As a former linux expert and sysadmin turned developer, I think this attitude is what pissed me off most about current developers. I thought I'd have a huge upper hand, understanding dark magic. Come to find out most developers don't know and don't care about any of it, and have infected the whole community with the idea that none of it matters and servers and processes are just cattle. /rant
They don't care, until a kernel panic causes disk corruption in just the right way to cause a cross-security-boundary information leak that also ends up breaking an entire global pipeline, or a rare buffer overread in a ubiquitous piece of code causes once in a petabyte mismatches in cross-checked processes with compliance implications.
Source: xoogler, developed a reputation for black magic debugging, debugged both of those things. Correctness still matters, no matter how big you are or how much you think auto-restarts help.
Honestly I think this just rolls down from management.
"Oh you can spend $x * 80 hours debugging or $x * 2 hours putting a patch to constantly restart"
It's hard to quantify the impact of having a house of cards system with components constantly restarting to side steps bugs until the whole thing lights on fire in a cascading failure later (oh the service scheduler was down for 30 mins and things are restarting so much a massive amount of capacity went offline during that time)
There's a cost efficiency tradeoff that's always important to keep in mind. As an example, I was working with a very experienced kernel developer on a (at the time) bleeding edge mobile phone. We were seeing random memory corruption causing kernel panics. The engineer spent weeks trying to find the root cause but eventually gave up and put in a patch. You can't lose the forest for the trees - you still have product to ship & other priorities. It's rare for any bug to be so valuable to fix that it eats up all the other oxygen in the room.
Yes, they really don't care unless it results in a site going down. An industrial giant is happy to throw infinite machines at a problem until it is resolved. The issue isn't in their behavior, it's in Linux's implementation being so poor that they have to. But what are the alternatives? Should Google/Facebook/Amazon throw infinite developer time resolving kernel issues? Should they walk away from Linux?
I mean one of them at least went ahead and wrote (technically is in the process of writing) an entire operating system from scratch in response.
I say this as someone who uses and has used linux as a daily driver for years now but honestly I don’t feel good about the future of the platform in the medium term at all.
If anyone has some time to throw at understanding why this is probably the single most sober and rational set of arguments I’ve found of the topic yet https://m.youtube.com/watch?v=WtJ9T_IJOPE
Sorry if this is a bit blunt, but I'm mystified by the description of that video as "sober and rational". I'm not a Linux fanboy at all -- I happily use my Mac and don't even own a Linux computer besides my Raspberry Pi -- and in fact I was looking forward to digging into that talk, but it's just a guy rambling extraordinarily slowly about a bunch of half-points for an hour.
The parts that I managed to endure were these:
"Some Linux figures are being cancelled, like Richard Stallman." Silence the pianos and with muffled drum... oh wait, actually, systemd will probably keep running and crons will keep firing.
"Linux companies undergoing changes." Where's Heraclitus when you need him?
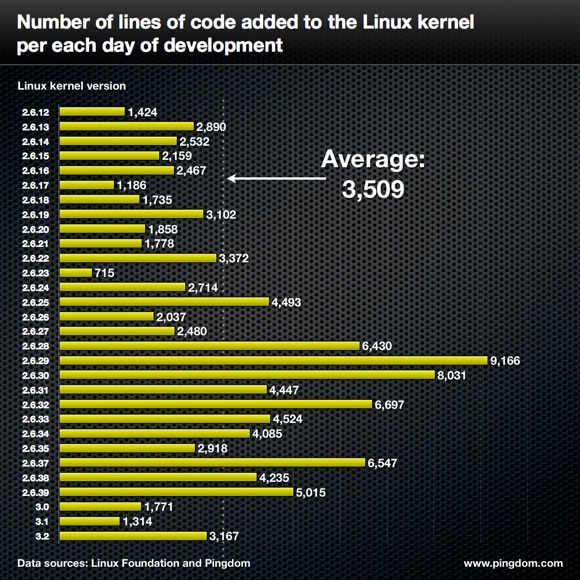
"Linux complexity increasing rapidly." He counts 2m lines of code added this year. But it's mostly drivers, and anyway this number has been trending downwards for a decade from what I can see (https://www.pingdom.com/wp-content/uploads/2012/04/linux-ker...).
