This article states the following power consumption:
> The 10900K has a 125-watt TDP, for example, while AMD's Ryzen 9 3900X's is just 105-watts.
My understanding from other articles (like [1]) is however that Intel had to _massively_ increase the amount of power the CPU consumes when turboing under load:
> Not only that, despite the 125 W TDP listed on the box, Intel states that the turbo power recommendation is 250 W – the motherboard manufacturers we’ve spoken to have prepared for 320-350 W from their own testing, in order to maintain that top turbo for as long as possible.
Somehow it feels like back in the Pentium 4 days again.
Intel's TDP is just at base clock which Intel keeps at 3.7GHz. Pretty it's close to a hoax.
Power increases linearly with frequency and squarely with voltage. Higher freq. needs higher voltage. This applies to pretty much any CPU/GPU. Also AVX loads are significantly more power hungry.
230W would be a low estimate for a fully clocked one.
It would be interesting if someone would take an Intel CPU and an AMD CPU and calculate the electricity bill difference someone would pay in a year considering 40 hours / week run time.
Power increases linearly with frequency and squarely with voltage.
Going by the common use of "squarely," the power usage might also be interpreted as being linearly with voltage. Rather, I understood you meant that power increases proportional to the voltage squared.
(For the lurkers: Friction increases proportional to velocity squared, as does kinetic energy. These are all quite useful things to know, and should be part of the takeaways from your basic science education.)
True that, but what bothers me is that people may take it 'as 4x times increase' (quad=4, similar to twice, thrice, and so on). This is pretty much what I used to use.
That's not right - it comes from the formula of power dissipation in an asic: P=CfV^2 (power equals capactiance times frequency times voltage squared).
Clearly we don't turn all the mosfets on every cycle but it's the rough idea.
The real draw under turbo is likely much higher. My i9-9900k for instance has a rated TDP of 95W but it can only boost to about 4.5Ghz all-core when limited to that TDP.
I run it at a 5.2ghz all-core overlock and it pulls nearly 200W under load. (yes, beefy watercooling). From memory it was around 150W @ 5ghz but I haven't played around with the OC settings for a while after I got it tuned right.
But... the overclocking is the official spec. It happens dynamically all the time, it’s not a knob you throw. If TDP is too facile, another more reflective metric may be needed, but for now it’s clear TDP for Intel is marketing not grounded in reality — and not directly comparable between products in their lineup let alone across brands.
The complaint was that when being restricted to TDP power draw processor won't run above about 4.5GHz. Having overclocking mentioned after that as drawing more power made me think, that by overclocking they meant going beyond Turbo Boost, as 4.5GHz is approximately the all-core Turbo Boost frequency for the processor.
If that is correct, then there is no surprise, that going beyond max boost requires drawing power beyond declared TDP.
What sort of water cooling setup do you have? From all that I've read, the typical AIO water cooling setup is only barely better than a high-end air/fan cooling setup.
>>...barely better than a high-end air/fan cooling setup.
A large air cooler will be as effective, possibly more effective, than an AIO water cooler. What matters is radiator surface air x airflow. AOIs tend to have small surface area radiators and quiet fans because that is their target market. Water cooling does have some advanteages, but for coninuous heavy loads all that really matters is radiator capacity. The large air-cooled radiator is going to have more veins with more surface area covered by a more powerful fan than the typical AOI radiator.
100% this, the ultimate performance of a cooling solution is how fast you can move heat into the working fluid and how fast the radiator can move it out of the working fluid.
AIOs confer no particularly special advantage in either. The fact that the working fluid is water means nothing, heatpipes actually use water internally too. The difference is that heatpipes are actually evaporating the water so they can actually more more heat energy (due to enthalpy of evaporation) than AIOs.
AIOs actually tend to be louder for a given amount of cooling due to cheaper, louder fans and crappy noisy pumps. Custom loops don't really suffer that but they also cost 10x as much. They mitigate a lot of the downsides like pump noise by throwing expensive, high quality components at it. That's fine as far as it goes, but AIOs themselves are not an automatic win.
A large air cooler (eg Noctua NH-D15) is going to perform very similarly to a 240/280mm with identical fans (Noctua) at the same RPMs/noise levels. The difference is that most AIOs ship with very cheap fans that are just designed to spin fast and be loud, but that cools quite effectively. You can punch up the fans on a big air cooler and push a lot more heat through them. They just are optimized for silent performance out of the box.
Furthermore, most situations are currently limited by the IHS. AMD once pushed 500W through a 120mm radiator on their 295x2 card (OC'd), and temps would stay under 60C while doing it. The radiator size is not as big an impact as most people expect, moving heat out of the loop is not the bottleneck, it's how fast you can move heat into the loop that matters. GPUs do that very efficiently (bare die, dual chip on the 295x2). 5 GHz 14nm chips push an incredible amount of wattage, 7nm chips are so tiny that they result in very high thermal density, making both of them fairly prone to IHS thermal limitations. Colloquially: the heat just can't move out of the die into the IHS fast enough. The surface of the IHS is actually fairly cool, the liquid inside an AIO is barely above room temperature, but the heat just is not moving into the loop very well.
There is a resulting thing where people splurge on high-end gear, say a 280mm, and see high temps and tell themselves "wow, good thing I bought a 280mm, a 120mm would have been way hotter!". And no, not really, the amount of radiator fins isn't the limitation, it's how fast you can move heat into the loop. If you put a probe inside the reservoir to actually see the temperature of the fluid, it would barely be different between a 120mm and a 280mm.
