Great article. But I'm wondering, how many of you have used Lenses in larger, or legacy projects?
It is this sentence that gives me some doubts:
> The formulation is wonky, and very difficult to grasp. Don't worry if the intuition hasn't kicked in. It turns out that you can use lenses quite a bit without fully grokking them.
Whenever I read something like this about a framework, I imagine that sooner or later some colleague will fall in love with the power of the framework too much and write code that is very hard to understand/maintain.
But I have to admit that I haven't worked much with Lenses myself yet so maybe things are not so bad?
As soon as I heard about this formulation back in 2012 or so I concluded that this particular structure was going to be foundational in Haskell and potentially the broader (purely) functional programming world. I agree with your intuition here with respect to that statement, but this case is an exception to that heuristic. I would say that these lenses are the purely functional equivalent to pointers in C. These lenses are type-safe functional pointers that are composable! This lens formulation is much more powerful than the naive lens formulations that came before it and it admits a number of just as powerful related abstractions such as prisms, traversals, etc.
Historically I have been pretty skeptical about adopting flavor-of-the-week flashy abstractions in the Haskell ecosystem for use in production code, usually preferring to lean on ADTs and pure functions for their simplicity and power. But lenses are essential. They are the fundamental building blocks for accessing and modifying ADTs. You don't have to understand the complicated type wizardry to use them. They're particularly useful for drilling deep into arbitrary JSON structures. See a reddit comment of mine for some examples: https://old.reddit.com/r/haskell/comments/792nl4/clojure_vs_...
I have. Like many other concepts in Haskell, it takes a bit of time for intuition to kick in. For example you likely wouldn't understand Traversable or Applicative when you first heard of it but it will become second nature in a few days.
The only rule I would have is to ban all the operators and force everyone to use actual words for names. For example (^.) is not allowed but `view` is.
> The only rule I would have is to ban all the operators and force everyone to use actual words for names. For example (^.) is not allowed but `view` is.
I sometimes find myself thinking the same, but then I remember "Notation as a tool of thought"[0] and become less sure.
Also I remember some lens compositions being more awkwatd with words, though I can't recall an example.
> The only rule I would have is to ban all the operators and force everyone to use actual words for names. For example (^.) is not allowed but `view` is.
Yeah, this is what I view as a enormous weakness of Haskell compared to Lisp/Scheme, where in the latter descriptive naming is a community norm.
It makes for much more readable code... especially if I've been away from the language for a while.
Pascal has a much smaller number of much simpler operators than Haskell + fancy libraries, which puts a low ceiling on the incomprehensibility of Pascal expressions.
Point of clarification for readers who aren’t familiar with Haskell:
Haskell doesn’t have operators in the classic sense, since they’re just an alternate syntax (infix) for regular functions; implemented in libraries. The Haskell ecosystem OTOH has a shitton of infix functions, as does Edward Kmett’s lens library. I don’t think there’s any reason to bother memorizing the ones that aren’t useful to you. You can always search them on Hoogle if you encounter one you don’t know. E.g. https://hoogle.haskell.org/?hoogle=%28%5E.%29&scope=set%3Ast...
I use lenses frequently in a large application and have only ever used view, set, and over.
> Haskell doesn’t have operators in the classic sense, since they’re just an alternate syntax (infix) for regular functions
Actually in Haskell there is a concept of 'functions' and 'operators'. The former are made up symbols, while the latter are made up mostly alphanumeric characters. Also they parse differently.
I have, but not in Haskell. Over in Flow land, well before we had the nicer `?.` nested property access, I worked on a React Native project that used them extensively. It was nice! We didn't do anything too fancy with them, they just allowed for safe (runtime) and safe (type-safe) access of some deeply nested state objects. Worked pretty well, and that project is still being developed today with no complaints (about that side of it anyway)
One of the nice things was being able to re-use and compose those lenses. Led to some really nice abstractions that were honestly pretty simple in practice, but to me that's the sign of a well-chosen tool.
Lenses in Haskell are truly easy. The hardest part around them is the tooling. They'd be much better if GHC could generate them for you. When I go back to imperative languages, like Rust, C++, or Javascript, I find myself missing the easy traversals and folds one can do with lenses. It's like being able to have a Graph QL database for all your data structures instantaneously. When it works, it is truly glorious.
