I checked the section "Interlude: Arrays" because the relationship between pointers and arrays in C is a major sticking point.
It claims that, given a declaration
int array[] = { 45, 67, 89 };
the expressions "array", "&array", and "&array[0]" are all equivalent. They are not. "&array" and "&array[0]" both refer to the same memory location, but they're of different types.
In the next section:
"By the way, though sizeof(void) is illegal, void pointers are incremented or decremented by 1 byte."
Arithmetic on void pointers is a gcc-specific extension (also supported by some other compilers). It's a constraint violation in standard C.
I don't think this is the "best" article on pointers in C.
> "&array" and "&array[0]" both refer to the same memory location, but they're of different types.
Indeed. And isn't this what makes the classic "countof" macro possible? The macro returns the number of elements in an array, calculating this by dividing the size of the array by the size of the first element:
Well, it's concise, but it leaves out something important. A C pointer has both a memory address and the type of whatever it believes it points to. The latter is what makes C-style pointer arithmetic possible, because if you know the type, you know its size too.
Right. That's why, when you have an array of structs, say each 8 bytes in size, and a pointer ptr to the start of it, each time you do:
ptr++;
it increments the address stored in ptr, not by 1, but by 8 (bytes) - so as to now point to the next struct in the array. Same if you do:
ptr--;
except in that case it decrements the address by 8.
And if you did:
ptr += 2;
it would increment the address in ptr to point to 16 bytes further ahead in memory than it was earlier, for the same reason. ptr will now point to the struct which is two items further ahead in the array. So you can access that struct with the expression:
Firstly, because a pointer is typed, when we dereference it, the memory location is accessed properly as the type. We don't have to put anything in the expression to say "please access the memory as 'struct foo', or a 'double'".
Secondly, arithmetic on pointers for array-like manipulation uses correct displacements for the size of the type.
Thirdly, we get error checking: there is a good amount of resistance in the language against mixing up types. If we convert one type of pointer to another without a cast, we get a diagnostic.
All these aspects are a key aspect of what separates C from assembly language.
> Firstly, because a pointer is typed, when we dereference it
Nonsensical and circular.
> Secondly, arithmetic on pointers...
Nonsensical and circular.
> Thirdly, we get error checking: there is a good amount of resistance in the language against mixing up types. If we convert one type of pointer...
Circular.
Every single one of your points about why this is an important property of pointers presupposes that the reader knows what a pointer is and how it works. It's a fundamental truism that you can't introduce, explain, and define a term using the term itself.
The OP's introduction does not suffer from this problem, which is why it is superior to your proposal.
(Edit: You all can downvote me all you want, but you're still objectively wrong.)
I'm sorry, but I disagree. The very first sentence of the linked article is being criticized unfairly. People are claiming that the very first sentence is incomplete because it should explain pointer arithmetic and typing.
Explaining what a pointer is by using the term "pointer" and explaining how to use one is a circular definition. A student who has never heard the term "pointer" before is going to be completely lost if the instructor jumps straight to "Pointer arithmetic works by increments of the size of the type of object to which the pointer points." If that is the first statement someone is exposed to, it will not make sense to them. I understand that someone may not like their proposal being called circular, but I don't think it's unfair or bad behavior to point it out.
The linked-to article is well done. There are some minor errors, as have been pointed out elsewhere. However, I think the criticism in this thread of conversation is deeply negative in a hostile, nasty way.
Dan's request wasn't about the technical merit of your comments, it was about the style:
> Nonsensical and circular.
> Nonsensical and circular.
> Circular.
> You all can downvote me all you want, but you're still objectively wrong.
If you feel that something is being criticized unfairly, you will win more people over to your point of view with civil and respectful conversation instead of flamebait.
We can have different opinions about something and still have an enjoyable conversation and learn from each other, as long as we interpret each other charitably and have a sense of humor about it.
I am all on board with being civil and respectful. It's the matter of application where I seem not to be of the same mind as some others. I don't want to belabor the point, but I don't agree with the way this played out.