And in fact the temperatures would probably be barely different than if you bought a NH-D15, or a Scythe Fuma, or other large multi-tower cooler. At the end of the day the working fluid doesn't matter, it's all fins and airflow.
I always thought the value of an AIO was in packaging. Sure, I can buy a huge case that has vast amounts of open space and configurable venting. Or I can jam everything into a smaller case, install an AIO, and ensure I’ve got reasonable airflow for the heat exchanger.
Yeah that's generally the main benefit. AIOs let you build in smaller cases without too much hassle. (Although when you go down to really tiny small form factor cases often you have to use super low profile air coolers again because there's no room for the AIO radiator)
> the ultimate performance of a cooling solution is how fast you can move heat into the working fluid and how fast the radiator can move it out of the working fluid.
Really, it’s all to do with how fast the heat can be permanently ejected from the system, almost always as heated air.
Analogised to a storage array, metal heat sinks and water reservoirs are a high performance write cache. Brilliant for bursty loads but once the cache is filled they don’t improve sustained performance.
There was a Linus Tech Tips video where they water cooled via just running water from a tap through the system and then dumping it back in the sink - no radiator or fans involved. The performance was of course fantastic, but the amount of water you use running a tap constantly is pretty astronomical so it's not actually practical.
The other problem is the mineral fallout in the water. A month or so later they had destroyed their waterblocks.
What you really want is a closed-loop heat exchanger, where the components only touch distilled water, and it gets pumped to a bathtub somewhere with a heat exchanger that pushes the heat out.
> how fast you can move heat into the working fluid and how fast the radiator can move it out of the working fluid.
Nitpick: "working fluid" here implies that cooling has to involve a liquid. But there are solid-state (e.g. peltier) CPU coolers, which of course have no "working fluid." They suck, but they exist!
(I think the suckiness of the existing peltier CPU coolers might be due to their small size, though. If you gave one of them as much solid-state thermal mass to work with as a water-cooling setup has fluid thermal mass, it might be rather efficient, for the same reason a chest freezer is efficient.)
In principle, yeah, but peltiers (a) suck at moving non-trivial amounts of heat, and (b) add a huge amount of heat of their own. Like, ballpark 10x the amount of heat you're moving.
You could move like 5W and you might have to dissipate 50W of heat total. Peltiers can't realistically move 100W and you don't want to cool 1000W.
Helpfully, Linus Tech Tips has walked through this particular experiment for you already ;)
> AOIs tend to have small surface area radiators and quiet fans because that is their target market.
What target market? I know there are some that just have one square 120mm radiator, but I guess I naively assumed that given the fact that they offer 1x, 2x, and 3x length radiators that the average size of a water cooler was somewhere in the middle. I've always understood that the basic advantage of a water cooler is that it lets you move the air-heat interface to a remote object instead of requiring it to be suspended horizontally from the motherboard. Given you get to shove it on the top or front of your case, why wouldn't people choose as big a radiator as possible? What do you think the average water cooler size is?
My guess is that the average AIO water cooler is something like a Corsair H60. The places where you're going to really leverage a water cooler are small and cramped cases where you otherwise can't get good airflow off of the CPU, and those tend to be smaller cases.
(The H60 isn't that much cooler than a Noctua UH-12, either.)
I'd actually be really interested to see statistics from Corsair, NZXT, Cooler Master, or another big AIO OEM about what they sell the most of.
My perspective from participating in PC building communities and consuming content from the big hardware sites and channels is that most people who use an AIO go for either a 240mm or 280mm radiator. I can't remember the last time I saw a 120mm or 140mm radiator recommended for a non small form factor build, as they usually perform equal to or worse than much cheaper air coolers.
If you press your hand to the bottom of a heat sink and warm it up, then turn the water pump on, it feels like water just washed over your hand, the metal cools down as soon as the water passes over it.
Some people seem to think air can be better because at idle, heat pipes can end up a few degrees cooler. Ultimately what you want though is heat dissapation, ideally without super powerful fans and water cooling is far better.
If you move the heat away from a small area quickly, you can easily spread the heat out into a MUCH bigger radiator which will cool more efficiently with air. A nice water cooling loop effectively increases the radiating surface area, with a nice side effect that it moves the heat further away from the rest of the computer.
It doesn't ignore that at all, the whole point is to move the heat from the tiny CPU to a big radiator with a lot of surface area. Air is a terrible conductor of heat compared to water, which pales in comparison to metal, but even metal doesn't move heat as well as flowing water.
They are comparable on cooling capability except for noise levels when the CPU is overclocked. I have a big air cooler and it gets really noisy when CPU is loaded.
I found an AIO (Corsair H115i 280mm rad) wasn't significantly quieter than a large air cooler.
On the other hand the custom loop I now have which has a 420 (triple 140) and a 280 (double 140) rad and includes the CPU and GPU is whisper quiet unless you're running a load that taxes both the CPU and GPU. It's actually eerie when you have it running because I was always used to that fan hum with previous builds.
Noise is a thing. I went back to the classic open loop water cooler on my threadrippers. The RX480 (130 x 56 x 518.5mm) radiator is complete overkill for keeping a 1950x cool - only have 2 of the 4 lower db 120mm fans even plugged in. I'm to the point where I wonder if I could go a single fan or even just a bare radiator with the CPU paired with it now. Only 30C in the loop @180W TDP.
(pump and radiator, longer term, will get tied to a 280w 3970x at some point this summer. Was not expecting the socket update they added with the sTR4x and 39xx series threadrippers)
You'll definitely need it for the 3970X. I run one on a Noctua NH-U14 (running in push-pull with one of their 2000RPM industrial fans and the included 1500RPM fan), and it can get toasty under sustained load. The Noctua typically tests similar to a 240-280 AIO in terms of heat dissipation capacity. It's a longer term goal to do a custom loop with 420mm+ of radiator, but I have other projects before that.