The intuition is easy. The fundamental thing is a getter and a setter. Getters can get multiple things, but always produce one answer. So, in order to take multiple things and combine them, you have to fold them. Thus, a getter of multiple things is a fold. A setter can also set / modify multiple things. To take multiple things and produce multiple things is a traversal. Due to the way Haskell works, all traversals are also folds (the math checks out).
Everything else is just a specialization of folds and traversals. And honestly, you can view folds as a particular type of traversal (the identity traversal with an effect). Thus, really traversals are fundamental.
For example, prisms are just traversals that can target zero or one (but not >1 element). A 'getter' (lens's terminology) is a fold with only one element. A lens is a getter and a traversal. Thus it can only set one element.
A nice thing about optics is that they are strongly typed enough that it's pretty hard to make them do the "wrong" thing. The type errors can be confusing (because the underlying types are rich), but I've rarely/never actually been able to make incorrect optics-based code compile.
As far as legacy projects - optics are awesome for refactoring complex nested state operations like you would see in many business-centric applications.
A lot of apps are basically just complex nested operations on a big, heterogenous, in-memory data structure, and optics are the best known DSL for reading/writing/processing such structures.
> As far as legacy projects - optics are awesome for refactoring complex nested state operations like you would see in many business-centric applications.
Motivating lenses will consist of concisely demonstrating this in a RecordDotSyntax world I think.
Optics by example does a really good job, but I think we need like a hotel reservation app architected with lenses or something.
I’ve used lenses, and yes, at least in my case, I couldn’t resist writing clever code. It was a lot of fun to write, but a giant nuisance to read later.
I don’t think this is the fault of lenses, though. I think they can add clarity. The problem was that I got curried away. Heyo! I’ve seen the same thing happen with Scala, Clojure, Ramda, Haskell, Rx. Newcomers want to flex their new-found muscles and push the abstractions as far as they can. The result is a world of pain come maintenance time.
Some things are invented and others are discovered. Frameworks are invented, while the concept of lenses is something you could discover on your own.
I can't help but believe that the things that are discovered are somehow more important than the ones which are invented. Discovered things are timeless while invented things are fleeting.
I've used Lenses as a beginner/intermediate haskeller and they're very easy to use. It's easy to get bogged down in the theory and specifics but Lenses are perfectly usable on the practical level without ever diving in too deep. That said, now that RecordDotSyntax is a thing, there's less of a use case for surface level lenses.
I think in a lot of cases like this, what's wonky is the actual mathematical details that are necessary for proof of soundness and/or correctness. Understanding it generally is not needed in order to use the thing.
It's not unlike abusing obscure details of a web framework to write overly-clever code. Overuse of mathematical abstractions is bad code anyway. Deep understanding is helpful, but not important for general productivity.
Haskell has a tendency to require mathematics that is by itself wonky. Usually because they use category theory but neglect to mention that they're actually working in a closed monoidal category (or perhaps cartesian closed, it's not 100% clear), and use currying implicitly everywhere.
This is why you even have an "Applicative" class of functors for instance, they're the ones that work nicely with the closed monoidal category structure. Somehow this detail gets skipped a lot in explanation of it (and you won't find it mentioned in mathematical texts).
> This is why you even have an "Applicative" class of functors for instance, they're the ones that work nicely with the closed monoidal category structure.
Applicatives still make sense with only monoidal structure: they're monoidal functors `C -> Set`, or more generally `C -> V` for `C` enriched over `V`.
I'd be interested to see a justification for that, given that the usual definition is essentially "A functor which preserves the internal hom functor".
Regardless I hope you can see what I mean when I say the mathematics you need for Haskell is wonky.
> I'd be interested to see a justification for that, given that the usual definition is essentially "A functor which preserves the internal hom functor".
Applicatives are monoid objects for Day convolution of functors (in the same way that monads are monoid objects for composition of functors) given by the coend `F \otimes G (x) = \int^{i, j} Hom_C(i \otimes j, x) \otimes_V F(i) \otimes_V F(j)`. These coincide with closed functors by currying if we have closed monoidal structure, but remain well-defined without it.
Using `<*>` instead of `liftA2` in the typeclass definition is basically a historical accident, and imo a mistake.
> Regardless I hope you can see what I mean when I say the mathematics you need for Haskell is wonky.
Wonky is too strong, but I agree that it's usually not treated with anything near the appropriate level of detail.
