These will finally cross a (useless and arbitrary) gap we've been at the doorstep of for the last 3 CPU generations: having enough threads in a consumer class CPU to change the task manager from line graphs to bar graphs!
In all seriousness, what I like about AMDs approach with the high core count complexes is they aren't completely different cores like the Intel efficiency cores, they're just slower cores. I do wish they'd take that as an opportunity to go crazy with the primary cores though, doing something like 4 or 6 asolutely giant cores and 16 small cores to give it a bit more than a 15% boost for those things which can't take advantage of having a bazillion cores available.
> having enough threads in a consumer class CPU to change the task manager from line graphs to bar graphs
If it will be done with voice recognition using iGPU. And just in case, add AI analysis for anomalies. I could say "take my money", but for now it only will take time of developers; doesn't matter, whatever. Personally, I'm pretty tired of Intel dividing its processors into something for servers, for enthusiasts, and for commoners. Thank you AMD for universal AVX-512 without downclocking or pseudo-cores.
I have an "old" 32c/64t threadripper 2990-WX as my primary dev machine. I'm really looking forward to a consumer grade Zen5 with 32c/64t as an upgrade, as threadripper is now locked to high costs OEMs..
In fact, I wonder how much market there will be for threadripper once we have 32c/64t consumer grade desktop CPUS.
Right now the problem with consumer grade CPUs from AMD is that you can't have 128 GB of memory running at full speed. You need to use 4 memory modules which means a lower speed.
From https://www.amd.com/en/products/cpu/amd-ryzen-9-7950x
Though theoretically that will stop being an issue when it’s viable to only hand the gpu 4-8 pcie 5.0 lanes and 1-2 lanes to an nvme drive or two. Then there would be plenty left over for other things.
100%, still rocking the original 1950x for this reason alone. More nvme storage makes a bigger difference to me than more cores or ipc. Pcie is where all the fun things are used =)
Huh, I didn’t know this. I recently upgraded my workstation to 128G and after some trial and error had to bring down the memory speed from 6000 to 4800.
Is it working just by accident?
CPU: AMD Ryzen 9 7950X
Memory: GSkill Trident Z5 Neo 6000 MHz.
Mobo: Asus Tuf Gaming x670e WiFi 6e
Probably a case of "not exactly". You're just overclocking the memory, and both your memory modules + the rest of the system are happy with those particular speeds.
It'll probably run happily at those speeds basically forever, so nothing to really worry about from doing that.
From an old article published by Puget Systems in 2013 [1]:
> Finally, ECC RAM is slightly slower than non-ECC RAM. Many memory manufacturers say that ECC RAM will be roughly 2% slower than standard RAM due to the additional time it takes for the system to check for any memory errors. To verify this, we examined multiple benchmarks that we run on each system we produce. By using comparable CPUs (For example: Intel Core i7 4771 3.5GHz Quad Core 8MB versus Intel Xeon E3-1275 V3 3.5GHZ Quad Core 8MB) we found that this 2% estimate to be roughly correct. Our own benchmarks showed a performance hit ranging from .72 to 2.2% which, given normal testing deviations, is right in line with the 2% estimate.
I wasn't commenting on the speed of ECC memory, although from what I've seen manufacturers don't offer ECC memory modules with a speed as high as non-ECC versions.
Anyway what bugs me about Zen < 4 is that you can install ECC memory, but you can't be sure that ECC is really working on some motherboards.
For Zen 4 at least there's DDR5 with its on-die ECC, but the path to the CPU might still be unprotected.
> manufacturers don't offer ECC memory modules with a speed as high as non-ECC versions.
Indeed, they seem to be aiming their ECC sticks at the server market, their "overclockable" sticks at the gamer market, and not mixing the two. Perhaps this would change if more workstation motherboards officially supported ECC.
In the meantime, I suspect today's ECC RAM and X3D cache CPUs might complement each other well.
> For Zen 4 at least there's DDR5 with its on-die ECC, but the path to the CPU might still be unprotected.