I can maintain turbo under load, but it decays from a full 4.5GHz to 3.9GHz-4.1GHz under a sustained prime95 load. My primary workloads are more bursty, so this is not a big problem for me. I just don't like leaving performance on the table. Also, I cannot turn on PBO on air. It runs up to 95C and then bounces around from 90C-95C, and I'm just not comfortable bumping up against the thermal limit like that long term.
A downside to watercooling in general is that it has a higher thermal capacity relative to a fan and heatsink. This means that a watercooled CPU will stay hotter for longer after it is no longer under load, relative to a heatsink setup. IMO an AIO is a notch down in cooling performance relative to a large heatsink. I still went AIO for noise reasons though.
This is irrelevant entirely, as long as it stays in the desired/designed range.
More importantly the higher thermal capacity allows for easier short turbo boosts which most of the load is. For sustained load, it matters only the hottest part (cores) of the cpu and water cooling is a lot better to transfer heat away.
Yes, it’s not much different than a bowl of water being heated from one side and cooled by a heat sink with a fan on it on the other. It takes time to move the temperature of that water around with some fixed heat source/sink.
That's not quite the right explanation. With the pump in the loop, the heat transfer speed is actually quite high, and ideally the temperature difference between "after CPU" and "after radiator" is small. Without the pump (ie. "bowl"), the temp difference would be quite big until convection kicks in.
However, cooling on any radiator is a function of the temperature difference between air and metal. The heat from the CPU will slowly heat up the water and radiator, which has actually a large heat capacity. That takes times, so the temperatures go up slower. When the heater stops, it will take the radiator also comparatively long to get that heat out of the water again.
A normal air cooler has much smaller heat capacity, so will react much faster, in both directions. These faster cycles are certainly less good for the CPU than the slower cycles of a water loop.
Gamers Nexus is an excellent Youtube channel and they have heavily invested in testing equipment to meaningfully evaluate coolers - some of their initial findings are already interesting. If you really are interested in cooling solutions I’d give their channel a visit.
The closest thing I have found to filling the void when Kyle had the gall to shut down HardOCP :/
There is a lot of variety... Most 360 AIO will do much better than any air cooler with less noise. Many 240-280 will as well... Good/Great air coolers will often do as well as a 120-240mm aio.
This will vary by radiator size/thickness, the fans and the case airflow and any obstructions.
Personally, O11 dynamic, with a 360 aio at the top/exhaust and 3x side, 3x bottom intake... It's really quite pretty much all the time... If I stick my head close, I can hear a little hum, but that my well be the video card for all I can tell. The 4-bay nas on the shelf nearby is more noticeable.
> Somehow it feels like back in the Pentium 4 days again.
What we've got here is actually the mysterious, long-overdued Pentium 5 (which was known for its greater-than 5 GHz clock speed and never released due to the huge heat dissipation issue). History repeats, but this time, it actually got released.
This is the cycle with Intel, though. They innovate, blow out the market, and then stagnate until AMD or someone else comes out with an architecture that's a category improvement on whatever Intel's offering.
This looks like they're turning every nob to 11 on the current architecture to try to get something that they can sell until they can come up with whatever will succeed the Core line.
It looks almost identical to the AthlonXP/64 vs Pentium 4 days when Intel just kept bumping the clocks and power consumption. Until they came out with Conroe.
Jim Keller might be doing just that with Intel right now. I only hope whatever they come up with, AMD is ready and able to keep up. Otherwise we're going to see a rerun of the following period too: Intel tweaking the same architecture for years at a time, and squeezing low single digit performance improvements that come with questionable security sacrifices and deeply unpleasant sticker prices.
While Conroe was definitely solid, last time around in getting there Intel didn't just pursue the technical side of bumping clocks/power, they also engaged in some genuinely illegal anticompetitive practices to get OEMs to not use AMD. So AMD wasn't able to leverage their few years of advantage into marketshare that would enable more sustained R&D, thus when Intel did regain the lead with a new architecture they had lost essentially nothing in the way of strategic position. The $1.25 billion AMD ultimately got out of Intel in a settlement years later didn't erase that advantage.
This time around though Intel isn't in the same position at all to dictate to major market players for a variety of reasons. The current big lucky break catapulting AMD way into the lead is certainly temporary, but it does seem like they'll be able to gain some real marketshare and attention. That will hopefully serve to make this time around end up in a much more stable back and forth.
I remember seeing AMD is growing R&D by 18% next year... what that means in practice, who knows. I am hoping to see them more competitive on the high end of graphics though... > $1100 for a top end consumer video card is crazy.
My understanding is that Nvidia can't produce enough GPU to saturate their pro market, the demand is huge as we speak and only increasing for now (looking at you, ML).
So AMD (or rather, their RTG division specifically) would be remiss not to align their price/perf with Nvidia to maximize profit.
A reason why they'll probably stay 'cheaper' to some extent for some time (perhaps long) is that they don't compete against CUDA, Nvidia's silver bullet. And don't just think “muh fancy library”, think hordes of engineers that Nvidia has the financial muscle to deploy in the field, 'lending' them to customers who need ad hoc driver work, custom implementations, general help, and what-have-you.
CUDA is a war machine, because that's how Nvidia operates its strategy.
It's how they owned the video game market back then, and I'm pretty sure they do the same with CUDA / ML / compute (why wouldn't they).