If you'd like to discuss further, my email is my username at GMail dot com. Otherwise, I'm going to let this lie.
> Every single one of your points ... presupposes that the reader knows what a pointer is and how it works.
Pardon my mistake; I made these points under the belief that I'm in a debate about how to teach pointers to a beginner audience, not that I'm addressing that audience itself.
I think this was misunderstood due to not being phrased right; I do not believe, let alone wish to insinuate, that torstenvl is a newbie who doesn't understand pointers. I mean, that doesn't even make sense. Though flagged, it was also upvoted to +2 at one point.
I'm sorry if I misread you. The comment sounded like a putdown to me, but it's easy to misread intent, especially when reading quickly, as moderation entails. If I read it the opposite way, I think I can see what you mean—but then it's a subtle enough point that the nuance was likely lost on more readers than just me.
Distinction without a difference. If you can't explain to your students why the words out of your mouth are useful, you've already lost them.
The fact of the matter is that you're getting hung up on implementation details that do nothing to explain the concept.
Pointer arithmetic, how pointers interact with the type system... those are important, but they're completely incidental. There's no fundamental reason C had to implement pointers that way. They're factoids about how pointers work in C, practical mechanics. They tell you nothing about what pointers are in essence: a memory address.
And I don't know if you've worked with novice programmers lately, but it seems pretty obvious to me - based on how so many people get their heads discombobulated about pointers - that that conceptual clarity is needed. The details you're listing don't need to be in the first sentence.
That C pointers have a type which is used for checking, semantics of memory access and arithmetic falls into a category that I like to call requirements, whereas I use the word implementation detail for something like how many bits are in a pointer, and do pointers to bytes have the same representation as pointers to wider types. (These are also requirements, but ones an implementation can vary.)
I accept your terminology, though. Let the key features of C be called "implementation details". Then, if the goal is to teach C, it is "implementation details" we must teach.
(In any case, the students are probably eager to learn implementation details in the regular sense also, otherwise they would have been satisfied with their Python or Javascript class.)
If what you really mean is that we should teach C by instead teaching the architecture of a machine, whereby C is treated as just a notation for manipulating that machine, and concepts like the type system are considered annoying/distracting details in that notation, then I strongly disagree. Even if it is easier to teach that way, and the students eagerly absorb and regurgitate the simplified misconceptions, they are ill served.
Problem is, the author isn't using that definition as a rung on Witgennstein's ladder. He believes it himself. That's why he's oblivious to the differences between array, &array and &array[0]. The expressions produce the same memory address and since that is what a pointer is by definition, they are equivalent.
> "&array" and "&array[0]" both refer to the same memory location, but they're of different types.
"&array[0]" also does a dereference, which may cause undefined behaviour if array is null or invalid. You can get fun stuff like the optimizer omitting null checks later on.
Interesting. In C, “&array[0]“ is the same thing as “(array + 0)”, but in my copy of the C11 draft standard, I can't find anything about adding zero to a null pointer.
"&array[0]" is equivalent to "&(array[0])" - [] has greater precedence than &. Desugared, this is "&(*(array + 0))" - add 0, dereference, then take the address.
Is there a valid use case for doing pointer arithmetic on a void pointer? It just seems so disgusting on the surface. Did someone just really not want to bother casting to uint8_t*?
As for the array types, I think maybe the article is really trying to say that they'll all compile down to the same thing in the end (probably...compilers can be weird sometimes).
> Is there a valid use case for doing pointer arithmetic on a void pointer? It just seems so disgusting on the surface. Did someone just really not want to bother casting to uint8_t * ?
As a side note, there was a debate whether casting to `uint8_t * ` is a strict-aliasing issue (As `uint8_t` and `char` are not guarenteed to be the same type, and so the compiler isn't required to treat them as such).
That said, you're correct that you can always cast to `char * ` in this case as `char * ` is allowed to alias anything. I do agree pointer arithematic on `void * ` a bit messy, I think the intention was just as a convenience thing, but it can definitely be abused.
