Most of those numbers are clickable. The graphs button on the left links to a flame graph (https://www.google.com/search?q=flame+graph) Ruby calls of the page. The microscope button is a sorted listing of CPU time and idle time by file that went into the page's render. The template number links to a timing breakdown of all the partials that went into the view. The SQL timing links to a breakdown of MySQL queries for that page, calling out N+1 queries, slow queries, or otherwise horrible database decisions. Depending on the page, we'll also have numbers for duration and queries spent in redis, elasticsearch, and gitrpc.
Our main github.com stuff is pretty tied into our stack, but one of our employees, Garrett Bjerkhoel, extracted a lot of this into peek, a very similar implementation of what we have on GitHub. We use peek in a ton of our smaller apps around the company. Here's the org: https://github.com/peek
I recently developed a profiler for my company's web application. It uses dynamic introspection to profile (nearly) all function calls on the server side. It automatically picks up any SQL queries and profiles them as well. It's all packaged up in a web interface which can be invoked on any page on the site. You can see the exact queries, sort functions by time or number of calls, etc. It also shows a full reconstruction of the call tree, with individual branches expandable and collapsible.
It was a lot of fun to write and has been just as fun to use. We've found a number of simple changes that led to big performance gains on some of the pages.
If you have time I'd appreciate learning more about your tech stack and the choice to implement this yourself vs. using one of the alternatives mentioned in this discussion.
I have deployed MiniProfiler on .NET, using only the default request introspection features. I am thinking about replacing it with Glimpse, but since neither one helps anyone but the current user (no long-term monitoring) it hasn't been used much.
I've been looking at symfonfy2 to see if our team wanted to switch from codeignitor for future PHP gigs we get. Any idea why it is such a dog in the benchmarks?
Generic benchmarks are dumb. They stress just a few points of the system, you can't assert that the test case was well written, you are not sure that caching on the framework was enabled, or even configured, there's a lot of variables involved to assure that you are extracting the most in performance from a framework/language that you just don't know on those generic benchmarks.
If you want to compare performance, do it yourself, don't believe someone else's benchmarks. Write a test case that is suitable for your reality, then go for a conclusion.
The techempower benchmarks are open source. If you think it is badly written, send a pull request. Running your own benchmarks simply isn't feasible at the scale they're running them. We all benefit from a comprehensive and well executed benchmark suite.
Symfony2 is a very slow framework by comparison but it's also a very complete framework (if you like to have it all). Why it's slow in the benchmarks, I can't really answer but I know that the development enviroment in Symfony2 is very slow and I haven't met one developer who at hates Symfony2 on at least one level.
One framework for PHP developers that is worth looking into is Laravel. Very clean and reasonable framework. Have a look at it here: http://laravel.com/
Laravel has an amazing amount of noise (hype?) around it which Symfony2 doesn't (why?), but looking through the code and documentation it doesn't seem to hit my pain points or be... complete.
For example, it has ActiveRecord by default, so you're focued around data stores... ideal for CRUD, but then its libraries to generate and validate forms are like something from 2008.
I'm a bit bemused as I must be missing something, given its popularity. Perhaps the apps I build are not a good fit for it - I'd be keen to have your input.
The sparkline in the bottom status bar lets you keep an eye on server request performance (single page app), and clicking it allows to see the details of the past 100 requests, including what DB calls were made and what parameters were used (great for finding slow queries and pulling them out to test and tune in isolation). The server tab gives overall php server and database statistics.
Our product has gotten a lot faster since integrating this, and I don't think that's a coincidence. It is extremely useful, and not just for performance optimization.
Sometimes what bothers me is I sometimes have no idea if a query is slow or not. This holds more true since I've been developing on Rails with Postgres. With MySQL it seems the bottleneck queries seem a lot more exponentially progressively degrading in correlation to the amount of records in a set.
With Postgres this seems to be a lot more linear.
I have just made some crafty work in rails to make use of hstore datatypes in Rails. It stores an array of hashes, which I have not found a way to index the keys of yet.
Is this slow or fast for example?
I'm doing a full-text search over all unnested (hstore) array values over a given column in a table wih 35k records.
development=# SELECT "leads".* FROM "leads" WHERE ( exists ( select * from (SELECT svals(unnest("address"))) x(item) where x.item LIKE '%mst%') );
Time: 57.257 ms
I'm used to MySQL, and this kind of query over unindexed records seems fast, but it also seems this might be slow for Postgres standards ?:/
Bear in mind.. no indices.
Yes! haven't dived into it, but the possibility made me go for it regardless. Have been quite impressed with pg's performance with a lot of things you wouldn't want to mess with in mysql.