I thought that OpenCL would eventually be to CUDA what Vulkan is becoming to DirectX (btw: thank you, Linux); but it seems to me that OpenCL is going the way of the dodo? (still very little support in all ML/compute software I encounter, anecdotally).
AMD can sell a ton of GPU at good price, and they should, but they're lagging behind because optimized software libraries support (CUDA, the whole commercial hammer it represents) is where it's at.
Fortunately or not for them, Intel's graphics efforts seem to be... hype, more than a truly organized effort (insiders leaks speak of a terrible, terrible political / manegerial / organization situation at Intel's). It's fortunate for AMD's graphics market share, but it's unfortunate in that Intel would be a major support for OpenCL (last I checked, at least) and Intel's rise on that market could have taken AMD's hardware along with it in a tsunami of competition for CUDA.
Eeeeh, still seeing signs of this in the NUC and Laptop space. For instance you can find a laptop with anything faster than a RTX 2060 despite 4800/4900HS completely thrashing the Intel line of laptop chips.
It would be incredible if they could actually top what AMD has now and is planning in the future. I don't think there will be that same amount of room available to be able to blow away Zen 4 or whatever AMD will have by then.
Jim Keller has said he is technically the manager for thousands of people now and that they are working on even more IPC with even bigger out of order buffers. Even so I don't see the same leap being made in power and single threaded performance.
Then again apple has an incredible amount of performance per watt in their cpus, so I don't know where the limits really are.
AMD's not really any better when it comes to fudging specs. At least Intel CPUs actually limit their sustained power draw to the TDP when running in their factory default configuration, even if enthusiast motherboards usually override it.
AMD CPUs OTOH run significantly higher power than their spec'd TDP right out-of-the box. For example, that "105 W" 3900X actually ships with a power limit of 142 W and it is quite capable of sustaining that under an all-core load.
AMD's turbo numbers are also pure fantasy. If AMD rated turbo frequencies the same way Intel did that 3900X would have a max turbo of 4.2 or 4.3 GHz instead of 4.6 GHz. When Intel says their CPU can hit a given turbo frequency they mean it will actually hit that and stay there so long as power/temperature remains within limits. Meanwhile AMD CPUs may-or-may not ever hit their max turbo frequency, and if they do it's only for a fraction of a second while off full load.
The outrage over Intel CPU's power consumption is pretty silly when you realize that the only reason AMD CPUs don't draw just as much is because their chips would explode if you tried to pump that much power into them. If you care about power consumption just set your power limits as desired and Intel CPUs will deliver perfectly reasonable power efficiency and performance.
>>AMD CPUs OTOH run significantly higher power than their spec'd TDP right out-of-the box. For example, that "105 W" 3900X actually ships with a power limit of 142 W and it is quite capable of sustaining that under an all-core load.
I'm pretty sure you've got that exactly reversed, AMD's power draw tends to stay closer to the rated TDP than Intel's.
>>The outrage over Intel CPU's power consumption is pretty silly when you realize that the only reason AMD CPUs don't draw just as much is because their chips would explode if you tried to pump that much power into them. If you care about power consumption just set your power limits as desired and Intel CPUs will deliver perfectly reasonable power efficiency and performance.
I'm not even sure what this means. AMD CPUs are on a more advanced and physically smaller process, with smaller wires, and a different voltage-frequency-response curve. Of course they would "explode" if you try to pump them with voltages that the process isn't designed to operate with, that the Intel CPU with it's larger process can handle. But the power draw isn't really the "point" of the CPU -- performance is.
Imagine thinking that the Pentium 4 or Bulldozer was better than their contemporaries because they were capable of drawing incredible amounts of power.
> I'm pretty sure you've got that exactly reversed, AMD's power draw tends to stay closer to the rated TDP than Intel's.
I was talking about the CPUs in their factory default configuration. Intel CPUs default to limiting their sustained power draw to exactly their TDP, AMD CPUs meanwhile run significantly higher.
Where Intel CPUs will draw more is when you disable the power limits, but that power buys you extra frequency over what AMD is capable of.
> That's like complaining that speaker wire is deficient because you can't use it to charge an electric car. It's a CPU, not a space heater -- how much power it can draw isn't the point, performance is.
Yes, and Intel CPUs achieve significantly higher frequency, and thus per-thread performance, in exchange for that higher power.
With Intel you have the option of running high power/high frequency or lower power/high efficiency. With AMD you don't get the former option due to limitations of the fabrication process used. Somehow this has come to be considered a win for AMD.
> Intel CPUs default to limiting their sustained power draw to exactly their TDP
No, no they don't. That's a motherboard setting not a CPU one, and basically no desktop motherboard at least follows Intel's "recommendation" out of the box.
Yes, they do. The power limits are set in MSRs within the CPU and the CPU has default values for those MSRs.
> basically no desktop motherboard at least follows Intel's "recommendation" out of the box.
Wrong again. Motherboards using chipsets other than the Z series typically do not change the power limits unless the user explicitly sets them. These days even Z series boards do not change the power limits unless the user enables at least one overclocking feature, e.g. XMP. This is how the motherboard manufacturers technically follow Intel's specs while actually running out-of-spec with the settings most enthusiast users use.
I'm pretty certain that I remember watching videos from GN, LTT, or Bitwit (can't recall which) where they noted that AMD chips were turboing up to a few hundred MHz above the specced numbers.
The most recent generation had turbo numbers that were about 100MHz higher than they should be, and it was difficult or impossible to reach the stated number on most chips, especially on launch or near-launch BIOS versions.
Most came close, but you're right... Of course, Intel's max boost is the same, and unlikely in most consumer systems.