> As for the array types, I think maybe the article is really trying to say that they'll all compile down to the same thing in the end (probably...compilers can be weird sometimes).
I donno, I've read this page before and think the author genuinely doesn't know about pointers to arrays - if they do they've done a good job of pretending they don't exist. They are not mentioned anywhere on the page (Besides the part that says they're are all the same), and near the top the author talks about parentheses in variable declarations and says:
> This is not useful for anything, except to declare function pointers (described later).
Which anybody who has used a pointer to an array will know is not true, as you have to use parentheses to differentiate between a pointer to an array from an array of pointers.
> `uint8_t` and `char` are not guarenteed to be the same type
Remember that `char`, `signed char` and `unsigned char` are the different types, even though `char` takes the same range of values as either `signed char` or `unsigned char`.
The typedef `uint8_t` is usually set to `unsigned char`, not `char`, even on systems where `char` is unsigned. Partly this reflects the fact that `char` is usually used to represent actual characters, while the other two types are usually used to represent integers that take the same amount of memory as `char`. The standard technically does not allow `uint8_t` to be `char` [1], although this requires an extremely pedantic reading.
Anyway, if you replace `char` with `unsigned char` in your comment then it's correct. I believe all current major implementations typedef `uint8_t` to `unsigned char`, but that's not guaranteed and even old implementations of GCC had a different type. `unsigned char` satisfies the same relaxed aliasing rule as `char` [2] but `uint8_t` may not.
Practically speaking, for most people these days it is. POSIX specifies 8 bits and windows uses it. If you're working with a larger bit char, you're most likely well aware of it (offhand, some TI embedded chips are the only ones I know of, and even theyre rare!)
"char" is portable and by definition sizeof(char) == 1 and on top of that char pointers can alias other types.
If I could time travel and influence the design of C the first things I'd do is change switch to break by default. The 2nd thing I'd do is rename "char" into "byte" since that's effectively what it is (and it's seldom a character these days since we often use UTF-8 or other multi-byte encodings).
A byte is the smallest addressable memory unit, nothing more, nothing less. It's true that on most modern machines it's always equal to 8 bits (and it's mandated by POSIX AFAIK) but that's orthogonal.
In French when talking about storage capacity we use "octet" instead of "byte", I always thought that made more literal sense (if you have a 1megabyte memory on a system where CHAR_BITS is 16, do you have 8 or 16 megabits?).
There are bit-addressable CPUs and DSPs. Examples are many microcontrollers (part of the memory accessible in bit-addressable windows), and famous TMS34010 (https://en.wikipedia.org/wiki/TMS34010).
4-bit CPUs (like the one in your toothbrush or thermometer) can also of course address 4-bit "words", "bytes" or nibbles.
So 8 bits might not be the smallest addressable memory unit.
I think from a C standards point of view, that's true; I was using the general convention of 1 byte=8 bits, but char being one or more of these bytes. Hence CHAR_BIT is the number of bits in a char, and sizeof gives the number of chars that would fit in the specified type.
Marshall Cline's C++ FAQ is really, really good, IMO. I had read it some years ago, I think both the online version and the book, even though I've not really worked on C++ in projects. It goes into good depth and detail, not only on C++ language features and points, but also a lot into OOP/OOAD topics. Things like why you should (sometimes) push code from the client to the server - push in the sense of shift, not in the sense of mobile code, how old code can call new code - that didn't exist when the old code was written - don't remember the full details of that one right now, it may be via virtual functions and inheritance), and many more such things, a lot of them very useful. And all written in a fun, engaging style.
The correct result is "aa is a (2-element) array of a (3-element) array of ints".
To get the correct interpretation, you have to know that the spiral has to avoid the "int" element after passing through "[2]". This defeats the purpose of the spiral, since the line sometimes goes through the element and sometimes it doesn't. For example if it were "int * paa[2][3]" instead, the correct order is { [2]; [3];* ; int }. Note how the star is first avoided and comes after [3]. A 2-array of a 3-array of pointer to int.
