> Yes, I had failed to see the proper solution: a class generator — so that I didn't have to manually copy code again
No, please don't. This is jumping from the frying pan into the fire. If you think abstract base classes can be clever and hard to understand, code generators can be even more so. In addition, because code generators are a one way conversion, and the generated code evolves independently and the code generator itself is evolving independently, you end up with a bunch of things that are subtly different yet somewhat related in a way that you will need an advanced degree in evolutionary biology to understand.
As a blog post with the title "Don't be clever" ending up with the author's answer being an even clever-er solution, than talking about the hidden fight against complexity in software, was an odd ending note.
I think it’s just a great metaphor, and an experience I seem to relive over and over. Every time I think I have something figured out, hindsight always shows me I didn’t. This probably leads to me living in a state of perpetual overconfidence. Because even if I don’t fully know what I’m doing, look at past me! That dude had no clue what he didn’t know!
To me the most ironic part was calling CRUDController clever in the first place. There could have been clever solutions to reduce the code repetition, but using inheritance to force a naive abstraction on every future programmer isn't it.
I don't know if it's because I'm reading HN more often these days instead of spacing it out but there's definitely a sizeable quantity of "<hard statement title>" followed by "so short it seems from twitter" article which really provides little insight or is absolutely misguided.
I guess the debate is instructional in itself and it's why the comments+article combo is the real power of HN.
It's not a clever-er solution? As an example, `php artisan make:controller` and potentially some custom derivatives is going to solve like 95% of what he was trying to abstract.
My understanding is that in this case, the code generator is merely a boilerplate generator that isn’t meant to keep the code in sync, but just do the initial copy/paste work.
I think code generators are a perfectly acceptable solution in cases like this, when the starting point all looks the same, and it needs to diverge from there. Especially if the generation logic is fairly straightforward.
There are a lot of IDEs that have boilerplate generators out of the box.
This is sometimes also called scaffolding, which I think is a better term. Code generation often means (compile-time or otherwise) generation of code from something else (like .proto definitions). Code that is not supposed to be modified by the developer and will be overwritten automatically.
Well if we're being anal about the metaphor, in construction and renovation, the scaffolding eventually goes away. Scaffolded code rarely disappears entirely; some of it usually sticks around.
It’s a little ambiguous with Entity Framework. There is no rule that says you cannot change the resulting code. If you want to continue with Code First, that is a totally valid approach, there’s even a subsection on that.
So much about programming in a larger sense is just getting abstractions correct. Too loose and they don't standardize/remove enough boilerplate. Too strict and they break or multiply when changes are needed.
I am curious, since my own backend experience is limited (obviously there will be many opinions on this) but it seems to me like his mistake was using the inheritance of classes.
If he had simply had a CRUD layer - that only standardized the actions of creating, removing, updating, or deleting a record (or records) from a database. This would accomplish standardizing the payload, as well as possibly doing an RBAC/Authorization check.
He could have just written individual controllers that invoke that layer with custom business logic. He would even have more space to add comments indicating why the business logic is implemented this way. When someone needed to make a change, they could just go straight to the specific controller.
Putting the impracticality of having to override specific methods aside, isn't it also a waste to instantiate a class full of methods that essentially do the same thing when you can just point to existing ones? Well I guess it is pointing to existing ones via inheritance, but it seems harder to reason about. But this is coming from someone who doesn't write traditional object oriented code very often.
Genuinely curious to hear from backend people about this, it's not my area of expertise but I've learned a lot this year.
In my view, there's duplication that could use an abstraction and duplication that is merely coincidental. (See The Wrong Abstraction by Sandi Metz [1])
Unless something screams "this should be the single source of truth about this" forget abstracting all together and just copy and move on.
The problem with trying to create 1 "CRUD controller" is that there are always going to be hairy things that make parts one offs. Perhaps someone needs to add location headers because the underlying calculation takes too long. Perhaps they want custom status codes when things go wrong. Maybe they need to use web sockets or server sent events. As soon as any sort of needed customization comes into play you start finding yourself closer and closer to the framework you are likely using until you reach a point of "Why am I trying to wrap the entire framework? Why can't I use it directly?"
And if you've made the mistake of pulling that abstraction into a library, heaven help you when you need to update things. What happens if the underlying framework library makes a breaking change? Or if you need to make a breaking change to support some feature? It all gets really messy really fast and now instead of just impacting the 1 application you are impacting 100.
Updating shared code is never as easy as you might think.
But, on the flip side, I can't think of anything easier, even if it's mostly boiler plate, than writing a controller that calls some business logic that works with a DB. Regardless the language or framework. The hard part of such applications is always the business logic and not the actual controller wiring.
Thank you for that link, I've never heard that but it's definitely going to be one of the new things I meditate on quite a bit. Especially combined with the concept of all "all abstractions are leaky"
If you're designing a backend service that has multiple "heads" - say, a web application and a mobile application. Then it makes sense that service should be code that manipulates the database(s) via business logic, and at the very least should be in one place.
But broadly, programmers do see value in abstracting interacting with the DB at least somewhat. It's why ORMs exist.
I don't know if there's a real answer. An abstraction can be right for a while and then become wrong when you add a new requirement right? So is it pointless to use abstractions at all? That definitely feels like the wrong takeaway. I guess instead, it's don't immediately abstract out anything that feels abstractable when writing new code and don't feel obliged to use existing abstractions in a codebase until you're sure they fit what you're doing.
> I don't know if there's a real answer. An abstraction can be right for a while and then become wrong when you add a new requirement right? So is it pointless to use abstractions at all? That definitely feels like the wrong takeaway. I guess instead, it's don't immediately abstract out anything that feels abstractable when writing new code and don't feel obliged to use existing abstractions in a codebase until you're sure they fit what you're doing.
The real answer is that, as much as some would like it to be otherwise, there aren't hard and fast rules in programming. Determining when it makes sense to abstract and when it doesn't is ultimately something that will be guided by experience.
That said, DRY is dangerous. It's to easy to blindly follow and has disastrous effects when the wrong abstractions get made. It's far better to duplicate first and DRY when it becomes a pain.
Generating code is fine, if the generated code strictly never evolves independently of what it is generated from. For instance generating libraries from .proto files (or other declarative schema definition solutions) works really well. If the schema changes, you throw away the old generated code and generate brand new code, no problem.
But if you want to make even a single tiny modification to one of the generated files, you're busted, you need a different solution.
Generated code is fine if it's newly generated on every build. If you're going to have to maintain the generated code, it's not generated code anymore, but duplicated code.
Seconded. How many in this thread have found generated code in source control? My trophy case includes artifacts produced by: flex, bison, gperf, swig, and one particularly nasty CORBA stub generator.
The original article isn't very convincing though. I mean, I fully believe the single abstract super controller was a bad idea, but there are far better options than that and duplicate code. He's just comparing two of the worst ways to do it.
> But if you want to make even a single tiny modification to one of the generated files, you're busted, you need a different solution.
Not totally true, if you can robustly express your tiny change as a `sed` or `awk` script, you can just append to the generator pipeline. Speaking from experience, do not condone, etc.
I think GP means "make a tiny change [after generation, outside of the generator, and persist that change independent of the generator code]", which is where all the demons are waiting
Modifying the generator itself to do something different every time, and doing GP's stated "regenerate and throw away the old stuff" is in line
It's not modifying the generator. The generator may be a proprietary black box. It's wrapping the generator in a bash script that pipes the result through AWK, etc.
As other commenters have noted, if the awk script is just a pure function of the output of the black-box generator to a new output, then I would consider this a modification to the generator, and no problemo.
However, if your awk script requires the current state of the generated code as input in addition to the output of the black-box generator, and tries to reconcile a diff between the two things, then yep, I consider that busted.
Sure, that's orthogonal. If you wrap the generator in your build system and still always regenerate, it's effectively the same. And also, I think, not what GP was talking about
Pedantic. There's a world of difference between grokking a new code generation DSL+codebase and a shell one-liner that fixes a string that is obviously invalid.
Since the issue is the maintenance of such systems, it is absolutely relevant.
> For instance generating libraries from .proto files (or other declarative schema definition solutions) works really well.
