These definitions don't really give you the idea, rather often just code examples..
"The ideas", in my view:
Monoid = units that can be joined together
Functor = context for running a single-input function
Applicative = context for multi-input functions
Monad = context for sequence-dependent operations
Lifting = converting from one context to another
Sum type = something is either A or B or C..
Product type = a record = something is both A and B and C
Partial application = defaulting an argument to a function
Currying = passing some arguments later = rephrasing a function to return a functions of n-1 arguments when given 1, st. the final function will compute the desired result
EDIT:
Context = compiler information that changes how the program will be interpreted (, executed, compiled,...)
Eg., context = run in the future, run across a list, redirect the i/o, ...
I completely understand what you’re saying, but assuming that this guide is aimed at people entirely unfamiliar with these concepts, I’m not sure whether these “ideas” provide any meaningful explanation to them.
Demonstrating by example what e.g. currying actually looks like is much more powerful, at least from my point of view. In that regard, I’m actually pleasantly surprised this guide does a very good job at that.
Currying is one of those cases where the code is the explanation
I think in many cases this isnt right, eg., Monads. The reason flatMap() "flattens" is just that "flattening" is really just sequencing, denesting the type using a function requires a sequenced function call: f(g(..))
This applies to many of these "functional design patterns"... theyre just ways of expressing often trivial ideas (such as sequencing) under some constraints.
While I _think_ I understand monads on some rudimentary level through how join and bind operate, your "just sequencing" doesn't tell me anything. And this is a problem with a lot of these texts. Maybe that's trivial to the writers, but it makes me feel even dumber when I cannot understand a concept I already understand, lol.
This is one of those things where looking at the type signature hard enough eventually gives the game away, but most writing on it sucks:
bind :: m a -> (a -> m b) -> m b
Because that function in the middle takes an `a`, your implementation of `bind` needs to be able to take an `m a` and pull an `a` out of it, which means it also has to evaluate however much of `m` is needed to actually get to that `a`.
Because that function in the middle returns an `m b`, binding again with a function `b -> m c` requires you to pull `b` out of `m b`, which in turn forces pulling an `a` out of `m a` to make progress. This is where you force sequentiality — you can only evaluate the `m` in `m b` after you've evaluated the `m` in `m a`
Caveat: there is the trivial case of calling the middle function zero times. Which does happen (in the case of a Maybe type) but presumably any useful code needs to be able to call the function sometimes.
Thanks, that's reassuring. I've long been frustrated by just how bad monad posts are in general, and been meaning to write something up about it that makes it clearer. It's good to know that I'm at least going in the right direction :)
A big problem with "just sequencing" is that there are a lot of ways of sequencing that either don't require the complexity of a monad or for which the monad interface is insufficient.
The former is probably uncontroversial but I'd love to see some examples of the latter since my understanding was that monads are essentially the generalization of sequentiality.
One obvious place to look is things that are almost a monad but can't be lawful and which might nonetheless be useful. An example that comes to mind is trying to use Set as a monad (for nondeterminism like the list monad, but with deduplication), which you can't do for some potentially avoidable technical reasons (it would have to be restricted to things you can Ord) but more importantly Set can't be a monad because Set can't be a functor, because `x == y` does not actually imply that `f x == f y` (even for reasonable definitions of Eq), so `fmap (f . g)` might not be equivalent to `fmap f . fmap g`.
I thought it was the case that you can't implement the Monad type class using the built in Data.Set implementation of Sets but there's no reason in principle why you couldn't build a Set Monad that works that way, right? Perhaps I am mistaken so I will investigate further.
There is a reason in principle that you can't build a Set Monad that works that way: it violates the functor laws.
In order to be a functor, you need `fmap (f . g) == fmap f . fmap g`.
The problem is that some functions (for instance, Data.Set.showTree) can produce different results for two values that compare equal.
For instance, imagine we have a set containing (only) the lists `[1,2]` and `[2,1]`; let's call it s. How many elements are in `fmap (Data.Set.showTree . Data.Set.fromList) s`? Two, because the result of fromList winds up being order dependent in the structure of the internal tree, even though both Sets represent the same set of values. On the other hand, how many elements in `fmap showTree . fmap fromList`? Just one, because the Set has a chance to "see" the output of fromList and notice that they are equal according to Eq.
Does this violation of the functor laws matter? Maybe; likely not; it depends on your use case.
But mathematically it means that the thing we are working with is not a functor, and so the thing we are working with is also not a monad (as all monads are functors).
İ prefer to say that show tree violates the abstraction. You can have s1=s2 but not f(s1)=f(S2). So f (show tree) is not a real function (or = is not a real equal). But showtree is a debug function, it doesn't count. İt's like saying in C that a=13 and b=13 isn't a real equality because &a and &b are not equal. There is the underlying structure and the structure after the equivalence. You have to know of what you're talking.
I'm not unsympathetic to that position, but I think it's ill advised to take it as far as "Functor means functor up to Eq". I grant that showTree in particular is a debug function that will usually be called at the end of any meaningful computation, and handwaving it in particular away is probably fine. I don't think we can say the same of something like splitRoot, which instead breaks the abstraction for the sake of efficiency.
> You have to know of what you're talking.
And the language (/ecosystem) gives you no way of specifying, so we have to be somewhat conservative. I've actually been thinking (partly driven by trains of thought such as under discussion here) that it might be very interesting to have a language that let you reason explicitly about different sorts of equality (tentatively defined, in the context of the language, as indistinguishability relative to some interface).
We need an explanation why we should care about support for currying. Where it is really just to support variadic argument lists, it is a big hammer for a little problem.
And precisely because of the code sample, it should be obvious that currying is not the same as variadic function arguments.
Instead, it allows for very concise partial function application, as demonstrated by the code. I can just call any function with a subset of its arguments, and it automatically returns a “new function” which you can call with the remainder of the arguments. It allows you to reason about calling functions in a different way.
Currying is one of those concepts done very well in languages such as Haskell (not a coincidence, as both derive their name from Haskell Curry).
But saying it’s a “big hammer to implement variadic function arguments” is like saying that pattern matching is a big hammer to implement a switch statement. Yes, it provides that functionality, but also much more in a very elegant manner.