How would you know when the spiral "avoids" the element on the left and when it doesn't? Well, you need to know the declaration grammar to know that [] and () bind stronger than the thing on the left, so you need to process those first. But if you know this, drawing a spiral is redundant, because you already parsed the thing.
I think the spiral rule is inherently wrong and should not be reposted as a helpful cheat-sheet for parsing C/C++ declaration syntax.
The correct rule is that postfix operators bind more tightly than unary. Declarations imitate use, so in declarators, we can regard the unary star and the postfix () and [] as unary and postfix operators. So "star star a [][]" is "star star (a [] [])".
To apply the spiral rule in these cases, we have to collapse together the chained unary and postfix operators so that the spiral traverses them as one clump:
A good exercise is to then guess why the spiral rule seems to work most of the time even though it is inherently wrong.
The reason is that some types that are syntactically valid are forbidden by C/C++. You cannot have a function returning a function. A function returning an array. An array of functions. You can only have a pointer to these (function returning a pointer to function/array or an array of pointer to functions), and then they need to be correctly parenthesized. Then the spiral rule works because you only have two elements in a parenthesis and you can just go right and then go left... unless you have arrays of arrays which are legal, and then it doesn't work.
But the more correct rule would be to go right and parse all [] and () inside the current parenthesis level, then go parse the * -s (including const/volatile) on the left. Then repeat for outer parenthesis levels.
The working algorithm is that the postfix operators in declarators (just like in expressions) have higher precedence than the unary ones (just like in expressions), but are overridable with parentheses (like in you know what).
The declared identifier is, first and foremost, the clump of high precedence postfix things that are on it:
a[3][4][5]; // a is an array of array of array
b(int); // b is a function
c(int)[3]; // c is an array of functions: nonexistent
Then we consider the unaries:
*** whatever; // whatever of pointer to pointer to pointer
Forget the spiral rule. That's putting an if-statement into a buggy algorithm instead of using the correct algorithm.
The simplest correct algorithm is to
1. From the identifier, go right one by one in the current parenthesis level and process every element.
2. From the identifier again, go left one by one in the current parenthesis level and process every element.
3. Repeat from step 1. except the "identifier" is the part you already processed.
Within step 1, you will encounter arrays and function parameter lists. Within step 2, you will encounter pointers (in C++ also references), const and volatile modifiers, and named types. Neither algorithm covers it, but if there is no identifier to start with, then you start at the most nested level between the elements that may occur in step 1 and 2 and if you find a comma, you were just processing the type of a function parameter.
Spiraling is unnecessary. Within step 1, you DON'T spiral because of arrays of arrays or you turn back because of a closing parenthesis so a spiral doesn't need to guide you. Within step 2, the elements on the right are all processed already, so a spiral going back right will hit nothing. For simple but common cases like "const int * ptr * const_ptr_to_const_int" you're spiraling around nothing on the right-hand side.
Let's rework and simplify the examples from the http://c-faq.com/decl/spiral.anderson.html page. Comments show what the result of parsing an element is. Process >> >> left to right and << << right to left.
char * str [10];
// XXX >>>> "str is", "an array of 10..."
