I just use | perl -pi -e 's/foo/bar/g' , etc for this kind of stuff. Is there anything I can't do with perl on a line that sed will do? I can see how perl is a lot more complex than sed, but I went through the whole perl learning curve back in the late 90's so it doesn't bother me that much..
Wait, why not just use awk? It can do pretty much everything the other two do (and can, like sed, be used to replace other things (like 'head')) and runs faster than perl at some things. (https://news.ycombinator.com/item?id=8858342)
I learned awk in school, and like it. But I like to choose tools which increase programmer-efficiency before machine-efficiency. Perl is just one tool and one easy syntax to learn. Its regex language is now the standard as well.
Only if runtime efficiency turns out to be too slow would I re-examine choice of tools. This is like avoiding premature optimization.
(I've never found perl to be too slow in practice, btw.)
It's a lot easier to delete specific lines using sed. Also you can have sed do replacements to the n'th instance of something. Doing that in Perl is a bit more complicated and a lot less succint.
The Rakudo Perl 6 compiler is still immature and slow, and the -i option (in-place edit) hasn't yet been implemented, but, at least for comparison's sake:
$ perl6 -pe 'next if ++$ == 2' example.txt
... prints all lines except line 2.
This is an example from Perl 6 One Liners[1].
The `$` is just just an unnamed variable that is getting incremented once per evaluation (-e is for `evaluate`) which in this case happens once per line (-p is for printing each line of input after eval'ing the code -- unless a `next` applies, in which case that line gets skipped).
P6 regexes are far easier to read and way more powerful than P5 regexes. The `:3rd` bit is a general language feature called "Adverbs", in this case applied to the regex focused s/// built in.[2]
"I asked on a forum what the goals are for relative size and speed of Perl 6 vs. Perl 5, and a Perl 6 developer responded that a reasonable goal would be to have Perl 6 be twice as big as Perl 5 and take twice as long to start up.
"To achieve this goal, the Perl 6 developers will have to shrink the program size by a factor of 6.1 (that is, get rid of about 84% of the code.) They'll need to reduce startup memory consumption by a factor of 13.7 (that is, cut out 93.7% of their memory use) and reduce startup time by a factor of over 275.
"Oh, and this is after they add in all the missing features required to bring Perl 6 up to production-level."
> "... all the missing features required to bring Perl 6 up to production-level."
The latest story is that the last major missing features (Unicode grapheme-by-default and native arrays) will land in the next few months and Perl 6 will be declared "officially ready for production use" by the end of 2015.
Probably not, but in some cases sed and AWK might be faster. I am a big fan of AWK. It is limited in some ways that make it impractical to use for really serious programs, but it is very expressive. Look at [1, 2].
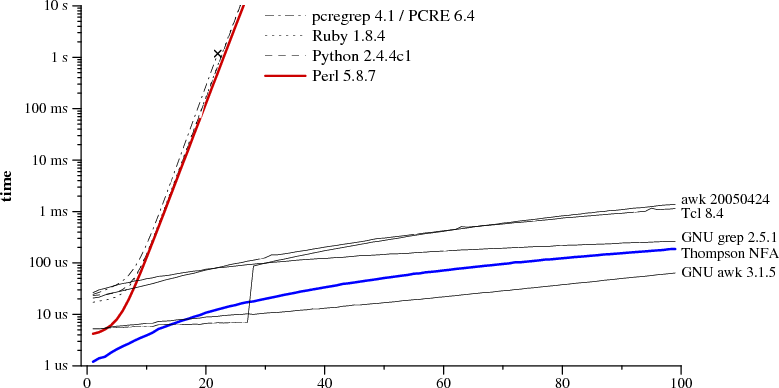
I have tested converting sed/awk lines to perl in a few base scripts that worked on a fairly large amount of data. Oddly enough, in every case, perl 5.18 performed at LEAST 1.5x faster, sometimes as much as 3.5x faster. Obviously anecdotal evidence, but recent versions of Perl seemed to have gained some good speed.