...does it ? Generated ones always feel being mismatched with the language paradigms. Maybe that's just my nightmares of dealing with MS Graph generated vomit hose of a library...
Sure, that's true, I'm a heavy user of the standard protobuf library in python, and you certainly won't catch me singing its praises for its style.
But that's a different (and less important) kind of problem. It does not exhibit the huge issue with generated-and-then-modified code where you have to maintain all the generated code rather than just the source from which it was generated.
It's trading wasting time by few developers manually writing client, for wasting time of tens of thousands of developers that use said client that doesn't fit language well.
Ha, yeah, though I would say that the lisp solution has a different downside: it's really nice to be able to see what the post-generation code all looks like. None of lisps I've used have made that as easy for their macro expansions as I would like.
There was an editor (for cmucl maybe?) that would macroexpand in a tooltip on hover and macroexpand-1 on right click (or maybe the opposite) on an s-expression. I'm surprised something like that didn't make it into slime, though you can I think macroexpand to the minibuffer. But, yeah, that's why it rewards doing macros in small pieces.
I absolutely prefer code generation over macros. It is a general solution that works for all languages, databases, protocols etc. And you can easily inspect the code generated.
Why would you want to do that? That would be adding unnecessary compile time overhead. And (again) code generation works for any language/framework/OS/… Not just for Lisp.
Code generation isn't well defined other than it's a calculation in which the end product is a certain language. The input could be any format and the transformation could be anything.
Macro processing is one way to constrain and refine the concept of code generation, in a particular direction.
Arbitrary code generating programs have the problem that they don't play along. Alice has a code generator and so does Bob. Both of these generate the same language. Alice and Bob want to work on the same files of the same project, each using their code generator. The only way it can work is if their code generators recognize only certain delineated syntax and pass everything else through, so that Alice's code generator can be applied first to code that also needs Bob's generator or vice versa. Suppose Bob uses his generator in such a way that Alice syntax comes out of a construct. If the Alice generator has run first, that won't work. Running both generators repeatedly, until a fixed point is reached, might work. This will likely not scale nicely beyond a small number of code generators.
If Alice's and Bob's code generation are only doing text substitution, it would be a lot better if Alice and Bob used a common textual preprocessor and wrote their respective parts as macros. Then their work integrates and is expanded by a single application of the tool, and any number of team members can write macros independently.
It depends on the preprocesor.
Recently, I converted a C-preprocessed file into code generation.
C macros don't have good tooling. They are not supported well under debugging, and even basic text navigation tools don't work well with them. Vim with tags will jump to the macro definition, but not to the definition of a function defined with a macro.
No. I'm not gonna sit there writing another tool to augment ctags so that the editor will know that sha256_init is written by the chksum_impl(sha256, SHA256_t, "SHA-256", SHA256_DIGEST_LENGTH, HA256_init, SHA256_update, SHA256_final); macro call, and jump to that line.
So the switch isn't motivated by a philosophical position on macros versus code gen, but by the concrete specifics of the state of the tooling, and the nature of the desired transformation. (E.g. are we generating large boilerplate spanning multiple functions? Or are we making syntactic sugar for walking over a list?)
This is a Lisp project; I'm not macro ignorant.
Other Lisp people have used code generation at the implementation level. The CLISP project dates back to the late 1980's, long before there was C99. Many of the C sources have .d suffixes, and are preprocessed by a script called "varbrace", which turns mixed declarations and statements into C90: statements before declarations (by emitting brace-enclosed blocks). E.g. puts("hello"); int foo = 42; becomes puts("hello"); { int foo = 42; ... }. There is no way you could do that with C macros, in any way that would be remotely reasonable, and not stray so far from the objective as to be comical.
Code generation is never off the table when we deal with languages that don't have good macros. But new language should be making provisions so that users don't have to resort to it. When language users resort to code gen, that's a sign that the language has failed in some way.
E.g. C failed for Bjarne Stroustrup by not providing support for OOP, or good enough macros to do it nicely, so he wrote a "C with Classes" code generator. Not everyone agrees; plenty still use "C without Classes" forty years later.
The funny thing is the last thing I did code generation for just generated classes which inherited abstract base classes. Then we had to inherit the generated code to extend it. It massively increased the complexity.
Then someone came along and invented partial classes in C# which made this problem go away. Well it would if anyone wanted to do all the maintenance legwork which they didn't so half of it's a 5 class inheritance tree, some of it's partial classes and someone got really fed up with this shit and just arbitrarily stuffed Dapper in there one afternoon.
I think one lesson newer programmers fail is that sometimes copy/paste is not only OK, but preferred.
One time this is good is when helping others get up to speed. Other people can copy/paste your examples and be functioning right now.
But if you have a function that you put in to eliminate some duplication, they have to understand this new abstraction layer before they can start working.
One good thing with a code generation approach is that we can actually inspect into the generated code and see what's going to happen in a relatively easier way. And it's usually working nicely with static analysis. For abstract base class or whatever, it's kind of hard to do.
Of course, code generator (or even compiler) is harder to maintain, especially when you want the output to be human readable. So it's always about trade-off. Think about how many lines of code it's going to generate. If it's an order of 100k then it's usually worth the cost. 10k might be good to go. 1k, probably not.
Code generators can work if you .gitignore the target folders, so everything generated must be used as-is or augmented by a separate handwritten file like a subclass. And to integrate them tightly into your build process so the generator tool runs transparently.
But even then they're a nightmare because your errors don't match your source files.
"generate and edit" is suicide. "generate and treat the outputs as intermediate compilation objects" is merely an incredibly painful tool of last resort.
Yeah surely a better approach is... rather than inheriting from an all powerful class, just compose controllers out of modules. Some used in almost every controller. Some pretty specific to one or two edge cases.
Like the problem was having an all-or-nothing inheritance model for shared functionality, which also ended up very long and intimidating.
I also don't really understand why emerging edge cases caused him to complicate his 90%-perfect parent class instead of just... overriding specific functions in the children. (The specifics of these overrides will probably make you want to refactor your parent class so that the overrides have clean joints but you shouldn't just dump the new child-specific logic into your parent)
IMHO, I don’t think there are enough code generators, however, a good code generator’s output should be a library, not editable source. I’ve had a lot of good experience using IDLs that could generate libraries for multiple languages that other code could be used with (e.g. define your REST url scheme and supported operations and a base class that gets generated that allows filling in logic).
At least in Java world, annotation seemed to have taken over, but the mixture of code and interface definition kicks you into the language and allows too much flexibility that really make it no different than writing registration code. Having a nice declarative language without business logic sneaking in.
This whole article is about whether to do or not, and I dig the lesson here. The author built on monstrosity they hate, and they propose perhaps creating another. How bold & brave!
Of course lots and lots of people love telling us why not to do things. This is the cosmic-brain point of Steve Yegge's "Notes from the Mystery Machine Bus", of what we let guide us. Is it trying and hope and doing? When and where do we allow reservation in? https://gist.github.com/cornchz/3313150
I use code generators all the time and it has saved me a huge amount of work. I routinely generate 80% of the code needed to implement typical business applications.
Having said that, code generators are not all the same. Some are awesome, others are downright awful. There is an art to writing good code generators. Not surprising really. The same can be said for most other software.
Is that what he's talking about? I thought he was talking about some pattern using first class classes rather than ever programmatically touching source?
"Write code that writes code" -- Tip 29, The Pragmatic Programmer[1]
I think we need to be a little more nuanced, here.
Don't be clever in your code generation, to be sure. But let's not act like you need advanced degrees for all meta-programming.
What do you think phased compilers do? They generally transform the AST produced by your code into expanded versions or rewrites of that AST that are more amenable to machine interpretation or transformation into assembly.
In a very real sense, nearly all production code goes through some kind of codegen process. It isn't clever, it isn't new, it generally isn't complicated (if this then that else that else ... when you get down to it). It is repeatable and reproducible and reliable enough method that the whole economic system of software is built on top of it. Most of the problems come with recursive applications of codegen and strange interactions between different subsystems of codegen.
Here's a tip: Don't do recursive codegen in your user land metaprogramming.
User code is _easier_, simply because it isn't as reusable as the language primitives themselves. But if you understand a problem well enough to essentially reduce it to copy, paste, and replace one or two items, codegen is superior because a bug fix during maintenance need only happen in a single place.
