Node benchmark is flawed though. Add something like
require('http').globalAgent.maxSockets = 64;
at the top of node script if you want a fair comparison with async php version. The bottleneck is bandwidth here. Not the runtime.
On my laptop, original script from the author took 35 seconds to complete.
With maxAgents = 64, it took 10 seconds.
Edit: And who is downvoting this? I just provided actual numbers and a way to reproduce them. If you don't like how the universe works, don't take it out on me.
> agent.maxSockets: By default set to 5. Determines how many concurrent sockets the agent can have open per host.
This stops you accidentally overloading a single host that you are scraping. It would not (assuming it works as described) affect your app if you are making requests to many hosts to collate data. Many applications (scrapers like httrack for instance) implement similar limits by default. If you are piling requests onto a single host but you either know the host is happy for you to do that (i.e. it is your own service or you have a relevant agreement) or have put measures in place yourself to not overload the target then by all means increase the connection limit.
You're close, but the rub is, every single http request uses the same agent (globalAgent), unless specifically passed an individual http agent or "{agent: false}" in configuration. So it is effectively a global connection pool. This has caused all kinds of performance issues in production applications. It can be easily shut off but it is easy to miss in the docs. The default of 5 has met its demise in 0.11 - the new default is Infinity.
Nobody should be downvoting you, you raise an excellent point and you are of course right.
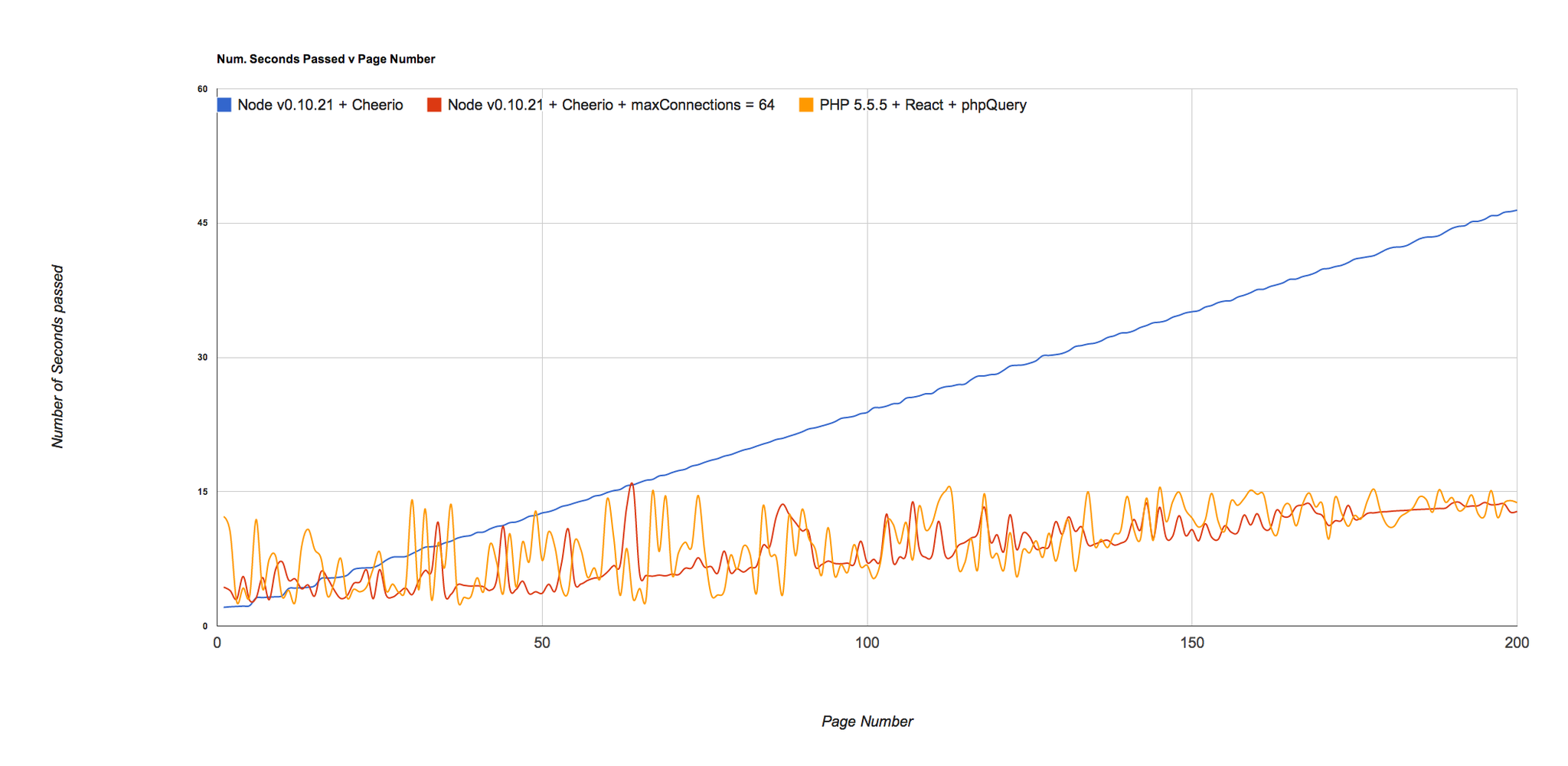
NodeJS v0.10.21 + Cheerio
real 0m47.986s
user 0m7.252s
sys 0m1.080s
NodeJS v0.10.21 + Cheerio + 64 connections
real 0m14.475s
user 0m8.853s
sys 0m1.696s
PHP 5.5.5 + ReactPHP + phpQuery
real 0m15.989s
user 0m11.125s
sys 0m1.668s
Considerably quicker! As I said I was sure NodeJS could go faster, but the point of the article was that PHP itself is not just magically 4 times slower, it is in fact almost identical when you use almost identical approaches. :)
> Update: A few people have mentioned that Node by default will use maxConnections of 5, but setting it higher would make NodeJS run much quicker. As I said, im sure NodeJS could go faster - I would never make assumptions about something I don't know much about - and the numbers reflect that suggestions. Removing the blocking PHP approach (because obviously it's slow as shit) and running just the other three scripts looks like this:
The article starts the loop though. If tuning one setting is a black are that an inexperienced dev would miss (which it of course is, I don't disagree at all there), then drawing in a new library to work around the limits (in this circumstance) of file_get_contents() is very much so too.
Neither the original benchmark nor the response were well researched IMO. This is the Apache vs IIS wars again, where good benchmarks that reveal useful information were drowned out by the noise of a great any poorly executed (or sometimes completely biased and deliberately poorly constructed), with bad test resulting in a bad result for one side being followed by an equally bad test to try prove the opposite.