The AMD bios's were updated and do get better boosts now, but really in short bursts. That said, they do incredibly well for most circumstances and depending on your use, a much better option at all price points, except for some gaming at the ~$500 mark.
I'd still take an R9 3900X over an i9 *900K series. Using a 3950X now, no plans to upgrade for 3-5 years.
Those youtubers are measuring "turboing" by looking at the maximum frequency column in HWiNFO. So they consider a CPU to have hit a frequency even if it only touched it for a single millisecond during a minutes long benchmark run. For AMD CPUs the average frequency is typically significantly lower.
Maybe smaller channels, but I find that most of the bigger ones (especially GamersNexus) put a ton of effort into having a good, repeatable process for in-depth looks at performance. Certainly on par with Anandtech or any of the other typically trusted review sites.
Yes, that is the nature of turbo. If the CPUs could sustain operating at those speeds, it would be the base speed, not the turbo. Turbo is for really short burst. After that the system ends up being restrained by the available cooling and will go at lower speed (but usually still higher than base).
There's a difference between "might hit the max turbo frequency for a millisecond under light load if the phase of the moon is just right" and "can sustain max turbo indefinitely so long as adequate power and cooling are provided". AMD CPUs are the former, Intel the latter.
> When Intel says their CPU can hit a given turbo frequency they mean it will actually hit that and stay there so long as power/temperature remains within limits.
Have you actually tried to do that? When Intel says their CPU can hit a Turbo frequency, it's usually pure fantasy because they can't actually do it within the power/temp constraints.
Yes, they'll get to 5-whatever GHz on maybe half the cores if you're lucky, but full all-core load at the top stated Turbo? No chip will stay there, it will throttle down, likely by a lot.
And AVX loads will bring it to, or close to, maximum non-turbo clocks, that's how hot they run.
It could maybe be done with extremely good cooling and undervolting, and completely removing power limits (in which case it will probably consume close to 500W if it doesn't fry something first :D).
I'm surprised they _still_ don't have a working 10nm desktop chip. They're 5 years behind schedule (and still counting) at this point! This is just a reskinned 9900k with 2 more cores and a much higher (> 25%) TDP at 125-watts, which is a generously low estimate of how much power it will actually suck. I briefly had their "140 watt" 7820x chip (returned for refund) that would gladly suck down more than 200 watts under sustained load. Intel plays such games with their single core turbo at this point that the 5.3ghz means very little, and it's the same tired architecture they've been rehashing since Sandy Bridge (2011).
This is an incredibly poor showing and if I were an investor I would be seriously questioning the future of Intel as a company.
I've always been puzzled by this whole Jim Keller situation. Is one man literally the only reason we have technological advancements in microprocessors?
Obviously not the only reason, but he appears to be a helpful ingredient in the mix with good things tending to happen with him around. No idea how much of it is due to his technical vs. management skill, but there definitely seems to be some there there.
He was an actual Microarchitect in his early career. This guy clearly has good knowledge on every aspect of microprocessor design: transistor, interconnect, process complexity, core layout & utilization, ease of design, circuit complexity, time to market, micro architectural behaviors, ISA & software patterns. From what I've seen he is really good at setting targets for the teams, especially given that he has been at multiple companies, he clearly knows what is good and what is lacking. Setting aggressive targets and motivating the team towards them. Something the previous management failed at.
In that light AMD losing him to Intel via Tesla sounds like a potential few billion dollar blunder. I wonder how difficult/expensive it would have been to prevent that.
You probably can't. He appears to like jumping into challenges such as those that AMD was facing and Intel is facing now. The jumping would seem to imply he's doing it to pursue an interesting challenge as the primary. Some personalities need that (others are obviously repelled by that risk & challenge). Lots of big corporations can afford to pay very large sums to retain him, if that were his primary consideration.
Ask HN: I'm somebody with this type of personality that likes challenges and to bounce around, but I'm not as talented and experiences as someone like Jim. What are some suggestions on how I can satisfy this while also avoiding the trap of not being somewhere long enough to gain a higher level of experience? It seems that my habits have sabotaged me and my peers have excelled in their companies to much higher positions and compensation.
Feel free to email me to talk more about this. I can share trajectories for myself and a few peers who have similar experience.
Get a role at a >decent consulting firm in the field you like. Move aggressively into a role where you get to take lead on projects. Find conferences in your area of interest. Speak at those. Build relationships with any vendors that are common to your customers and area of interest. Speak more. Get to know organizers at conferences and seek keynote and panel discussion opportunities. Engage with everyone you can to identify problems. Evolve your content to focus on the intersection of interesting and common problems. Somewhere in here you can shift to a top-tier consulting firm in your field, or to independent consulting, or jump to a vendor, or take on a senior role at an org that would otherwise be a customer of your consulting firm.
At this point you should have strong experience and a reputation for the same. Leverage this to filter opportunities to those you want.
All of this is predicated on you actually being quite good at what you're interested in. You don't have to be world class to start, but you do need to continuously improve. You'll probably end up in the top 10% of your field. Again, predicated on ability.
Jim has extremely strong foundations in his field of study, and is work is an outpouring from this. He bounces between companies, but not from the basic problem of CPU arch and management, allowing each problem to further deepen his roots.
That really depends on the specific nature of your bounce around trait, what you need to fulfill that part of your personality. Only you can properly answer that of course. However, a few speculative ideas:
- Consulting can be interesting to feed that. You can expose yourself to a wider variety of projects and you can eventually have a lot of say in what work you choose to take on. You will also have the opportunity to limit the duration of projects you take on to an extent, so you won't be stuck on any given thing for longer than you can tolerate. Difficult to get started, to gain momentum.
