- Replace the partitioning code in flux_default_partition and flux_reverse_partition with the obvious AVX-512 version using a compare and two compress instructions
- If you're feeling ambitious, swap out the small array sorting, or incorporate crumsort's fulcrum partition for larger arrays.
I know why I haven't done this: my computer doesn't have AVX-512, and hardly anyone else's that I know seems to. Maybe a couple Zen 4 owners. I'm less clear on why the tech giants are reinventing the wheel to make these sorting alrogithms that don't even handle pre-sorted data rather than working with some of the very high-quality open source stuff out there. Is adaptivity really considered that worthless?
Fluxsort makes this particularly simple because it gets great performance out of a stable out-of-place partition. It's a bit newer; maybe the authors weren't aware of this work or started before it was published. But these algorithms both use (fairly difficult) in-place partitioning code; why not slot that into the well-known pdqsort?
You are right the initial kick-off point was an attempt to port fluxsort for a stable sort in Rust, but that quickly turned out to be unfeasible because Rust implementations have way higher requirements in terms of safety. The user can modify values during a comparison operation, leave the logic at any comparison point via an panic (exception) and the comparison function may not be a total order. Together these effects make most of the code in fluxsort useless for Rust. I had been working on ipn_stable and ipn_unstable to completely different implementations. ipnsort, previously ipn_unstable started off with the pdqsort port that is the current Rust `slice::sort_unstable` and from there on I iterated and tried out different ideas.
Well, I know what you mean but "completely different" is potentially misleading here. The current ipnsort is using bidirectional merges developed for quadsort (the merging part of fluxsort) and the fulcrum partition from crumsort, also by Scandum (all credited in comments; check the source if you want to see more influences!). To balance things out, the strategy for using the namesake sorting networks is new to me: pick a few fixed sizes and handle the rest by rounding down then a few steps of insertion sorting.
I should clarify, I meant that ipn_stable and ipn_unstable were separate projects, albeit with some cross-over ideas.
I can't rule out that someone else had that idea for limiting the use of sorting-networks, all I can say is that I came up with that myself. At the same time a lot of the good ideas in ipnsort are ideas from other people, and I try my best to accredit them. As I commented before, my goal is not peak perf for integers at any cost. Here is a commit https://github.com/Voultapher/sort-research-rs/commit/d908fe... that improves perf by 7% across sizes for the random pattern. But that comes with a non negligible binary size and compile time impact even for integers. And while I use heuristics to only use sorting-networks where sensible, they can guess wrong. This is a generic sort implementation with the goal of being a good all-round implementation fit for a standard library and those various uses.
"pick a few fixed sizes and handle the rest by rounding down then a few steps of insertion sorting."
I'm late to the party, but this sounds a lot like quadsort's small array handling:
Sort 4, 8, or 16 elements using unrolled parity merges, and handle the rest with insertion sorting.
An unrolled parity merge can be viewed as a stable sorting network. I never added unstable sorting networks to crumsort due to wanting to keep the code size low, and perhaps the mistaken idea that it would reduce adaptivity, as crumsort is likely to scramble partially sorted input.
I'm not talking about ipnsort, which I think is great. It makes good use of existing work and doesn't use AVX at all. So extending it with AVX-512 partition code would also be a good project!
Publishing a paper can be an imperfect, but useful 'expensive signal' that increases visibility. For vqsort, we initiated a collaboration with two universities who had published papers: KIT's ips4o for parallel sorting; Jena's fast AVX2 partition and 2D sorting network.
It needn't be AVX-512, but I'd consider AVX2 to be table stakes for any sorting algorithm. It's not clear that scalar techniques transfer to vector approaches (for example, multi-pivot partitioning did not help), and the speedup from AVX2 vs scalar is at least 3x.
