Friendly fyi - I think this might just be a web interface bug but but I submitted a prompt with the Mixtral model and got a response (great!) then switched the dropdown to Llama and submitted the same prompt and got the exact same response.
It may be caching or it didn't change the model being queried or something else.
Thanks, I think it's because the chat context is fed back to the model for the next generation even when you switch models. If you refresh the page that should erase the history and you should get results purely from the model you choose.
They allow you to configure chat participants (a model + params like context or temp) and then each AI answers each question independently in-line so you can compare and remix outputs.
Alright, I'll bite. Haskell seems pretty unique in the ML space! Any unique benefits to this decision, and would you recommend it for others? What areas of your project do/don't use Haskell?
Haskell is a great language for writing compilers! The end of our compilation pipeline is written in Haskell. Other stages are written in C++ (MLIR) and Python. I'd recommend anyone to look at Haskell if they have a compiler-shaped problem, for sure.
We also use Haskell on our infra team. Most of our CI infra is written in Haskell and Nix. Some of the chip itself was designed in Haskell (or maybe Bluespec, a Haskell-like language for chip design, I'm not sure).
Haskell is a great language. However, when you want to build production grade software it’s the wrong language. Specially when it comes to a complicated piece of software like the compiler for a novel chip. I can tell you for a fact it has always being the wrong choice (specially in the case of Groq).
If I understand correctly, you're using specialized hardware to improve token generation speed, which is very latency bound on the speed of computation. However generating tokens only requires multiplying 1-dimensional matrices usually. If I enter a prompt with ~100 tokens then your service goes much slower. Probably because you have to multiply 2-dimensional matrices. What are you doing to improve the computation speed of prompt processing?
You can ask your website: "What is the computational complexity of self-attention with respect to input sequence length?"
It'll answer something along the lines of self-attention being O(n^2) (where n is the sequence length) because you have to compute an attention matrix of size n^2.
There are other attention mechanisms with better computational complexity, but they usually result in worse large language models. To answer jart: We'll have to wait until someone finds a good linear attention mechanism and then wait some more until someone trains a huge model with it (not Groq, they only do inference).
Changing the way transformer models works is orthogonal to gaining good performance on Mistral. Groq did great work reducing the latency considerably of generating tokens during inference. But I wouldn't be surprised if they etched the A matrix weights in some kind of fast ROM, used expensive SRAM for the the skinny B matrix, and sent everything else that didn't fit to good old fashioned hardware. That's great for generating text, but prompt processing is where the power is in AI. In order to process prompts fast, you need to multiply weights against 2-dimensional matrices. There is significant inequality in software implementations alone in terms of how quickly they're able to do this, irrespective of hardware. That's why things like BLAS libraries exist. So it'd be super interesting to hear about how a company like Groq that leverages both software and hardware specifically for inference is focusing on tackling its most important aspect.
One GrogCard has 230 MB SRAM, which is enough for every single weight matrix of Mixtral-8x7B. Code to check:
import urllib.request, json, math
for i in range(1, 20):
url = f"https://huggingface.co/mistralai/Mixtral-8x7B-v0.1/resolve/main/model-{i:05d}-of-00019.safetensors?download=true"
with urllib.request.urlopen(url) as r:
header_size = int.from_bytes(r.read(8), byteorder="little")
header = json.loads(r.read(header_size).decode("utf-8"))
for name, value in header.items():
if name.endswith(".weight"):
shape = value["shape"]
mb = math.prod(shape) * 2e-6
print(mb, "MB for", shape, name)
tome's other comment mentions that they use 568 GroqChips in total, which should be enough to fit even Llama2-70B completely in SRAM. I did not do any math for the KV cache, but it probably fits in there as well. Their hardware can do matrix-matrix multiplications, so there should not be any issues with BLAS. I don't see why they'd need other hardware.