Saying "it allows for very concise partial function application" does nothing but repeat the definition. It does not, in particular, offer any reason to want that. What is so special about the first argument, that I want to fix it? Why not the third? Why is what I do to fix the third not just as good for the first?
Pattern matching is a good example of a language feature included because they could not figure out how to provide features expressive enough to be composed to implement the feature in a library.
In a language like Haskell, pattern matching was explicitly chosen to be a primitive operation. It's not that there's no way to put it in a library; it's that it was chosen to be one of the small set of ideas everything else is described in terms of. Along with allocation and function application, you've got the entirety of Haskell's evaluation model. (Note: not execution model. That needs a bit more.) Having such a small evaluation model probably should be taken as evidence the primitives were chosen well.
> Note: not execution model. That needs a bit more.
Actually... not really? You need the foreign function interface to have anything useful to execute, but (unless you're talking about something else?) the execution model is basically just a State monad carrying a unique magic token, built on top of the same evaluation model as everything else.
The execution model needs something that actually drives execution. There needs to be something that explains how IO actions are actually run. The state approach kind of works until you need to explain multiple threads, then it falls over.
Edward Kmett did some work to describe IO as an external interpreter working through a free monad. That approach provides very neat semantics that include multiple threads and FFI easily.
But IO needs something to make it go, and that something needs capabilities that aren't necessary for the evaluation model.
> The execution model needs something that actually drives execution.
Er, yes: specifically, execution is drivenby trying to pull the final RealWorld token out of a expression along the lines of `runState (RealWorld#) (main)`, which requires the evaluation of (the internal RealWorld -> (RealWorld,a) functions of) IO actions provided by FFI functions (hence why you need FFI to have anything useful (or more accurately, side-effectual) to execute).
> until you need to explain multiple threads
I don't. It's a terrible idea that's effectively the apotheosis of premature (and ill-targeted) optimization as the root of all evil.
I'm not trying to dodge your question, but the answer to your question is that until you work with it for a while you're not going to understand it. Any blog-sized, bite-sized snippet isn't impressive. You have to work with it for a while.
I speak many computer languages, and one of the ways I measure them is, "what do I miss from X when using Y?" The answers will often surprise you; the thing you'd swear up and down you'd miss from X you may never think of again if you leave the language, and some feature you hardly consider while you're in the thick of programming in X may turn out to be the thing you miss in every other language for the rest of your life. For me, one of the things I deeply miss from Haskell when programming elsewhere is the fluidity of the use of partial function application through the currying syntax. I see so many people trying to force it out of Haskell into some other language but there just isn't any comparison to the fluidity of
map someFunc . filter other . map (makeMap x y) $ userList
Currying enables that syntax. If you don't see how, I'm not surprised. Sit down and try to write a syntax extension for an Algol-descended language that makes it work that well. Be honest about it. Run some non-trivial expressions through it. What I show above you should consider the minimum level of expression to play with, not the maximum. If you pick something like Python to work in, be sure to consider the interaction with all the types of arguments, like positional, keyword, default, etc. It can absolutely be done, but short of re-importing currying through the back door I guarantee the result is a lot less fluid.
The question about "what is special about the first argument" is backwards. The utility of the first argument is something you choose at writing time, not use time. The reason why map's first argument is the function to map on and the second is the list to map over is nothing more and nothing less than most of the time, users of map use it as I show above. There's no deep mathematical or group theory reason. If you don't like it there are simple functions to change the orders around, and the goal of picking function argument orders is just to minimize the amount of such functions in the code. Nothing more, nothing less.
OK, thank you. The key seems to be that argument lists for functions in a language with easy currying are carefully designed so as to make currying maximally useful.
That's an example of why Haskell code is often hard to read, and why I'm glad this isn't available in other languages. Why not write out the callback given to map using a let block? Then you can give meaningful names to intermediate values so it's easier to see how the pipeline works.
(Though, functional programmers would probably pass up the opportunity and use one-letter variable names.)
"It depends". My long pipelines were still usually nice to read because I had context-relevant names and I didn't tend to name them with single letters. You could still read off from them what they were doing. However honesty compels me to admit that by Haskell standards I tended to write long variable names. Not everywhere; there's a lot of "f" in Haskell for "functions that I only know about them that they are funcitons" for the same reason one you aren't winning in C by insisting that every for loop has to use a descriptive variable rather than "i". But I tended towards the longer.
In real code I probably would have named it, but example code is always silly.
let f = makeMap x y
in map someFunc . filter other . map f $ userList
I suspect not as it certainly doesn't seem to improve the situation. Perhaps you could elaborate?
Edit to add: I was focused on the "write out the callback given to map using a let block" part and not the meaningful name part, but that's perhaps what's confusing about this to me, as (makeMap x y) seems like the most clear name possible here, what else could you do? This?
let mapOfXy = makeMap x y
in map someFunc . filter other . map mapOfXy $ userList
And then I've "partially applied" f. Is this what currying is?
The syntax I posted is ambivalent about which arguments you're partially applying, isn't that superior to only being able to provide the first argument?
Currying is turning a function with arity n into a sequence of unary functions.
f(x,y) = ... // arity 2
f = \x -> \y -> ... // sequence of two unary functions
f x y = ... // more compact representation of the above
Regarding partial application, your JS (?) example is basically what happens under the hood with Haskell, but without the ceremony:
f x y = ...
fByThree = f 3
fByThree y = f 3 y
Those last two are equivalent, but you don't have to include the y parameter explicitly, because f 3 returns a function that expects another parameter (like the function you wrote out explicitly).
And the Haskell version is more general, since it doesn't require a unique function to be written for each possible partial application. Of course, you can do this in languages with closures:
function fByX(x) {
return y => f(x,y);
}
fByThree = fByX(3);
But in Haskell that extra function isn't needed, it's just already there and called f. Regarding your last statement, there are also combinators in Haskell that allow you to do things like this:
fXbyThree = flip f 3
// equivalent to:
fXByThree x = f x 3
// JS
function fXByThree(x) { return f(x,3); }
// or
function fXByFixedY(y) { return x => f(x,y); }
fXByThree = fXByFixedY(3);
So I'm not sure it's strictly superior, it is more explicit though.