Some Zen 4 motherboards do support ECC. ASUS lists it in their manuals and exposes settings for it in their EFI setup, for example.
As for being sure that it's working, I suppose that depends on the OS. This addition in Linux 6.5 looks helpful:
You can most certainly test ECC functionality on unqualified boards using a Linux LiveCD/USB. And there are plenty of boards that have gone through the process of getting ECC qualified, and advertise the feature. ASUS, for instance.
Wasn’t Threadripper more of a “because we can” product, not a mainstream one? The price jump from the highest end Zens to the lowest end Threadrippers seems to indicate that.
Yes, it is basically a prosumer version of the Epyc server CPUS, limit to a single socket, and with higher clocks.
What frustrates me is that in the last 2 or so generations, you cannot simply buy a CPU. One has to buy an entire system from a vendor like Lenovo or HP. When I built my box in 2018, the 2990-WX was available for ~$1900. Which is a lot, but doesn't match the $5k->10k prices for the entire systems.
There just aren't that many affordable, reasonably efficient ways to get >= 32c these days. (and by efficient, I'm excluding used server-class boxes from older generations that are power hungry).
Price... now that's definitely a story :). The current 32 core Threadripper is around $3,000 itself now. It does have some advantages like the 8 memory channels but even just trying to build a low core count box with a lot of PCIe lanes is an extremely expensive endeavour. I think part of it has to do with the gap between the consumer and server markets widening over time, it becomes harder to justify doesn't something special for the HEDT market.
> Yes, it is basically a prosumer version of the Epyc server CPUS
Threadripper was, yes. Threadripper Pro wasn't. It was a workstation CPU. Threadripper was discontinued while Threadripper Pro wasn't, because workstation CPUs are profitable, while HEDT CPUs aren't.
(AFAICT the HEDT "class" of CPUs only existed for a short time when CPU production was such that all the individual cores could perform really well, but the die as a whole could still fail validation as a server/workstation-grade CPU. I think, with chiplets, this just doesn't happen any more.)
Similar to what the sibling comment says, I was able to find a motherboard/CPU combo from Newegg 2 years ago when I built mine around a 3955WX. I'm not incredibly happy with the Supermicro board though and sort of wish I went with the Asus.
The boot time is long, the BMS programs are awkward (but maybe I'm not familiar with server-style BMS programs), and I can't get the DDR4 clock as high as it should be for my DRAM. There's a chance my UDIMM doesn't support the speed I want to run, but it hasn't been a big enough deal for me to look into.
Yea, SuperMicro are not boot time optimized boards at all. In the style of systems I've always built them in we were talking systems that might only be rebooted once or twice a year.
Though with CPU/firmware exploits commonly getting patched it does seem like there are a lot of reasons to reboot server style systems these days.
I have 4x16GB of 3200MT/s DDR4, but can't get the clock above 1055 MHz (which would be 2110MT/s). There's a chance that the cheaper/consumer grade G.skill memory isn't compatible with those speeds, but it hasn't been a blocker lately.
I built the machine to be more basic for now but be able to upgrade over time into a powerful computer to run electromagnetic simulations.
I'm disappointed in the lack of I/O in consumer chips these days. I've had 3930k 4930k and now 1680v2 Xeon and I have memory channels and PCIe lanes coming out of my ears. Current consumer chips give you maybe 20 lanes.
Things actually end up not that different in the I/O department. Yeah, there are only 20 lanes going direct to the CPU but the northbridge has the bandwidth to hang another true 16 PCIe 3.0 lanes off it (before running into contention). At this point you are still an honest 4 lanes short but half the lanes are 4x faster so things like your GPU or high speed NIC don't need to eat 16 lanes each in the first place. The story repeats on memory where, yeah, you don't have 4 memory channels anymore... but the actual memory bandwidth is significantly higher and the total capacity is about the same.
I've got a 13900k NAS build with 14 NVMe drives in it and 25G network connectivity. If you do W680 for the motherboard instead of the typical boards you get to keep the ECC too. Saved me thousands compared to getting equivalent I/O and total CPU performance with a server board. Reminded me a lot of when I got a 1650v3 prior really, "oh, it's kind of just consumer stuff but fully loaded", but ran a lot faster (of course).