I used lenses with Ramda JS and Redux to great success. Codebase was very easy to reason about, simple to extend, and never surprised me. Highly recommend this pattern to anyone who likes function composition / piping!
Lenses let you do some amazing things, but I think most of their existence is just thanks to how truly horrible (nested) record field access and updates were.
This is a lot better now with record dot syntax. [1]
A similar statement could be made about monads. Originally used to implement IO in Haskell because it’s a lazy pure functional language, they’re largely unnecessary in strictly evaluated languages.
Monads are now of course seen by Haskellers as being very useful in many different use cases beyond the original motivation.
IO in PureScript, which I’d describe as strictly evaluated Haskell, is still implemented using monads. The biggest benefit of this (as one might expect) is forcing the separation of pure and impure code, but a cool byproduct is asynchronous IO is also implemented in a monad. Various functions are available to launch async from synchronous IO and lift synchronous functions into async. The ergonomics of mixing sync and async are better than any other language I’ve used.
So theres an interesting question: once you have dot syntax, are there reasons you’d still want lenses? I’ve come up with two.
First, it is nice to use “over” (%~) to avoid specifying a location in a data structure twice (first to read it and apply a function to the read value, second to create a new data structure with the read value replaced with the output of the function. The deeper the data structure, the bigger the benefit.
The second case is writing functions that take lenses as an input and operate generically with larger data structures without knowing where in the larger data structure the values of interest reside ahead of time.
I started using monads in Python as sort of a gimmick / something to add flavor to a boring project (I was guessing in a final form we'd keep Result types and throw away most other things) but by now they're a boon to productivity and easy to read in fluent notation. Plus they're easy to implement from scratch if you're dependency-phobic (on the rather rickety selection of monad libraries out there, too).
I use basically variations of copy-pasted code from tutorials and (I think) pymonad. I keep reimplementing things because the last API had warts. Maybe one day I'll have a library.
> Lenses let you do some amazing things, but I think most of their existence is just thanks to how truly horrible (nested) record field access and updates were.
Only for the most basic uses. Architecting programs as folds or traversals can be powerful.
One simple example of lenses i can think of being useful for more than record access is:
Not to be a lens hater, but I would definitely flag it in PR review if someone came up with that instead of something like this:
> sum $ map (fromMaybe 0) <some list of Maybe Int>
Possibly with a different default value for Nothings. A lot of the optics libraries seem to focus a lot on making the general case as easy as possible while overcomplicating the specific case. `sumOf (folded . folded)` does have some advantages in working for lists of other types but I question how often you would reuse such a function for different types the first place. It just doesn't come up all too often in my own code, perhaps it is different elsewhere.
> `sumOf (folded . folded)` does have some advantages in working for lists of other types but I question how often you would reuse such a function for different types the first place.
The common refactor here would be to Either:
> sumOf (folded . folded) [Right 1, Right 2]
3
I don't like the "unwrap the Maybe" or "get rid of the pesky monad in my way" intuition that fromMaybe and catMaybes give beginners.
> A lot of the optics libraries seem to focus a lot on making the general case as easy as possible while overcomplicating the specific case.
I kind of agree with this, but contend the universality of a single powerful and composable lens syntax simplifies things more overall even if it makes a single use site more complicated.
> `sumOf (folded . folded)` does have some advantages in working for lists of other types but I question how often you would reuse such a function for different types the first place.
Just remembered another refactor that comes up a lot for me:
Refactoring `[a]` to `NonEmpty a`. A lot of times this tightens your code up, but i find if the call chain is monomorphic to list most won't bother with the refactor.
So I like lens for pushing away from that level of monomorphism that is resistant to better architecture.
"Architecting programs as folds or traversals can be powerful."
This is my own idiosyncratic view but lately I've been fiddling with the proposition that the defining characteristic of functional programming languages is the definition and pervasive utilization of recursion schemes via composition as the primary organizational method for code. That is to say, such programs do not just borrow a few recursion schemes here or there (like chaining a map with a filter and calling it a "functional program"), but that the entire architecture is oriented around operating on data via such recursion schemes, stacked on top of each other.
So many of the previous touchstones keep getting moved into non-functional languages, like "functions as first-class citizens" (almost everything has this now) and "immutability" (less common, but common enough we can say with confidence now that having immutable values does not turn a language "functional"), but the destination languages remain quite distinct from something like Haskell.
From that point of view, lens is a development you'd expect any such language to eventually come up with and make extensive use of. It isn't the only way to compose recursion schemes together, but it's certainly one of the basic tools.