It's not clear to me that special-casing already-sorted inputs is a net positive in practice outside of benchmarks. Sure, we can early-out as soon as a difference is found, but we're still paying for potentially an entire scan through the array, or a slowdown in partitioning (we found that even tracking the min/max had a noticeable cost). This can instead be done at the level of callers, who can then remember that this dataset is sorted and even skip the is-sorted check subsequently.
In-place seems helpful for benefiting from limited-size but faster memory such as L3 or even HBM.
Finally, why C? As you mention, AVX-512 is not ubiquitous, and we'd prefer portability over duplicating several thousand LOC for each instruction set. That's much easier (via Highway) in C++. Would a C-compatible FFI be enough?
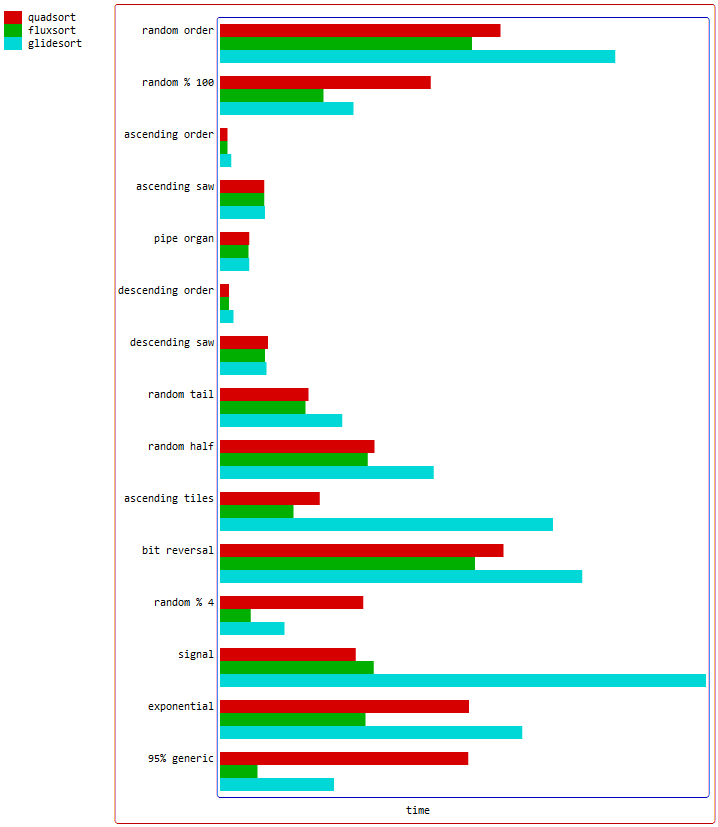
Pre-sorted data is just the simplest example of adaptivity. Partially-sorted input can't be tracked easily by the caller and I believe that something like merging a few sorted arrays by concatenating then sorting is pretty common. Fluxsort, glidesort, ipnsort, vergesort all have methods that allow for merging such patterns quickly. According to the benchmarks in the article, many are also doing better at low-cardinality data.
If you don't consider any of this adaptivity useful, it's very strange to compare to std::sort which does make some attempt to be adaptive. And strange that your documentation wouldn't mention the difference. But we all know why you're doing that. I suppose you'll keep your fingers in your ears regarding 32-bit radix sort, which has benchmarked at 1450MB/s for a million elements (2.77 ns/v) on M1: https://github.com/mlochbaum/rhsort/issues/2#issuecomment-15... .
The fulcrum partition from crumsort is an in-place adaptation of fluxsort's out-of-place partition, which is why I mentioned it. It's faster when things stop fitting in L2 in my testing.
> According to the benchmarks in the article, many are also doing better at low-cardinality data.
VQSort handles low cardinality quite well. Unfortunately only a few benchmarks in the article (not including that one) were re-run after our performance bug fix.
> it's very strange to compare to std::sort which does make some attempt to be adaptive.
We chose std::sort mainly because it seems to be widely used.