I've had a similar experience, with Perl up to about 7x faster. I had sed in a few data-mangling pipelines because I assumed simpler=faster, but replacing it with Perl was either a wash or a speedup in every case. This with the versions of perl and sed in Debian (looks like it's GNU sed), so ymmv with other seds.
The case where I saw a 7x speedup was doing many-times-per-line, fixed-string search/replace on a file consisting of very long lines (an SQL dump where some lines had >1m characters). Perl was IO-bound (so presumably would've been even faster if I'd had better disks), while sed was CPU-bound at a pretty low fraction of the possible IO performance.
EDIT to manage expectations: the article doesn't explain why, it just provides benchmarks and one commenter made a suggestion about character handling. More insight still welcome :)
There are many different versions of awk: gawk, (BSD) nawk, mawk, etc. I think OS X uses nawk, but mawk is reputedly faster. Gawk is definitely slower than both mawk. I'm not surprised that Perl is faster though.
I'm a firm believer that there are many ways to work effectively. If Perl fills the same needs for you that sed does for some people, then by all means stick to Perl.
However, for someone who knows neither, here are some reasons you might want to choose sed over Perl:
1. sed syntax is pervasive in other tools. For example, to run a substitution from early on in the tutorial in vim, type :%s/abc/(&)/<enter> from insert mode.
2. sed is simpler than Perl. It used to be that Perl filled a unique role as a scripting language but now there are a bunch of languages in that space (most notably Python and Ruby). Python + sed for example would fulfill most of the same functions that Perl does (and there are reasons to choose Python over Perl as scripting languages, although that's a much more complicated domain to discuss).
3. sed is more performant (or so I hear). This has never been a real concern for me, but some people cite this is a concern.
4. sed usually is a bit more terse. For the length of expressions you'll typically be writing with sed, this isn't a big concern.
Disclaimer: There are probably good reasons to choose Perl over sed, too. Not being a Perl guy, I don't know those reasons. I'll leave that to someone who knows more about Perl.
When I learned sed it was because I was taking a *nix class in college, and a professor pointed me at sed and not Perl. I learned sed instead of Perl because it was put in front of me, not because of any weighing of pros and cons. That's how a lot of learning happens. Sometimes simply learning what's put in front of you leads turns out to be an obvious mistake in retrospect (I was stuck writing VBA for a little while). I don't know whether learning Perl or sed is better for what sed does, but I do know that after maybe 6ish years using sed quite frequently it hasn't turned out to be an obvious mistake.
I am always amazed by how much people can get done using piped unix commands - but, personally, I find it much easier to just use sed when I need to quickly edit a few files, and if I need to do anything slightly more elaborate, to do it in Python with a script.
It's obviously much slower - but I've never been in a position where I needed insane speed to quickly fix a bunch of files.
I'll sometimes use sed/awk/cut/etc... to get one off summary info out of large files. Excel/LibreOffice would choke, and loading it into a database for one off is painful.
The nice thing about these tools is you can count on them being on any unix machine w/o worry about installing them on a remote locked down box of some kind. You can also avoid any dependency complexity. They can be real awkward to remember however and the man pages can sometimes be a handful, so I try to store common idioms in gists or in my .bash_profile whenever I develop one.
With regard to cross-platform compatibility, it's worth knowing some of the basic differences between GNU sed and BSD sed. I like the GNU extensions -- particularly the extensions to regular expression such as non-printing characters (e.g. `\t`) and character classes such as `\w` and `\b`. I almost always use the GNU `-i, --in-place` option once I'm satisfied that my sed commands do what I want. A couple of years ago, I was using my other half's Mac (OS X 10.4 with a very old version of BSD sed) and I really missed the GNU extensions.
When you say you store common idioms in your Bash profile, do you mean storing the commands as Bash aliases or functions? I have similar issues with remembering syntax and building sed commands and I've been trying to do something similar to avoid spending time building a complex command from scratch when I already created a similar one some time previously.