The hardest part is finding a board which breaks out the things out into ports instead of trying to figure out how to cram 2 extra cheap "gaming" nics, wi-fi, 50 USB ports, or other useless things in statically instead.
Never said full speed because I'm running 192 GB at 5200 MT/s :p. Just the ASUS Z790 creator, like I said though I'd look into W680 and some ECC instead had I not had a steal of a deal on the memory at the time. 5600 MT/s booted but wouldn't pass memory tests. I've heard others with the same setup needed to go to 4800. That just happens to still be faster than the max memory bandwidth of the quad channel platform that was referenced anyways.
Part of it might be that the early 48 GB kits (mine included) were themselves only rated for 5600. I'd be willing to bet mine would work at 5600 with one of these new better rated ~6800 kits helping things a little.
I will say my experience with the memory controllers on modern Intel systems has been SIGNIFICANTLY better than my experience with them memory controllers on modern AMD systems. I could barely get my 7950X to do 64 GB at 6000, and that was one of the better experiences have had with the Zen memory controllers, but the Intel builds easily blow past that.
I am much more looking forward to potential 256 Core EPYC with PCIe 6.0 Server for Netflix CDN.... Waiting for the "Serving Netflix Video Traffic at 3200Gb/s and Beyond" Talk :)
That is assuming 1600Gb/s is already possible with ConnectX-7 XD.
I'm looking forward to the 96 core Threadripper, personally. It helps for compilation to have as many cores as possible. Not sure how the single threaded performance will be however as it's slower than the Ryzen series, generally, and I still want to game.
I don't think consumer grade Zen5 with 32c/64t will be released because the frequency of Zen 5c will be pretty low leading to poor single-thread performance.
Many CPUs have claimed to be competitive with x86, but it rarely pans out. Being able to match the IPC on a microbenchmark is good, but they often struggle with poorly tuned, low bandwidth cache and memory controllers.
I would like to think Wei-Han Lien's (who previously led M1 at Apple) Ascalon team, as well as Jim Keller (CEO), industry veterans as they are, definitely use industry standard benchmarks, and avoid the mistake of extrapolating IPC from microbenchmarks.
I'll bet the publicize whatever benchmark looks most competitive to get the next funding. That's no criticism, just the way every business somewhat has to work in a competitive industry.
Given the choice between exaggerating the performance and getting funded, and not exaggerating and running out of money, I think everyone ends up choosing the former.
I'd say Apple got there with their M1 and M2 chips. But it took 10 years of incrementally improving on an already commercially viable cpu, unlike what tensortorrent is claiming.
Latest zen4 is very competitive power wise with M2, M2 still has the crown,but laptop battery life is dominated by other parts of the system when you're down to 1 to 2 W of cpu power for light workloads.
only in cinebench or other dense math workloads afaik (especially ones that don't use vector extensions on ARM).