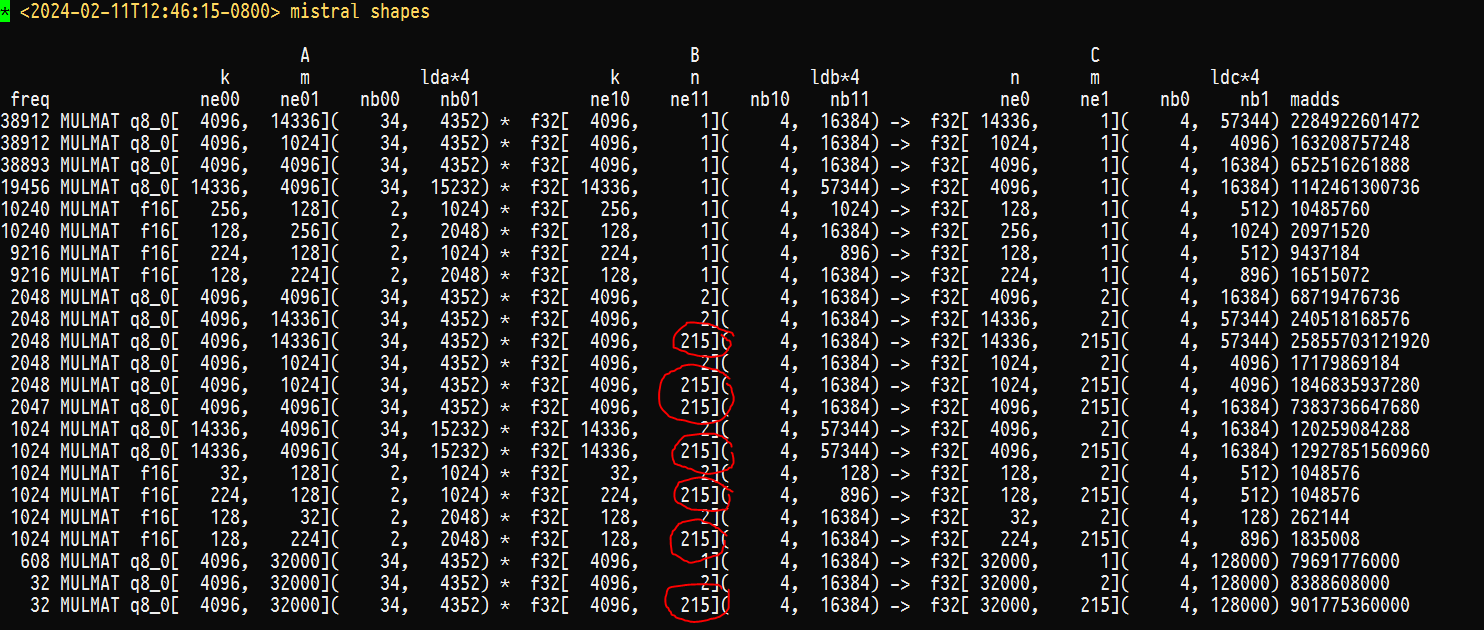
all I know is that when I run llama.cpp a lot of the matrices that get multiplied have their shapes defined by how many tokens are in my prompt. https://justine.lol/tmp/shapes.png Notice how the B matrix is always skinny for generating tokens. But for batch processing of the initial prompt, it's fat. It's not very hard to multiply a skinny matrix but once it's fat it gets harder. Handling the initial batch processing of the prompt appears to be what your service goes slow at.
You all seem like one of the only companies targeting low-latency inference rather than focusing on throughput (and thus $/inference) - what do you see as your primary market?
Yes, because we're one of the only companies whose hardware can actually support low latency! Everyone else is stuck with traditional designs and they try to make up for their high latency by batching to get higher throughput. But not all applications work with high throughput/high latency ... Low latency unlocks feeding the result of one model into the input of another model. Check out this conversational AI demo on CNN. You can't do that kind of thing unless you have low latency.