(An interesting element of this particular heterodox view is that this enables one to imagine a "pure functional language" that is not based on total immutability, though whether that's a good idea is another question.)
It can be powerful, but it also makes code a lot more complicated and confusing.
The focus on fancy type level abstractions is why Haskell is so interesting, but it is also one of the reasons I don't use Haskell in a business environment.
Everything is just so complicated, and every library does things somewhat differently.
Lenses are not fancy or complicated. They require no language extensions to create or use at all. Heck, it require no libraries beyond base to create lenses for others to use. There's a bit to learn, but there's nothing fancy. It's just a matter of applying a simple pattern repeatedly. (Or doing some software engineering and letting a library do the repetition for you.)
I wouldn't call that trivial but "common", and for these cases we could even use something like catMaybes:
> sum . catMaybes
Lenses (imho) shine when you have to write data-extractors for arbitrary-complex and ill-documented APIs with corner cases or things like HTML scrapping. The beauty of lenses is that you get one composable language across libraries. For instance, if your HTTP-library has lenses and your XML-library has lenses, you can write things like safely composing a getElementsByTagName with some XML-parsing and data extractions:
> response ^.. responseBody . xml . folding universe . named (only "p") . text
and the bonus is that if you need to filter, you can do that with a similar mechanism (e.g., filtering based on some html meta-tag)
overall it feels like SQL-for-arbitrary-structures: dense but powerful
I prefer a general polymorphic solution to optimize for global simplicityand consistency rather than lots of different ad-hoc simpler solutions that are more complex and/or less composable altogether.
Perhaps they were born of necessity but now they are a strictly better solution for computing on members than any other solution or language feature.
Record dot syntax is very unappealing. Would way prefer automatic lenses, or just some principled way to qualify using the constructor or equivalent. And take your hands off my compose operator tyvm!
This is such a good presentation. The story it tells of the derivation of the type is ahistorical, but it makes a lot of sense. If you are looking for an intuition of how the types work, it's just fantastic.
What's really neat about lenses to me (more of a practitioner than a theoretician) is that while the level 0 explanation of them is "they're like getters and setters in your OOP language" they extend the concept much further.
Lenses can be "indirect" or "pseudo" getters or setters, for want of a better term. I.e. they can filter among many fields to set, then modify multiple fields at once, change only non-null values, replace only null values, and so on. So in a sense they're like multiple cursors at the code execution level. But they can also contain more complicated transformations if that makes your code simpler (sort of like C# properties.)
They are also first class concepts meaning you can pass these accessors around without caring about which object you will use them on.
And they compose with each other very nicely.
Those three properties make them super powerful and I really with I had them in more languages.
----
Lenses are the sort of thing where if they had been the default in more languages, people would wonder why on earth anyone would want to have the obviously inferior getters and setters of today's OOP languages.
Notably, this feature would be very useful in SQL or similar data processing languages.
I wish these query languages had the ability to select "all key columns", "all writeable columns", "non-system-generated columns", etc...
In most database or query platforms this is either impossible, or requires breaking out into another system/approach entirely. For example, it's possible to generate a SQL query to do above by querying the column metadata from INFORMATION_SCHEMA views, but this is obviously not what most people want to be doing when writing a query.
Worse, even if the database platform has features like this, when it gets processed through an ORM in typical languages like Java or C#, any such features are once again lost...
Lenses and optics could apply well to SQL-like query languages, because those are largely functional as well, and thanks to "JSON columns" often have nested structures where the composability of these abstractions would be more elegant than some hideous "tree query syntax" as typically seen in XPath and the like.
And you can weave effects into them just like normal functions, without losing the ability of composition. Fun stuff!
In defense of OO-style access pattern, they’re a lot simpler and syntactically well integrated into most languages. The flexibility of lenses is clearly visible in types (in most current implementations). Ideally you want to hide this when you don’t need the flexibility.
> What's really neat about lenses to me (more of a practitioner than a theoretician) is that while the level 0 explanation of them is "they're like getters and setters in your OOP language" they extend the concept much further.
This doesn’t tell me anything since getters/setters are almost useless in my experience.
Right ... And lenses are not. Imho a better comparison would be to (safe) pointers that can point to multiple, conditional positions in a data structure.