This is why I said to be sure to consider all the things you can do with function arguments. You can't in general assume that f(3) for a two-part argument can be read by the compiler as a curry, because the second argument may have a default. You also have to watch out in dynamic languages because the resulting function instead of a value may propagate a long way before being caught, making refactoring a challenge. (In Haskell it'll always blow up because the type system is strong, although you may not get the nicest error.) Imagine you have a whole bunch of code using this approach, and then you set a default value for the second argument. Imagine you're applying it to a whole bunch of code that wasn't written to optimize the first parameter as the one you want to partially apply.
The end result is you need a lot more noise in the partial call to indicate what it is you are doing, no matter how you slice it, and it interacts poorly with default parameters (which almost every language has nowadays) anyhow.
Currying support is orthogonal to how function arguments work. Some languages (e.g. OCaml according to this question[1]) combine named parameters with currying, allowing partial application with any of the function's arguments.
Assuming that this guide is aimed at people entirely unfamiliar with these concepts, I think it fails to explain the concept. Yes, it is plain English, but it is not simple or common English, and it's mostly code examples. I'm familiar with the concepts, but not fluent, and functional programming jargon I already knew is not clearer to me now than it was before I read it.
Good sample code, though. It only required me to look up a handful of things I wasn't already familiar with.
I agree, and not just the English. There is use of particular notation that does not explain anything unless you already know what it means:
> f is a morphism from a -> b, and g is a morphism from b -> c; g(f(x)) must be equivalent to (g • f)(x)
If I don't already understand (g • f)(x) this is not helpful at all. This other one especially jumped out at me (perhaps because I've personally never seen this "bent equals sign" ≍ before):
> A functor must adhere to two rules:
> Preserves identity
> object.map(x => x) ≍ object
What does that sign ≍ mean? If I don't know, I am no closer to understanding functors. And the sign is not explained anywhere in the document.
Except it's not and =, it's a ≍ sign, which looks almost identical. I'm not a mathematician and I don't know the deep theory behind functional programming, but the internet tells me that ≍ in Graham, Knuth, and Patashnik's Concrete Mathematics it's defined to mean the same thing as "Big Θ"[1], as you note.
A product type, named after Cartesian product, contains other objects of various types, but it is none of A, B or C itself.
If types A, B and C have respectively a, b and c distinct values, their sum type has a+b+c values (each value of each type is allowed) and their product type has abc values (the part of the value that belongs to each type can be chosen independently).
"The idea" practically, is whatever resolves the polymorphism. So context is a compiler function from syntax->semantics.
Eg., `+` is polymorphic, `1 + 1` and `"1" + "1"`... the context is whatever implicitly resolves `+` to `ADD` or to `CONCAT`.
The utility of these ideas is, in practice, just they provide a syntax for different kinds of polymorphism. Eg., for monads, we're basically just telling the compiler to change its implementation of `;`
This explanation is useless imo because it expects the reader to already understand the weirdest part:
"If I have a function A -> B, how could I possibly get something that goes in the direction F B -> F A out of it?"
The answer to this is: given e.g. a function that accepts a B, i.e. `B -> ...` you can compose it with `A -> B` on the _input side_, to get a function that accepts an A, i.e. `A -> B` (+) `B -> ...` = `A -> ...`.
Once you've managed to get that across, you can start talking about contravariant functors. But expecting people to just intuit that from the condensed type signature is pedagogical nonsense.
Single-argument doesn't capture the difference between functor and applicative.
ex1 :: Functor f => f (Int, Int) -> f Int
ex1 = map (uncurry (+))
Applies a multi-argument function within a functor. What applicative allows you do is take a product of contexts to a context of products, and lift a value to a context.
pure :: a -> f a
zip :: (Applicative f) => (f a, f b) -> f (a, b)
This can then be used to make ex1 into a multi-argument function of contexts, which is not the same as (uncurry (+)) being a multi-argument function
ex2 :: (Functor f) => (f Int, f Int) -> f Int
ex2 = ex1 . zip
I find your list a lot more helpful (and succinct) than the linked repo in the thread topic. Kudos! Perhaps you should make your own repository -- I would upvote it!
"A homomorphism is just a structure preserving map. In fact, a functor is just a homomorphism between categories as it preserves the original category's structure under the mapping."
The closest I've come to understanding Monads was funny enough, the Wikipedia page (ok so there's at least two pages on Wikipedia for Monads, one in a category theory context, and one in a more general programming context, the latter I could actually begin to grasp). It wasn't overly full of vocabulary from category theory, nor did it try to compare it to taco bell menu items.
A monad is a special kind of a functor. A functor F takes each type T and maps it to a new type FT. A burrito is like a functor: it takes a type, like meat or beans, and turns it into a new type, like beef burrito or bean burrito.
Best comment in this thread. The guide does a so-so job of building on terms previously defined. The term accumulator, for example, is not defined before use. The first appearance of it is under Catamorphism, where the guide says, "A reduceRight function that applies a function against an accumulator and each value of the array (from right-to-left) to reduce it to a single value."
I note, in passing, that the actual guide is just titled "Functional Programming Jargon". It does not claim to be "in plain English".
I didn't really understand FP until I read Functional Light JavaScript by getify/Kyle Simpson. It is so well written and approachable by mere mortal coders. I'm not an FP wizard, but it is the coding paradigm I mostly use now. I've even adapted some aspects (e.g. composability) to the CSS I write using `var()`.
Lists like this tend to be a bit overwhelming without context, because a definition can often seem to focus on things that don't make sense if you don't understand the use case, even if you understand the words.
Even if you've read the definition of functor first
> Lifting is when you take a value and put it into an object like a functor. If you lift a function into an Applicative Functor then you can make it work on values that are also in that functor.
Is a pretty rough sentence for someone not familiar. I think Elm does a pretty good job of exposing functional features without falling into using these terms for them, and by simplifying it all.
It does pay for that in terms of missing a lot of the more powerful functional features in the name of keeping it simple, but I do think it makes it a great entry-point to get the basics, especially with how good the errors are, which is very valuable when you are learning.
I know it's a controversial language on HN to some extent (I certainly have my own issues with it shakes fist at CSS custom properties issue), but I genuinely think it's a great inroad to functional programming.