"All Linux events are cancelled." Hmm, far be it from me to say, but I faintly recall that there was something besides Linux which might account for that.
"Google building Linux replacement." Google not building Linux replacement, Google building operating system.
"No operating system stays dominant forever." Linux is indeed not Ozymandias, sitting alone at the top of all creation, outside of space and time ... but I'm not sure how that means it sucks.
I wanted to like this, I honestly did, but the arguments are so dreadful that it feels like a deleted scene from one of Plato's dialogues. And Lord almighty he could have got to the point - such as it was - in much less than an hour.
I'm a huge Linux fanboy, who thinks Apple is evil and a puppet of the Chinese government and judge you for using Mac, and I totally agree. Lunduke is big on anti-SJW fearmongering, which I think projects a lot into his points. (He inductively applies that to society at large, which is the reason he gave for voting for Trump in 2020 lol.)
He used to have really good "Linux sucks" videos, which were actually tongue-in-cheek celebrations of Linux's progress combined with legitimate griping about the platform's issues.
The last two, though, have been identical pearl-clutching and doomsaying. You articulated my thoughts about them exactly. "These bad things are happening! We might actually not be using this 1970s OS 20 years from now. Better OSes might exist by then. But they'll probably be worse though! BUT people will use them anyway. It's all over. D: But is it actually all over? Maybe not. c: Who knows? I'm really scared though. But at least gaming is perfect on Linux now and all the old problems it ever had are gone. Pardon me while I fire up DOSBox."
It is easy and correct to critize that Lunduke's video. But the main point behind is that Linux project is becoming more corporatey, more windowsey and less user friendly and less small business friendly. New Linux drivers can't run perfectly fine 10 year old hardware (RAID cards, GPU cards) and users are forced to stay on old versions, or keep buying new hardware they don't need. That is not user or community friendly. But it is how Microsoft operates.
I'm a bit confused behind the substance of your argument. I use RHEL at work a lot which is admittedly pretty corporately, but use Debian at home just fine. But as for windows-y? How so? And regarding backwards compatibility, isn't that how Linux has always been? Windows has always been the king of backwards compatibility, whereas it wasn't one of Linux's strengths.
As Miguel de Icaza said in 2012:
> Backwards compatibility is not a sexy problem. It is not even remotely an interesting problem to solve. Nobody wants to do that work, everyone wants to innovate, and be responsible for the next big feature in Linux.
> So Linux was left with idealists that wanted to design the best possible system without having to worry about boring details like support and backwards compatibility.
> Meanwhile, you can still run the 2001 Photoshop that came when XP was launched on Windows 8. And you can still run your old OSX apps on Mountain Lion…”
Centos cancelled for the benefit of Redhat and detriment of many of its users.
Kernel changes that exclude users of 10year+ older hardware.
Corporate-backed campaign to discredit ethos leaders and defenders of user rights and veteran contributors - Redhat turning back on FSF and Richard Stallman, OSI banning Eric Raymond.
Ubuntu and Redhat losing interest in needs of desktop and small business users, putting most efforts into features for big cloud operations.
User group events degraded / cancelled.
Yeah Debian is still keeping mostly pro-user but they are not the leader in the cutting edge of development. Distributions innovating more do exist, but they are very small part of the Linux world. Most of it is Redhat, Ubuntu and hardware vendors.
Systemd, GNOME, GPU drivers are very windowsey; tightly coupled big software that one is discouraged to study and improve, almost as bad as their closed source counterparts on Windows.
I'm not sure what 'corporatey' or 'windowsey' means in the context of an operating system? Also, surely it's part of the nature of drivers that they are hardware-specific. Hardware changes a hell of a lot over 10 years. These complaints seem to describe issues with the way computers are architected and developed, more than anything in Linux itself.