// <<<< < XXX "pointer to", "char"
char * ( * fp ) ( int, float * );
// XX "fp is"
// < XX "a pointer to"
// XXXXXXXX >>>>>>>>>>>>>>>> "a function taking (int, float*) and returning"
// <<<< < XXXXXXXX "a pointer to", "char"
void (* signal (int, void (* fp) (int))) (int);
// < XX "fp is", "a pointer to"
// XXXXXX >>>>> "a function taking (int) and returning"
// <<<< XXXXXX "void", "and it is a function parameter to something else"
// XXXXXX >>>>>>>>>>>>>>>>>>>>>>>> "signal is", "a function taking (int, void(*fp)(int)) and returning"
// < XXXXXX "a pointer to"
// XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX >>>>> "a function taking (int) and returning"
// <<<< XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX "void"
const char * chptr;
// <<<<< <<<< < XXXXX "chptr is", "a pointer to", "char", "that is const"
// Notice how a spiral would make this worse and the page omits drawing it for a reason
char * const chptr;
// <<<< < <<<<< XXXXX "chptr is", "a constant", "pointer to", "char"
volatile char * const chptr;
// <<<<<<<< <<<< < <<<<< XXXXX "chptr is", "a constant", "pointer to", "char", "that is volatile"
Notice that in the examples where Anderson drew any spirals, it only made sense because there was a single "<<"/">>" element to the left and to the right of the XXXX part. In all other cases, spirals don't make sense because you might have to avoid the element on the left or there is no element on the right to spiral through, you're just going right-to-left. Why fit a spiral when a straight-line arrow will do?
For me, all confusion about C's pointer-happiness cleared up when I finally realized that C (and Asm, I guess) works with heap memory as a big blob of bytes, and it's programmer's job to keep the blob's contents from getting messed up―with some thinly-veiled help from the language and the compiler. Everything else, including variables, is just syntactic sugar when it points to the heap.
(With the clarification that afaik variables are different when they're on the stack or registers, becoming first-class 'indivisible' entities).
My favorite proof that C arrays and strings are actually just syntactic sugar for pointer arithmetic is that the following are all valid and equivalent:
Yes, that works because for an array arr and an int i,
arr[i] (i'th element of array arr)
is the same as
*(arr + i) (the value at the memory address arr + i)
which is the same (by commutativity) as
*(i + arr) (the value at the memory address i + arr)
which in turn is the same as
i[arr]
That last bit is what seems non-intuitive, but it is true.
I first read about this, maybe in the K&R book or some other C book, many years ago, at first didn't believe it, and remember trying it out on at least a Windows C compiler (MS C, likely) and maybe GCC on Linux as well. Worked on both, no compiler error.
This works because the expression arr, while we think of it as the name of the declared array, is also a synonym for the address of the first memory location of the array.
Note: all that I wrote above is what I rememeber from using ANSI C (a lot, but some years earlier). Things may have changed some with C99, etc.
In object oriented terms, the number two is an infinite map from all possible strings, to the third character of each string (or undefined behavior if the string length is too short). That just happens to be highly optimized in C. ;)
In Objective C, that would be [2 getNthCharacterOfCString: "ABC"];
Just joking! If you try to think about C in object oriented terms, you're misunderstanding what's really going on. It doesn't actually have arrays or strings as objects, they're just syntactic sugar (more like syntactic syrup of ipecac), and [] doesn't send a message. It's all just pointer arithmetic.
Pointers aren't just heap specific. Pointers are a language type that can reference memory address ( stack, heap, null or anywhere really ).
It's why you can have stack overflow, heap overflow, etc via pointer bugs.
Also, C/C++/etc runtimes don't have garbage collection but that's a runtime issue not a language specific issue/type system issue.
I think you have a good understanding of pointers, but you are mistakenly confining it to the heap or the runtime. Pointers part of the language and the type system.
Yes, this. The more you use a debugger the more it becomes apparent that C accesses OS protected domain and the best the OS can do is complain and stop you if you aren't smart enough to continue.
The title claims everything, but certainly it doesn't cover everything. It mentions const but doesn't mention volatile. It also doesn't mention restrict which is more confusing than const/volatile. It didn't mention the strict aliasing rule. It actually didn't even mention NULL.
I always wonder what makes pointers so difficult for some. So far I have always been able to explain it to people by drawing a linear memory space and then showing how different types are allocated. It seems to me that pointers are one the easier concepts in programming.
While I agree that a simple figure does a good job at explaining what a pointer is, it takes quite a bit longer to develop an intuitive sense of how to effectively work with pointers. In that case it's the more examples, the better.