While I appreciate FP using terminology from its math origins - I do think it's a huge barrier for entry, and not really sure languages that cling onto them, will see much real mainstream success.
But then again, I don't think the language maintainers et. al. are too concerned with widespread success. Just some observations, but the majority of people I know that actively use FP languages, are academics. I've encountered some companies that have actively gone with a FP language for their main one - but some have reverted, I guess due to the difficulty of hiring.
With that said - functional elements are becoming more common in widespread languages, but not all the way.
I think using math terminology is honest, in that it gives an accurate expectation of how the ideas can be communicated and learned. They are simple ideas that can be communicated in their entirety in just a few symbols, but it takes time, exposure, and practice to develop facility in their use and a feeling of "understanding."
That's the math experience. I know people hate that and would much rather it be a matter of reading some a nice explanation and then "aha" but there's no such explanation yet and after years of people trying to develop one there's no point in expecting one right around the corner.
I agree about the math terminology, but I think it would be more confusing if we created a completely different set of vocabulary for the same concepts. So I don't really know what to do: refer to something by its proper name, or create a new, less precise name to make it sound less scary? Why do we find certain identifiers scary in the first place?
I don't. FP terminology is so bad that clearer names (Mappable, Chainable, etc.) would really help adoption.
You might say "but it will make it more confusing for people who already know the FP terms", but those people are a tiny minority of programmers so it doesn't make sense to cater to them. At least if you want your language to be popular among anyone except academics.
> You might say "but it will make it more confusing for people who already know the FP terms"
People who already know FP would be fine. Newcomers would be the ones to suffer. We already have a large number of tutorials, blogs, books, etc. using the existing terminology. For a programmer new to FP to tap into that they would need to learn both the "friendlier" (whatever that means) terms as well as how they map to the math terms.
We need to stop treating math like some unlearnable alien language—you'd still need to learn it anyway, regardless of what you call the abstractions. Also in many (perhaps most) cases there is no clear choice for the "friendly" term. Words like "chainable" would be highly ambiguous, as many different types of abstractions support some notion of "chaining". This would likely result in bikeshedding and more divergence in terminology and less precision in meaning.
If you think the math terms are bad, try asking a mathematician to rename the terms in their field. They'll tell you the same thing.
A "functional language", like an "object-oriented language", is an exercise in futility. But support for a functional approach in a general language will often be useful.
Pet peeve: The word "just" when used to gloss over something with the author don't know how to explain. Using "just" shift the burden from the author to the reader, since it signals it is the readers fault if they don't understand.
> A homomorphism is just a structure preserving map. In fact, a functor is just a homomorphism between categories as it preserves the original category's structure under the mapping.
How about removing the "just":
> A homomorphism is a structure preserving map. A functor is a homomorphism between categories as it preserves the original category's structure under the mapping.
Much clearer. Although most readers would now ask what "structure" and "structure preserving" means, since this is never explained.
Mathematicians use "just" with a specific meaning: it is not used to gloss over something that the author doesn't know how to explain. It has a purpose, useful for mathematically trained readers.
For suc a reader, "a homomorphism is just a structure preserving map" makes it clear that "homomorphism" and "structure-preserving map" can be used interchangably, and that by understanding one of the concepts, you'll immediately understand the other as well.
When you got rid of the word "just", you got rid of this connotation and changed the meaning of the sentences.
E.g. the sentence "a functional is a linear transformation" is correct; but not all linear maps are functionals, so writing "a functional is just a linear transformation" would be plain wrong in a mathematical setting.
That would be an extremely good thing to explain in the introduction. I feel like this kind of very culturally-specific usage of everyday words is what makes math/CS papers so impenetrable for many people.
The word "easy" is another example: saying "it is easy to show X" (just?) means that X can be derived from the already stated theorems in a more-or-less mechanical way without having to introduce new concepts. It does not in any way suggest that deriving this will be "easy" for a student reading the paper.
(Of course the most challenging "easy" parts are best left as an exercise for the reader anyway...)
>Mathematicians use "just" with a specific meaning: it is not used to gloss over something that the author doesn't know how to explain. It has a purpose, useful for mathematically trained readers.
Based on the author's public profile, I'm not convinced the author is a mathematician writing "... is just ..." as rigorous formalizations for a math-trained audience.
Instead, the "is just" phrases are innocently slipping into explanations as a subconscious verbal tic caused by the The Curse of Knowledge. My previous comment on that phenomenon: https://news.ycombinator.com/item?id=28256522
(Also, as a sidebar followup to your comment, Wikipedia's page about homomorphism (https://en.wikipedia.org/wiki/Homomorphism) has this as the first sentence: "In algebra, a homomorphism is a structure-preserving map ..."
I'm guessing that a hypothetical edit to "a homomorphism is _just_ a structure-preserving map" -- in an attempt to add more refinement and precision to the definition... would be rejected and reverted back by other mathematicians.)
Sure, but the title does say plain English so this would be the sort of thing the author is trying to avoid. If that’s the meaning just write all a are b.
While I agree that the English used in the repo could be plainer, that's not remotely the same thing as "using 'just' to gloss over something that the author doesn't know how to explain", which was the complaint that goto11 made.
This has not been true in my experience, as someone who is used to talking to a mathematician during my academic life (a bit). They prefer to not use words like "just X".
They generally reply in definite statements, "this is undecidable", "this is an example of X", "this can't be done without Y", they rarely say.
"X is just Y", they would probably say, "X is Y".
The "just" implies some form of detail that might be missing in the relation generally. Even my mathematical text books of pretty advanced topics rarely used "just".
Again, what you say is most likely true when math people talk amongst themselves but I don't think they do so with other non math people. I was in compsci.
> The word "just" when used to gloss over something with the author don't know how to explain.
Never thought of that before, but it's certainly true. Always hated when we got cryptic explanations for the difficult things, and elaborate explanations for the stuff everyone understood anyway at the university. I guess professors have to explain things they don't fully understand from time to time
Just to be clear, that's quite literally the Wikipedia definition.
> In algebra, a homomorphism is a structure-preserving map between two algebraic structures of the same type (such as two groups, two rings, or two vector spaces).
Not sure if this is rude but many definitions there seem a bit, not plain English.
I am assuming we are aiming for something close to ELI5 if the title says plain English.