The problem with old HW support is that the hardware is fine, the drivers are available and fine, but the kernel people decided to throw them out and replace by newer drivers which can run only newer HW products. Developers/vendors could be more user-friendly and keep support for the older hardware since the older compatible drivers exist, but they often don't.
What are these drivers you're talking about? Linux very rarely drops support for older hardware.
Things I remember off the top of my head in recent years: floppy boot support being removed, pre-ATAPI Matsushita CD-ROM support being removed, stuff like that. Turns out... you aren't going to be running modern Linux on systems that ancient anyway, because the minimum system requirements for just the kernel alone are already higher than machines of that era. So the number of people impacted by those cleanups should be ~0. Are you seeing drivers actively being used by people on modern kernel versions being removed?
You mentioned GPUs, but Nouveau supposedly supports Nvidia GPUs all the way back to the Riva TNT2 from 1998, and the Radeon driver should go all the way back to the original Radeon R100 from 2000. What are these unsupported GPUs you speak of?
Same with RAID cards; I see the driver for the Promise PDC20277 is still in mainline, and that's a PATA card from 2001 or thereabouts.
You can't endlessly upgrade software on ancient hardware; at some point the software outgrows it. Linux has historically been extremely good at keeping compatibility for old hardware, 20 years down the line. No other OS does that. But at some point things do have to go. I don't remember any time Linux broke something within a timeline similar to other OSes' support period.
1) dropping support of some Adaptec RAID cards in RHEL/Centos 8 with Linux 4.18. Like <= 5xxx series. Yeah, Adaptec 5x series is old and weak performance, but perfectly fine and widespread SATA controller card for servers. Many storage-oriented servers don't need anything faster.
2) Radeon RX4xx RX5xx GPUs worked on kernel 4.19, but they don't work for many people on newer kernels such as 5.10 and higher. Lots of error messages in dmesg, lots of reporting on forums, no official guide as to how to fix that. Amdgpu driver is in state of being endlessly rewritten presumably due to shiny new GPU cards and cutting edge Linux can't work with older cards reliably anymore.
Honestly, it's not that sensitive (at least without service details; plus this was over 7 years ago). I think the lawyers won't send me a nastygram for this much detail:
The kernel panic one started when I got pinged by a downstream team that we somehow delivered garbage data (valid-looking but entirely the wrong schema) to them, and that broke everything. Tracing things back up the chain, I found out that the source machine had had a kernel panic. Turns out that ended up with file metadata flushed to disk, but not file data. The unwritten sectors happened to contain data from a different process that was in the right file format, but had the wrong payloads, and since the file format was garbage-tolerant and self-synchronizing, the processing from that point on cleaned it up into data that looked completely valid... but was just from entirely the wrong place. All that happened automatically upon reboot from the panic. I was able to quite conclusively prove that this is what had happened by observing the data offsets logged to debug logs, and noting that the funkiness happened on filesystem block boundaries, and also aligned time-wise with the kernel panic, and a process that matched the schema of the data that ended up delivered had been running simultaneously on the same machine. This was all from just one instance of the fault, forensically debugged; we never reproduced it. The conclusion was basically "working as intended"... that is, this is apparently a thing that can happen given the filesystem mount mode in use (which was chosen for performance), so I think in the end they introduced some sanity checks on the data shape as a stop-gap. I think this was all soon deprecated and replaced with a system that didn't use local disk at all anyway, so there wasn't much point in introducing a big refactor to eliminate this rare failure mode at that point, but it's interesting that it did have security implications (it was just rare and not directly triggerable). It was very satisfying being able to trace down exactly what had happened (and the team lead sent this one off to me specifically due to my reputation for working this kind of stuff out... :) ).
