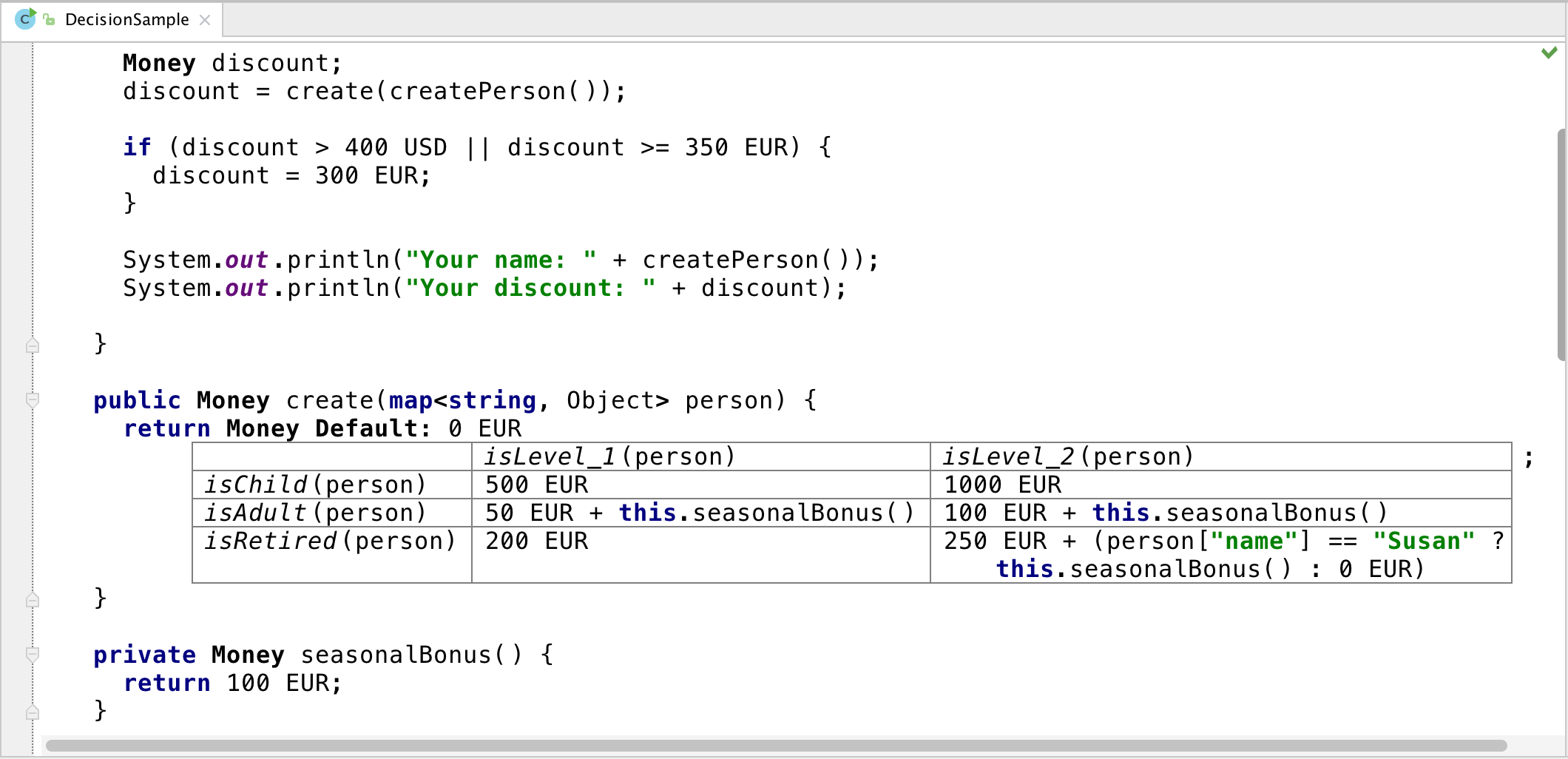
Logic tables are a secret weapon when refactoring spaghetti code.
You take all the conditions relevant to the part you're refactoring.
You refactor common parts of the conditions (so if one if has (x>3 & y<2) and another if has (x>3 and y>10) you get (x>3), (y<2), (y>10).
You put that into a table, write all possible values that can happen (sounds like combinatoric explosion but it's usually not, because many of them depend on each other and lots of combinations cannot happen or aren't relevant to the result) - then rewrite the whole thing looking at the table.
x>3 | y<2 | y>10 | effect
F | F | F | ...
T | F | F | ...
F | T | F | ...
T | T | F | ...
F | F | T | ...
T | F | T | ...
It's usually not a truth table, the "effect" column is stuff like "call f1 then f2" or "call f2 then f1 then f2 again".