The point was that NodeJS and PHP were pretty close, and I posted (before the update) that I'm sure Node could go quicker.
You run either of them in suicide mode to RUN ALL THE CONNECTIONS and you'll get a speed up. The point is that NodeJS is not magically 4 or 5 times faster than PHP, they're about the same when you the packages you use support the async approach. This update proves they're exactly the same, but similarity is all I was going for.
This is already why the author did though; the original benchmark that he replied to used Cheerio vs. phpQuery, but he rationalized that that was a losing battle anyways, and decided to test Cheerio vs. ReactPHP -- which requires a non-standard PHP extension called libevent.
Default is 5. Should be just fine if you don't have a specific use case that would require higher limits.
If so, just crank it up, should be safe unless you assign Infinity or something like that and push it too much (then you have another problem though). We use 15 in production where our server parses a lot of external web pages.
The new default in master is Infinity. (Also, there's opt-in KeepAlive that actually keeps sockets alive even if there are no pending requests.)
The ulimit will prevent you from opening up too many anyway. The HTTP Client is not the correct place to implement job control and queueing with such a low limit by default.
First things first, IsaacSchlueter in the thread, wow :)
So, I'm stress testing our company Node app to find where we can go with it's performance. First problem was file descriptor, which I fixed with your "graceful-fs" module.
But now, I'm reaching some "invisible" limit that I can't identify. My app doesn't return any error in the log.
Does "maxSockets" will help to receive more requests also or is just to make requests?
What performance problem with FD? How many requests exactly are you handling per second with what code or processing? Are you sure its not what he just mentioned, ulimit? The docs say client requests so yes its just to make them.
Why do you need to handle 5k requests simultaneously? Maybe you mean per second? Maybe you can add a server and do round-robin DNS? Then you will he able to do double unless there is a database bottleneck or something. But you said concurrent which 4k really concurrent is asking a lot.
Currently, we are with a C# application and in the process to migrate to Node.js. I wan't to prove that Node.js can handle huge concurrency, so I wan't to benchmark the highest possible numbers I can. We are currently usign AWS to load balace.
And it's being a great exercise anyway.
We are using Redis for session store. Do you thing raising this parameter can influence on Redis performance? Because in the Redis server, the service is only using 5% in process, when Node.js is 99%.
If we really want to get into benchmarks LuaJIT with multithreading is almost 2x faster then both, it took 21 seconds to complete on my computer. And I'm willing to bet that multithreaded C would be even faster.