The other one had to do with Google's NIHed gzip implementation, because of course they have one. We had found data mismatches between output computed over identical input in two different data centers (for redundancy/cross-checking), but it always went away if we tried again. This happened once a petabyte or so, give or take (I'll let you guess how often that was in terms of days, at Google scale). Digging through the error logs, I found that the mismatch was an offset mismatch, not a data mismatch. These files had gzip-compressed data blocks. Investigating the data was tricky because we weren't allowed to copy parts of it to workstations due to privacy reasons, but doing some contortions to work in the cloud I found out that the logical data was equivalent, but the compressed data was one or two bytes larger in one of the files, hence shifting the offset of the next block. Eventually I managed to grab one of the problem-causing uncompressed data blocks, build a test case for the gzip compressor with exactly the same flags used in production, and I had the idea of running it under valgrind... and that's when it screamed. Turns out the gzip compressor used a ring buffer of history to perform searches for compression, and for performance reasons the lookups weren't always wrapped, but rather there was a chunk of the ring buffer duplicated at the end. This was calculated to never exceed how much the pointer could fall off the end of the buffer. But, on top of that, the reads used unaligned 32-bit reads, again for performance reasons. And so you could end up with the pointer less than 4 bytes from the end of the buffer padding area, reading 1 to 3 bytes of random RAM after that. The way the compressor worked, if the data was bad it wouldn't break the compression, but it could compress a bit less. And so, the chances of both the read falling off the end of the buffer and happening to be one that would've improved compression were tiny, and that's how we ended up with the rarity. We never saw crashes due to the OOB read, but I think I heard some other team had been having actual segfaults (I guess the page after the buffer was unmapped for them) and this fix resolved them. I think we had the problem going on sporadically for a few months before I got sick of it (and I'd managed to rule out the obvious "it's a RAM bit flip / bad CPU / something" things you tend blame rare random failures on at that kind of scale) and spent a couple evenings figuring it out.
This was an absolute joy to read. Isn't it fun how many years later we remember stuff like this? The thrill of hunting down a complex issue, peeling away layer after layer to find the solution. Thanks for sharing.
Fuck. I envy the mental models you can probably evoke on command.
If you have a second to engage, I have found that I learn best in sandbox-types of environments, ie repls, notebooks, etc. What method do you find yourself going back to when you need to expand your understanding of a big production system like at Google? It might be my own ignorance, but I'm not sure how to move into big-systems engineering with low-stakes realism.
Most of the time this kind of debugging is either retroactive (look through logs and just try to piece things together from all available information), or you can manage to get a test case out of the system. In both cases, it's a matter of digging through the stack in some direction. So it's a lot of code searching to work out how different pieces fit together, and looking through the bread crumbs left in logs.
This isn't unique to big production systems in any way; while the numbers may have a few extra zeroes and the pieces of code may be more disparate and numerous, it's exactly the same process I go through today when debugging a kernel issue (these days I work on Linux support for reverse engineered Apple Silicon platforms). You start at the point where the problem happens, then add debugging statements and dig through the call stack, gaining an understanding of the system as you go, until you find the root cause. The good thing about Google, at least in the field I worked in (production SRE), is that usually there was enough logging already, in different forms and at different levels, that you could work things out without resorting to patching code to add more. But digging through the stack like this is certainly a skill, and it applies regardless of the scale of the system.