Might be a bit out of context, but isn't the TPU also optimized for low latency inference? (Judging by reading the original TPU architecture paper here - https://arxiv.org/abs/1704.04760). If so, does Groq actually provide hardware support for LLM inference?
Jonathan Ross on that paper is Groq's founder and CEO. Groq's LPU is an natural continuation of the breakthrough ideas he had when designing Google's TPU.
Could you clarify your question about hardware support? Currently we build out our hardware to support our cloud offering, and we sell systems to enterprise customers.
Thanks for the quick reply! About hardware support, I was wondering if the LPU has a hardware instruction to compute the attention matrix similar to the MatrixMultiply/Convolve instruction in the TPU ISA. (Maybe a hardware instruction which fuses a softmax on the matmul epilogue?)
We don't have a hardware instruction but we do have some patented technology around using a matrix engine to efficiently calculate other linear algebra operations such as convolution.
1. How many GroqCards are you using to run the Demo?
2. Is there a newer version you're using which has more SRAM (since the one I see online only has 230MB)? Since this seems to be the number that will drive down your cost (to take advantage of batch processing, CMIIW!)
3. Can TTS pipelines be integrated with your stack? If so, we can truly have very low latency calls!
1. I think our GroqChat demo is using 568 GroqChips. I'm not sure exactly, but it's about that number.
2. We're working on our second generation chip. I don't know how much SRAM it has exactly but we don't need to increase the SRAM to get efficient scaling. Our system is deterministic, which means no need for waiting or queuing anywhere, and we can have very low latency interconnect between cards.
3. Yeah absolutely, see this video of a live demo on CNN!
Follow up (noob) question: Are you using a KV cache? That would significantly increase your memory requirements. Or are you forwarding the whole prompt for each auto-regressive pass?
You're welcome! Yes, we have KV cache. Being able to implement this efficiently in terms of hardware requirements and compute time is one of the benefits of our deterministic chip architecture (and deterministic system architecture).
I think currently 1. Unlike with graphics processors, which really need data parallelism to get good throughput, our LPU architecture allows us to deliver good throughput even at batch size 1.
Yeah. And it's a real shame bc even before LLMs got big I was thinking, couple generations down the line and coral would be great for some home automation/edge AI stuff.
Fortunately LLMs and hard work of clever peeps running em on commodity hardware are starting to make this possible anyway.
Because Google Home/Assistant just seems to keep getting dumber and dumber...
You can find out about the chip to chip interconnect from our paper below, section 2.3. I don't think that's custom.
We achieve low latency by basically being a software-defined architecture. Our functional units operate completely orthoganal to each other. We don't have to batch in order to achieve parallelism and the system behaviour is completely deterministic, so we can schedule all operations precisely.
are your accelerator chips designed in-house? or they're some specialized silicon or FPGPU or something that you wrote very optimized code for inference?
it's really amazing! the first time I tried the demo, I had to try a few prompts to believe it wasn't just an animation :)
When you start using Samsung 4 nm are you switching from SRAM to HDM? If yes, how's that going to affect all the metrics given that SRAM is so much faster? Someone said you'll eventually move to HDM because SRAM improvements is relatively stalled.
I read an article that indicated your Bill Of Materials compared to NVidia's is 10x to get 1/10 the latency, and 8x BOM for throughput if Nvidia optimizes for throughput? Does this seem accurate? That CAPEX is the primary drawback?
I will mention: A lot of innovation in this space comes bottom-up. The sooner you can get something in the hands of individuals and smaller institutions, the better your market position will be.
I'm coding to NVidia right now. That builds them a moat. The instant I can get other hardware working, the less of a moat they will have. The more open it is, the more likely I am to adopt it.
I don't think that quite does it. What I'd want -- if you want me to support you -- is access to the chip, libraries, and API documentation.