Example: in a game you want to update the health points of all enemies that are affected by an area of effect attack. With lenses you would compose a lens from multiple simpler lenses:
```enemiesAtDistanceToPoint (10,20) 5 . health -= 5```
The benefit here is that you abstract the work of extracting the enemies and can reuse it elsewhere. Also note the lack of any loop to affect multiple entities.
Somewhat, but even my pointer analogy just scratches the surface.
Filtering/selecting is big, but another interesting thing is that there are lenses (which I think are called prisms?) that only provide a view of something.
Eg you have a text document in Unicode, select all words marching a certain pattern, and then look as if they were encoded in ASCII. (No idea why this would useful :-) ).
A "lens" that only provides a view of something is just a plain function. Prisms are first class constructors: a `Prism a b` can build a `b` from an `a`, or attempt to match on a `b` and `Maybe` get an `a` that could construct it.
The OP means accessing instance variables really. That is, the `.x` in `this.x` or `that.x`. They're not making a distinction between manually created getters and setters and what the compiler generates.
Yet ekmetts package is called "lens" and not "optic".
While I agree with you in principle, I think that ship has sailed and for all practical purposes, "lenses" has come to mean both the narrower definition that is arguably correct, and optics more generally. It's a historical accident, much like a lot of people use "function" to mean all sorts of subprogram, including procedures and sometimes even methods!
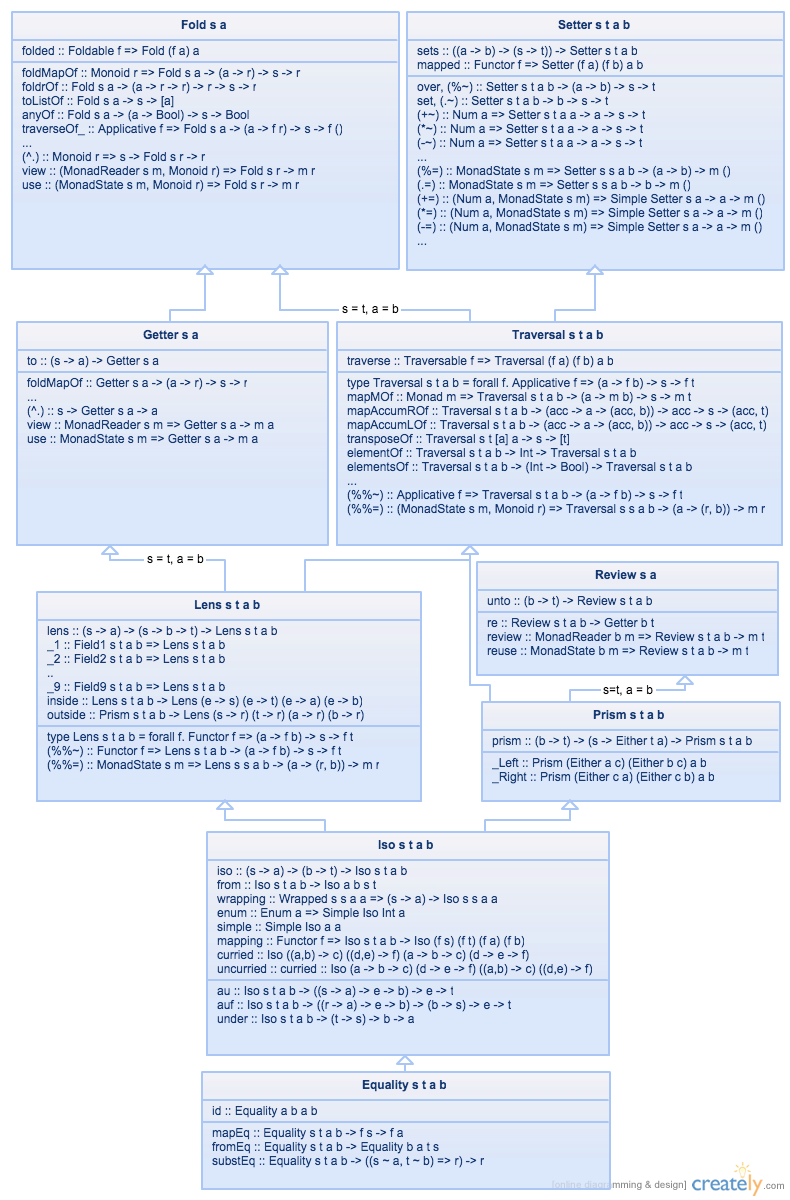
I would love to see some kind of table or diagram that shows all the various "optics" in some kind of structured format. Lenses are the only one that I can keep straight in my head.