This skill is the crux of a fairly classic Google interview question: "You type www.google.com into your web browser and hit enter, what happens?" The goal there isn't to test your knowledge of any specific part of the puzzle, but rather to see if you have an understanding of how the puzzle fits together at some level, and hopefully enough of an interest in some part of it to go into significant detail. If you're a networking person, you might start talking about DNS requests, the TCP 3-way handshake, TLS handshakes, HTTP headers... If you're a web person, you might start describing how HTML is progressively loaded and resources are fetched in the background, how CSS lookups happen, how the DOM works... If you're a systems person, you might start talking about input events from the window manager, system calls to initiate network operations, caching to local filesystem... And if you're a smartass like me, you might start "At first, nothing happens; the microcontroller inside your keyboard is likely sleeping waiting for an interrupt that will have it advance to the next column in the scan matrix. Eventually, once the timer expires and the interrupt fires enough times to reach the column corresponding to the Enter key, it will bring that column to a logic high level, and the voltage will travel through the Enter key switch into the corresponding row line. The microcontroller will sample this line a short time later, and detect that a key has been pressed. It will then build a USB HID keyboard report packet containing the scan code, which will be placed in a buffer. The USB device hardware will then wait until it receives an INTERRUPT IN packet from the USB host, addressed to the HID interface endpoint responsible for delivering input reports..." (if I really wanted to frustrate the interviewer, I could start by describing a generic clock oscillator circuit and how the timer countdown logic might be implemented in terms of logic gates and transistors... but that might be going a bit too far, and we probably wouldn't get to the USB packet before the interview was over :-) )
All of those are valid answers, and the idea is that hopefully you can dive through some subset of the stack. So if you're interested in this kind of thing, that's a good place to start - pick something you're at least vaguely familiar with, and start digging through the stack to see how much of an understanding you can get of the different bits and pieces. Doing this with an open source OS is invaluable, since all the code is right there at your fingertips - there is nothing you can't figure out given enough time and patience. If you find interactive environments with a REPL more intuitive, you might use a debugger, set a breakpoint at the top level of the code, and single-step your way down the stack. If you're more of a reading code and printf() debugging person like me, you might do it that way instead. If you're interesting in digging downward towards the metal, perhaps try working with microcontrollers (e.g. Arduino, but make sure you dig through the libraries, don't stop at the interface - it's not that hard to learn how to program 8-bit microcontrollers in assembly!), and if you want to look at larger distributed systems, perhaps take a look at something like Ceph or some kind of Kubernetes deployment (both of which can be tested in a single machine with containers or VMs).
I feel like I just shook a tree and a bag of gold fell out. Thank you! Your answer makes me more confident that I can find a mooring. I'm starting to see what my next steps are. Praise be for your time.
That depends on how noticed it gets. My company makes embedded systems that in some failure cases can kill - we have a history of losing large lawsuits over the base 70 years (before computers of course). As such we have a powerful safety review system in place because million dollar lawsuits make CEOs care - it isn't perfect but there are a lot of things that we don't do that our customers would love.
"My app has a memory leak. Please can I have the engineering time to debug an operating system." wouldn't fly at any company. It's not that developers don't care; it's that developers don't have any choice.
I'm pretty sure I did this several times and I worked in a company of 15 people where our whole IT department was me and the other guy.
Depends on the domain.
For example we had our devices for impaired vision people stop responding to touch events on our cheap OEM touchscreens when German locale was enabled. Turns out linux driver used locale-specific code to read calibration configuration so each event position was scaled by orders of magnitude :)
The funny thing is that then they fixed that in the driver and if you had commas in the config file as a workaround - you get a kernel panic :)
That's a problem where you had no real choice to do anything else by the sounds of it though. You couldn't just "turn it off and on again" to fix it. In the case of a server where you can just have health check that reboots the server if memory gets a bit too low, it's far simpler just to automate a power cycle. It's not laziness or incompetence; it's understanding where to spend your effort best.
It's not that simple. Intermittently rebooting touchscreens make for a bad user experience.
User experience is one of those things that doesn't matter until it suddently does, often when a competitor sells a product that doesn't reboot in the middle of a user operation.
Exactly. We all choose the most cost effective solution - it's a balance between engineering effort and how effective the fix is. In the case of a touch screen, rebootingit every few hours isn't as effective as debugging the underlying cause. In the case of a web server having a memory leak, killing a pod and bringing up a new one automatically when it gets unhealthy definitely is. It's not surprising that each dev team settles on different solutions to each problem.
Yup, the matrix for transforming hardware coordinates into software coordinates was saved in a config file using locale-specific number format. When user changed locale it remained in the previous format and if the change was English->German the matrix elements suddenly changed from 1.234 to 1234 :)
The funny thing is we had the issue once - reported it and added a workaround (added special handling for these config files that used locale-specific calibration tables), then a year later we updated the linux version and had the issue the opposite way till we removed our workaround :) But it was even more fun cause it bricked the devices (kernel panic on libinput startup = restart loop forever) :)
I'm only 12 years in the industry and that is young compared to some others here but I'll give my perspective.
