At least their bots accurately identify themselves in the User-Agent field even when they're ignoring robots.txt, so serverside blocking is on the table for now at least.
Bytedances crawler (Bytespider) is another one which disregards robots.txt but still identifies itself, and you probably should block it because it's very aggressive.
It's going to get annoying fast when they inevitably go full blackhat and start masquerading as normal browser traffic.
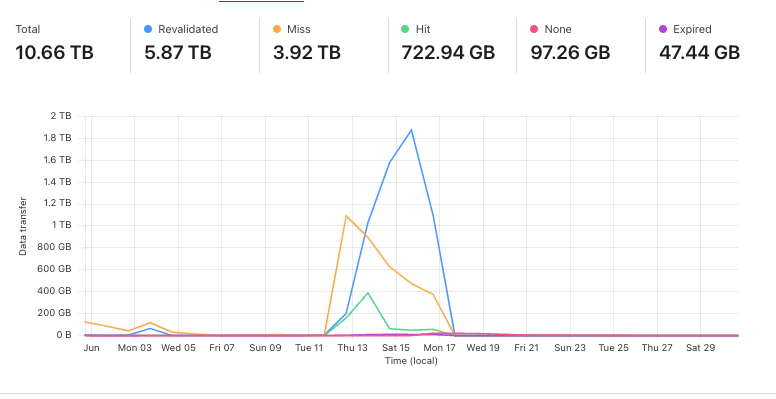
For those saying "just use a CDN", it's not nearly that simple. Even behind a CDN, the crawlers on our site are hitting large files that aren't frequently accessed. This leads to large cache miss rates:
> Sites use robots.txt to tell well-behaved web crawlers what data is up for grabs and what data is off limits. Anthropic ignores it and takes your data anyway. That’s even if you’ve updated your robots.txt with the latest configuration details for Anthropic. [404 Media]
Cloudflare has a switch to block all the unknown bots other than the well behaved one. Would this be a simple solution to most of the sites? I wonder if the main concern here is that the sites don't want to waste bandwidth/compute for AI bots or they don't want their content to be used for training.
I've noticed Anthropic bots in my logs for more than a year now and I welcome them. I'd love for their LLM to be better at what I'm interested in. I run my website off my home connection on a desktop computer and I've never had a problem. I'm not saying my dozens of run-ins with the anthropic bots (there have been 3 variations I've seen so far) are totally representative, but they've been respecting my robots.txt.
They even respect extended robots.txt features like,
User-agent: *
Disallow: /library/*.pdf$
I make my websites for other people to see. They are not secrets I hoard who's value goes away when copied. The more copies and derivations the better.
I guess ideas like creative commons and sharing go away when the smell of money enters the water. Better lock all your text behind paywalls so the evil corporations won't get it. Just be aware, for every incorporated entity you block you're blocking just as many humans with false positives, if not more. This anti-"scraping" hysteria is mostly profit motivated.
> This anti-"scraping" hysteria is mostly profit motivated.
That seems overly reductive.
First, it sounds like you're insinuating that the people claiming the bots are causing actual disruption to their operations are lying. If that's your intent, some amount of evidence for that would be welcome.
Second, lots of people don't want their content to be used to train these models for reasons that have nothing whatsoever to do with money. Trying to avoid contributing to the training of these models is not the equivalent of rejecting the idea of the free exchange of information.
I qualified my statement but you've chosen to ignore that. I've been paying attention to the Anthropic bots closely for a (relatively) long time and this mastodon group's problems come as a surprise to me based off that lived experience. I don't doubt the truth of their claims. I looked at https://cdn.fosstodon.org/media_attachments/files/112/877/47... and I see the bandwidth used. But like I said,
>I'm not saying my dozens of run-ins with the anthropic bots (there have been 3 variations I've seen so far) are totally representative,
My take here is that their one limited experience also isn't representative and others are projecting it on to the entire project due to a shifting cultural perception that "scraping" is something weird and bad to be stopped. But it's not. If it were me I'd be checking my webserver config to be sure robots.txt is actually being violated. And I'd check my set per user-agent bandwidth limits in nginx to make sure they matched. That'd solve it. I'm sure the mastodon software has better solutions even if they haven't solved their own DDoS generating problem since 2017 (ref: https://github.com/mastodon/mastodon/issues/4486)
Ah, thanks, I could only read the main/single mastodon post properly since mastodon v4 is javascript only and I was reading the HTML source meta-content field. This does not show replies or linked postings.
I don't know if I should Block Claude. I think it's really good and use it regularly and I think it's not fair to say that others should provide content.
Which isn't the case for the extreme majority of all websites? We're talking about ifixit.com here, a random guide page (so quite heavy in pictures) is only 6.8MB.
I think they'll survive this massive DDOS of 76MBPS.
Same in the case of ReadTheDocs which was linked above, 10TB of traffic over 6 days, an incredible 19.29MBPS sustained. Has humanity even built technology powerful enough to handle this massive assault?!
{kind=link}
Bytedances crawler (Bytespider) is another one which disregards robots.txt but still identifies itself, and you probably should block it because it's very aggressive.
It's going to get annoying fast when they inevitably go full blackhat and start masquerading as normal browser traffic.