My primary language recently added generic derivation to the language itself (as opposed to in macro libraries) and it is totally worth it as I almost never have to write a ser/de by hand. I never have to test the ser/de round trip. I don't have to pepper my code with second-class annotation primitives or keywords. I never misspell `asJson`, etc.
Not everything should be done with codegen in user land code (code outside the compiler and language tooling). But if I see thousands of lines of json/avro/protobuf/test example copypasta, that's a code smell that needs to be addressed or it will lead to production bugs and take hours instead of minutes to fix.
And when you write these things, you come to find out that they are just like any other data transformation task. They turn `A`s into `B`s, systematically.
My mentor, when I became a professional coder, taught me that if you do something more than three times, its probably worth taking the time to generalize it and do it once before you push the changes into the version repository. It's been 18 years now since I began my career, and that simple principle has rarely steered me wrong across probably a dozen languages that I've written production code in.
I have swung both ways and I think I now settle somewhere near "boring is good" and "repetition is harmless (compared to the astronomic costs of wrong abstraction)".
Especially repetition seems to be hated with the might of a thousand suns and while I get it, because I myself hated it, I now can see the beauty of it.
What is currently a superficial repetition - a bunch of endpoint handlers, some forms - will often turn out to be similar-looking instances of completely different problems. Repetition is quite often deeper than just "code looks the same".
I've seen my share of cases where the repetition was only because the original author didn't know how to abstract the problem say, using a simple struct. Or even easier, a simple function.
I've sometimes taken on factoring the repeated code using common abstractions, and when that was done it often turned out that there was much more to factor out. And that the code quality could massively be improved because there are often some tricky situations that can only be properly handled when everything goes through a single place with all the necessary context.
As an example, we had a config file with an ini-like structure that was parsed by some central parser code. So far, so good, but after the parse, the resulting key-value pairs were processed like this:
if (string_is_equal(config_key, "foo_setting"))
config->foo = parse_number(config_value);
else if (string_is_equal(config_key, "bar_setting"))
config->bar = parse_string(config_value);
Repeating this pattern dozens of times is decidedly not cool. It lacks expression of the common structure, it imposes and prevents code optimizations and fixes (such as error handling).
Sometimes I was told that abstraction isn't worth the hassle and boring and repetitive is good. By factoring the code allegedly we risk breaking it and make it harder to fix. Those people didn't see how broken and incomplete the code is precisely because there is a lack of abstraction. We can't even know that there isn't some "quux_setting" with broken handling code because of course there aren't proper tests for each config setting or combination of settings.
If it can be abstracted, often the abstraction can have unit tests. That's my goal, it is not just about avoiding boilerplate and repetition, it is that boilerplate and repetition are more surface area for errors.
I hate repetition because it's nearly always laziness - it takes less thought/time to copy and paste a few lines of code than it does to factor them out into a reusable function and decide where to put it (and with what name). I'm taking about scenarios where the business logic needs to be exactly the same in both cases, there just happens to multiple ways to reach that point.
On the other hand I also hate having to deal with shared functions that have been repeatedly adapted and extended to be able to deal with all the various edge cases to the point they have 20 cryptically named parameters and no reasonable way of guessing what the output should be for given set of inputs.
But I'd still say more of my time is used up dealing with problems caused by lazy copying & pasting than by shared functions becoming overcomplicated or buried under excessive layers of abstraction.
> I'm taking about scenarios where the business logic needs to be exactly the same in both cases, there just happens to multiple ways to reach that point.
I've seen lots of these cases turn out to be "the business logic happens to be exactly the same in both cases".
It might have been a single feature at one point where it should have been identical, but two flows going there in two different ways means it's serving two masters. Often it will diverge as the product grows and those flows become their own features with differing requirements.
---
And also - "it takes less thought/time to copy and paste a few lines of code than it does to factor them out into a reusable function and decide where to put it (and with what name)."
Yes, that's the point. It takes both less time and thought, and it often diverges anyways. You are wasting time and creating complexity.
But the divergence is more often than not unintended and causes inconsistent/ unexpected behaviour when a change is made in one copy and not the other, which is why it ends up using up more time in the end.
And how is extracting a few lines of code into a function and calling that more complexity than having two identical copies of it?
When the divergence comes from subtle differences in requirements, then those subtle differences in requirements now need to baked into your single function (or, really, broken out from the function; but they have to be recognized as different to begin with). Now, the next time you need to address a new feature along one pathway, you must also be certain that you are not subtly breaking some completely unrelated feature requirement.
If the function grows like you describe it's because the developers are doing bad work. Instead of extending the function into a monster it should be split appropriately according to the new requirements. In some cases it may end up being multiple classes and that's fine. What isn't fine is cramming multiple classes worth of complexity into one function just because it almost did what you needed.
Indeed...laziness in both cases! I certainly admit I've been guilty of "ooh this function already exists to do this, except in this case I need to tweak it slighty, so I'll just add another parameter" - which is usually OK the first or second time: the issue is when it sets in motion a pattern of behaviour that other devs keep following without stopping to question "has this function grown too complicated", or worse "I know this needs refactoring, but we need this bug fix in now, I'll create a tech debt ticket and come back to it later", but of course never do.
Laziness is good though. If repetition requires less work for the same outcome, that's good. If abstraction or automation of some kind (like codegen) requires less work, then that's good.
But the question is, "less work over what time scale?". Repetition usually requires less work over short time scales but often requires more work over longer ones. But not always! I see people abstracting and automating things in throwaway scripts, tools, and PoCs. That is a waste of time.
Yes definitely. But the point is that you have to ask yourself what timescale matters. It isn't always "optimize for the long term" and it isn't always "optimize for the short term". It really depends on what you're up to.
There are also valid use cases for preferring boring repetition.
Most of the time when I do any kind of coding work, it's as a single person project for companies/orgs with absolutely zero tech people. For instance, the last project I took on was for a bra shop of 3 people. No IT. Nobody on staff who has any idea how anything tech works - the closest is the person who taught herself the basics of using Shopify + advertising platforms.
Which means that in the future if they need somebody to look at or update anything I've done, I can't assume they're going to have access to a well-trained, talented person - it's equally likely they'd go "hey so and so's kid does 'computer stuff' let's see if they can fix it for us." Knowing that the next person who looks at my work might have very basic level skills leads me to prefer being repetitive and 'simple' over the more efficient solutions I can think of.
It's the difference between a regular Wikipedia article and the Simple English Wikipedia - if I'm writing something that is likely to be maintained by beginners or apprentices, making it easy to understand and work with matters a lot more.
I have what I call the "10 second rule". The rule is that an experienced programmer (ie. someone who has written the type of code your codebase is written in, whether Python, JS, etc) should be able to look at a code snippet, any code snippet in your code, and figure out what it does in about 10 seconds. There are obviously exceptions to this where complexity can't be avoided but overall I found the tradeoff is worth it especially on a team of multiple devs.
I currently work for a client that has a very very large react native app that is pretty hard to wrap your head around. I can't tell you how many millions of dollars they have wasted in dev hours because it takes a dev way to long to even figure out what the code is doing before they can start making changes.
I always try to imagine that I'm coding for other people rather than coding for myself. This helps me to remember to make the code as easy to understand as possible.
I like your "10 second rule"! I have a slightly modified version, the "look, a fly" rule. If I can lose focus for a bit and return to the function without being confused, it's probably good!
I thought about this a while and concluded that the right question is whether the repetitions are intended to do the same thing. If they are, deduplicate them. If not, leave them alone to evolve independently.
I feel the same way. Repetition is fine when you're working within a solid, well established framework. If you're writing 100s of GET endpoints, and most of them requires you to prefix your endpoints withs some @GET and @RequriesToken decorators, so be it.
If there are other forms of repetition within the user-code, there are ways of dealing with it. But writing a super class to solve superficial code repetition is most often the wrong way to go.
I've come to the same conclusion as you. Code is typically read more times than it is written/modified, so it is better to optimise for the common case, i.e. code that is tedious to write but simple to read and follow.