> But we all know why you're doing that. I suppose you'll keep your fingers in your ears regarding 32-bit radix sort
huh, I'm curious what's the background or context for this remark?
FYI I published a fast 32-bit radix sort in 2010: https://arxiv.org/abs/1008.2849
The trend has been towards less and less memory bandwidth per core, and we are often seeing servers bottlenecked on that.
Avx512 is also good for merging and pattern detection. Merging in the case of a large input (rather than just opportunistic for presorted subsequences) is arguably the most interesting part—a big queueing and data movement problem.
From what I understand, these sorts are only for direct lists of primitives. For most of the sorts I see, I'm trying to sort an array of structs with an embedded key. I know this organization destroys the memory access patterns that make SIMD effective. Is the best alternative to move the key out of the struct, and sort two arrays: one of primitive keys and another of original indices? This sort would still be very amenable to SIMD. It just requires a final pass where you rearrange the original array with the indices. Alternately, you could avoid sorting an array of indices and try sorting an struct of arrays directly. I don't see a lot of people handling this very frequent situation in these benchmarks. Any pointers?
It depends on the size of the structs. For struct pointers you're likely better off sorting keys and pointers simultaneously. It doesn't matter much until you get to large sizes (millions), but sorting indices and then selecting with them is random access. If the original ordering is messy, selecting can be slower than the sorting step. For structs a few words long, the unit you're moving is a larger portion of a cache line, and I'd expect the data movement to drown out any SIMD advantage. A radix sort might be all right because it moves less, but I'd probably go with sorting indices as the first thing to try unless I knew the arrays were huge. For very large structs there's an interesting effort called mountain sort[0], "probably the best sorting algorithm if you need to sort actual mountains by height". Given that it minimizes number of moves it's ignoring cache entirely. I haven't benchmarked so I can't say much about how practical it is.
In situations where I need to sort a list of large objects, I normally create an separate "OrderedView" or "Ordering" which holds either two lists [comparable_value] and [index] like you describe, or a single list of [comparable_value, index] (depending on the types and languages the second option will be faster). Then it just provides either an iterator. If you only need the ordering once this saves you from going back and re-ordering the original array.
If you need to run through the list multiple times, it probably makes sense to actually go back and re-order the original so that the accesses are linear memory. That is, unless the values are pointers in which the indirection will likely kill the benefit.
I agree this is a super common case. I don't have a benchmark, but I bet when actually moving structs the C qsort starts looking a lot more reasonable.
Often you can sort a u128 (or smaller integer) that is actually the key and a pointer or the key and an index into an array. You may find that a single pass to rearrange the original array to the sorted order is slower than multiple passes because of cache issues. I would certainly be interested in reading about this sort of thing if you find anything :)
So Rust's ipnsort is actually one of the better sorting implementations across a variety of input sizes. Faster than avx512 sort on small arrays, slower on mid sized arrays, and almost the same on large ones.
The avx512 sort seems like a questionable choice given it requires specialized hardware and is not the best option under many real-world conditions.
I'd like to emphasize that ipnsort is primarily designed as the new Rust std library unstable sort, which means it optimizes for all these factors simultaneously:
- input type (including stuff that is not an integer or float)
- input size
- input pattern
- prediction state
- binary size
- compile times
- varying ISAs and Hardware
Especially binary size and compile times mean I'm not chasing the performance crown for integers in some HPC setting. I can trivially pull out another 7% perf by ignoring binary size, compile times and effects on types that are not integers https://github.com/Voultapher/sort-research-rs/commit/d908fe....
This is a point that I'm kind of fuzzy on: is there a specific requirement to not change the algorithm too much based on type/comparison? Like if the user calls it on a 1-byte type with default comparison, the best way to do this in a vacuum is a counting sort. Smaller generated code and everything. Both C/C++ and Rust developers seem unwilling to do this, but not having asked I don't know why exactly.
On the other hand Julia just switched to radix sort much of the time in their latest version, so other languages can have different approaches.
