-19 was discovered.
I will cede that I didn't specify this last point, and you were correct to point it out.
GP was pointing out that this was incorrect, and you just made that point by stating it yourself.
Assuming you are intending to engage in the conversation and not be a pedant, I might let you know that your replies are coming across quite coarsely. More specifically, as to prefaces on earlier comments, there is no need to excuse incivility, because there is no need for incivility here.
I found the exchange to be more than civil, with pleasantries not being taken in the literal sense.
At least this did not fall into the category of "Cold regurgitation of data" (quite popular it seems) and had a level of warmth that was an indication of passion, more than anger (from all parties).
If they added a temperature social cue to HN comments..... That would be funny.
"Is there a search engine which excludes the world's biggest websites?"
There was "rebranded" web search that someone created a number of years ago and posted on HN that aimed to exclude the top websites from results. I cannot remember the name he gave to the project.
One way to exclude the world's biggest websites when using Google is to restrict the search to TLDs other than .com, .net and .org. The root zone is full of silly new TLDs that no one uses for large websites. There are hundreds to choose from.
It is kind of funny that we talk about SARS-COV-2 as if it is the only coronavirus. Coronavirus, singular. If I’m not mistaken the common cold is in the corona virus family.
I have a theory that web crawling alone is not the best way forward to find the most relevant results because of the volume of content continually being created, much of which is niche and sometimes dynamic.
Instead I believe linking together vertical search sources that have targeted information based on search intent will provide better results.
I created Runnaroo [0] for that purpose. If you search a programing question, it will pull traditional organic results from Google, but it will also directly query Stack Overflow for a deeper search.
This is somewhat ironic because 20 years ago, hobbyists would frequently put their obscure personal pages on Geocities and other large corporation's web space.
Memory can be foggy but the most useful were hosted on university pages or random folders off a random domains or you get a subdomain. I picked the username 'search' which gave me search.batcave.net which worked great until one day they just took over the subdomain for a site wide search. They were confused when I complained.
Sure people hosted on geocities and tripod and they were the biggest and easiest to remember. But quality of a geocities page compared to a mit student page was much lower.
20 years ago, it was extremely common for your ISP to give you 5MB or whatever of space to use. users.ispname.com/~yourname or whatever. It was great, tbh, since anyone with cuteftp and notepad could publish to the world.
Hey! I actually liked this idea and I'm considering starting a learning project on it. I've seen a lot of interest and ideas in the comments, and decided to create a very short Google form to start gathering all the interested people so we can organise something interesing. Is anybody in? :)
If there was a way to simply exclude from searches: shopping, news, images, videos, and “listicles”, I think that would get us most of the way.
Especially shopping. The endless stores are the worst part of search results. If I search for anything that remotely looks like a product, the results are just choked with store after store trying to sell me the thing. Awful.
{kind=link}
There are so many cool things I remember reading on the web like 10-20 years ago that still exist that are so buried now on Google they might as well not exist. Nowadays searching any topic seems to always lead you to CNN and Microsoft and Facebook and other huge corporations. Search results are just becoming more sanitized and beige and meaningless every day.