I would honestly say that all developers outside of companies who activity are going to run out of cash in 6 months have the time and are given the choice.
When management says, we don't have the time the reality is the proposed time given goes beyond a reasonable allocation of time, the max capacity given and or managers bullshit radar amount.
Great developers also are able to factor these tasks into their own ticket time to make the time for the issue.
I've been in countless meetings where individuals will complain about the state of X, how this is a hack, or we should really fix that.
Plenty of times I've seen, "You've got two days of dedicated time to identify, solve and implement."
This is met with various results, individuals taking the time, don't really do any work and consider it free time.
They spend two days just trying to understand even how all the components fit together. Even if you revisit in a month with another two days they'll spend the same two days relearning the same information because they did not retain or make notes to be able to pickup where they left off.
On a rare occasion someone will come in and fix it or move the needle further for the next person. All of these issues tend to funnel into these types of developers and from my sampling they're ~1 per 100 developers at a company.
I literally do this all the time. My job is to make the software I work on perform well, and sometimes that means debugging the operating system and figuring out why it’s not doing that. Assuming I bring results by doing this (and I do!) nobody is going to tell me to stop: they honestly could not care less with how I went about my job.
There's a huge difference between giving engineers 20% time to work on open source code, and choosing to fix a memory leak by debugging the OS rather than using a health monitor to automatically restart an app. For a start, there's no guarantee that the devs will succeed. It might be a huge waste of time. That's a massive risk.
"Debugging the OS" sounds not just a little bit pretentious. Perhaps call it "troubleshooting" instead, because that's what's being done. That the problem was found in a driver doesn't make it any different from faulty shell script or a faulty hard disk.
Leaving a leak in your code base is a risk too. What if it scales with something outside of your control and suddenly you have to restart every 15 seconds?
Very much depends on the domain. Not for a generic server-/web-app normally, but in other software fields not surprising. But of course "current developers" only work on webapps ;)
> But of course "current developers" only work on webapps ;)
The rule of thumb is that the vast, overwhelming majority of developers are working on business apps, especially Line Of Business (LOB) internal apps nobody ever sees.
It's hard to get exact numbers for this stuff but I wouldn't be surprised if the ratio of base infrastructure developers (kernel, shell, drivers, compilers, runtimes, frameworks, libraries etc.) to app developers is 1:100.
Not sure if a contrast between "base infrastructure" and "apps" in response to "only on webapps" is supposed to be a joke or not. Just because its not a webapp it doesn't mean it's "base infrastructure".
At some point we have to ask ourselves, who does care?
Especially if you're running open source. Yes there are sponsored open source developers, but do the people who don't care even submit a bug report more than half the time?
I did always submit bug reports and patches. Most of the time some GitHub robot closes my ticket or PR after it is ignored for a month. That’s the new status quo: keep your ticket queue short by auto closing it.
That's either that, or pay the most expensive support contract from your OS vendor. You can also ignore it, but you'll end up running into a wall at some point… hopefully after you left the company ?
You have only this much bandwidth between business logic, the last trendy framework/language thrust upon you, the billion overengineering "good practices" adding clutter to your code base and the zillion intricacies of the latest kubernetes platform that "makes your life easier". Most devs have way more than they can work with a single human mind on their plates. Accusing them of missing out on the low level kernel stuff that is about 5 or 6 levels of indirection deeper than the stuff they work day in and day out is like accusing pilots of insufficient knowledge of organic chemistry to understand the jet fuel composition.
I'm also a current developer. This isn't a slight against developers, but the prevailing mindset. And that mindset is little more than 'move fast and keep rebooting things'
Please, where do you work such that you are afforded adequate time to debug deep OS level issues? That it's acceptable to code to handle the 1-10^12 type error?
