The annoying thing about trying to implement a Docker registry on Workers and R2 is that it's so close to having everything you need, but the 500MB request body limit means Workers is unable to accept pushes of layers larger than 500MB. The limit is even lower at 100MB on the Pro plan[0].
We are running a registry that does store content on R2[1], and today this is implemented as the unholy chimera of Cloudflare Workers, AWS CloudFront, Lambda@edge, regular Lambda, S3, and R2.
Pushes go first to CloudFront+Lambda@edge, content is saved in S3 first, then moved to R2 in background jobs. Once it's transited to R2, then pulls are served from R2.
I would so love for Workers + R2 to actually be able to accept pushes of large layers, unfortunately I have yet to talk to anyone at Cloudflare who believes it's possible. Especially in this era of AI/ML models, some container images can have single layers in the 10-100GB range!
It’s trivial to set up a self hosted docker registry on your own storage. I’m running the helm version of it on my own k3s cluster, the cluster itself costing 20€/mo.
Why would you need all of this fancy vendor lockin when a few low cost ARM boxes can get the job done?
Because I actually want it to serve 10GB container images to our "enthusiastic" users over the Internet.
Oh, and our "enthusiastic" users want to pull it on 100s of boxes at the same time. What are you going to do? Send a legal notice to them for "DDoS"-ing your poor low cost ARM boxes?
I should preface this by saying that I figure you know all this, but I'm laying it out anyway. :)
Theoretically (I haven't read the parent article yet) it's just GET and HEAD requests for a Docker Registry[1], so if CloudFlare or another CDN supports large binary files, you could cache the images from the low cost box.
That said, obviously I'm suggesting adding "cloud" CDN infrastructure to your tiny ARM box. In a more normal scenario, most would probably pick a free Docker Registry and just upload a mirror of the images to multiple registries to spread out the bandwidth load. E.g. Docker Hub, GitHub, etc.
For a better solution, don't serve 10GB container images. Instead, start from someone else's 10GB container image and add the layers you need on top of it. Or consider a solution where you don't need to ship 10GB of data in your application, but could perhaps side-load only the necessary data.
Another workaround: because Docker images can be pushed and pulled with identical signatures, it's also possible to encourage your end users to keep their own Docker registry of the image and refer to it from an internal or private copy of the image. This is a best practice for pretty much every kind of production deployment of a Docker container, so you don't have 100s of boxes pulling from your shared infrastructure, and leads to more reliable Docker deployments. An example is, in fact, pulling an image - because it stores a copy locally that you can refer to and run multiple containers at the same time from one local image. Pretty much every container image deployment I refer to in production, I prefer to use a privately mirrored copy instead of pulling from a source repository directly. Maybe it's just me? :)
> For a better solution, don't serve 10GB container images. Instead, start from someone else's 10GB container image and add the layers you need on top of it.
This is assuming I'm not shipping 10GB of novel bytes, but in (2024's) reality quite some people ship model files in container image, guess how large they are :p
> it's also possible to encourage your end users to keep their own Docker registry of the image and refer to it from an internal or private copy of the image
Of course. Or I can just piggy back on Cloudflare until they decided to stop the party. Sounds much easier for my casual users.
For serious users they setup internal mirror anyway so I don't need to encourage someone over the Internet which is hard.
Docker gives you everything you need to cache a build and keep the final image small: multi-stage builds, layer caching, build caching (cache-from/cache-to).
It's more recent of course, so there are a lot of docker images out there that don't contain any of that.
As to my original point, for purely internal purposes you can self-host for a pitiful cost. You're not going to open that to the internet and start running a public registry from it, but it's a trivial setup, easy to integrate with (not abstracted through cloud IAM setups) and cheaper than paying SaaS for it.
The specs of the box are the least of your worries at that point. You tell your enthusiastic customers to set up a pull-through cache, because with that kind of traffic, you're going to pay through the nose for egress on typical cloud providers, unless you can guarantee that your users are collocated.
Yeah in our case we are operating a private registry on behalf of our customers, so slightly different use-case than running your own registry for your own internal use.
Uploading in chunks could definitely solve the issue, and the OCI Distribution Specification does actually have some language about an optional chunked push API[0].
Unfortunately very few of the registry clients actually support this, critically containerd does not[1], so this means your regular `docker push` and a whole lot of ecosystem tooling does not work.
This also means that the single PUT must be able to support very large pushes as a single request, possibly even larger than what R2 or S3 would allow without using multipart upload. This means you actually need a server to accept the PUT, then do its own chunked upload to object storage or otherwise stage the content before it's finally saved in object storage.
This rules out presigned URLs for push too, since the PUT request made to the presigned URL can be too large for the backing object storage to accept.
There's also other processing that ideally happens on push (like hash digest verification of the pushed layer) that mean a server somewhere needs to be involved.
Once again i would like eastdakota to respond to this sales tactic. Surely this can't be a double-digit driver for revenue to where he must stay silent on it.