- A first line suggestion from HN would typically be side projects. This can help restrain your desire to bounce around, dulling that like a pain killer. You do what you want on your own time, and change it up anytime you see fit, while staying at a job and trying to progress up the ranks. I don't know what your skillset is of course (eg programmer), it's somehwat dependent on that as to whether side projects is an interesting angle.
- If you think you're not experienced enough, focus on trying to leap yourself forward on something you are good at, to open up more opportunities to jump. Push one of your skills well above the market average. If you have some strong center pivot skill, you can bounce more often. You don't have to be Jim Keller to do this, people that are in the top 1/3 in tech at something often bounce around because they can, it's not unusual. As the other person commented, Jim has a core strength and it's why he can jump around. The bottom 1/3 is in a beggar position, they are always in a position of having to take what they can get by necessity (which rarely changes, unless their skill level changes or the labor market is extremely tight); so you have to focus on pushing a skill as high as you can, and you don't need to reach elite levels as an outcome.
- Much like physical exercise (high intensity training), there are paths to gain intense experience in shorter amounts of time with a high payoff in the experience you acquire. These opportunities are rare, although that doesn't mean they don't exist. The work is usually very difficult, the hours are more likely to be long. There is always that trade-off in there. To get what you want in the bounce around aspect, you might have to dial up the intensity for a time until you get the experience you need (after which you can dial it back).
Probably a good thing for the market at large though. If the current x86 duopoly ever turned into a monopoly with Intel or AMD it would not be good for consumers.
Intel's problems are not soley tech related, though their missteps here have not helped the situation
Intel does not know how to compete from a marketing, sales, and business standpoint, for a few decades they only really competed with their own product line, now that they have actual competition in the market they are unable to react to it properly even if they had the tech stack to do so
Base clocks are irrelevant on desktop, it's not Sandy Bridge days anymore. No modern (desktop) processor runs at baseclock in practice.
The 10900KF will do 4.8 GHz all-core at $472, the 3900X will do it at around 4-4.1 GHz[0]. AMD has a slight IPC advantage in productivity, Intel has a slight IPC advantage in gaming[1].
The market for the 10900K/KF is basically someone who wants the fastest gaming rig, but then as a secondary priority wants more cores for productivity. Kind of an overlap with the 3900X, sure, but the 10900K/KF will still outperform it in gaming, where the 3900X tilts a little more towards productivity.
There are of course exceptions, CS:GO loves Zen2's cache and Zen2's latency makes DAWs run like trash, so your specific task may vary.
I'd personally point at the 10700F as being the winner from the specs, 4.6 GHz all-core 8C16T with slightly higher IPC in gaming than AMD, for under $300. That's competitive with the 3700X: little higher cost, and more heat, but more gaming performance too. The 10900 series and 10600 series are a little too expensive for what they offer, the lower chips are too slow to really have an advantage.
But really it's not a good time to buy these anyway. Rocket Lake and Zen3 will probably launch within the next 6 months, if you can stretch another 6 months there will be discounts on Zen2 and more options for higher performance if you want to pay.
These days you can't say anything positive about Intel even if it is factually true. I am personally excited about the 10900K and the competition with AMD is bringing Intel prices down.
People seem to have a deep hatred for Intel, exactly the way they had deep hatred for AMD (pre-Conroe days, when Intel released Conroe in 2005/06, people were rooting so hard for Intel, it was hard to find any positive comments about AMD). I don't get it. Both are multi-billion dollar companies and innovating like crazy. We can't just sit back, and feel the utter awe of what it takes to make computer chips whether it is Intel or AMD. You know, its engineers like anyone else - they have good intentions and work hard to make all of this possible, the fans have this egregious entitlement that is so infuriating and dismissive.
to be a little more explicit: there are ARM chips that are affected by meltdown.
People shit on Intel like it's their particular mistake, but POWER, ARM, and basically everyone's out-of-order cores except Ryzen were affected by Meltdown. It's some oddity of Ryzen's cache predictor that make it immune, basically everybody else was affected by it.
Well they’re typically not as superscalar in processing, which helps. But I wouldn’t make an assumption that ARM chips generally are more secure — plenty of weaknesses have been found, and doubtlessly many more exist. Security research has shown there are always new untapped directions to exploit, and really nothing can be assumed to be actually secure at this point. Like I said before, Intel is the big target, especially as they run the servers you access over the internet. ARM devices tend to be local and thus aren’t as valuable for side channel attacks. Instead, most attacks for ARM chips tend to be at the sandbox/OS level.
That cuts both ways... there are definitely Intel fans that will excuse everything Intel is/has ever done that isn't above board.
I was only stating part of why someone might favor for AMD strongly, without going into the irrational, which you seem to be focusing on here.
Right now, AMD is largely better at every price bracket and in general has done better in terms of security and long-term support (don't have to by a new motherboard every year if you want to upgrade).
You seem to miss the huge list of speculation bugs with mitigations that take a variable chunk of performance away with no buyback or return program in place. VW diesel gate was less of a blunder than the Intel speculative execution saga and one cost a company $33 billion.
Wait, really? My understanding was that, whereas VW intentionally cheated to fool regulators, Intel (and others) got blind-sided by a creative attack against a fundamental, well-established technique for gaining performance. These seem like very different problems.
Note: I haven't followed the "saga" closely so maybe there is more to it that I'm not aware of.
Speculative execution is fine, speculative execution across protection domains is not. So VW cheated for better milage, Intel cheated for better performance.
"Cheating" implies something sinister. Far more likely, they just missed it.