Of course I can't speak about your experiences, but I think the reason for this are mostly business goals. At least I have the impression that lots of developers care for technical excellence, but often that is not desirable from a business perspective.
That said, I really wish this wasn't the case. I miss the days when efficient software really mattered (just look at modern tv firmwares, or even mobile stuff).
I still remember coming in to 'take over' a new product one (crazy) guy had written. It had no safe guards at all - no queueing, kept everything in memory, no retries or really error handling other than printlines. I remember pointing out 'what if x happens', where x is a really realistic scenario, and the author(and VP) kept saying 'oh thats a caviar problem.' When I asked what that meant, they said "by the time we have to worry about that scenario, we'll be so rich we'll all be eating caviar." Apparently retrying network requests or getting say, 50 requests at a time would make us all millionaires or something.
Predictably, the thing fell over multiple times per day until we trashed it and started from scratch...and I still have no idea what caviar tastes like.
>"won't fix, we just reboot servers when they crash"
>understanding dark magic
That is the original Unix black magic: KISS and do the simplest possible thing that works and when in doubt use brute force and so forth. That is the "C" language of infrastructure.
In the particular in the scenario we're discussing, there's always a pool of several servers ready to handle a HTTP request (or DB query, or multimedia transformation, etc.). Rebooting a small % of this pool, rather than debugging every single memory leak is a pragmatic, cost-effective solution. "Zero bugs" is a very abstract and detached goal; "cost effectiveness" is a very realistic and wholesome goal.
I feel like the overall direction of the software world has been aiming to maximize developer productivity -- at the expense of rock solid reliability -- for quite some time now.
You can think of garbage collection as being an early admittance that it's far simpler to just clean things up in bulk on a periodic basis, than it is to keep track of every resource you're allocating, and making sure that it's freed at the earliest possible time.
Restarting a service after it's been running for hours, because of memory leaks, seems like a broader implementation of a similar notion... despite best efforts, sometimes services just accumulate cruft, and so long as you can properly drain clients to another server before restarting, is it really that bad to have to restart it periodically? I think of it as an extra long GC pause that frees everything up.
There's a sweet spot where "good enough" really is good enough, and I don't lament it all that much.
They have not infected, that's not fair. they just don't care and shouldn't be blamed just because you care too much. Good that you and others care and contribute to improve tools and libraries.
Devs don't generally have the time to take good care of these things while meeting the goals of the business, especially because they probably work at a company with 0 sysadmins.
Different mindsets. I was cutting my teeth on a set of 12 static servers/processes, with no autoscaling or auto reboots. Memory leaks were rare but reported. Usually FD leaks were culprits. So learned a ton about how to write really correct applications, and today it just feels like none of that matters. And in complete fairness, with today's ops tools, it probably doesn't.
At scale, server failures are going to happen. Maybe it's a power outage. Maybe it's a failed drive. Maybe it's a kernel crash. Only one of those can be remedied (not even prevented) with careful debugger investigation, so you're going to have to do the work to be able to handle such failures gracefully. At that point, unless the leaks are causing outages so rapidly that the machines can't handle, then rebooting becomes not that big of a deal, while wasting senior eng days trying to track them down is a real cost.
Not only Facebook, but the whole industry, if I may say. For example, I had a client who could not get rid of weird JVM GC pauses that would come from nowhere, after which it would render the application unusable for some time. The cheapest solution (as they could not scale it to more machines because it would just replicate the matter) was to add a custom code that would ping systemd watchdog every X seconds. If that stopped, systemd would restart the app.
I think there are two problems with "hard core" debugging: 1) these things are costly and will usually pull in the best devs (so no one will be working on that "important" UI-related ticket that should have been finished a week ago /s). 2) for the management team, spending 10-15 hours fixing one-line or/xor/bit-flip magic stuff doesn't make much sense, and I'd usually get responses like: "oh, it was THAT simple?". Yeah, right, none of you'd seen I've read that Intel manual twice and re-evaluated my math knowledge multiple times over the last two nights :D
IIS literally has functionality built-in to restart its subprocesses or whatever they're called, if the memory usage goes of X or if the subprocess crashes.