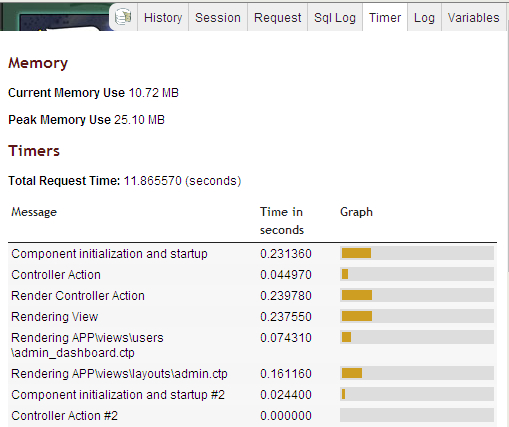
Great tip! For rails devs, I strongly recommend rack-mini-profiler [0]. It gives you an in-browser view of rendering time (which you can expand to break out by partial) with query time listed for each query. Each query also includes a stacktrace to make it easy to fix offensive queries. Great for identifying N+1 query bugs as well. There's a railscast for it, too [1].
With particular reference to database queries, if you're using .NET with SQL Server you're better off keeping the SQL Server Profiler open on one monitor with:
* Showplan XML (Statistics Profile)
* SP:StmtCompleted
* SQL:StmtCompleted
(I think there's an RPC:StmtCompleted that's useful in some circumstances but I don't use it.)
Personally I pay more attention to the execution plans [1] than execution times, unless you have lots of data (indicative of what's on your production database) in your development database all your queries will complete quickly (table scans, nested loop joins and all).
You also see the N+1 problem very quickly when you're presented with a wall of trace results.
This isn't a silver bullet, but it's been a very long time since I've let any significantly suboptimal query get to production.
[1] Some difficulty arises with small development databases, because SQL Server will frequently scan a clustered index instead of a non-clustered index + clustered seek/key lookup because it's quicker to do the one thing. In this case you have to understand that the query is not bad and treating the clustered index scan as "bad" is not correct.
Unfortunately you have to buy a commercial solution to easily monitor and report what everyone is experiencing; these tools report on the current user.
MiniProfiler- https://github.com/MiniProfiler/rack-mini-profiler- from the Railscast[0]- "MiniProfiler allows you to see the speed of a request conveniently on the page. It also shows the SQL queries performed and allows you to profile a specific block of code."
Bullet- https://github.com/flyerhzm/bullet- from the Railscast[1]- "Bullet will notify you of database queries that can potentially be improved through eager loading or counter cache column. A variety of notification alerts are supported."
If you do significant work with databases, you should have a DBA.
When I was in that role, I combined education, public humiliation, cajoling and various administrative means to discourage bad database behaviors or optimize databases for necessary workloads. The median developer can barely spell SQL... Adult supervision helps.
Whatever I was making then, I probably recovered 3-5x my income by avoiding needless infrastructure and licensing investments.
Jokes aside, I still think profiling is a great idea here. Even if you're not responsible for writing the database portion, it's important to see how much time those calls are taking.
If there is a python dev who wants to port MiniProfiler to python, I would love to help (I'm a MiniProfiler maintainer and did the go port). The UI is all done, you just spit out some JSON and include the js file. Kamens has a good port, but it's not based on this new UI library.
I wrote sqltap not too long ago to solve this problem for users of SQLAlchemy, complete with pretty web UI for visualizing not just the queries, but also where they originated in the application:
It also lets you dynamically enable/disable the introspection so you could run it in production.
I have the following on localhost at the bottom of every page:
<!--
head in <?php echo number_format($head_microttime, 4); ?> s
body in <?php echo number_format(microtime(true) - $starttime, 4); ?> s
<?php echo count($database->run_queries); ?> queries
<?php if (DEBUG) print_r($database->run_queries); ?>
-->
Example output:
<!--
head in 0.3452 s
body in 0.7256 s
32 queries
Array(
[/Volumes/data/Sites/najnehnutelnosti/framework/initialize.php25] => SELECT name,value FROM settings
[/Volumes/data/Sites/najnehnutelnosti/framework/initialize.php45] => SELECT * FROM mod_captcha_control LIMIT 1
[/Volumes/data/Sites/najnehnutelnosti/framework/class.frontend.php123] => SELECT * FROM pages WHERE page_id = '1'
[/Volumes/data/Sites/najnehnutelnosti/framework/class.wb.php96] => SELECT publ_start,publ_end FROM sections WHERE page_id = '1'
[/Volumes/data/Sites/najnehnutelnosti/framework/frontend.functions.php28] => SELECT directory FROM addons WHERE type = 'module' AND function = 'snippet'
...etc
)
-->
The array keys are the file from which the query originates with line number and the value is the query. I made it due duplicate queries.