At a consulting gig I did, we were bootstrapping a brand new python engineering team for a new line of products. We chose the frameworks, set standards via decision records, wrote a template service that you would copy paste, and build on top. Cross cutting concerns were pulled out into a library that all of these services installed. Most things were standardized, all APIs felt like they were written by a single person, and yet little was abstracted. It was simple and beautiful. An engineer would come onboard, look at one repo and be able to navigate all service repos going forward. You could see and feel the repetition, aside for the business logic, it was like reading the same book over and over again. The team was delivering at a crazy velocity.
Then a year or so later the client brings us back in to help diagnose and fix why their delivery dates continue slipping and number of bugs in production is increasing. Finds out a new, very vocal hire, came in, saw the repetition and decided to build a "service service". A service, into which you would pass a single python file of pure business logic encoded as a b64 string, with some decorators, and it would set up the endpoints, serialization, DB, etc automagically.
If you feel confident refactoring some code then you have been able to read and understand it easily. If you can read and understand it easily then it’s good code, leave it alone.
If the code is confusing then absolutely refactor it.
There’s 3 levels of understanding DRY
1 programmer is unaware of DRY
2 programmer sees how much simpler code is when you reduce duplication
3 programmer sees how DRY can sometimes cause it’s own problems.
A good clue is that if the cyclomatic complexity of the system goes up when you DRY then you shouldn’t DRY. For example if the new single method is now full of if statements then you’re creating problems.
Another clue is if you’ve just coupled things that shouldn’t be coupled.
Low cyclomatic complexity and coupling of components is much much more important than having a DRY code base.
There are cases where doing the "same" work twice is sufficient, preferred even...
Somehow some colleagues found it absurd to parse some code twice, but don't see the insanity of parsing code, getting an AST, serializing, sending it, and then deserializing correctly.
Never mind the fact that the serialized AST is 250x larger, and deserializing arbitrary constructs without codegen is a whole different can of worms, and especially harder when the code is running in 2 different programming languages.
First time I've heard this, I love it. Definitely resonates both as the one who is there first, and then future ambitious folks would rather rebuild than understand and extend. Also, relatable when I come in somewhere and immediately start thinking about how I would re-build something instead of improving it. We sure have a lot of hubris in software, don't we?
If you're looking at a giraffe's laryngeal nerve[0], you see it making a circuit from the jaw, down the loooong neck, to the chest, back up the loooong neck, and to the jaw again. It's like this because it used to be an small, innocent "u" shape back before giraffes evolved long necks. As their necks elongated, there was never any effort to rewire the nerve, so it elongated too.
When encountering that situation, the correct urge is to rebuild against current circumstances.
From why you've said it sounds like maybe the issue was really how they factored out the common code (Python loading base64 encoded Python is clearly insane) rather than the fact that they did.
It's difficult to draw conclusions from these sorts of things though because the answer is "sometimes you should copy and paste a bit, sometimes you shouldn't" and you just have to have skill and taste to know the difference.
I really dislike when someone considers my code "clever" because it always means they don't approve of it or think it's too confusing. No, I wasn't trying to be clever, but to create the most appropriate solution I could imagine.
The author's problem isn't being overly clever, but that they had applied an inappropriate yet imtellectually-satisfying programming pattern that is notorious for being difficult to make exceptions for. The quote about the correct solution being a "class generator" shows that the author misdiagnosed their problem. If you continue down the path of making everything a class, you're gonna have a worse one than if you made most of your functionality into compostable functions, reserving classes for things that truly deserve it.
So many issues in programming would be diminished if programmers toned down the thinginess of their code, focusing more on procedures and data shapes.
Making things worse, I suspect there's at least two (and probably more) definitions for 'clever' that are thrown around and the intent half the time is that one definition is masquerading as the other.
One plausible definition for clever code is that it's code that only works because of a non-obvious dependency on some other fact being true in the code base or outside of the code base. Once the fact is no longer true the code will be broken or subtly broken (or it will break or subtly break other code). "Ah ha, very clever, but we shouldn't do this."
Another plausible definition is approximately, "I don't understand the feature or pattern you're using, and I don't want to understand it or form a coherent argument against it."
The other option is "yes this works well and is very neat, but it's not going to withstand 5 years of people changing it and only reviewing the diffs."
Does anything withstand that? I don't think that's the responsibility of the original author, I think it is the responsibilities of all those devs and reviewers to make sure changes make sense and don't make the system worse.
Nothing can stop morons from ruining good code. Good devs will evolve code into something that makes more sense.
The only code that probably does withstand it is code that does its job so thoroughly from its inception that there becomes no reason for someone to frequently make changes to it. I know such code exists because I definitely have run into code in popular repos that hasn't been touched in 10+ years. This is not exactly the norm though, particularly within web development, it seems. The more developers and reviewers you introduce to a unit of code, the more chaos you introduce, and said code is liable to losing comprehension until a major rewrite is performed.
> So many issues in programming would be diminished if programmers toned down the thinginess of their code, focusing more on procedures and data shapes.
Exactly my reaction too. The code is complicated and requires boilerplate because it tries to adhere to a pattern that doesn't need to exist.
Whenever something becomes entangled and complex, decompose it into pieces first (functions and data) and then put it together again, piece by piece. The right abstractions (if needed) emerge naturally from simple code.
I wouldn't object so much to "complex" because there may be a much simpler way to writing my code. What I don't like about "clever" is that it's always a shit-sandwich that comes off as misrepresenting my intentions. I never write code with the intent of impressing myself or anyone else; my only interest is in writing minimal code that is maintainable and as easy to understand as possible. If my code doesn't achieve that, just tell me without patting me on the head by telling me I was trying to be clever.
It's the focus on "minimal" that sometimes gets called "clever".
Some that I've found in actual code
Using ternary operators everywhere instead of if-else just because it's a few characters less, mixing them in the middle of already complex function calls so that it takes a less clever coder hours to untangle when there's an issue.
Creating your own classes for storage, the best of which was a custom from-scratch implementation of a Vector, but it kept the 3 largest items in the first three cells. It was 100% API compatible with Vector and no part of the API gave any hint of the weird sorting mechanic.
Fluent APIs. Just don't. They look pretty when written, but are a complete horror show to debug.
> Using ternary operators everywhere instead of if-else just because it's a few characters less
This isn't a fair assumption to make. One good reason to prefer ternaries over if-elses in languages which lack if-else expressions (and only have if-else statements) is that ternaries guarantee that you'll get a value for each branch, and with static typing you'll even know what type that value will be, whereas each branch of an if-else tree might do anything, is usually forced to rely on mutation to accomplish its job, and has no statically enforced guarantee of producing the value that you want.
The fact that ternaries are terser is irrelevant. Some modern languages, like rust, have avoided copying this awkward if-else-ternary dichotomy by providing if-else expressions, which is the perfect solution to this particular situation.
I am also honestly a bit concerned over how many developers consider ternaries hard to read. They're one of the most basic constructs of most of the popular languages out there, not some advanced corner case where it might be understandable to struggle with them.
They probably consider them hard to read because people overdo it with multiple nested layers of them when they don't need to, and tools like prettier often format them in completely moronic ways that obfuscate the original dev's intention.
Larry Wall said something like "if you have a complex problem, the complexity will come up somewhere -- either you have a complex language and a simple program, or a simple language and a complex problem. The complexity can't be wished away." Being Larry, he said it far better but I can't find the exact quote.
All programming is making models: representing a chaotic and changing analog world in bits, data structures, and algorithms. For every model there's something that breaks that model. Attempting to incorporate every exception into your model leads you to the path of tuples + a workflow engine, and at that point all you've done is build a different database and programming language and move the complexity further up the stack.
As requirements change, the model you built will no longer prove appropriate because now you're modeling different situations. There's an art to building a model that doesn't box you in to the point where the first change request doesn't break your model. But at some point, every model is going to be inadequate.
A senior programmer brings to this: knowing the common ways things change, the costs of changing different types of model, and the understanding that there's no such thing as Perfect so don't proclaim your framework to be such.