And yes, it is used in production in very big companies.
The main thing that was monitored was actually the restart rate/memory increase rate, i.e. a restart every 6 hours: ok, a restart every 30 minutes, not ok.
> "won't fix, we just reboot servers when they crash".
Where are you getting this?
The article is about a tool Facebook made specifically because they have teams doing deep-dive analysis of even rare bugs that occur in their systems. This suggests the opposite of Facebook being the type of company that looks the other way when crashes occur.
Every big org I’ve worked for had some form of this. To be honest, if the estimated cost of fixing the leak is an order of magnitude bigger than the cost of recycling the nodes every week for the next 5 years, then it’s the best thing to do from a business perspective, however sad that may be as engineers :)
This is a long time thing though. Tuxedo (a transaction processing system from the early 90s) would periodically restart processes to ensure that memory leaks didn't compromise the system. The Apache webserver has a knob for how many times you should run code in a process before restarting it. At the end of the day it is an extremely practical way to ensure that memory leaks don't bring your service down.
IIRC - it's an integer overflow problem. And power cycles generally come much sooner than than the 51 days.
From a software engineering perspective - seems like something that should be fixed. But apparently someone else decided not to. Maybe complexity? Cost?
The tl;dr version is that there are 10^80 atoms in the known universe, a computer with 1MB of memory can be in 2^1,000,000 or 10^300,000 possible states. Worse with a thousand times more memory. The easiest, quickest, perhaps the only, way to get it into a known state is to reboot it.
(Amusing introduction: "I took Friday off to be at home, because I can't get any work done at work, too many interruptions")
(I like Joe Armstrong's sense of humour here, dry, understated: "A prompt came up saying 'there's a new version of Open Office' and I thought 'That's good, it'll be better'.".)
I don't know any major service at FB that works this way. There could be risks from increased uptime, but I don't know any service that has OOMing as a regular, expected behaviour.
Memory is big enough an issue that they have a whole team working on jemalloc internally. It’s a big enough issue that, when a release of jemalloc messed up the memory usage profile on my team’s service, one of my team mates spent a couple of months figuring out why.
That sort of cavalier attitude to memory leaks doesn’t really fly when we’re talking potentially millions of dollars in server costs going down the drain.
That was my first assumption as well, but it seems like Alphabet is taking the traditional 'parent company' approach to branding, and not pushing a name change from Google to Alphabet.
It seems like Facebook is really trying to fully rebrand as Meta; even the Facebook 'about' page displays Meta instead of Facebook: https://about.facebook.com
Nowadays a lot of the network gear runs Linux too. Cisco's IOS XE and NX-OS run on a Linux kernel as does Juniper's Junos Evolved. All of Arista's gear has been Linux based since day one.
That's very interesting and has the potential of impact as dtrace did but for the regular non-sysadmin person. Good that they were able to open it. The author posted their github in an answer down here: https://github.com/osandov/drgn
* Stack tracing needs architecture-specific support which is currently only implemented for x86-64 and ppc64. It's not too hard to add for other architectures, so if this is a feature you need, please open a GitHub issue and I'll get around to it soon.
* 32-bit ARM doesn't support /proc/kcore, so drgn can't do live kernel debugging on 32-bit ARM. This seems to be due to historical reasons rather than any technical limitations, so I may send a patch to enable /proc/kcore for future kernel releases. AArch64 doesn't have this issue.
Userspace application debugging with drgn also has a couple of limitations mentioned in the blog post, namely the lack of breakpoints and stack tracing for live processes. Again, feel free to open issues asking for these so I know to move them up my todo list.
Maybe so, but that's another unsubstantive comment and we ban accounts that do that repeatedly and ignore our moderation requests. You've been doing it repeatedly, and doing it precisely in response to a moderation request doesn't give the impression that you want to use HN as intended. I don't want to ban you, so would you please just stop doing this?
{kind=link}