Query method in my class.database.php for the above output:
public $run_queries = array();
Nice, but if the same line of the same file makes the same query more than once (e.g. it's inside a function that is called multiple times), it will overwrite information about previous queries because the array key will be the same.
We've been using NewRelic at my work for a few months now and this is capability is incredibly helpful. When a page is slow you can see which of the numerous queries may be at fault (or if it's being spent in code Ina bad loop, etc.)
That's a fine and good idea, but don't exclude the front end time.
SQL servers can be faster places to carry out certain types of operations on data, and it may be quicker to write the right kind of query for the server, than choose a very quick query and have to spend time on the front end processing that data.
The ultimate goal is time to eyeballs, not fastest query time. The best achieve that is to measure every stage not just queries, and spend time profiling and experimenting with various operations.
CakePHP has the DebugKit Toolbar[1] which I've ported internally to our symfony application at work (it's quite a bit better than the symfony debugbar).
This is okay, but what about showing the actual queries? What about showing how long each query took? I wrote some code that actually logs all this information directly to Chromes Console log. Pretty awesome: http://bakery.cakephp.org/articles/systematical/2013/05/08/h...
Yep that's how it works. Should be libraries for other languages too. I also log php warnings and errors to chrome as well. Very handy. Funny how hacker news works. Not sure why this post got homepage...Very basic.
I've been fortunate enough to work for a company that develop performance monitoring so I always dogfood the latest cutting edge stuff that we do.
Best part of the performance monitoring is that if the Request spans multiple Servers (load balancer/proxy, web-app, microservices, DB, etc), I can see it as a single transaction so that I can easily track down which Microservice that caused the performance slowness. For example, we have a web-app written in Python and a Microservice written in Java. A single request can end up at the Microservice level and our tool can see truly end-to-end => load balancer to web-app to microservice to database.
On top of that, we also have an app that performs synthetic monitoring where I can set to automate certain User workflow and set it to run every 5 minutes. Combining both performance monitoring and synthetic monitoring give us a leg up on automating performance monitoring!
New Relic's application monitoring and transaction traces were invaluable for us. For particularly slow transactions it provides a detailed view of the time spent in each function call and each SQL query.
If you're rolling an SQL timer of your own, be a bit careful. On most relational databases it's quite possible for your first result(s) to come back extremely quickly, but additional processing to be required to retrieve subsequent results - effectively a lazy evaluation. If you measure time to first result you may get an inaccurate picture of the cost of certain classes of query.
From the Readme:
This WordPress plugin allows you to easily place various development notes throughout your website. The development notes will appear on your page and the browser's console only when:
* You are working on your local development environment.
* You are logged into WordPress.
* ?devnote is appended to the URL.
One of the features is that it display in the page's footer the total number of SQL queries performed on the page and the total time required to generate the page. It also displays every SQL used to generate the page.
There are a few other features such as colour-coded CSS debugging, etc.
In addition, I would track with a web analytics tool the number of queries and the time they took for each page, so I could easily have them as metrics in the Pages Report.
Next, sort pages by query time and optimize them first.
Has anyone got a way to do this for API calls? I'd love to be able to get some json back at the end of a call that shows how many queries/how long they took.
More often than not, the slowness end users experience is problems in the front end - not the database. Think uncompressed assets, cache misses, or unused javascript and stylesheets. It's very likely most pages in your application are (or should) be served entirely from cache, so end users will benefit much more from front end optimizations.
This statement is dangerously false. Unused javascript and stylesheets is where you would start your performance debugging when users complain of slowness ?
{kind=link}
{kind=link}
Here's a screenshot expanded version of our staff bar on GitHub.com:
http://cl.ly/image/0O0N183x2F44
Most of those numbers are clickable. The graphs button on the left links to a flame graph (https://www.google.com/search?q=flame+graph) Ruby calls of the page. The microscope button is a sorted listing of CPU time and idle time by file that went into the page's render. The template number links to a timing breakdown of all the partials that went into the view. The SQL timing links to a breakdown of MySQL queries for that page, calling out N+1 queries, slow queries, or otherwise horrible database decisions. Depending on the page, we'll also have numbers for duration and queries spent in redis, elasticsearch, and gitrpc.
Our main github.com stuff is pretty tied into our stack, but one of our employees, Garrett Bjerkhoel, extracted a lot of this into peek, a very similar implementation of what we have on GitHub. We use peek in a ton of our smaller apps around the company. Here's the org: https://github.com/peek