You can transform it into a truth table by pulling these into input variables "f1ShouldBeCalledFirst", "f2ShouldBeCalledFirst" etc, or by using separate table for each binary decision, but that was overkill for my needs and it caused combinatorial explosion. YMMV.
Decision table's are really good at representing complex rules, in a language with pattern matching u can convert a nested if else block to a decision table that is much more readable, as an example see https://github.com/finos/morphir-examples/blob/master/src/Mo...
You can also use sth like Map<List<Boolean>, Result> in languages with no pattern matching. Sadly map literals aren't pretty in some of these languages, but it's still better than a bunch of nested if-then-elses or switches.
In the past I have just worked some hairy logic on a spreadsheet and just manually migrate it to code / nested conditionals.
This other article [1] shows some really cool ways to writes decision tables using structured editing UI. I wish structured editors where more commonplace!
This article gave me a fair bit of nostalgic feelings. So much so, that I had to go and dig out one of my first university assignments from seven years ago[!], writing a simple Linux Shell, where I actually had to use "decision tables". In my case I remember thinking about using an automata for a grammar to prevent my code from becoming an unmaintainable, unexplainable, SEGFAULT-y mess.
Most important of all, I remember the lecture assistant telling us that we "won't pass the assignment as long as I can bring your program to SEGFAULT."
Many of us struggled, SEGFAULT after SEGFAULT, with uneven quotes, pipes inside or outside quotes, double bars, double ampersands, etc. As the days progressed, many code-bases became more complex and more fragile as we tried to deal with the pesky inputs of the lecture assistant. When our turn came up, we all grinned while the lecture assistant tried in frustration to bring our shell to SEGFAULT. I remember pointing out "those inputs are not supported by the grammar, and walking him through the bits I list below". Those were the days, oh man :)
Interesting that you did this as part of a course! It makes a lot of sense, as I agree shell has a lot of conditionals to handle. I would say that the segfaults are an instance of the "else-idgaf anti-pattern" where the corner cases are undefined/broken. This seems to happen a lot in bash.
I use regular languages a lot in the Oil shell precisely because it forces every state and transition to be defined:
It looks like "else-idgaf" is meant to describe not considering all cases. What do you think about pushing input validation to the caller; you write code that explicitly considers some subset of all possible inputs and thoroughly document that subset -- behavior for other inputs is not guaranteed.
I think if you have an assert() for the invalid input, that makes sense. I don't think documentation is enough in practice.
In my experience, you can write "don't call this with 0" in the comments, or you can write it in the documentation -- it doesn't matter. Someone will call it in an unexpected way. They will make it work for the happy path and not consider the other cases, because that takes time. (And that includes myself in many instances.)
So the only way to be sure is to blow up and make it a hard bug.
----
I'll also note that very few functions are public APIs with documentation. I'm thinking about the bash codebase, which has 140K lines of C written over 30 years. There are a lot of informal internal APIs, and few documented APIs.
They are kinda stable but also subject to change. So I think assert() is the best way of "documenting" the expected invariants in these cases, which comprise the vast majority of coding situations.
A few years ago I was working with JetBrain's MPS [1] and got excited about it's projectional editor, which allows for different "projections" of your code, not just linear text. One of the things this enables is using descision tables directly within your code [2], as well as a bunch of other things like math notation or graphs for statemachines [3]. Being able to use another notation than just plaintext can make some code a lot clearer.
I know this isn't going to replace code as text anytime soon, but it looked really interesting. Does anyone know of other projects experimenting with representing code in other ways?
Mesh Spreadsheet is explicitly designed to make it easier to view and write decision tables with a projectional editor, while keeping the code as text for storage, version control, etc.
Oh, and another thing, so I'm making another comment.
> Input Elimination: Often by using - we find that a column is unnecessary
I've found this to be true in many cases. However, efficiently calculating a potential "input elimination" has eluded me.
I've done research into various relational-database techniques. I've looked at binary decision diagrams (or their relational multi-valued counterparts: Multi-Valued Decision Diagrams). Etc. etc.
It is "obvious" that minimizing columns and removing unnecessary columns can grossly improve performance. But I can't find any efficient algorithm that detects this case.
Lets say we have Table ABCD (with 4 columns: ABCD). To test if Column C can be eliminated, I came up with:
ABD = (Select a, b, d from TableABCD where C = true)
ABD2 = (Select a, b, d from TableABCD where C = false)
If ABD == ABD2, then C is redundant.
That's for binary variables. If C has multiple values, then you have to do this for every value C could have.
-------
This seems inefficient to me. Especially if I'm checking every column to see if they're redundant. (Repeat the above process for A, B, and D). I feel like there has to be some kind of dynamic-programming magic (or even Greedy-algorithm) that can figure out the redundant columns all simultaneously. I just don't feel like coming up with the algorithm.
I can't believe that I'm the first one to investigate this problem. But I don't know the "magic word" for this to search on. I don't even know how to search the internet for this algorithm, even though I know its important. If anyone knows the most efficient solution, please let me know :-)
I'm looking at a lot of these... and it seems like coding of these "tables" needs to be discussed.