As a datapoint, numpy also chooses between radix and timsort based on data type. From the docs [^0]:
> ‘stable’ automatically chooses the best stable sorting algorithm for the data type being sorted. It, along with ‘mergesort’ is currently mapped to timsort or radix sort depending on the data type. API forward compatibility currently limits the ability to select the implementation and it is hardwired for the different data types.
IIRC, there were issues with it causing frequency throttling on Intel cpus, whereas AMD's avoid that by "double pumping". It would be very interesting to compare and contrast there.
Seems like there's be value in it for all the new ML hotness that's come about. The AMD 7950x seems like it hits the sweet spot for that.
The vqsort README says it is a non-issue on that generation CPU (Skylake-X) based on their benchmarks: https://github.com/google/highway/tree/master/hwy/contrib/so...
At least on their low clock speed server CPU (<=3GHz), downclocking was hard to measure compared to clock speed variability they got with std::sort.
The 10980xe used for windows benchmarks here normally boosts much higher, so bigger differences could be expected. The author of OP mentioned measuring clock speeds with perf and seeing some difference.
I've read the C++ code used in the benchmark and noticed several issues that would affect its performance (wrapping comparison function behind multiple layers of indirection, throwing exceptions (!?) from comparator, passing arguments as references rather than values, not using the C++ sort "Compare" template argument). Given the amount od indirection and boilerplate I'm pretty skeptical of the results od this benchmark.
Argh. Apologies to the author. I didn't see the original when I looked before submitting, and I expected HN to pop up a link to the existing post, like it usually does. Wasn't my intention to post a dupe :(
The data stops before it gets to useful sizes (10e7 and up). How are people implementing sorting algorithms not routinely working at 10e9-10e12 where the workload is actually a bottleneck?
I run ml algorithms like boosted trees (i.e xgboost) on data sets with 30k-1m rows and 200-2k columns. Sorting is the bottleneck, it's what the algorithm does. I doubt I'm special, and I'm sure these size are common
Ok so both the things you linked are not my ideas. The first one is AFAIK originally from the BlockQuicksort paper https://arxiv.org/pdf/1604.06697.pdf section 3.2. Which Orson Peters used in his pdqsort, which I know base ipnsort on. The second one is from Igor van den Hoven in his work on quadsort as I mention in the function description. Really a lot of this stuff is building on top of other peoples work and refining it. Seemingly I'm the first to write neat little ASCII graphics for them in the code making them easier to approach. There are some novel ideas by me in there too though, for example https://github.com/Voultapher/sort-research-rs/blob/42bf339d... the way I marry a limited number of sorting-networks, insertion sort and the bi-directional merge into one, very fast but binary size and compile time efficient package is novel. Or that with LLVM you can do 2 instead of 4 writes per loop iteration in the bi-directional merge, which Igor has now ported back to his stuff as well. Generally I'd say my work has been more about figuring out novel ways to combine existing ideas into one good cohesive package fit for a standard library sort implementation. As well as taking ideas that work in the C and C++ world and doing the legwork to adapt them for use in Rust, which requires a lot more considerations and a lot of code can't be ported straight up. I wrote a little more about that in another comment here.
As you can see, quadsort 1.1.4.1 used 2 instead of 4 writes in the bi-directional parity merges. This was in June 2021, and would have compiled as branchless with clang, but as branched with gcc.
When I added a compile time check to use ternary operations for clang I was not adapting your work. I was well aware that clang compiled ternary operations as branchless, but I wasn't aware that rust did as well. I added the compile time check to use ternary operations for a fair performance comparison against glidesort.
As for ipnsort's small sort, it is very similar to quadsort's small sort, which uses stable sorting networks, instead of unstable sorting networks. From my perspective it's not exactly novel. I didn't go for unstable sorting networks in crumsort to increase code reuse, and to not reduce adaptivity.