Ofc that could not be what the author intended and is just but that's how inferred the title.
I will see if I can find time to improve and send some PRs for the ones that are in deep need of simplification, hopefully OP is open to discussing changes.
Also like Arity, Arity is not just for functions, it can sometimes be interchanged with Rank and apply to even Types. higher ranked types. higher arity types...
I do understand they are not something most people like, because of their issues but that's not a complete definition so I assumed it was for the means of simplifying to explain to beginner programmers. [reference to issues with HRTs](https://www.sciencedirect.com/science/article/pii/S016800729...)
Again this is not meant to be rude to the author, just hopefully the title could be better formed to explain the intent of the work.
Or my opinion might be minority and we can decide against it as well ofc.
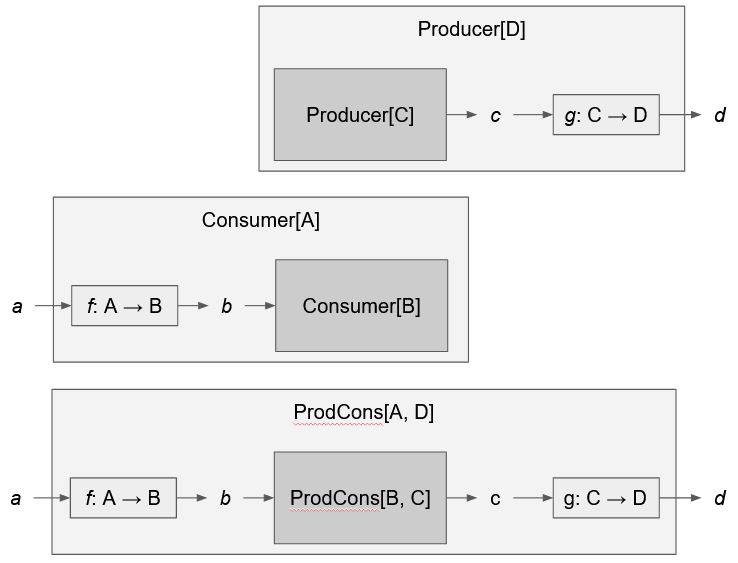
• You have a producer of Cs, then you can turn it into a producer of Ds by post-processing its output with a function g: C → D.
• You have a consumer of Bs, then you can turn it into a consumer of As by pre-processing its input with a function f: A → B.
• You have something that consumes Bs and produces Cs, then you can turn it into something that consumes As and produces Ds using two functions f: A → B and g: C → D.
You can get a lot of mileage out of functional programming as a style without using a functional programming language, and you can do it in (almost) any other language, the big one: avoid side effects to functions as much as possible. That alone can make all the difference between a maintainable, refactorable and testable codebase compared to one that has side effects all over the place. If that's all you get out of it that's profit.
That's always been good programming practice to me, not functional per se. I learned the term 'spaghetti code' early on and took it to mean not just gotos, but lots of flags, especially globals.
The biggest benefit I see is lack of side-effects. With a functional program you can be sure that your can safely call any function without having to worry about the current state of your app.
A proper functional program can start to do very cool things safely: like hot reloading of code. When I'm debugging a Clojurescript app I can have a live running game, and update the physics without even reloading the page. It's all live.
A proper functional program really looks like a series of mappings from a collection of data sources to a collection of data sinks.
There are other benefits like composability, designing your programs this way will give you access to algorithms that works otherwise not work with your code. The simplest example is Map, Filter, and Reduce. These functions are by their very nature parallel because a compiler knows that there are no intermediate steps, unlike a for loop.
I should probably add that I program mostly C# so I'm getting Functional benefits like Map and Filter because Eric Meijer added LINQ. He made it his life's work for a few years to bring functional programming to the masses.
But I was minimizing state long before that because state makes any program much harder to understand.
C# might not be the best language to try FP in. F# is a popular alternative that might feel more familiar than e.g. Haskell. Since JS was one of my first languages, I learned a lot just from using the library RamdaJS which helped soften the learning curve for me
Julia gives such beautiful examples for composabilty:
Feed 3km+-10m into an algorithm which was written with just numbers in mind and units and confidence intervals often propagate all the way through.
https://fsharpforfunandprofit.com/ This might provide a pathway to groking FP. As you mentioned in another comment to have c# experience, you should already have all the tools installed to get started in f# as well.
That's a very good point. People think of functional programming languages and OOP languages as entirely separate worlds that, like oil and water, do not mix. In reality they're equivalent, they just have different ergonomics.
For example, lambdas can be translated to anonymous inner classes.
This is more helpful than anything I have ever encountered on the topic.
Comments:
1. It should explain map somewhere before it is used.
2. For the more abstruse and abstract concepts, a comment suggesting why anybody should care about this idea at all would be helpful. E.g., "A is just a name for what [familiar things] X, Y, and Z have in common."
3. It goes off the rails halfway through. E.g. Lift.
Expanding on your #1, I think they could use some more definitions. As you say, they use "map" in its functional programming sense before defining it, but I think more confusing is this one:
> A category in category theory is a collection of objects and morphisms between them.
What is a "morphism"?
I think this is a great starting point though, which could use some expansion.
A category in category theory is a collection of objects and morphisms between them. In programming, typically types act as the objects and functions as morphisms."
There is a myth that "monads" are magical insights of some sort -- it's not.
Difficult to understand: likely yes because the myth is not groundless. What "monads" capture is how to combine things with a lot of ceremony: (0) the things that we want to combine are sharing some structure/properies (1) we can inspect the first thing before deciding what the second thing is (2) we can inspect both before deciding what is the resulting combination. What requires a lot of thought is appreciating why "inspect, decide, combine" are unified in a single concept.
Important: indeed, because in Haskell-like languages monads are pervasive and even have syntactic primitives. It's also extremely useful when manipulating concepts or approaching libraries that implement some monadic behaviour (e.g. promises in JS) because the "mental model" is rigorous. If you tell someone a library is a monadic-DSL to express business rules in a specific domain, you're giving them a headstart.
Some final lament: there's a fraction of people who found that disparaging (or over-hyping) the concept was a sure-fire way to yield social gain. Thus, when learning the concept of monads, one situational difficulty that we should not understate is that one has to overcome the peer-pressure from their circle of colleagues/friends. Forging one's understanding and opinions takes more detachment than the typical tech job provides.