So many times I've had people regurgitate this blog post[1], or KISS, or some other general piece of advice to "keep things simple" and it just means they want to influence the shell game of managing complexity so the complexity is someone else's problem--and they can stop thinking about it. I've come to really hate when someone pulls this out as some general principle, because it so frequently means they want to push complexity from an implementation (which maybe has a hope of hiding some of the complexity) out into callers or configurations or some other kind of leaf, where it becomes a breeding ground for manually synchronized configurations, copy-and-paste code promotion (not reuse, which is bad enough, but the pattern where some thing that you're forcing people to manually compile or explode has to be copy-and-modified through an artifact promotion.
Frankly, KISS and its ilk have become more often "things uninsightful people say to make them sound clever and vaguely iconoclastic" than something that can be actually useful as guidance: because people think they remove nuance rather than adding it (KISS is great if you honor its nuances like "and no simpler..." and "considered as a whole"; but instead it's a thought-terminating cliché). I've heard people use these sound bites to justify, e.g., the entire notion of automated testing (too complicated), or "infrastructure as code"--though I also dislike this term and favor "software-defined infrastructure", though maybe if it became popular, objections that software-defined infrastructure isn't really software would become as common as objections that infrastructure-as-code isn't really code.
-----
[1] I don't mean this literal blog post, I mean the same kinds of "don't be too clever" platitudes.
Very well put. Effective businesses are good at communicating and sharing these models so everyone is able to reason about them, and if they’re lucky anticipate future articulation points.
I think these stories and aversion to "clever" code end up hurting programmers overall. I wish we spent more time teaching how to choose the correct time and place to be clever instead. Searching for ways to make things better instead of mindlessly copy pasting how it was done by the person before me is how I learned my most valuable skills.
It doesn't help that we don't have a good definition for what 'clever' means when referring to code.
This article talks about a time someone made an abstract class and then took DRY a little too far. If this is an example of 'being clever' then anyone using map instead of writing a for-loop would have to be at gaussian levels of cleverness.
[Also a class generator is implied to be less clever than an abstract class ... I'm not sure I can accept the usage of 'clever' in the article as meaningful.]
A new pattern may seem "clever" or "difficult" if you haven't encountered it before; but if you spend time with it and work with it, it can look like the most natural thing in the world.
I am not sure if teaching this skill would help or is possible.
But I do agree with the direction of your thought. The reading material at least needs to be inherently balanced rather than writing itself getting balanced out by 50% of articles talking about "Using proxies to prevent null pointer errors"(guilty of writing this) and the other half being "Maybe proxies are a bad idea".
Code was devised to address a specific problem (DRY), which it did quite elegantly. Then, the situation evolved, rendering the solution inappropriate. When a controller starts to deviate from the standard approach, it's best to refrain from inheriting from the base controller and instead create custom ones. Once all controllers operate independently, the base class can be safely removed.
The key lesson here is not to avoid cleverness but to be aware of when the initial problem becomes obsolete.
If there is no process for re-evaluating code architecture choices, it can create challenges regardless of the approach taken.
Experience tells me that relying on copy+paste as a solution isn't a cure-all, or even a better approach, and often introduces new problems in the future. A thoughtful and adaptive approach to code development is crucial to ensure long-term success and maintainability.
What about making all of the "clever" things composable and optional, instead of tightly coupled? That way when you get a special case you can just make that part a special handler. You neither need to throw out the whole "clever" thing nor make the "clever" thing "more clever".
My first lesson around this was in manufacturing. It has stuck with me much more strongly than any sort of software industry jargon. It is an incredibly simple phrase too: "Value-add".
I just stay focused on that item. "Is my proposal/refactor/shiny thing going to make a customer want to spend more money, sign additional/longer contracts, or somehow smooth out support & operations?"
If I get an "ehhh im not sure" or a more honest "no", then I'd be inclined to shitcan the proposal unless a very clear argument can be put forth for why this refactor will somehow eventually result in downstream value-add.
Arguments along the axis of "because its the right thing to do", "this is the technical best practice" or "it's cool to look at" are rejected by default unless additional supporting evidence can be brought forth. Proposals that bring additional vendors & operational liabilities without also bringing obvious value are to be considered malicious suggestions.
This probably sounds draconian as hell to some of HN, but if you are working with truly complex software, you cannot be playing games in traffic, especially if you are already in production for many customers and under half-decade-long contracts.
The time to be clever is on your side projects. Do not conflate the thing that results in your paycheck with entertainment. It might seem like there could be some happy co-existence, but I've personally never seen it work out.
I love best practices, and I'm even a fan of cargo cult development to a certain degree, staying with what's tested, reducing novelty, making things repeatable and declarative, choosing a million line framework over 1000 I'm house lines.... But it's not worth trying to maintain your own Ansible in your own custom language with a GUI in your own GUI toolkit, just to avoid some ugly hacks and workarounds you'd need if you just used the popular tool.
Apparently the author hasn't learned the most important lesson: Think thrice before you use OO. And if you do, keep your hierarchies flat and simple. Prefer composition over inheritance. Make invalid states unrepresentable.
I once worked in a role where my boss made me rework commits that were too DRY. I had to completely decouple features that were early in development, then reopen the PR. I thought it was excessive and pointless at the time, but I've seen enough stories like these to get it now.
1. Make sure there's always a trap-door where you can implement special cases
2. A good way to always have (or to create) a trap door is to compose out of smaller pieces; then if you need something to be different in one case you just "reassemble it" with pieces added, removed, or rearranged
In the author's case, maybe CRUDController's key pillars of functionality could be broken out, still bundled together as CRUDController for normal cases, but then for special cases they could just assemble custom solutions out of those pieces instead of bending CRUDController into shape
Not disagreeing with the core assertion in this post because I think the author is correct that you can absolutely over-engineer things. But one thing I don't quite understand.
> Some controllers had to do some things a little differently.
....
> And young me? I just kept going. Adding the proverbial knobs and pulls to my abstract class
Aren't the ways in which the concrete implementations vary supposed to be in the subclasses? One of the points of the abstract base class is to encapsulate common behavior. For things that differ, those belong in the concrete implementations. So _one_ of the mistakes here was to try to write a god class that could anticipate all of the ways in which the subclasses differ and to encode those into the abstract class in order to leave the subclasses as simple as having to specify the entity type.
I think the point of the author was that as a young - implied: inexperienced - developer he was blinded by the power of being able to describe the world in code; and inadvertently got stuck in the rabbit hole.
Learning to take a step back and discern the best fitting abstractions that allow modeling the business domain is a learned skill. There's a difference between learning about object inheritance in school, and actually applying it in big projects where the effects only become apparent over the course of months.
For sure. I meant to say that was _one_ of the points the author was making. You're absolutely right about what the core sentiment/point of the post was.
To expand on the article from my personal experience, sometimes, there's a very thin line between "clever code" as in "overengineered", and "clever code" as in "I don't understand it, so I don't like it".
Imagine situation where a team of Java developers need to create a component in Python. No problem!
We come to the following code:
```
list_of_resources = method_a()
if not list_of_resources:
handle_empty_list()
```
Now, is the code above "clever", or not? As Java developers, you could get into arguments like "we should use `len(list_of_resources) == 0` instead" vs "it's not Pythonic and there's no reason to use len instead truth/falsey-ness".
Of course, the whole problem gets exacerbated by unit testing, where `list_of_resources` can be a MagicMock, and therefore `if not list_of_resources` will never trigger.
Of course, probably nobody will argue that the above snipped of code is overengineered. But, somehow, the same logic of "clever code bites you back" applies to more situations than just insane class hierarchies. And it's those very tiny fragments that seems so simple yet there are hidden issues that I find the most interesting to focus on.
> you could get into arguments like "we should use `len(list_of_resources) == 0` instead" vs "it's not Pythonic and there's no reason to use len instead truth/falsey-ness".
these kinds or arguments trigger me so badly i should probably talk to a therapist. I've been involved in a couple and it usually ends, rightly or wrongly, with me pulling rank and saying this is what it's going to be, this is what it's always going to be, move on to bigger things or gtfo of my team.
> the whole problem gets exacerbated by unit testing, where `list_of_resources` can be a MagicMock, and therefore `if not list_of_resources` will never trigger
Not a python or javascript programmer, but that alone already points at using `len` as a better (more testable) solution.
In my limited understanding of python, there's no type-checker that will shout if someone in another team changes method_a() to sometimes return a `None` or `False` in addition to a List. So even if in python empty lists are falsy, the code will be a bit more robust if it doesn't rely on that feature to begin with. The code will error on the if instead of continuing and trying to use a `None` in a place where a list is expected later on.