Do you feel like you have a sort of "intuition" for which things might work, and you experiment starting from that, or what is your general thought process like?
Or maybe you start by drawing things out on paper? Really curious what the process of reasoning and thinking about something like this is.
As with many things experience plays a large role. I've now spent more than a year a probably more than a thousand hours on and around the topic of sort implementations. The way I think about this now is very different to the start. I have a background of investigating and wanting to understand compilers and how they interact with modern hardware. My mental model of how hardware works is usually my start-off point to try out ideas. More often than not my ideas don't work out and my mental model is wrong. That's ok, modern hardware is a giant bunch of shared mutable state that interacts in really non-trivial ways. So I guess yes I've developed an intuition, but I always try to prove it wrong with experiments. Sometimes I sit down with pen and paper and scribble ideas down, sometimes I start coding an implementation directly, sometimes I start with an experiment setup, sometimes I search for what other people have done in that space, and I've even tried asking Chat-GPT about some stuff but that has been mostly useless. Specifically with high-performance sort implementations it helps to think of them as a bunch of components that each have their own role. Giving a simple example of a quicksort based implementation, you have partitioning, small-sort, fallback and some kind of pattern analysis. Each component exists to fulfill a certain role, partitioning is the algorithmic core and should perform well for sizes above your small-sort threshold up to really large sizes. The small-sort is maybe the most perf critical part, quicksort will spend most of the calls, not necessarily most of the time, in the small-sort, classically insertion sort e.g. https://user-images.githubusercontent.com/6864584/200373619-.... The fallback is there to make sure that you have a worst case Big O(N * log(N)). It should take over if a certain recursion limit is reached based on the input size, eg. `2 * (len | 1).ilog2()`. And the pattern analysis, for example a simple streak analysis usually sits at the start and makes sure that fully ascending and descending inputs can be sorted in O(N - 1). Hope this answers your question, and thanks for asking :)
You cleverly wrote "sort" two times without referring to actual sorting in a thread about sorting.
The first algorithm that you linked is easy to explain. As soon as a value has been stored in another location its original location can be overwritten. To get started we move something to an additional location called temp A > Temp. Then we can overwrite it with the intended value Z > A. Then we can overwrite Z and so on and so forth.
There's also the ability to notice strange/curious/discordant things, and either connect the dots through trying semi-random things, as well as sudden insights which seem to be partially subconscious.
One of my (many) theories is that I have the ability to use long-term memory in a quasi-similar manner to short-term memory for problem solving. My IQ is in the 120-130 range, I suffer from hypervigilance, so it's generally on the lower end due to lack of sleep.
I'd say there's a strong creative aspect. If I could redo life I might try my hand at music.
Before attempting to parse the whole text, I suggest starting from the end of it and the update written two days ago (according to the history of the changes):
"The new version of vqsort addresses the main issue of very poor performance for smaller inputs, and even manages to improve overall performance for larger inputs. With this it is now undoubtedly the fastest sort implementation in my testing"
{kind=link}
{kind=link}
- Clone fluxsort (https://github.com/scandum/fluxsort)
- Replace the partitioning code in flux_default_partition and flux_reverse_partition with the obvious AVX-512 version using a compare and two compress instructions
- If you're feeling ambitious, swap out the small array sorting, or incorporate crumsort's fulcrum partition for larger arrays.
I know why I haven't done this: my computer doesn't have AVX-512, and hardly anyone else's that I know seems to. Maybe a couple Zen 4 owners. I'm less clear on why the tech giants are reinventing the wheel to make these sorting alrogithms that don't even handle pre-sorted data rather than working with some of the very high-quality open source stuff out there. Is adaptivity really considered that worthless?
Fluxsort makes this particularly simple because it gets great performance out of a stable out-of-place partition. It's a bit newer; maybe the authors weren't aware of this work or started before it was published. But these algorithms both use (fairly difficult) in-place partitioning code; why not slot that into the well-known pdqsort?