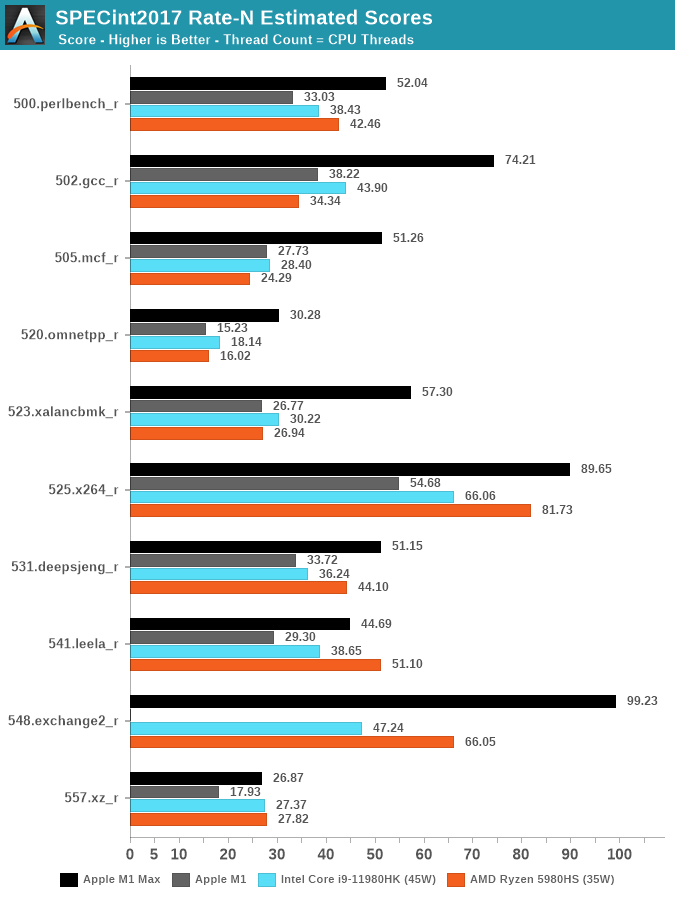
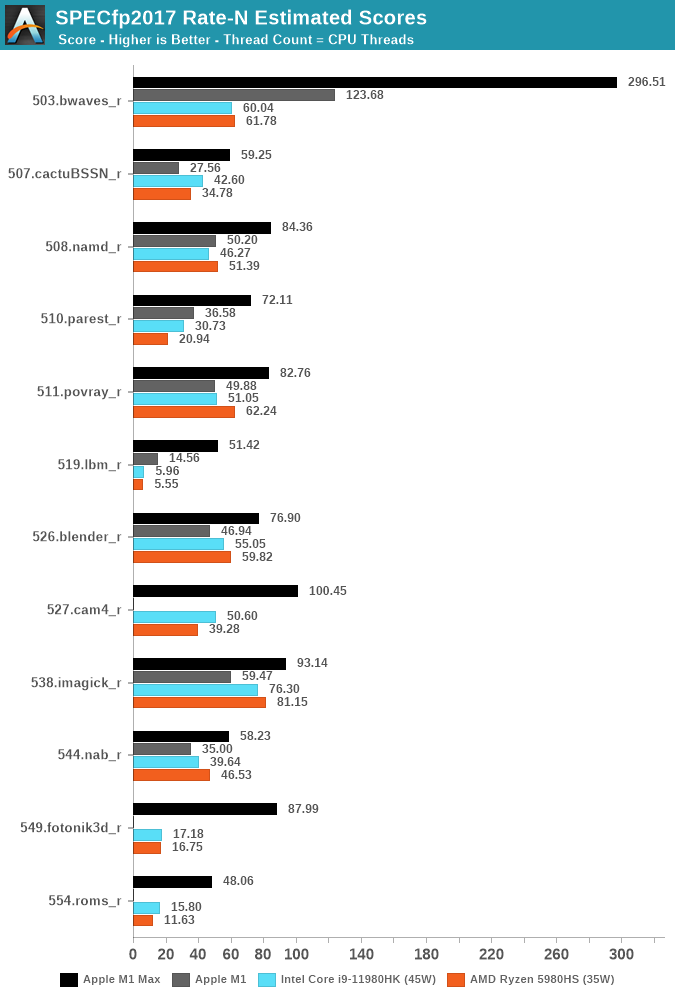
SPEC benchmarks have M1 Max demolishing x86 in a lot of real-world applications. Similarly, in things like CFD the M2 Ultra absolutely demolishes server processors let alone laptops.
cinebench really just tests one thing, arithmetic intensity, and it doesn't represent cache performance, branching, reordering, or anything else in a processor. but those are actually quite important to real workloads.
let's look at perf/w for, let's say gcc (chrome compiles?) or PGBench or something besides cinebench and see how the picture looks then.
Those charts are at 35w for the Ryzen, so calling that a comparison with a server class processor is a stretch. I don't see the power of the M2 in those benchmarks, do you know what it was for reference?