I usually store things as aliases...and while sometimes I don't end up using the alias exactly having a useful name that describes what it does helps me tailor the command later on. For example I have the following alias 'watch_port' that looks like this:
so `watchport 8080` will print all network traffic over port 8080 on my ethernet. I actually rarely use this as 'watch_port' directly, but it helps me remember quickly how to bend ngrep to my needs.
Thanks for the response. I used to keep a list of long commands that I had constructed in a plain text file, titled `useful-commands.txt` but that became too unwieldy. Now, similar to you, I try to store them as aliases – even if I don’t use the command exactly as it was saved. The hard part is coming up with a good, succinct name (descriptive but not too long) for the alias.
For a long time, I didn’t like using aliases because I didn’t want to become overly reliant on my custom aliases – and then miss them when working on an unfamiliar system. This generally worked out alright when I was able to use `Ctrl-R` with a large Bash history. Now, I think that was an irrational rationale and that aliases are very useful shell features. I’m currently trying to organise my aliases and functions into useful groups such as `home_aliases.sh`, `cygwin_aliases.sh`, etc. so that they can be loaded as needed. I then plan on adding them to a git repository so that they can easily be used – and updated – on different systems.
BTW, thanks for letting me know about ngrep. It looks like a useful complement to tcpdump.
Maybe it's because Perl was really popular at the time I discovered Unix and its tool, but why would you use sed and awk instead of a Perl one-liner? (Or even :s// in vim or M-x query-replace-regexp in emacs, if it's just regex munging)
Perl isn't included in e.g. BusyBox. The additional overhead of including perl in an embedded distribution could be a valid reason for using sed where you could otherwise have used perl.
I tried posting this to /r/programming. It said already submitted 8 years ago. It's a very good tutorial and I was oblivious of its existence for so long.
To be honest I don't know how much he has improved on the manual. It is such a small language that you could easily read up to the the examples very quickly even if you aren't particularly interested in learning.
Though be forewarned, something that neither document explains well is the actual syntax. As in how addresses and expressions can be used and how to read a script. The syntax is relatively simple to understand looking at some examples, but the lack of clear delimiters between the address, command, and command parameters can confuse beginners.
Well, it does mention explicitly which parts are GNU extensions. But I see what you mean. I can write sed scripts fairly well at this point but clearly didn't internalize any of the notes about what is an extension, thus it is frustrating trying to get the non GNU versions to do anything at all.
Peter Krumins also has decent a walkthrough of sed that essentially goes through and explains it via detailed explanations of sed one-lines (The explanations are original, but the list of one-liners was already popular on the internet).
This was written in 1984 (I think) and still works with a few syntax adjustments. I think it is not bad discipline to return to these tools from time to time and remember core UNIX principles.
A friend of mine has been trying to get me to learn awk, sed, perl or grep. Honestly I only have the patience for one at the moment, which do you think is the best (taking the ease of learning into account)?
You don't, it's a readline thing, it doesn't really generate a file you can manipulate. (I expect to be proven wrong with some insane one-liner though).
What you can do is press Ctrl-R again and it will search the older match. There's also forward match but I can't recall the shortcut.
was interested in reading this until i saw the yellow background and couldnt stomach it - looks like a lot of great information just displayed in a horrible way
If it's available on your platform, you could print it to a local file since the print version doesn't use the same CSS as the web (OS X = print to PDF, Win = print to XPS, etc).
Or, presuming you're on a modern browser and care that much about the content, you can just inspect the dom, find that <link type="text/css"...> in the head, and delete it.
> If it's available on your platform, you could print it to a local file since the print version doesn't use the same CSS as the web (OS X = print to PDF, Win = print to XPS, etc).
I had the same opinion about the official sed page[1], until I noticed the footnote. It got my attention and I decided to learn. One of the best, portable, elegant tools I use every day.
It's weird, it didn't always look like that. I'd been recommending it for years while it was a very Spartan HTML page with no CSS or inter-page navigation. The horrid new look came early last year.
{kind=link}