Page 10 of this paper has a table with references to some more exotic optics, though it's going to be hard to parse without some category theory: https://arxiv.org/pdf/2001.07488.pdf
Getters and setters are not a "concept" in OOP. They're just a naming convention that is occasionally built into language syntax for brevity.
FP people constantly miss something fundamental about OOP. Objects only exist at runtime. Any facility that provides powerful tools to deal with objects has to be runtime-oriented and would require corresponding language support. E.g. Mirrors: https://bracha.org/mirrors.pdf
> The first issue in Haskell is that we can't mutate alice; we instead have to return a new Person value with the updated city.
I don't get it. Ok, so it can't mutate, but why can't haskell have an easy syntax and just return a copy with the updated value? Why does it need this very convoluted way for updating records?
eg you could have {{ }} denote an "update block", and this has some special syntax to change values, add or remove items from lists/dicts and similar
Lenses are still more powerful as they can be composed. Consider your (and the record dot) syntax for having to modify alice.cart.items on one branch of the conditional and alice.cart.discount on another branch of the conditional.
This is basically what Immer [0] does for Javascript apps if you use immutable-like libraries like Redux which expect a new object created every time a property changes so that it can detect that it's changed and propagate that to any observing components.
Yes it could. But lenses offer much more than that. They are sometimes called "functional references", because a lens can be used for both reading and updating; and can be passed around. They can also be composed and combined in arbitrarily complex ways, e.g a lens into a map, option or a list.
The type looks a little insane, but it's just a combination of three mundane hacks that also exist in other languages.
The first: If you need a serializer/deserializer in a simple language like old-school Java, you can either write two methods for each class, or you can combine them into one method like this:
class HoveringSkull inmplements Streamable {
String desc;
float height;
void stream(Stream c) {
desc = c.stream(desc);
height = c.stream(height);
}
... and have two different implementations of Streamable. That's what the choice of (pro-)functor instance does -- you can swap out the implementation to get 'read' and 'write' (and 'deepClone' and 'equals' and 'hashCode' and 'defaultGui' and 'treeMatch' and ...)
Good God! This kind of stuff is built for a very different kind of brain than mine, that's for sure.
I always come away feeling that Haskell makes the simple things tough, and the tough things beyond my reach. For me, it seems so much simpler to deal with in-place single-writer mutation, where aliasing is controlled by the type system, ala Rust or D, or, something like Elm's record updating syntax. Even Erlang will do in a pinch.
I hold Haskellers' abilities in high regard, but at the end of the day, I'm not sure if they produce better software than other equally capable/rigorous/knowledgeable developers. (Don't mean to dredge up the static/dynamic typing debate, but given the literature I have read, there is no clear winner).
Take heart! Plenty of very smart and capable people bounce off this sort of thing. I think it's a matter of temperament; some folks are wired for strict typing and struggle to see the value of dynamic typing, other folks vice versa. It's always valuable to walk a mile in the other shoes, but here we are.
For the record, it's not immutability that cause "the record problem" and bring these complex ideas, it's immutability + strict typing. Clojure's weak typing and tree-based immutability makes the record problem just as clean as the OO version:
(assoc-in person [:personAddress :addressCity] city)
returns a new record with the new city, and any other function with a reference to 'person' would not see it changed.
I will say that of the very few pieces of software I actually actively like (as opposed to begrudgingly tolerate), most are either written in Haskell or C. C software includes openSSH, wireguard. Haskell software includes pandoc, xmonad. So whether it's a property of the language itself or a second-order social filter effect (I suspect the former), it does seem to result in relatively good software. I think it's more poignant with libraries; the quality of libraries in the haskell ecosystem is incredibly good (although many people seem to dislike how the haskell ecosystem deals with e.g. documentation: by not writing as much).
> I always come away feeling that Haskell makes the simple things tough, and the tough things beyond my reach
I would say it makes (very) simple things a lot harder, but very hard things much easier. I like to think of it in terms of asymptotics. If you consider a mapping `f` from problem complexity to program complexity, python is something like `f(x) = 0.001x^10`. Very simple problems have very simple solutions, but complex problems have very (intractably) difficult-to-manage solutions. Haskell is something like `f(x) = 1 x^3`. Very simple problems become harder, but once you have a sufficiently complicated problem, the polynomial factors dominate and haskell becomes much simpler. The higher constant-factor cost allows you to handle vastly higher asymptotic problem complexity.