If you read the article, the OOP was running a gambling site so it is fairly reasonable for Cloudflare not to want their IP blocks to be associated with that.
It’s a communication failure on CF’s end, but it’s not an ordinary situation.
And all of that is fine when communicated properly. Even if OP is an unreliably narrator are we to believe they also left out some of CF's emails?
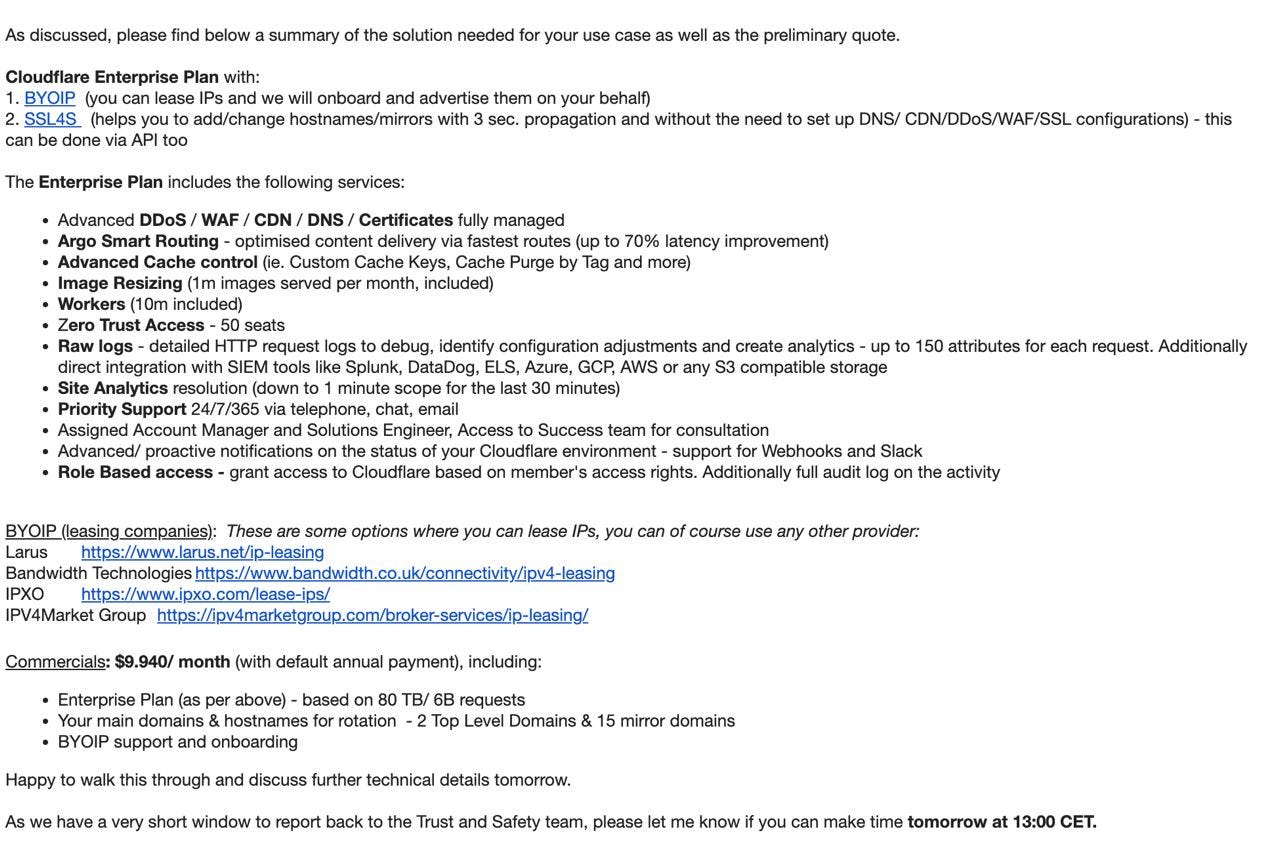
To me it looks like https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_pr... is entirely the wrong email to send in the situation and if you are as old as I am and come from where I come from, you will have flashbacks to "reading between the lines" of the party daily in the 1980s. The real content is at the bottom:
> As we have a very short window to report back to Trust & Safety team, please let me know if you can make time tomorrow
Big red flashing lights: the right questions are 1) why is T&S involved at all 2) What are their concerns which forces such a hurried deadline? 3) What are the consequences of missing this deadline.
The right email would start with something like this:
> Providing services to your business constitutes serious legal risk to Cloudflare. We are happy to work with you in the future if you are buying an Enterprise plan. As we need to commit significant resources to accommodate you, we need an annual commitment. Otherwise, with much regret we need to terminate our services provided to you as it is our right per Terms on date/time. ("We may at our sole discretion terminate your user account or Suspend or terminate your use or access to the Service at any time, with or without notice for any reason or no reason at all.")
I did read it and understand that they are running a gambling site. CFs handling of it though where they instead took this as an opportunity for high pressure upsell is the scummy part.