Many important "effects" (e.g. non-determinism, IO, asynchrony, environmental context, state... etc) are modelled as monads in Haskell.
You _can_ write Haskell code without understanding what a monad is, but composing and creating these things is going to be a little painful without that understanding.
Additionally, it seems to be a harder concept to grasp than e.g. functors or monoids.
I think this can be partly attributed to many Haskell programmers first being introduced to monads that are less than ideal for understanding the concept.
I think this was some amazing insight. I understand monads and I can use/write them but I feel like the concept hasn’t FULLY clicked yet. While even now it hasn’t, I feel like your blogpost got me that step closer to it, so thank you!
If you want a lazy-by-default language, you need to deal with a problem — laziness means you don't need to actually evaluate the reads until you use `a` and `b`, and the print uses `b` before `a`, so the two reads can be executed in reverse order:
a = read()
b = read()
print("{b}, {a}")
One of Haskell's original goals was precisely to be lazy-by-default, which necessitated coming up with a way to solve this problem, and monads are the solution they came up with that gave us reasonable ergonomics. From a practical point of view, monads are just types that have reasonable implementations for three simple functions: `pure`, `map`, and `flatten`
# lists as monads:
pure 1 = [1] # put a value "inside" the monad
map f, [1, 2, 3] = [f(1), f(2), f(3)] # apply the function to the "inside" of the monad
flatten [[1], [2, 3]] = [1,2,3] # take two "layers" and squish them into one
# also, the simplest, but least useful, way to use functions as monads:
pure 1 = (x -> 1) # putting a value inside a function is just giving you the constant function
map g, f = (x -> g(f(x))) # map is just composition
flatten f = (x -> f(x)(x)) # you squish by returning a new function that performs two nested calls
("reasonable" here largely means "they follow the principle of least surprise in a formal sense")
The trick is that, once you know what monads are, you can use them in any language (with varying degrees of support), and you can see instances of them everywhere, and it's an incredibly useful abstraction. Many common patterns, (like appending to a log, reading config, managing state, error handling) can be understood as monads, and compose quite well, so your program becomes one somewhat-complex data type, a handful of somewhat-complex functions that build an abstraction around that data type, and then lots of really small, really simple functions that just touch that abstraction. I have a .class parser written in Scala that exemplifies this general structure, need to put it up somewhere public.
I think one of the reasons for the meme is because there's so many monad tutorials. When a Haskeller is introduced to monads they'll run across all these monad tutorials with abstruse analogies for what a monad is. Is a monad a burrito? Or a space suit? Odds are that none of these analogies will make much sense and the programmer will have to figure out on their own, what is the deal with monads after all. At some point they might have an epiphany; monads are the sort of idea that is actually pretty neat when it "clicks". They will feel compelled to write a monad tutorial, and thus history repeats itself.
For me the difficulty comes from the formal explanations/definitions, those always manage to confuse me. Result & Option types seem to have something to do with it so I may already have some understanding of the concept. But many explanations containing the word Monad also contain various other abstract mathematical terms. Trying to explain the concept to someone without mathematical background can be tricky.
Why does this come up so often when people talk about Java?
Because beginners are confronted with the IO Monad if they want to write a Hello world program.
Monad is a typeclass that any datatype can implement. Monads have a then or flatmap like function that takes a Monad and a function that operates on the contents of the monad but also returns another monad of the same type which is then combined according to the implementation details of the specific monad that implements the monad typeclass.
They are used pervasively in Haskell, less so in other functional languages.
In Haskell, you can't write a "Hello world" program without using monads, so you cant really avoid learning about them.
IMHO monads are only really useful in Haskell because it has specific built-in syntax sugar to support them. Without this syntax sugar, they would be very cumbersome to use. So it's not really the monad type per se which is interesting, it is the code style which the syntax sugar enables.
And the reason you can't write "Hello world" in Haskell without using a monad is that functions in Haskell are "pure", meaning they cannot have side effects like outputting to the console.
Preventing side effects, including reading and writing global state, helps prevent bugs and makes it easier to understand and refactor Haskell code. Some would argue that the extra layers of abstraction from category theory and unpredictable order and number of lazy evaluations can actually make it harder to understand and refactor Haskell code.
Anyway, in order to perform I/O in Haskell, you evaluate your pure functions as a sequence of actions that are executed by the Haskell runtime. The construct that helps you build the sequence of I/O actions and allows you to bind their intermediate values to arguments to be used by subsequent actions is called the 'IO' monad.
While it's true that `IO` in Haskell has a `Monad` instance, you don't really have to know that to do `IO` in Haskell. Certainly you don't need to know `Monad` in the abstract to use `IO` concretely.
I like Haskell's `do` notation, which is its syntax sugar for monads, but it's really not that bad without. For example:
do name <- getLine
putStrLn ("Hello " ++ name)
isn't really that much nicer than:
getLine >>= \name-> putStrLn ("Hello " ++ name)
or even:
getLine >>= \name->
putStrLn ("Hello " ++ name)
The main reason that monads are important in Haskell is that programs that do IO simply are not functions in a mathematical sense. If Haskell were limited to functions, it wouldn't be able to do IO.
Not as an "escape hatch" (that would be something more like `unsafePerformIO :: IO a -> a`), but as a principled way to compose (among other things) IO actions.
A Haskell program executes the IO action at `Main.main`, which must have type `IO ()`.
`putStrLn :: String -> IO ()` is a pure function - if you give it the same input, it always the same IO action as a result.
Monads are (for better or worse) contagious. So when one function calls a monad, then it needs to be included in the monad as well. It makes introducing memoisation to a file, randomisation, and memoisation not-to-a-file (without using lazy evaluation to express it) difficult. I don't know whether the alternatives (effect systems for instance) help with this.
I personally don't use functional languages because I find them too difficult given the needs and interests I have. I think about computations sequentially most of the time.