However precision comes at a cost, usually in verbosity and understandability. Coq, for example, requires even more precision. It's great for math, but terrible for writing a database.
For the systems I wanted to build, even Haskell feels needlessly precise in the areas I tend to get right in short order, but there's no (or not enough) support in the cases where I could use some help, such as the behavior of an O/S or database or network. I prefer F# and Erlang in their balance between precision, safety and system building ability.
> This kind of stuff is built for a very different kind of brain than mine, that's for sure.
No it isn't, and this attitude doesn't do you any good. This stuff only seems difficult because it's unfamiliar, but I can assure you it's simpler than whatever "real life" technology you are proficient in.
FP concepts are very simple (so very easy to understand!), the real power comes from their true compositionality, which is also why you don't need a "special brain" to understand what is happening -- concepts compose!
At a 50000 foot level, I will accept your statement. Concepts composition is a delightful property.
But at a lower level, it is a slog. I have tried somewhat hard (e.g understanding different monads, writing a tutorial --- doesn't everybody?) to plough through the language and the libraries, but after some point I got tired having to learn one more new concept, one more language extension, all for doing fairly routine things. Now, I'm reasonably confident that I _could_ master it if my life depended on it, but it feels so .... tedious.
> it's simpler than whatever "real life" technology you are proficient in.
That has certainly not been my experience, alas. I'm constantly unsure of whether a piece of code is idiomatic enough, abstract enough or whether it is a simple composition of some other concepts. I suppose there is a particular hump beyond which these things click into place, but I haven't come close to it. Secondly, producing any real life technology requires me to fit that tech and Haskell bindings (should they exist) together in one brain.
That said, Haskell's been a wonderful fit for writing a compiler for a pet toy language. And monads changed the way I write code in mainstream languages.
>And monads changed the way I write code in mainstream languages.
This is my main takeaway from Haskell and other FP languages and it is what I always tell others. FP is the "paint the fence" of code. Learn FP and you will become much more proficient in every other language that you end up using.
> I'm confused. How is Elm's record updating syntax related to aliasing?
It isn't. The key word was "Or".
In general, the point I had in mind is that mutability is a problem only in the presence of aliasing. Elm and Rust chose two different points in the mutability+aliasing space. Elm doesn't have mutation, Rust restricts mutation when there is aliasing.
> FWIW, Elm also doesn't have a nice way to update nested record fields, and there are lens libraries in Elm to deal with the same problem.
Does anyone know what's the situation with lenses and type errors these days? Many moons ago, when I played around with lenses, I remember that the type error messages were could get very scary. Paragraphs of inscrutable type errors for a single typo, something that could make even C++ template errors look nice.
There are a couple type errors that are weird, like complaining about missing Monoid instances when you try to use a Fold as if it was a Getter. A few other things can have error messages that only make sense if you ignore the weird type aliases and focus instead on their expansions.
There is now an alternative library, optics, which does a lot to improve error messages at the expense of removing extensibility. Since the ecosystem (in terms of types and operations) is closed, it can be very precise in the error messages it produces. It's a good compromise if you're more worried about error messages than some of the less common lens operations.
(I tend to stick with lens, as I am comfortable with its error messages and often find myself using things optics doesn't support. But the option is there for those who have different needs.)
For anyone looking to play around with lenses outside of Haskell, Ramda JS has a great implementation along with many other FP utilities. Been a happy user for a few years now with several production use cases, all still going strong
hytradboi 2022 hosted a 10m talk [1] about Project Cambria [2] which imagines bi-directional lenses as the basis for deep compatibility between software systems across time and domain.
I'm kind of befuddled as to why the original "Modifier functions" solution is not better than the "And now we can finally unify our getter and modify lenses into one:" solution.
{kind=link}
{kind=link}
> The formulation is wonky, and very difficult to grasp. Don't worry if the intuition hasn't kicked in. It turns out that you can use lenses quite a bit without fully grokking them.
Whenever I read something like this about a framework, I imagine that sooner or later some colleague will fall in love with the power of the framework too much and write code that is very hard to understand/maintain. But I have to admit that I haven't worked much with Lenses myself yet so maybe things are not so bad?