Disclaimer: I work with a language with only two falsy values (nil and false), so I might be biased
I have a softer rule for myself, which is "If you are going to be clever, make a (depends on the size of the abstraction): README, detailed API docs, possibly even a landing page. Specify behavior, write diagrams, explain what and why, document edge cases. Also, periodically have someone who's never seen it give honest feedback based on the docs only."
If that sounds like too much work, then its not worth it.
Yeah, like me (DevOps) writing our dev environment manager tool in Python when all the devs write nodejs. Then not being able to just ask them how to solve a problem in node, instead having to spend far longer figuring stuff out myself.
Good for learning, bad for velocity. Although I do know a buttload more Python now.
Yeah, clever! As my old man said, so sharp you cut yourself.
Some of them complain about regexes, and running commands in the terminal.
Recently one was blocked for a day because they didn't think to google "how to make a script executable".
Another one complained because their files weren't automatically copied to a new laptop. All on the macOS desktop directory of course.
One of those wanted me to set up an Emacs config with org-mode, and write instructions on how to use it. Thankfully their manager "had words" with them and they gave up on their quest. They had never used Emacs before, and hated the command line.
Oh and the enormous "fun" we have dealing with the staunchly windows/microsoft only developer who has to use a Mac. You'd think they were being asked to shoot children they way they carried on.
My most productive time working on DB applications was when I worked with a code generator.
You laid out the entry screens, specified the tables and columns, fired off the generator and magic happens.
You could slam out a basic maintenance CRUD screen, with search, foreign key popups in an hour!
But here’s the meat of if. If you ever needed to go back and update that program, you could do it in minutes.
Add some validation logic? Mechanically trivial. Say a column was added to the table and you just wanted to populate but not even show it on the screen. 5 minutes. If you wanted to add it to the screen the hard part was deciding where to put it, making room for it, putting it in the right focus order. But coding it? Once it was part of the screen the rest came for free.
See the trick was that unlike pretty much every other code generator I’ve seen (which I think are better termed wizards), this code generator was not a one shot deal.
Your code was in a separate file and the generator merged your changes with the generated code to create the final result. So for simple changes, your code file was quite small as the generator built up all the boiler plate around it.
A very (very) crude example is imagine using a typical one shot generator, making changes to the result, capturing those as a diff patch file, and in the future you did all your work in the patch file, applying it any time you needed to rerun the code generator.
That won’t work in practice, but when the patch files uses more semantic indicators, it does work. It worked really well.
This makes the code generator part and parcel to the workflow, and you get to leverage it again and again.
In many of these systems, and especially modern frameworks, they have a happy path that can do 80+% of the common task, but more often than not you hit that 81% mark and you have to toss the baby out with the bath water. Not only is the tooling not able to take you where you want to go, it can’t even take you partway and you’re on your own and your stuck with 100% of the work instead of the extra 20%.
I never really encountered that using this toolset. I had few examples where you should not rerun the generator any more, but it was really rare.
I agree that you should strive to not make "clever" code since it requires more cognition to parse later (and none of us have perfect memories). I try to strike a balance between reusable code that doesn't have 1 million flags/params to handle all the cases and writing straightforward code.
It's easy for developers to look at 2 components and see the overlap and a lot of, normally junior, developers go overly-DRY and the readability and usability suffers for it.
I'll take verbose over clever every day but at the same time I think this blog author goes a bit too far in assuming there was no use for a base class at all. I agree that the base class does not need to support every eventuality but a good base class would provide the base implementation with an easy way for subclasses to override the logic as needed. And no, tons of hooks probably aren't the way to do that either.
We have some code where I work that I wrote as a base implementation of some CRUD logic but it requires your implementation to create stubs for get/put/delete/iterate/etc that call the internal logic. I got some pushback on this because "I have to write this boilerplate when I just want a straight passthrough" but I'd seen this play out enough times to hold my ground and, while I'm biased of course, I think it's proven successful in the long term. At the start you might just need to do a straight pass-through but business logic always changes or evolves and while on day 1 you might not appreciate having to write "boilerplate" you will be thanking yourself 1 month, 6 months, 1 year down the line when you need to modfiy default flow. If a class never goes pass the "boilerplate" then great! But as soon as it does you'll be thankful for how easy it is to modify.
As always, when making "one-size-fits-all" statements, my answer is "It depends."
In many cases, I use inheritance and polymorphism, as well as extension, to make my code incredibly adaptable. It's basically habit.
It is not always so easy to scrutinize (even by Yours Truly), but I document it well, and the structure can sometimes make tasks that might take days, take minutes (This has happened many times in the project I'm working on, now).
A couple of weeks ago, one of the team needed a fairly large change to the operation of one of my screens. I was pretty reluctant, because it was one of those "Just one little change" things that actually translates to a massive codebase hit.
However, when I reviewed the code (which I hadn't touched in a while), I found that I had left some fairly good hooks in the base class, so it actually took about five minutes to give them what they wanted.
Right now, I'm working on two databases that almost do the same thing. One is legacy, the other is the new and improved. I can't delete the old one because there are several teams that generate their reports from it, I can't delete the new one because new functionality depends on it.
When we add a new feature, we run update queries on both databases (but not always). We need several months of work and create training for everyone to move to the new DB. The business does not recognize the work as valuable so we continue to do this dance.
How did we get here? Someone with great intentions thought "I hate this crappy mssql db, I'll create a new modern one". That person has left the company many years ago. This is now my real life example for "... now you have two problems"
I think this is because most literature focusses on exactly those things. Design patterns to be one step ahead of some obscure future usage of your API, FP patterns to abstract your API into a 'something' that you could not just use to aggregate customer account balances in the database but, say, merge arbitrary lists as well etc.
It's rare to find literature that tells you -not- to use new frameworks or design patterns, and if it exists, if probably doesn't sell very well because it's just not sexy.
Now I'm tempted to write that book, maybe it could work. Find examples of things people desire and write the simple 'common knowledge' rules to achieve it, acknowledging the role of bad/good luck.
Want to be healthy, in good shape? Get lots of sleep, eat well, exercise. Unless you suddenly get cancer.
Want to be rich? Work a steady, boring job that pays well and live below your means. Unless a financial disaster occurs and you lose all that money you saved up.
Honestly I think that would be a really interesting book! It could be case studies of people who were 100% invested in a "system," but found that they got just as good (or better) results from following common sense guidelines and not sticking to them too rigidly.
People often learn the wrong lessons from literature. Design patterns, for instance, are something you should learn, not as tools that you should eagerly find applications for, but rather as a shared understanding of the kinds of patterns that commonly occur in code, such that you have the right vocabulary to communicate about them with others, and such that you can easily recognize them when they occur in the code. You'll almost inevitably utilize various design patterns extensively in your code even if you've never heard of "design patterns", learning about them simply lets you understand what's happening.
I don't think this particular person would have learned the lesson.
> Yes, I had failed to see the proper solution: a class generator — so that I didn't have to manually copy code again. It actually existed back then, I simply didn't know about it, no one told me about it, and I wasn't smart enough to question myself once I started going down a certain path.
I shudder for the next gig where they get to apply ^
> Yes, I had failed to see the proper solution… It actually existed back then, I simply didn't know about it, no one told me about it, and I wasn't smart enough to question myself once I started going down a certain path.
And there’s your problem right there: Assuming that nobody has ever tried to solve this problem before so not bothering to look around at existing solutions.
This is a failure of lack of context, in two ways:
1. The author lacked knowledge about the various possible solutions and the strengths and weaknesses of each one.
2. The author lacked knowledge of the context into which the solution would be applied, e.g. a sophisticated solution might not make sense for an unsophisticated team to maintain.
Found solutions also tend to be super clever. Because they're packaged in a generalized library or white-paper, where the author doesn't have to worry about implementation details.
Clever works great outside of your actual business code.
I would argue you can be clever in one place if it lowers the overall complexity of the code.
In the Lisp community, we try to be "clever by composition" and not "clever by subclassing" and... it makes code where you have to have more than one thing in mind at a time, but if you can do that it's often MUCH simpler than subclasses.