Why wouldn’t they allow them to pay monthly for enterprise? This would allow them to use their own IPs, eliminating the risk to CF, and allow for an orderly migration off the platform if they wanted. Forcing an annual contract with a massive price tag is again just scummy sales tactics.
Also after reading that and searching a bit it looks like this isn’t the first time that CF has had these types of “communication failures”.
EDIT: a few words to clarify what I meant on the lack of a monthly option in this exchange.
Ten thousand percent. When I read the article earlier they made the email something to the tune of "CF engineering says your account is seriously messing up our network. contact us to resolve this"
and it was a sales call. scummy as hell to get your kpis
> We are running a registry that does store content on R2[1], and today this is implemented as the unholy chimera of Cloudflare Workers, AWS CloudFront, Lambda@edge, regular Lambda, S3, and R2.
What’s the advantage over just using ECR? Cost of storage? Cost of bandwidth to read? Hosting provider genetic diversity?
ECR is slow. Despite being a static datastore presumably backed by S3 it will only serve container image layers at around 150mbps, when dealing with large (10GB) container images this is a problem. R2 will happily serve the same data at multi-gigabit speed.
Data transfer costs. Our registry is for our customers, and they expect to pull their images from environments outside AWS, e.g. GitHub Actions.
If that customer has a 2GB image, they want to build the image and then pull it into 10 separate matrix jobs (think like parallel Cypress tests), and they have 1,000 commits in a month, then the AWS data transfer costs are $1,800/mo, just for that one customer to pull their images.
With R2, it acts both as a CDN and since Cloudflare does not charge for egress, reduces the cost to only storage + the one-time transfer out of AWS.
OCI is demonstrably broken as a specification body as demonstrated by the referrers API. Distirbution spec as it is at the moment is just a very poorly written technical doc.
How's the pricing with low usage? I suspect this is great. I wanted an image registry so that I can use it to deploy with Kamal, but the $5 plan is overpriced, given I push an image maybe once every 3 months. This could solve that
I don't use much of CloudFlare services but it seems kinda cheap, $0.015/GBmonth for storage (+10GB free), Workers are charged per request and CPU time, both of which would probably be quite low for a registry so free plan would go quite far?
I just set up the official registry on a VPS (for similar usage pattern) and it was a bit of work and probably much more expensive, this seems quite attractive unless I've misunderstood something.
Yeah it does sound great.
The alternative for me is to host my own docker registry on my home server. That would cost me 0 essentially (I have good internet at home)
I think this is wonderful. I’m running a Gitea instance in one of our dev machine just for private registry. Keeping the instance only had been extra workflow for us.
But 500MB limit of layer size is a dealbreaker for AI related workflow.
I’m self-hosting gitea just for their private docker registry. LFS is actually slow for heavy deep learning workflow with millions of small files. I’m using DVC [1] instead.
Have any container running tools just implemented basic S3 compatibility for pushing/pulling images? If your registry doesnt accept pushes from untrusted sources, it doesn't seem like there is a ton of value in having "smarts" in the registry server itself.
When you push, the client could just PUT a metadata file and an object for each layer in the object store, and pulling would just read the metadata file, which would tell it where to get each layer. And could use etags to skip downloaded layers that have already been downloaded.
For auth just use the standard S3 auth.
Would be compatible with S3/r2/any other S3-compatible storage.
I'm using this registry with regctl[0] to chunk uploads (to circumvent 100MB limit), works just fine for huge layers with models.
With regctl you will also get 'mount' query parameter for upload initialization with the proper blob name so you can skip additional R2 copy when multi-part upload finalisation which speeds up the upload (and avoids crashes on larger blobs).
This is not part of docker registry API, so I never got to PR that.
When you switch to private Docker or Github registry to Cloudflare, are you effectively just trading one vendor lock in to another, or is there more into this?
None of these are really vendor lock in. The registry protocol is an open standard, this is just one more source that implements it. So you’re only locked in as far as your data is stored somewhere, but that data is behind an open API, so minimal risk there.
I would have thought for sure someone would have already tried that, but regrettably trying to search for "serverless git" coughs up innumerable references to the framework that is hosted on GIThub
I actually prefer their second scenario of splitting out access to the objects and pack files but since doing that would still require a function (or, ahem, a web server running) I suspect that optimization is not within the scope of what you had in mind
{kind=link}
We are running a registry that does store content on R2[1], and today this is implemented as the unholy chimera of Cloudflare Workers, AWS CloudFront, Lambda@edge, regular Lambda, S3, and R2.
Pushes go first to CloudFront+Lambda@edge, content is saved in S3 first, then moved to R2 in background jobs. Once it's transited to R2, then pulls are served from R2.
I would so love for Workers + R2 to actually be able to accept pushes of large layers, unfortunately I have yet to talk to anyone at Cloudflare who believes it's possible. Especially in this era of AI/ML models, some container images can have single layers in the 10-100GB range!
[0] https://developers.cloudflare.com/workers/platform/limits/#r...
[1] https://depot.dev/docs/guides/ephemeral-registry