Best-case would be something I buy for <$2k (if out-of-pocket) or under $5k (if employer). Next best case would be a cloud service with a limited free tier. It's okay if it has barely enough quota that I can develop to it, but the quota should never expire.
(The mistake a lot of services make is to limit free tier to e.g. 30 day or 1 year, rather than hours/month; if I didn't get around to evaluating, switch employers, switch projects, etc. the free tier is gone).
I did sign up for your API service. I won't be able to use it in prod before your (very nice) privacy guarantees are turned into lawyer-compliant regulatory language. But it's an almost ideal fit for my application.
The issue with their approach is that the whole LLM must fit in the chips to run at all: you need hundreds of cards to run a 7B LLM.
This approach is very good if you want to spend several millions building a large inference server to achieve the lowest latency possible. But it doesn't make sense for a lone customer buying a single card, since you wouldn't really be able to run anything on it.
I don’t really understand this. If you are happy to buy a <2K card, then what does it matter if the service is paid or not? Clearly you have enough disposable income to not care about a ‘free’ tier.
2) Low-level access and doing things the manufacturer did not intend, rather than just running inference on Mixtral.
3) Knowing it will be there tomorrow, and I'm not tied to you. I'm more than happy to pay for hosted services, so long as I know after your next pivot, I'm not left hanging.
Why free tier?
I'm only willing to subsidize my employer on rare occasions.
Paying $12 for a prototype means approvals and paperwork if employer does it. I won't do it out-of-pocket unless I'm very sure I'll use it. I've had free tier translate into millions of dollars of income for one cloud vendor about a decade ago. Ironically, it never happened again, since when I switched jobs, my free tier was gone.
Don't blame you. Been at plenty of startups, resources are finite, and focus is important.
My only point was to, well, perhaps bump this up from #100 on your personal priority list perhaps to #87, to the limited extent that influences your business.
Groq Engineer here as well; we actually built our compiler to compile pytorch, TensorFlow, and Onnx natively, so a lot of the amazing work being done by y'all isn't building much of a moat. We got LLama2 working on our hardware in just a couple of days!
How does the Groq PCIE Card work exactly? Does it use system ram to stream the model data to the card? How many T/s could one expect with e.g. 36000Mhz DDR4 Ram?
We build out large systems where we stream in the model weights to the system once and then run multiple inferences on it. We don't really recommend streaming model weights repeatedly onto the chip because you'll lose the benefits of low latency.
Have a look at section 2.3 of our paper. Between any two chips we get 100 Gbps. The overall bandwidth depends on the connection topology used. I don't know if we make that public.
It's a general purpose compute engine for numerical computing and linear algebra, so it can accelerate any ML workloads. Previously we've accelerated models for stabilising fusion reactions and for COVID drug discovery
It seems like you are making general purpose chips to run many models. Are we at a stage where we can consider taping out inference networks directly propagating the weights as constants in the RTL design?
Are chips and models obsoleted on roughly the same timelines?
I think the models change far too quickly for that to be viable. A chip has to last several years. Currently we're seeing groundbreaking models released every few months.
@tome for the deterministic system, what if the timing for one chip/part is off due to manufacturing/environmental factors (e.g., temperature) ? How does the system handle this?
We know the maximum possible clock drift and so we know when we need to do a resynchronisation to keep all the chips in sync. You can read about it in section 3.3 of our recent whitepaper: https://wow.groq.com/wp-content/uploads/2023/05/GroqISCAPape...
Those sorts of issues are part of timing analysis for a chip, but once a chip's clock rate is set, they don't really factor in unless there is some kind of dynamic voltage/frequency scaling scheme going on. This chip probably does not do any of that and just uses a fixed frequency, so timing is perfectly predictable.
It should work great as far as I know. We've implemented some diffusion models for image generation but we don't offer them at the moment. I'm not aware of us having implemented any video models.
{kind=link}
(If you check my HN post history you'll see I post a lot about Haskell. That's right, part of Groq's compilation pipeline is written in Haskell!)