To add another reason they’re difficult: many non-trivial uses of pointers are in particularly hairy situations, such as navigating complex data structures.
Combine that with magic number offsets, the guy who wrote it retired or moved on, and the only documentation is a comment above it that says, "DONT TOUCH".
Pointers require a very clear mental separation between the thing and the location where the thing is stored. However, in C the thing is only really identifiable by the place it is stored.
If the learner's mental model of what is happening has any flaws whatsoever, it will break under that strain. There are a few complicated concepts that are very similar but not quite the same.
I vaguely remember the first few times I wanted to do something more than paste magic snippets to my .emacs file. I knew nothing about Lisp and was not much of a programmer overall. The concepts of symbols and quoting were somehow really hard to grasp. It's strange now to imagine what was so hard then.
I have no memory of pointers being a hurdle like that. But I guess the concepts are somewhat similar so there probably was a time like that with pointers also.
My guess is, people are trying to keep variables the primary concept, and explain pointers on top of that. Hence, ‘boxes’ again crop up in an explanation of pointers.
For me, everything became much more clear when I realized that the heap memory stands on its own as a concept, being a big pile of bytes instead of ‘boxes’—and implicit allocation/deallocation of variables is just a thin veil on top (muddying the matter somewhat since vars can themselves be stored in memory and point to it).
Guess I had to deal with OOP before I grokked all the pointer-juggling going on behind the scenes.
I visualize memory as a big range and variables occupy space on them. The pointer is just the first byte of that space. Once you realize that C is basically placing stuff on memory things become pretty clear I think.
Yeah, so much this. I did most of my programming in asm in the mid 70s to early 80s. C wasn’t available back then on most 8-bit systems I used (Z-80, 6502, 6809, 1802, SC/MP). C pointers made complete sense to me once 16-bit microcomputers showed up.
Context: This is true in many parts of India at least, where I suspect the parent is from.
I used to teach C, found pointers a bit tough, then understood them after playing around a bit. General teachers of C indeed didn't have any real world exposure to programming.
I believe because it is taught the wrong way and with a confusing notation.
We do int ptr instead of int ptr and talk about memory instead of just saying: "It is simply a box containing 1 value, we can also make a box containing a box containing the value."
Do you use "vi" or "emacs"? It's my opinion that "vi" warps your mind about how pointers work, with its cursor that can't decide whether it's BETWEEN characters and OVER characters.
>In insert mode, the cursor is between characters, or before the first or after the last character. In normal mode, the cursor is over a character (newlines are not characters for this purpose). This is somewhat unusual: most editors always put the cursor between characters, and have most commands act on the character after (not, strictly speaking, under) the cursor. This is perhaps partly due to the fact that before GUIs, text terminals always showed the cursor on a character (underline or block, perhaps blinking). This abstraction fails in insert mode because that requires one more position (posts vs fences).
>Switching between modes has to move the cursor by a half-character, so to speak. The i command moves left, to put the cursor before the character it was over. The a command moves right. Going out of insert mode (by pressing Esc) moves the cursor left if possible (if it's at the beginning of the line, it's moved right instead).
>I suppose the Esc behavior sort of makes sense. Often, you're typing at the end of the line, and there Esc can only go left. So the general behavior is the most common behavior.
>Think of the character under the cursor as the last interesting character, and of the insert command as a. You can repeat a Esc without moving the cursor, except that you'll be bumped one position right if you start at the beginning of a non-empty line.
>Make VIM normal-mode cursor sit between characters instead of on them
>I would really like it if the VIM cursor in normal mode could act like it does in insert mode: a line between two characters. So for example:
>- Typing vd would have no effect because nothing was selected
>- p and P would be the same
>- i and a would be the same
>Has anything like this been done? I haven't been able to find it.