A practical example might be a collections "class" (actually just a few functions) in old-school lucid lisp to do the same thing Java/Smalltalk collections did. Instead of subclassing for Set, Dictionary, OrderedCollection, etc. We had an "insert" function that could call functions to see if we could insert a particular element and where to insert it if we could. If you wanted Set semantics, you returned false from the first function if the element was in the collection. If you wanted OrderedCollection semantics, you did a binary search to find where to insert the element.
It worked well if you were the type of programmer who couldn't remember the Collections class hierarchy semantics but could remember how to write two functions. I'm sure we had a few helper functions for common cases.
It's not a panacea, but every now and again you can lower the overall complexity by raising the complexity of a small portion of code. It is, as the author has discovered, hard to figure out how to do it right the first time through.
At a previous job we used ActiveAdmin on top of Rails, which is a sort of CRUDController as described in the article. Wonderful productivity when you are just starting out, but it got so bloated that it took over a minute to hot reload code. You basically had to kill the server and restart it when changing anything.
Nobody dared doing anything about it and nobody had any idea how to fix the issues. But there were scripts to make it easier to kill and restart the development server...
So at some point I wrote a script that read the ActiveAdmin parts and used a library to convert it into its abstract syntax tree. Now I could manipulate the tree and shape it into regular Rails controllers and plain old HTML views.
That took care of about 90% of the work. The remaining 10% was of course the weird exceptions. Finishing it took a lot of testing, a ballsy deploy to production, and a further hour of frantic bug fixing, but then it was done.
No more productivity destroying hassling with the smart admin framework. I think I would have quit my job way earlier if I wasn't able to fix that, and had to live with it instead.
> It's such a classic example, many of you probably recognise it. I wouldn't say my coding skills were bad, by the way.
Oh, coding skills. This isn’t about coding skills, this is about maintenance skills, which are wholly almost completely different than coding skills.
Maintenance skills are about creating systems where you can:
- extend, add or remove with low risk
- quickly read and understand
- quickly find a relevant bit
- keep modules simple enough that you can consider all possible cases and build them robustly to handle those cases
I see a lot in test code where engineers get overly clever and start writing looping test scripts and whatnot and pretty soon, you don’t have a clear picture of what’s even being tested anymore, or it becomes difficult to remove or change a part of the test.
Testing is _not_ an area you want to get clever with. There is already plenty of built in complexity in introspecting and mocking runtime code to be adding a layer of cleverness to it.
An engineer of a complex system doesn’t strive to make things that are clever or novel. They strive to make things that are maintainable (as defined above). If in DRYing up code, or creating a solution, it’s not making the code more maintainable, you’re going the wrong way.
This is a junior issue fixable with proper social alignment with the team or business process. If the team has no adequate know-how transfer process then there is no right way to properly abstract and understand any business model.
Saying "Don't be clever" is like saying, let me give you a piece of advice: "Don't be mistaken". I've personally find that level of vagueness very annoying.
I don't understand why he added all those exceptions to the abstract class. That's not what abstract classes are for. The initial code example shows an implementation class inheriting from the abstract class; that seems like the perfect place for exceptions. Why not simply use that most basic feature of OOP? Override the parts of your abstract class that you need to override.
I guess he wanted to make sure that the subclass code would be as simple as possible. So when he wanted to add a new entity to his model, as he mentioned, he only had to extend the abstract class, without writing any new business logic.
Clearly what you're saying is correct, however, it would mess up his original intent, which was frictionless extensibility.
The problem isn’t copying code, the problem is if the code has to evolve and then has to be changed in a dozen places consistently. Each place by now having its own particular knobs and special cases doesn’t make it easier.
In the context of code maintenance and evolution, there is a tension between duplication and abstraction. Both have their drawbacks. There is no silver bullet. One can overdo both.
Which is why I always use the term „clever by half”. Simply clever is actually good and a term of praise. Clever until an unforeseen (but foreseeable!) consequence bites back, is, well, not clever enough.
Everyone always wants simple beautiful code they can understand, I want boring code, that implements a beautiful UI users can understand.
And if that means calling some black box of horrors mega library, that's fine as long as I don't have to look in the box.
My first approach to embedded was an installer script that configures a stock distro image. Then I moved to a premade CustomPiOs image, but that's a nightmare and adds another large artifact to build and manage and maintain and isn't portable. Now I'm back to the installer script.
Technical merits have nothing to do with the choice really. Nobody else was interested in learning anything about the customized image but they already know basic scripting.
As much as I love high tech, and pretty much always use the megaproject latest hyper neophile stuff if I can.... I like not having to maintain custom stuff even more.
This describes our legacy codebase, which is quite cleverly optimized for the original business case our company had ~15 years ago, and which is now a massive millstone dragging everything down into a black abyss. Just try to add a feature, I dare you.
I would say: design for flexibility rather than cleverness in most cases.
Fifteen years is a long time for code to remain unchanged. Either you constantly work on it and change as the needs change, or you have a boom and bust cycle of productivity.
Another way to look at it would be: holy shit, this company made it 15 years without investing in rearchitecting their codebase even as they took on new problems. That's amazing! Now we have 15 years worth of use cases to accommodate as we remodel/rearchitect/refactor/rewrite ... do you think that new codebase will last 15 years before it needs major work?
If the amount of time it takes to type your code is the biggest bottleneck in your project and you need to optimise for amount of characters written you're either the most genius 100x coder ever or ... not one of the best.
You should always optimise your (work) code for readability, even if it takes longer to type. I've spent way too many hundreds of hours of my 25 year career untangling overly clever code just to figure out what's wrong.
If you can't be sure the person who has to open up your clever code at 3AM to fix a live production issue can instantly see what's going on with the code, write more readable code. Preferably ask someone to review the pull request and see if they can understand what's going on.
You can be as clever and terse you want on your own time, but on company time write readable code even if it's verbose.
The only time being clever has helped me has been putting out a fire in production, to stop the bleeding, and to buy us time for implementing a better fix in the next release.
Being clever during feature development is a red flag to me. I’m a huge fan of the YAGNI principle.
The CRUDController example is interesting because the problem is not exactly cleverness, but more a design without good escape hatches. It's bad because the pathway from a CRUDController to a controller that does more is a total rewrite.
I have a slightly different view and I think expressing it in front of the right people may have gotten me a job. Programmers ought to be clever, but clever is something you hold in reserve. Choose the boring, the staid, the obvious. Clever is for when you're backed into a corner by odd requirements, edge cases that the obvious will not cover, and so on. Then, you comment your clever, journalism-style. Why were you clever? Where is the clever? Just how did you do it? When do you apply this? And so on.
While I agree with the sentiment to keep things simple, I feel that saying "don't be clever" is just a way for developers to sound actually clever. :-D
So much of the horribly unmaintainable code I've come across was the result of overengineering that whenever I see an abstraction I have a compulsive urge to scream into the void. Some (the simplest ones) are ok, but other times an abstraction that seems like a good idea on day 0 evolves into an unmanageable hodgepodge of hacks that makes an innocent developer that bumps into it years later question their choice of career.
An abstraction creates a new language, a new semantic layer, that has a precise definition. You can express laws and properties from its definition. This lets you think in the new semantic layer without thinking about the lower levels of complexity.
But yes… the pattern class problem is real. a good number of us have all done it once or twice.
The takeaway seems less about nifty coding and more about working in isolation. The author found a path he thought would solve the problem and was 'clever', but never really got feedback from peers. I've done that myself; been so enamored with my own idea that I failed to get feedback and ultimately delivered a non-optimal solution.
things like this always have some underlying notion that there are objectively correct combinations of lines of code. There isn't. The cleverness problem can live at any level in a system.... this line is really clever because in <language> <data type> is really just a <other data type>, so if we use this <unrelated feature> we actually can do this all in one line!
You can also have system level cleverness, which is fine as long as you can explain the cleverness in a few sentences. Sometimes the data access layer is clever and the other stuff isn't....
at the end of the day, as long as you leave things such that they are easy to change, or at least you're brave enough to change them, none of it really matters. Someone is going to replace the "clever" code with other code that does more or less the same thing, and then next engineer will replace that code with something else.