Modern CPUs are at the very edge of what humans can design and build. Hundreds of verification engineers try to make sure they work. Not one of them will have a whole picture of the entire machine in their head, or really understand all of its requirements. The very best, hardest working, most diligent and dedicated teams will still ship a CPU with bugs. Perfection is simply not possible in this domain.
>That's competitive with the 3700X: little higher cost, and more heat, but more gaming performance too.
I wouldn't call the cost « little higher » if you factor in the motherboard (and possibly the cooler). Any AM4 board will run a 3700X whereas Intel's using yet another socket for their new chips.
The value of the pack-in cooler is sub-$20, it's quite noisy and not particularly good at cooling. Something like a Hyper T4 or Deepcool Gammax 400 is in the ballpark, something like the Hyper 212 Evo is cooler and quieter, so that sets very low bounds on the value of that pack-in.
You don't really want to be using the sub-$100 tier of motherboards for AMD either. People will talk up how cheap motherboards are but tell people you're going to put a 3900X (only 105W TDP) on a B450 and their eyes will roll at you.
> I'd personally point at the 10700F as being the winner from the specs, 4.6 GHz all-core 8C16T with slightly higher IPC in gaming than AMD, for under $300
I think the 10700F would only be the winner if you have a motherboard that either isn't following Intel's recommendations for turbo or lets you ignore them.
Otherwise the 10700F's 4.6ghz all-core isn't going to happen with a 65W limit after unknown seconds. That TDP limit is going to really cripple that chip. Whether or not you can ignore that limit will I guess decide whether or not the i7-10700KF is worth the extra $50.
But the 9700 appears to be almost nonexistent. I think the 10700 will end up in the same camp. The 10700K will likely be the only chip with any meaningful coverage/reviews in the i7 lineup.
what do you mean by this? I researched intel vs. amd gaming performance pretty extensively last summer, and I paid particular attention to csgo benchmarks. AFAIK, 9700k/9900k are a little faster than the 3900X in csgo at stock speeds, and a good bit faster on a typical overclock.
The doubled cache really made an enormous difference in performance. Zen2 averaged about a 15% IPC improvement on average, in games the average was more like 30%, and in CS:GO it was about 42% improvement. It went from being pounded in this title to tying or beating the 9900K.
And that's against a 2700X, the 1800X was significantly worse than that. Compared to the 1800X, CS:GO is more like 50-60% improved.
The slightly higher clocks don't hurt, but Zen2 really made huge progress in handling the "unhappy cases" for their architecture. I tend to point the finger at cache for this specific case, cause I don't think of source engine titles when I think clean, well-optimized, highly threaded code.
Good statistics about the current install base rather than market share are hard to come by. The Steam Hardware Survey is a decent source when you're looking at desktop PCs, because there's pretty strong overlap between desktop PC users and gamers. Slightly more than 25% of machines measured by the Steam survey don't support AVX2, which means they're pre-Haswell on the Intel side or pre-Excavator on the AMD side, or a newer but low-end Intel model. (Those recent low-end Intel chips that have AVX2 disabled also tend to have Turbo Boost disabled.) It's plausible that Sandy Bridge and earlier may still account for 10+% of gaming desktops.
As desktop user I don't care about power consumption, I care very little that it has x% more power then last year processors (at least when the x < 100) because current processors have enough power for anything you throw at them, but what I do really care is this:
-Do they still pack that PoS Intel management inside the CPU? And are these new CPU still vulnerable to Meltdown? Because if any of those questions are answered with "yes" then no amount of cores, GHz and performance % is going to change my mind from Ryzen
Well, power consumption is still kinda important on a desktop. All that power has to go somewhere and you need a cooler that can keep up or you'll be losing more performance from thermal throttling.
My current desktop water cooling setup can handle 700W under load easily. After setting it up my test was to actually spin everything up under 100% load with 2 crypto miners (1 for GPU and one for CPU, in 2014) and did it for 10 hours straight. Peak temp was 60 degree Celsius in hot July. Why I never continued with that? Because at the time bitcoin was 120 dollars and the electricity was 10 times more expensive. According to worker pool I joined at the time in those 10 hours I've earned 3 cents. Anyway, back to topic - I trust my water cooling 100% (also I made it manually because I like to build things).
I agree, it's a sad one. But compared to Intel's flurry of independent security incidents in past years, it's but a bucket in a lake.
I am not praising AMD, don't get me wrong, I am merely choosing the lesser evil. In this case the lesser evil happens to be better and cheaper. ¯\_(ツ)_/¯
I have no horse in the CPU race but I do have a different perspective here. I have a SFF home server with <100W cooling. I am compute-bound, have no discrete GPU, and have no interest in Meltdown as I run only trusted code. My box sports a 6-core i7 8700, and I am tempted by the 10-core i9 10900.
Why not AMD? Answer: iGPU. AMD's best iGPU offering seems to be the Ryzen 9 4900HS, which has fewer cores, and you can't just order it - it seems to be for OEMs only. So staying with Intel.
The stupid answer is that a GPU is needed to get past POST. I need graphics to boot, and nothing more.
AMD has a "NUC-gap". At the high end, there's Epyc2 datacenter offerings, and going low there's the embedded line. And every device in between either assumes a discrete GPU (Ryzen 7) or is a wimp (G-series).
I built a beefy NUC-alike based on an Intel chip, because AMD has no offerings here. Google "Ryzen NUC" and the demand is evident.
It feels like we are moving towards ARM becoming the primary consumer CPU, and x86/x64 being used to power only niche use cases (dev, audio/video, gaming etc.) or servers only. Can anyone working in the space confirm/deny?
Define "nowhere close"? Apple's cpu's are competitive with x86 when looking at low power applications. Microsoft has multiple examples of windows running on arm. This seems pretty close in the grand scheme of things.