>Answers:
>The idea that the cursor is always on a line and on a character position or column is inherent in Vim's design. If you were to try to change that, many of Vim's operations would behave differently or would not work at all. It's not a good idea. My advice would be that you learn and become accustomed to Vim's basic behavior and not try to make it behave like some other editor. – garyjohn Feb 5 '11 at 23:55
>What you want is not Vim, I'm afraid. – romainl Feb 6 '11 at 7:15
I tried to investigate what it would take for Vim to have a mode where the cursor is between characters (so that the I-beam shape can be used for the cursor).
That is, this would be for the purposes of visual selection with 'v'. It now includes the character under the cursor, which makes no sense when the cursor is a vertical bar that is to the left of the character.
The code is so contorted and poorly modularized, it would have to change in numerous places; I estimated it at a minimum of two weeks of full time work to ramp up on the internals sufficiently to be able to add the feature with reasonable confidence.
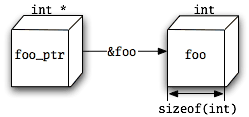
When graphical gimmics steal the show: https://boredzo.org/pointers/boxes.png visualizes both pointers and their target (an integer) as 3d boxes. So the sizeof(int) is the edge length of this target?
Normally we see such guiding images with 2d boxes. There's nothing wrong with 3d because clearly, integers are also not 2d (they are not even 1d). However, don't associate the size of theses boxes with the memory size of an element. This overstresses the analogy and suggests the whole thing is a vector space, but it isn't.
This is why people think programming is difficult. That same article could have been written in a significantly less convoluted way, and had a much broader reach, particularly for people who aren't already at least moderately familiar with C.
I joked the other day to a co-worker, currently working full time in Python, that you get used to the list comprehension and other nice things of Python so much, that you'll never be able to go back to gnarlier languages like Java/C. It's just too nice. You can get python to run really fast nowadays and if you can't, you still got nim.
> var is Java 10, though I believe it should not be used in production code, ever
Is that your opinion of var in general, or something about Java's implementation of it? If the former, I'm really curious why, as a C# dev who's used it for many years.
Unless you are using a constructor to fill the var, it makes reading/exploring/understanding source code more difficult. If the value comes from a method, enjoy chasing it down in your VCS. In your IDE you only need to hover it, but it's still an unnecessary extra step.
Sometimes I explore source code on GitHub, excessive use of var makes reading it very uncomfortable.
Turning it around, what are the benefits of var? Slightly increased typing speed. More time is spent reading source code than writing it and var makes reading harder and writing easier, so it's not worth the trade in my opinion.
I'd actually argue that var makes it easier to read and understand code. Most of the time, an explicit type on a variable declaration is just noise, because it's a repetition of what we already know from the same line of code. The main place where this doesn't apply is when the variable is initialized from a method call, but even then I tend to find that it's usually quite easy to infer the result type based on context (variable or method name), even without using IDE features. It's definitely different and requires some getting used to, but I personally see a lot more positives than negatives from it.
RE your sibling comment about dynamic: I primarily use it with json. It's useful for things like one-off error responses where you just need to grab a message or code to return/throw and there's really no benefit from introducing a class for that one usage. I did once work on a project where that was attempting to re-use some awful legacy code in a new app, and they leaned on dynamic a lot to make the legacy code work without to re-architect it correctly. It was about as terrible as you're imagining.
I'm not a java dev, and I don't anything around introduction var into java.
But I am a c# dev, and in the early days when var was introduced a lot of people avoided var because of misunderstanding of how it works. People thought it was dynamic rather than inferred, is it the same here?
{kind=link}
It claims that, given a declaration
the expressions "array", "&array", and "&array[0]" are all equivalent. They are not. "&array" and "&array[0]" both refer to the same memory location, but they're of different types.In the next section:
"By the way, though sizeof(void) is illegal, void pointers are incremented or decremented by 1 byte."
Arithmetic on void pointers is a gcc-specific extension (also supported by some other compilers). It's a constraint violation in standard C.
I don't think this is the "best" article on pointers in C.
I usually recommend section 6 of the comp.lang.c FAQ, http://www.c-faq.com/