I’ve been working with Prisma and React Query recently and I wonder if those libraries haven’t fallen victim to the same trap. They seem to want to ”do everything you could possibly want to do, in a clean wrapper”.
But I wonder if they are trying to wrap domains that are too big to wrap, and should just be left to a programming language.
It seems, in some subcultures the FactoryFactory or ServiceService approach to reducing repetition and increasing complexity is common. In Lisps/ Scheme the best approach is usually the copy&paste until you established it is a problem and then introduce some wrapper function or a macro or whatever.
I read this like "if I was was really clever back then I would do what now I think is clever" and my humble opinion about the ultimate solution for it really horrifies me (the class generator).
Maybe I'm not clever enough. Maybe I don't hate copy and pasting enough.
The real hidden message in the article is: no matter how great you think your code is, when you revisit it a few years later, it will (nearly) always be crappy.
The lesson is to keep it simple so everyone can recognize that it's crappy and help fix it/make it worse.
As a corollary, quite often in code there is a 'happy path', or small set of operations that people are going to be using 90% of the time. That code is going to get read even more, so make it as high quality and as simple as possible, don't mess with it unless you're very sure...
Oh no, the conclusion is so funny. That's the problem with "magic frameworks" like ASP.NET, where it's not obvious how to extend things if need be (if even possible).
Code generations is just metaprogramming. The worst case, where you have to compile twice. The first one to generate the code and the second to compile the generated code.
Ha, I ran into one of these once. I didn't write it.
Even our database records of "OAuth clients" went through it. I had wanted to make an optimization to those: I wanted to inline the OAuth client IDs for the mobile & web applications into the source code¹. The beast that was the CRUD controller stopped me in my tracks. I eventually gave up — too much complexity all muddled into one thing.
It was also "cleverly" general in that our admin interface built off it, and the UI thus built the table showing you what records existed … generically! Similarly, you could generically CRUD records. And one day … someone deleted the mobile client's record from the OAuth client's table, which of course breaks the mobile app and caused an outage, and lead me to wonder "why do we even have this lever, Kronk?" (While maybe it made sense to delete some random script's OAuth client … not so much the mobile app¹.)
Treating everything as a generic object that can be CRUD'd is one of those extremely leaky abstractions, and as the article gets at, it's usually the business logic that will reveal where the holes in the hull are.
We had another class of "objects" which were user uploads, and they went through about 4 different storage models (they started as rows in the database, and that didn't scale well at all — they ended up as S3 objects which was okay-ish). But my predecessors, when they added a newer, better way of storing these … didn't migrate the old ones. So the read logic had to be ready for a v1 upload or a v4 upload. A minor nightmare. So add "the DB model changes and is never migrated" to the list of things that screw these things up.
(I still see devs doing this — adding newer, better means of storing something but not migrating the old records — and it's massive tech debt, every time I've seen it. Inevitably, I've had someone want to do a "give me all the data" style query, and that necessitates dealing with all the caked on layers of upgrades.
My current company has this in the form of audit records. They started in the database … which … didn't … scale … and now they're in … a bucket in a cloud's blob storage, which is okay-ish.
So if you ever find yourself in one of these … please, please migrate the old data.)
I don't think codegen is the answer. I don't think codegen is ever the answer … "what happens when the generator changes?" is something I never see addressed. The old code rots, typically.
(¹because a.) unless the company folded, they weren't going to change, so I figured that a commit to remove the literal mobile app was fine in that case and b.) that meant that, for those clients, we didn't need to make DB requests to that table. IIRC we did this on every query.)
OK, I grasp what the author is getting at -- there are certainly times when I've gone needlessly complex expecting a set of problems that not only never materialized, but the ones that actually materialized were poorly handled by my design. It sucks. Lesson learned.
I only have first-person anec-data based on a diverse career in software development (big/small/solo/small/big team/process-heavy/haphazard) but it's the opposite circumstance that usually burns me far worse.
I describe this as "they asked for this really small thing and now it runs half the company" problem. It's an exaggeration, but the story from my past was the temporary system that was set up for an (unnamed) major long-distance carrier to "pay the bill via an EDI setup"[1]. Ten years later, shortly after we moved a huge data-center to another time zone the panic alarm bells rang over a few million dollars missing from said carrier.
The temporary-turned-permanent setup was an IBM NetVista machine hooked up to a 1200 baud modem with a dedicated phone line running a DOS program at boot off of a hard drive that had to have its disk parameters manually provided via BIOS every reboot because the little battery inside had sent its last electron down the line and -- rather than replace the battery with an abundance of spares -- the technician decided printing a label with the values would suffice.
A more apt example would be a dashboard that I created a simple service for which produced a list of "the top 20 endpoint threats by vulnerability patching level" ... oh did the execs love this[2], which led to creating a mess of other dashboards and a set of small services that produced just the hostnames. They were all variations like "Just locations with desktop support staff on-site by location", "Servers", "Domain Controllers" ... I want to say I had something like 30 variations at the end ... and thousands of lines of code. I wasn't clever. This "stupid service" took me away from things I needed to finish and several others that I enjoyed working on much more, so this was a model of spaghetti-code-copy-pasta(-marinara). And then they wanted something added to the output of everything. I finished it a few days before leaving the department ... along the way I figured out that more than half of the reports produced results that were anywhere from "kind of close" to what they said they did to several which produced results for the wrong building for each endpoint type (and -- as a result -- was completely ignored). I bit the bullet and took this 5,000 multi-file ASP (vbscript!) monster down to 6-ish classes, less than 500 lines, easy to extend/expand and re-use what's there[3].
Unfortunately, this leads to the totally useless advice of "Be Clever When It Will Help." When will it help? Beats the hell out of me. I didn't imagine a world where a VP calling my desk asking for "a quick web page that shows the worst machines on the network for a slide I'm working on" would become an integral reporting component of an in-house massive networking auditing tool, so I can't help much, there...
[0] Admittedly, I only discovered I encountered the opposite circumstance after that circumstance presented itself, so the whole thing benefited from hindsight bias.
[1] I was not directly involved in the software involved, only in the resurrection of the dead service.
[2] I had the dubious distinction of accidentally creating "a new operations process" whereby every week it was expected that the top 20 machines on Monday (...which became "from each list"...) would be fully resolved by Friday. Desktop had to have dolls in my shape with knives sticking out of them.
[3] Demonstrated on the final revision by adding a single class that altered the retrieval process to WeakReference cache all views (there were reasons an output cache wasn't useful due to it now being part of a bigger system that often required previously materialized values on other threads but never touched an HTTP endpoint).
The problem OP describes (multiple classes like that other class, but with a twist each) is a textbook use case for inheritance, but after decades of prominent programmers indoctrinating „inheritance bad”, I can see why he would not consider it at all.
On a similar vein, Kernighan’s Law: Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.
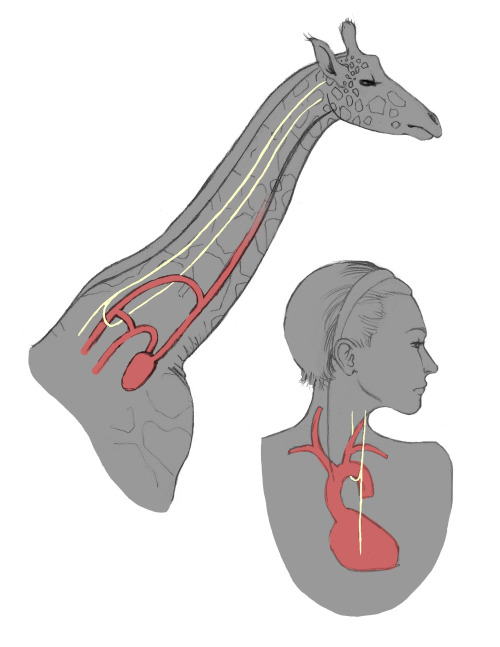{kind=link}
No, please don't. This is jumping from the frying pan into the fire. If you think abstract base classes can be clever and hard to understand, code generators can be even more so. In addition, because code generators are a one way conversion, and the generated code evolves independently and the code generator itself is evolving independently, you end up with a bunch of things that are subtly different yet somewhat related in a way that you will need an advanced degree in evolutionary biology to understand.