However you want to know what this benchmark proves? Absolutely nothing as it has to query a website. So the response time of the website matters more then this test.
Long term php guy (I maintained APC for years, slowly given up now), so I've worked a lot with ~2k/3k request-per-second PHP websites.
The real trick here is async processing. A lot of the slow bits of PHP code is people not writing async data patterns.
If you use synchronous calls in PHP - mc::get or mysql or curl calls, then PHP absolutely sucks in performance.
Nodejs automatically trains you around this with a massive use of callbacks for everything. That is the canonical way to do things - while in PHP blocking single-threaded calls is what everyone uses.
The most satifying way to actually get PHP to perform well is to use async PHP with a Future result implementation. To be able to do a get() on a future result was the only sane way to mix async data flows with PHP.
For instance, I had a curl implementation which fetched multiple http requests in parallel and essentially lets the UI wait for each webservices call at the html block where it was needed.
There was a similar Memcache async implementation, particularly for the cache writebacks (memcache NOREPLY). Memcache multi-get calls to batch together key fetches and so on.
The real issue is that this is engineering work on top of the language instead of being built into the "one true way".
So often, I would have to dig in and rewrite massive chunks of PHP code to hide latencies and get near the absolute packet limits of the machines - getting closer to the ~3500 to 4000 requests per-second on a 16 core machine (sigh, all of that might be dead & bit-rotting now).
Something like gearman queues basically take the asynchronous processing out of the web layer into a different daemon. There were things like S3 uploads and fb API calls which were shoved into gearman tasks instead of holding up the web page.
Some of the stuff is very design oriented, for instance in most of my memcache code, there are no mc-lock calls at all - all of them are mc-cas calls. A lot of the atomicity is done by using add/delete/cas which involve no sleep timeouts. A bit of it was done using atomic append, increment and decrement as well.
SQL queries are another place where PHP doing actual work sucks for the web apps. A bunch of the mysql/postgresql functionality within a lock is actually moved onto stored procedures, instead of being driven by PHP.
So the code above is horribly written because you can't parameterize table names or column names in PL/SQL. But that essentially cuts down the involvement PHP has with the backend's locked sections.
Also a lot of the stats data was flooded onto apache log files instead of being written out from the PHP code directly using an fwrite.
This uses apache_note() function in PHP to log stuff after the request is done & the connections are closed. That gets into the log files as %(<name)n fields in the access log.
You can see there that every single access log has an associated user, the HMAC of the request and peak memory usage. All collected at zero latency to the actual HTTP call.
The thing to avoid though is pcntl - it absolutely messes up all of apache/fastcgi process management code.
This is not all of what I've done. I am sorry to say some of my best work in this hasn't been open-sourced & has perhaps been killed since I left Zynga.
PHP backends I built using these methods were handling approx ~6-7 million users a day on 9 web servers (well, we kept 16 running - 8 on each UPS).
Ah, fun times indeed - too bad I didn't make any real money out of all that.
I get sick of these language wars, especially the constant stream of PHP ridicule that just never seems to end. The positives I try to take away from all of it is that there are a lot of people that are extremely passionate about software development and are striving for better tools and ways to express themselves. I want to believe that through the vitriol encountered in some of these articles that there are people really trying to improve the technologies at heart instead of taking part of some kind of programing language apologetics. In regards to PHP, I think that the ridicule has led to improvements in the language, but the overall tone in some of these articles is still a turn off for me.
1. apt-get install php5 ? Seriously, that's it. On the other hand, neither Debian stable nor Ubuntu LTS have any usable version of node in their package repository (Debian has nothing, Ubuntu has 0.6)
4. json_decode() ?
5. If Atwood's law ever becomes reality, it will be a consequence, not a source of benefit.
(I don't use either Node or PHP as my main language)
I've developed software in Java,.NET, Php & NodeJS. I ll rate JVM higher than any other platform. But when it comes to simplicity, easy scalability, Node ranks way higher. Php isnt even closer at all.
NodeJS literally takes 5 minutes to get started writing scalable apps without even thinking about concurency at all.
Write a software in Php yourself and let people download and run themselves, there are endless pain. Actually Php sucks in many areas which I dont want to touch right now.
And so is PHP. You cannot argue that PHP is not simple, you just can't.
And frankly I like composer, sure it doesn't do C/C++ installation stuff, but PHP doesn't need that. What is does is almost identical to NPM, the only different is one looks different, and the names.
Any decent compile-time optimizer will transform your first snippet into the second one (or better). Some languages preclude that optimization at compile time, but I presume that a JIT would also have little problem performing that optimization.
That is, one could argue that a good language is one that lets developers ignore trivial changes like this without hurting performance.