But then monads are a way to think about computations sequentially. If I write highly sequential code in a C-like language, in many cases most of the code is just boilerplate made necessary by the absence of native support for monads:
int ret = doStepOne();
if (ret == RESULT_OK) {
ret = doStepTwo();
}
if (ret == RESULT_OK) {
ret = doStepThree();
}
return ret;
Separating IO is kind of the killer feature, something like `rand()` is not an int unless you're reading dilbert[1] or xkcd[2]. Basic equations break down in the face of an Int-valued IO-action being conflated with an Int
Monads themselves aren't really contagious, it's the actions that would otherwise have side-effects that are, and also the fact they have to be executed in sequence.
This is also true for other things in other paradigms, such as async functions in javascript.
This is a good thing, however. In imperative programming, you have invisible temporal coupling. In pure-FP you have the same coupling, but it's exposed.
While I broadly agree with you, I think the post you're responding to has a point. You can't, in general, get a value back out of a monad, so if you call a monadic function, you may well have to return a monad. The obvious example is IO: there's no (safe) way get the `a` from `IO a`, so IO is kinda contagious.
Then again, there are lots of monads, such as `Maybe` and `List`, where you can get values out. These aren't contagious at all.
I agree with you that this is a good thing. Effects show up in the type signature - and it's all about those effects and managing them.
I think that applicatives and monads feel more contagious than they really are, because at first people tend to write functions that consume values of type `f a` too readily. This is because it takes some time to become comfortable with `fmap` and friends, so the new Haskell programmer often doesn't write as many pure functions.
I get why they chose to do this in Javascript, but I can't help but feel it's an awkward choice. Many of the examples (e.g. currying) look unnatural in javascript.
I think the title should have `JS` in it, because for quite few people it just might not make sense. Besides the examples are such that the author seems to have been simultaneously competing in a obscured code brevity competition. Plus, language is definitely not "plain English" wrt jargons.
This project should be exactly 1 (one) file. The readme.md.
LICENSE - There is a license? Why? Someone might steal the text for their own blog post? So what? The license won't stop them.
package.json - to install dozens of packages for... eslint. Just install globally. It's just markdown and code examples.
Yarn.lock - ah yeah let's have this SINGLE, NON EXECUTABLE TEXT FILE be opinionated on the javascript package manager I use. Good stuff
We have a .gitignore, just to hide the files eslint needs to execute. wow.
FUNDING folder - wow we have an ecosystem of stating the funding methods?
This should have never been a github repo. This is a blog post. It's a single, self contained post.
I hate this crap. We have 9 files just to help 1 exist. It's aesthetically offensive.
> LICENSE - There is a license? Why? Someone might steal the text for their own blog post? So what? The license won't stop them.
But it’s still good that author underlined that he don’t want it to be copied. What’s wrong with that?
> package.json - to install dozens of packages for... eslint. Just install globally.
Then other contributors won’t know what version he used, what config he had, he won’t be able to easily recreate it on different computer, etc…
> Yarn.lock - ah yeah let's have this SINGLE, NON EXECUTABLE TEXT FILE be opinionated on the javascript package manager I use.
That’s author choice. Any good argument against it or you will just criticize for the sake of it?
> This should have never been a github repo. This is a blog post. It's a single, self contained post.
It’s a blog post with 270 different revisions, 80 contributors and a bunch of different languages. Show me how to easily do that with a blog post.
> I hate this crap. We have 9 files just to help 1 exist. It's aesthetically offensive
Why number of files is offensive to you? We have a couple tools good at what they do to keep things consistent and organized. Better to have these tools to keep standards than not.
The document appears to have 80 contributors, that's hard to do with a blog post. It could have been a wiki page. But then I'm not sure if hosting a single repo on Github is harder than hosting a wiki. And of course Github provides superior platform for collaboration compared to a wiki.
I think it's cool that it's a repo. Now other people can submit pull requests and improve it.
As for the files, bah whatever. Go find a squirrel to bark at.
Can someone clarify something for me? If you build a linked list or a dynamically growing array in a Functional program, am I correct in understanding that the array is never modified, instead a copy is made and the new element is added to the copy of the array?
Immutable, fixed size arrays are pretty easy to handle in a functional style, of course, but most functional languages only discourage mutability while not outright forbidding it, so you'll usually have access to mutable dynamically growing arrays that work the exact same way as you expect them to.
Because functional languages do discourage mutation, they tend to fallback on an implementation of linked lists where the lists are never modified (You can google for Persistent Data Structures for more). Because the list never changes, you can have two lists share a tail, by building on two different heads atop that tail (like a git branch of sorts, minus the merging).
If you want to build a pure language, you can build immutable dynamic-sizeable arrays with a copy-on-write setup. Growing the array keeps building on top of the existing buffer, if you outgrow it or need to actually mutate it, you make a copy.
If you want both purity and actual full-on mutability, e.g. Haskell has Data.Array.MArray, which locks the array behind a mutable context (like IO), so your pure code never sees any mutation.
The result should be that after the addition you should not have affected the old array yes. The most basic way of implementing this is what you described. However, there are a number of different ways to optimize this. Since you know that the elements are immutable, if you add the new element to the start of the list you could just point it to the old elements and you now have two lists which share the majority of their elements. If you are interesting to learn about this more I would recommend looking into how for example Clojure implement their "persistent data structures". Most functional languages have similar things so you could find it elsewhere as well if you want.
1. You switch to a pragmatic language that gives you an escape hatch to mutate data.
2. You use a persistent data structure that lets it grow without needing to make millions of copies for millions of new entries.
3. You use a different constructor pattern to avoid the allocations.
For (3), a common way around this (with lists) would be to build it in reverse and then reverse it (assuming that the order actually mattered at all, if it doesn't you don't need to reverse it at the end). This is done in Erlang, for instance, as a common pattern:
You end up with two copies of the list, one in the constructed order and the reverse ordered version, but the constructed order one will be garbage collected in short order. Two copies, better than millions of copies.
You also see a pragmatic solution in Erlang with iolists. These are lists that contain items that you'd want to send to, well, IO functions. But instead of forcing you to allocate whole new strings for concatenation (a common thing to do with strings) like this:
S1 ++ S2 %% results in allocating a new string and copying contents from at least S1
You can do this:
Concatenated = [S1,S2]
Now it's a two-element list that references the two prior ones, you've allocated some new memory, but just enough for a new list. Now you have a third string you want to prepend?