Would you say x86 is held back by lack of scalable vector processing, limited to AVX512? ARM must be doing something better power efficiency and parallel processing, that x86 was too complacent in.
We supposedly consume about 100 watts at rest.
Given that my flops are low (less than one!), I don't think I'm an efficient processor. At least for floating point operations.
Producing paper and ink cartridges isn't free, either.
I might be competitive with an LLM + GPUs, but I imagine it'll demolish me on throughput.
I don't think it's e-cores so much as a Zen 5 version of the Zen 4c cores. So smaller L3 (the 4c has half the L3 that the Zen 4 has) and slower clocks. But the compact cores are half of the size of the regular cores and about 75% of the power.
The key point is that the cores are otherwise the same so you don't have the weird intel situation where the e-cores don't support the same instructions as the p-cores.
> the weird intel situation where the e-cores don't support the same instructions as the p-cores
Intel didn’t have this problem. They simply disabled instructions available on P and not on E. They did face the scheduling issues inherent in heterogenous systems. But so will AMD.
Does Linux have mechanisms in place to properly utilize ecores? Specifically tagging background services so they never jump in priority? Or would it be up to me to manually assign affinity?
I read somewhere that part of what makes the iOS experience better is tight control over how much CPU background jobs can steal.
Linux has had support for cores with different capabilities for ~a decade, when arm introduced big.LITTLE. systemd puts background services in "slices", which can have properties set in bulk.
That’s interesting and easy enough to experiment. While I do not have mixed performance cores, I have been curious if pinning processes results in any noticeable smoothness. I get annoyed at various Gnome garbage that occasionally thrashes.
also has taskset which just lets you say "this PID can run on cores 0 through 13".
Not the friendliest mechanism for defining what runs on what but it's what I use to make sure that server software I really want on the P cores stays on the P cores.
> We don't know yet what types of cores these new Zen 5 core clusters will have. Half of Zen 5's core count could be dedicated entirely to Zen 5c efficiency cores, or the entire stack could be vanilla Zen 5 performance cores. It could be a mix of both since AMD's slides suggest that there will be different models featuring FP-512 support and some models with low-power cores.
Is anyone else finding that AWS is overcharging for the Zen 4 CPUS? I get better price performance for m6a vs m6i but the M7 series is too close to call for my workload.
This is really dampening my enthusiasm for future AMD hardware. I wonder if AMD is aware of the damage Amazon is doing to them right now.
Yeah, I found this too. For our specific workloads (data science) m7i-flex works well enough that I don’t mind, but it was not an obvious upgrade from m6a like I expected it to be.
Supply and demand, I think — their DCs just don't have that many of that instance-type to go around.
On GCP, even to this day, the Zen 2+3 instance type (N2D) doesn't cost more than the equivalent Intel N2 type; but you get very low quotas for N2D CPUs per project, and they aggressively refuse quota increases for them.
I assume that AWS here went with the other option for Zen 4, and just raised the price until demand went down enough that nobody was hitting the quotas any more. After all, they can always lower it later.
They’ve only been out for six weeks. We’ve just done so many migrations in the last few years that it’s pretty simple for us to upgrade things. Figuring out how many nodes to run is the only part that takes brain cells.
It makes sense in my case where I want strong single threaded performance, but it doesn't seem compelling to switch from Graviton if single threaded latency isn't important.
While 10-15% IPC increase is great on paper, it is quite far from previous rumoured 20-25%+ IPC increase. To put this in perspective, the A16 / A17 is ~50% faster per clock than Zen 4 in Geekbench 6. And will still be 20% faster than Zen 6 in ~2025/26.
Still waiting for 86 to catch up. It is just around the corner.
{kind=link}
{kind=link}
In all seriousness, what I like about AMDs approach with the high core count complexes is they aren't completely different cores like the Intel efficiency cores, they're just slower cores. I do wish they'd take that as an opportunity to go crazy with the primary cores though, doing something like 4 or 6 asolutely giant cores and 16 small cores to give it a bit more than a 15% boost for those things which can't take advantage of having a bazillion cores available.