I specifically assumed a max tweet size based on the maximum number of UTF-8 bytes a tweet can contain (560), with a link to an analysis of that, and discussion of how you could optimize for the common case of tweets that contain way fewer UTF-8 bytes than that. Everything in my post assumes unicode.
URLs are shortened and the shortened size counts against the tweet size. The URL shortener could be a totally separate service that the core service never interacts with at all. Though I think in real twitter URLs may be partially expanded before tweets are sent to clients, so if you wanted to maintain that then the core service would need to interact with the URL shortener.
Thanks for clarifying. I missed the max vs. average analysis because I was focused on the text. Still, as noted in the Rust code comment, the sample implementation doesn’t handle longer tweets.
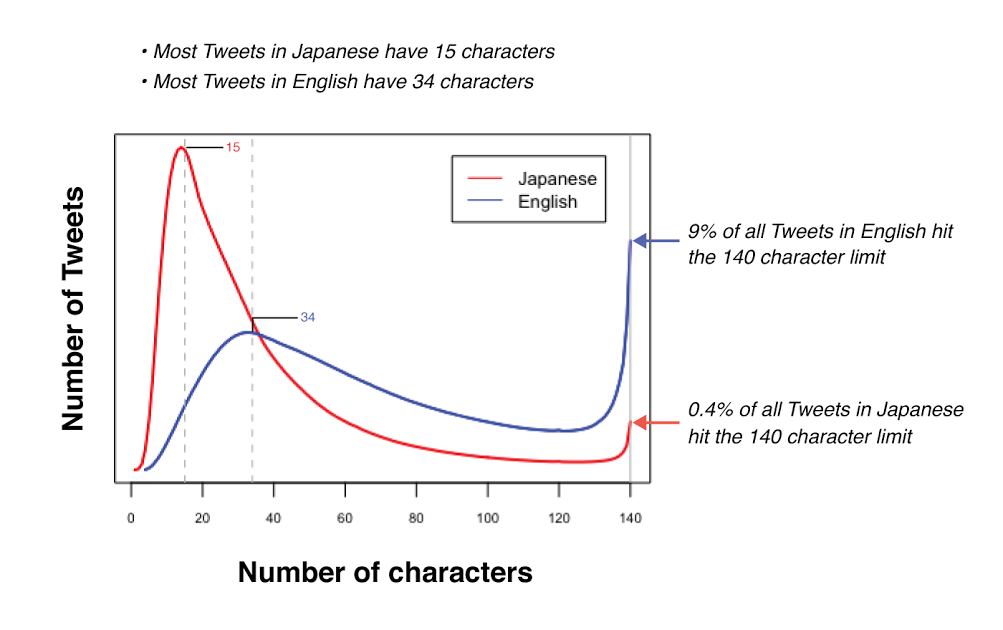
If it counted UTF-16 code units that would be dumb. It doesn't. The cutoff was deliberately set to keep the 140 character limit for CJK but increase it to 280 for the rest. And they did that based on observational data.
That size in bytes is based on the max size in UTF-8 and UTF-16. Codepoints below U+1100 are counted as one "character" by twitter and will need at most 2 bytes. Codepoints above it are counted as two "characters" by twitter and will need at most 4 bytes. Therefore 560 bytes, and it supports all languages.
Side note, this is more pessimistic than it needs to be, if you're willing to transcode. The larger codepoints fit into 20-21 bits, and the smaller ones fit into 12-13 bits.
{kind=link}