More as a reference for others, this is a fun page that highlights a few interesting optimizations GCC 4.2 is capable of making: http://ridiculousfish.com/blog/posts/will-it-optimize.html Maybe the optimizer can deduce guarantees about a function, but the writers may have just included an optimization for a specific built-in because the unoptimized form is such a common mistake...
I don't see how that would work. I'd say that the two snippets describe different intentions and using one when you want the other is a case of not saying what you mean.
A function call in a loop condition might have side effects or do something very unorthodox.
Pulling redundant work out of loops is a category of optimization that is widely used. In many cases, the optimizer can detect a lack of side effects on $list inside the loop body and perform the above optimization.
The canonical PHP implementation is a simple interpreter that cannot even dream of such optimizations. Hell, it uses unions to handle dynamic typing and hash tables to represent objects.
The implementation by facebook (HipHop) might have such an optimization though.
At some point, you'd expect these arbitrary this vs. that comparisons to die off. They haven't, and I'm guessing they won't.
Basically, it comes down to picking the tool that best supports your use case, or being okay with a compromise. Like the SQL/NoSQL discussions recently... Use it poorly and you get poor results.
One might argue that Javascript is considerably less sub-par than PHP, though; speaking purely from my own experience, I've found that writing Javascript involves a significantly lower probability of the language attempting, at random intervals, to shatter my kneecaps with a crowbar.
But the reason for this wasn't that Node/JS is faster than PHP; it was because I was able to write the Node.js app asynchronously, but the PHP version was making hundreds of synchronous requests (this is the gist of the OP).
The issue I have is that Node.js makes asynchronous http calls relatively easy, whereas in PHP, using curl_multi_exec is kludgy, and few libraries support asynchronous requests.
The situation is changing, but the fact remains that asynchronous code is the norm in Node.js, while blocking code is the norm in PHP. This makes it more difficult (as of this writing) to do any non-trivial asynchronous work in PHP.
I agree that the comparisons are often unfair between languages/frameworks, and agree with everything phil says, but there is a lot to be said for language level non-blocking constructs.
I am really enjoying reading Go code and seeing how people use concurrency etc; and they are all doing it the same. When I would read ruby, I would have to know the particulars of a library like Celluloid or EventMachine which made it harder.
The "Thoughts" section was the most informative part of the benchmark which underscores the way I, when I was working with PHP, operated. When I started with PHP(2005), the frameworks were terrible, I would cobble together many random coding examples from stuff I found on the web and just make my own Framework up. I don't think PHP from a performance standpoint is any better or worse, but the default examples that you generally see in the ecosystem provide significantly worse performance. The one thing that Node clearly has an upper hand on PHP with is the ecosystem. It's a lot easier for a developer new to the Node ecosystem to hit that Node target than it would be for someone of the same skill to hit the PHP target in terms of hours spent.
One funny thing is that the ReactPHP[1] site is visually similar to the Node[2] homepage.
There are plenty (including myself), we just avoid stating it in public for fear of the instantly appearing anti-PHP trolls that lurk around every corner.
I have used RollingCurl (non blocking CURL) to fetch multiple API requests at once using PHP. Really easy to implement using a simple class. The example shows how you could build a simple efficient scraper.
A lot of the components are in production already, it was built by the original developers to be used in production. It's on 0.3.0 for many parts, which is no further behind where Node was when people started flapping about it :)
Yeah the CSS style selectors and methods are the same, I assumed he was referring to the fact that it's all JS.
When you are scraping it's great to be able to do a test run in the browser console and then just paste the code into your node script without any language porting.
It's not an argument that it's better or faster or anything than PHP, just that some find it easier to hack a scraper together in this way.
> Even if Node was 5x slower than PHP I would still go for Node because of its easy jQuery syntax
That "jQuery syntax" has nothing to do with the language itself. jQuery uses Sizzle[0], which is a CSS selector library for JavaScript. There are plenty of PHP libraries which provide CSS selectors, such as the Symfony CssSelector component[1].
The argument you really should be making is that the Javascript syntax is familiar. jQuery and it's methods for traversing the DOM can trivially be implemented in any langauge. e.g. PHP:
{kind=link}
{kind=link}
require('http').globalAgent.maxSockets = 64;
at the top of node script if you want a fair comparison with async php version. The bottleneck is bandwidth here. Not the runtime.
On my laptop, original script from the author took 35 seconds to complete.
With maxAgents = 64, it took 10 seconds.
Edit: And who is downvoting this? I just provided actual numbers and a way to reproduce them. If you don't like how the universe works, don't take it out on me.