[S3,Concatenated]
Again, minimal amount of allocation and copying (there is no copying). You can use this pattern in other situations and only flatten when needed, or "flatten" it by recursing over the structure to access all the elements but never actually constructing a flattened version.
So when you ask about the STL I can interpret that in several ways:
1. Good sized standard library for many common tasks, yes. You won't have to reinvent the wheel using functional programming languages. Though the size and scope of their standard libraries will vary. And when it's not in their standard library, code reuse is a thing and most have decent to good package managers for obtaining what amounts to community-standard solutions to problems not covered by the language standard.
2. Generic data structures. Definitely yes. Either by virtue of being dynamically typed (Erlang, the Lisp family) or because parametric polymorphism (roughly analogous to C++'s generics) has been a standard thing for 4 or 5 decades for the statically typed ones (ML family, Haskell).
They said 'a function takes arguments', which is correct. The arguments are passed into the function, aligning to and being bound to the function's parameters. So arity applies both to arguments the function can take, and the parameters the function has.
I thought this guide is great. Not sure why people are upset with it. It’s not the be all end all definite guide to the topic, but it definitely helps.
I especially like the examples given that remove ambiguity in explaining the concepts.
Though I think the closure example doesn't actually show capturing context. It's just a partial function application unless you count the literal '5' as a local variable.
Constant functors are only ever useful if you need to thread a simple value through code that asks for an arbitrary functor. I'd say that's rare even for abstract, type-level heavy code.
All these niche functional programming languages are an exercise in pseudo intellectualism
Give me an object oriented language any day. The world is made of state and processes, (modern niche) functional programming goes too far to derecognise the value of state in our mental models
The good thing about functional programming is stressing to avoid side effects in most of the code and keep it localised in certain places…
It's kinda funny, because you could say exactly the same about object-oriented programming as a discipline.
In functional programming the jargon might be foreign, but they correspond with the math they came from. You also have clear rules and clear situations where you can apply all those things.
In object orientation, however, we have mostly made-up jargon (from patterns and from SOLID), the "rules" for the application of those are completely fuzzy, arbitrary and broken most of the time, and even the categorisation of those is mostly made-up. It's pseudoscientific-mumbo-jumbo compared to Monads and other FP silly-named stuff.
Functional programming is actually mathematics based on lambda calculus.
Imperative programming isn't.
OOP is a failed metaphor, unless you use composition, not inheritance, even then, the actual basis for OOP was about the messages between objects, not the internals.
> The world is made of state and processes
No, the world is made of objects that have state and messages (events) between them.
The lambda calculus is an entirely arbitrary way to organize things in math. It’s not based on nature or truth at all.
The real problem, though, is that FP doesn’t do anything well. It’s never the fastest method of programming, which means that it needs to excel in some other way for its proponents to be right about it. Is it the most maintainable? Maybe if you have zero side effects but then any paradigm would be in that case. Once you introduce state, it becomes a nightmare to maintain, unlike OOP. It’s certainly not the most readable.
> The lambda calculus is an entirely arbitrary way to organize things in math. It’s not based on nature or truth at all.
Lambda calculus, category theory, and logic are essentially 3 sides of the same coin (the Curry-Howard-Lambek correspondence). The rules of lambda calculus match those of natural deduction. It runs quite a bit deeper than you're suggesting here. It's not just some arbitrary formalism.
Glad to see these comments because the parent's "it's math therefore from a deity, and much more correct than your grubby computer stuff" is so often trotted out. It turns out that there's no directionality to the relationship between mathematics and computers -- they're the same thing and one can be transformed into the other. e.g. Lambda Calculus is just a kind of VM someone came up with that can be used to model certain structures. Same for Category Theory, and same for Logic. So you might as well say that Lambda Calculus is derived from IBM 360 assembler language than the other way around.
There are limits on what lambda calculus can model though. For example, it doesn't model IO very well. So, these days, lambda calculus is only one of the parts of maths that informs functional programming.
I guess you could also say that the world is made of state, state transitions and state derivations, and functional programming does a great job of making the latter two reliable.
Every anything-oriented language amounts to wankage.
The world is a complicated place with complicated problems. Complicated problems are always solved by splitting them into different sub-problems, each routinely of radically different character than the outer problem, other sub-problems, or its own sub-sub-problems.
So, a language "oriented" for any one of those is a terrible choice for others. To solve any whole problem, your language should support all the styles that might be useful. Often, a sub-problem falls to a style combining a little of this style and a little of that. Styles should not be straitjackets.
Generally, it is better if the language is powerful and expressive enough that support for a style is not built in, but can be provided by a library. Any fancy built-in feature is always an admission that the core language wasn't strong enough to express it in a library.
That is why weak languages so often have fancy core features (e.g. dictionary): without, you would be left with no support. This should make us suspicious of a "match" feature.
A more powerful language lets you pick from variations on the fancy feature in a library or libraries. And, the library might define a new style useful for the sort of problems the library is designed for.
I can relate to your sentiment but calling it "pseudo intellectualism" is a step too far in my opinion. The math behind FP is legit. Like Programming Language Theory it can teach you interesting abstractions. And useful basic things like how most collections you use are monoids, map/flatMap, etc.
On the other hand, the original Design Patterns book was published in 1994. I'm still waiting for its FP equivalent.
Design patterns are just a repetition of the golden rule "don't repeat yourself" (when they're not they're antipattern). Maybe the functional developers don't need a book to teach them how to walk...
Either define concretely what the world is made of (i.e. particles and what they do), or don't use this sentence. Currently you just say "wow this is so abstract, it's actually <something else that's also abstract>". Turns out neither paradigm has anything to do with real life, they have their own niches and their own place within different contexts.
{kind=link}
"The ideas", in my view:
Monoid = units that can be joined together
Functor = context for running a single-input function
Applicative = context for multi-input functions
Monad = context for sequence-dependent operations
Lifting = converting from one context to another
Sum type = something is either A or B or C..
Product type = a record = something is both A and B and C
Partial application = defaulting an argument to a function
Currying = passing some arguments later = rephrasing a function to return a functions of n-1 arguments when given 1, st. the final function will compute the desired result
EDIT: Context = compiler information that changes how the program will be interpreted (, executed, compiled,...)
Eg., context = run in the future, run across a list, redirect the i/o, ...