The most obvious decision-table encoding is the humble bitset. For example:
A B C | T/F
---------
0 0 0 | T
0 0 1 | F
0 1 0 | T
0 1 1 | T
1 0 0 | T
1 0 1 | F
1 1 0 | F
1 1 1 | T
Which would be represented as: 0x9D (10011101-binary), a simple 8-bit number (one byte).
Unfortunately, this table grows exponentially: 11-variable tables require 2048-bits, but this is still a 256-byte value that can be manipulated in a single-clock tick on AVX2 systems (Zen and Skylake). AVX2 supports AND, OR, NOT, XOR in a single clocktick (heck: Skylake supports 3 256-bit boolean instructions per clocktick. Zen2 supports 4 per clocktick)
---------------
While 2048-bit (11 variable) tables maximize memory bandwidth through SIMD instructions, the real "rich" instructions exist in the 64-bit world. I don't feel like making this post much larger, so I'll just note a brief summary now.
* Popcnt -- Provides a "Select Count( * ) from table", so to speak. 1-clock tick on Skylake, 4-per-clock tick on AMD Zen.
* PEXT -- Parallel-Extract, a bitwise gather command. 1-clocktick on Skylake (unfortunately slow on Zen: 18 clocks). This is your "Select" statement. Take the 8-bit (3-column) table 0x9D as an example (10011101-binary). PEXT (10011101b, 10101010b) == 1010, which so happens to be equivalent to "Select A,B from table where C=True".
Some other examples:
PEXT (table, 01010101b) is "Select ... where C=False".
PEXT (table, 11001100b) is "Select ... where B=True".
PEXT (table, 11110000b) is "Select ... where A=True".
PEXT (table, 00001111b) is "Select ... where A=False".
* PDEP -- Parallel Deposit, a bitwise scatter command. This is the exact opposite of PEXT. If you're building a larger table from a smaller one, getting ready for a "join" operation, this is useful. Ex: "Expanding" a hypothetical "AB" table into a "ABC" Table (making room for the new "C" column) can use the PDEP instruction.
* Summary: PEXT "Reads many column in parallel", while PDEP "writes many columns in parallel".
* Where PEXT and PDEP are inefficient (ie: everything outside of Intel chips), a careful mix of bitshift-and-AND operations can implement the above operations with reasonable speed.
* BLSR -- Reset lowest bit. The 0x9D table is converted into 0x9C, a useful operator for "iterator++" in C++ terms. For example, 0x9D across repeated BLSR commands changes as follows: 10011101, 10011100, 10011000, 10010000, 10000000, and finally 00000000. See TZCNT for more info.
* TZCNT -- Trailing Zero Count. A useful operator for "*iterator" in C++ terms. For example, the TZCNT(10011101) == 0, TZCNT(10011100) == 2, TZCNT(10011000) == 3. To convert fully into ABC column form, simply write out the index in binary. For example, "TZCNT(10011000) == 3", or 011 in binary (A=false, b=true, c=true).
"TZCNT(10010000) == 4" becomes 100 in binary (A=true, b=false, c=false).
------
64-bit Popcnt, BLSR, TZCNT are all implemented in GPUs by the way. PDEP / PEXT is an Intel CPU-only trick, but its definitely one of the coolest operators I've seen.
Given that all of these instructions can be implemented in 1-clock tick on most hardware (except PDEP / PEXT), it seems important to learn how to use these instructions. Especially if you're manipulating logic tables in the form described in the blogpost.
-------
This area of super-optimized bitmask based programming wraps full-round to Relational Algebra and SQL. Its a very intriguing corner of Comp. Sci for me.
Arguably, the classic "Table form" that typical SQL-databases use are simply the sparse-matrix form of these bitmasks I described above. Otherwise, the operators are identical in concept.
It also should be noted that hardware exists that executes these bitmask-tables extremely efficiently. Its called an FPGA (which these days, are primarily composed of 6-LUTs, or 6-column look up tables, aka 64-bit numbers). Manipulation of these tables alone is Turing complete!
{kind=link}
You take all the conditions relevant to the part you're refactoring.
You refactor common parts of the conditions (so if one if has (x>3 & y<2) and another if has (x>3 and y>10) you get (x>3), (y<2), (y>10).
You put that into a table, write all possible values that can happen (sounds like combinatoric explosion but it's usually not, because many of them depend on each other and lots of combinations cannot happen or aren't relevant to the result) - then rewrite the whole thing looking at the table.
Another form is Usually if the code is old enough there's redundant branches, checking conditions that can't happen, duplicated code "just in case", etc.With the table you can look at it and see input-output and refactor it without worrying about changing behaviour.
For simple cases it's overkill, but with big enough mess it's a life-saver.