The number of computers in use in 10 years will be a lot larger. According to the below link between 2002 and 2014 computer numbers doubled to 2 billion. So if things continued in even vaguely similar form ARM would have to sell about as many machines as are currently used.
But there are an awful lot of people who will take a low power, cool machine. Even if slower I’d like some.
Well they said “consumer CPU”, not “PC CPU”. So the question is, do most consumers do their computing on PC CPUs or ARM CPUs? Which then raises the question, what does “computing” mean...
Laptops outsell desktops by something like a 2:1 ratio. If you restrict your analysis to just consumer devices and exclude office PCs purchased in bulk by businesses, that ratio is even more skewed toward laptops. Desktops are a niche, and x86 could be relegated to niche status for consumer computing simply by ARM making significant inroads to the laptop market without having any uptake in the desktop market. (It's already the case that consumers tend to own more ARM-powered devices than x86-powered devices.)
Sounds a bit like Google trying to sell Stadia: "Nobody needs processing power close-by, let's compute everything in the cloud and access it with thin-clients!"
Which sounds workable in theory, but is unworkable for many people due to limited Internet access speeds/volume.
And the real disadvantage then becomes obvious when the "super powerful cloud" only renders the game at console visual details levels with in-built control-lag.
Not just limited to gaming: Video-editing is becoming increasingly popular as a hobby and a field of work, which is another use-case for lots of local processing power.
So while in terms of market size desktops might be a niche, that niche still fulfills an important function thus I don't see that going away any time soon.
> Microsoft has multiple examples of windows running on arm
And none of them have been well received or commercially successful. They seem to be more defensive bet hedging against Intel than anything intended to go anywhere.
Just now I googled "Surface Pro x review" and picked the top 4 results which are actual reviews. Out of those only one is negative. This also seems to align with my own experience of users using it.
For the purposes of this conversation, I'll define "nowhere close as follows (and willing to put money on the prediction, if you'd like to negotiate such):
"Primary" means simple majority. >50% ARM market share for consumer PCs as defined below.
"Consumer CPU" refers to non-server application PCs. Workstations, desktops, laptops, and DIY. Personal and professional use (including enterprise purchases, so the full fleet of corporate laptops at any company are included). Some current examples would include things such as the Talos POWER workstations and ARM workstations.
For "PC", the definition gets a little rough, and I'd be willing to negotiate this. I'd say anything where the primary interaction mode is mouse and keyboard. With this definition I would exclude most tablets, but something such as the Microsoft Surface would be included. The test that includes the Surface and excludes most other tablets is that the Surface is sold with a keyboard and trackpad. If the keyboard and trackpad is not included or required, then it's not a PC. This rule would also exclude something like a NAS, where the hardware is basically that of a tower desktop, but the use is headless; this would be a server. Like I said, this can get a bit loose. Happy to negotiate a firmer definition.
As for "nowhere close", I'd say that we won't see ARM as the primary consumer CPU for the next decade easily. I'd be willing to bet $1,000 US on this.
If you wanted different timelines, I'd put $5,000 on 5 years, and $500 on 15 years.
Apple's market share won't push ARM past 50%. Enterprises move slowly and make up a lot of the PC market. If you assume a 3-year hardware replacement cycle, then ARM would have to come to dominance at least 3 years before the end of a betting period for it to have a chance of meeting the end of the betting period. Thus, for the 5 year timeline, ARM would have to be dominant by 2022. For the 10-year, by 2027.
Separately, in writing this response, I realize that you could easily make the argument that a "consumer CPU" includes cell phones and tablets. This is a very different conversation.
> "Consumer CPU" refers to non-server application PCs. Workstations, desktops, laptops, and DIY. Personal and professional use (including enterprise purchases, so the full fleet of corporate laptops at any company are included).
This is a totally arbitrary distinction. We can’t just ignore the fact that consumers are doing the bulk of their computing on smartphones nowadays.
> We can’t just ignore the fact that consumers are doing the bulk of their computing on smartphones nowadays.
> > Separately, in writing this response, I realize that you could easily make the argument that a "consumer CPU" includes cell phones and tablets. This is a very different conversation.
I think you can see that I didn't ignore this fact in my post.
I made a definition (as requested) to clarify my position and based on my interpretation of the original post in this thread. Based on this interpretation, it seemed like that poster was referring broadly to PCs. The definition was for the purposes of a prediction.
In defense of my interpretation, I would consider it unreasonable to assume that the OP meant to include smart phones in their consideration of "primary consumer CPU", due precisely to the fact that you and I have both mentioned, that many individuals use a smart phone for the bulk or even all of their computing.
Aren't we? How many people's primary computing devices are ARM-based devices at this point? I know plenty of people who rarely touch a laptop, yet alone a desktop. Expansion of the computing market is mostly happening in developing markets through predominantly ARM-based devices too.
> How many people's primary computing devices are ARM-based devices at this point?
At home, it's a high percentage and has been for many years.
In office environments at work, it's still near zero (emphasis on primary). A couple hundred million people across middile and upper development nations use desktops and laptops every day at work. They're not going to switch to ARM systems anytime soon for that work. Good desktop processors are a few hundred dollars; ARM has no great angle there (including on pricing). For businesses the cost of a decent Intel or AMD processor is a modest share of the overall system they're buying for the employee to work with.
In developing nations with primitive economies, certainly smartphones are much more common for primary work purposes. And that's a case where ARM pricing does bring a huge advantage that Intel and AMD struggle to compete with. Cost obviously matters in personal businesses where your income is $50-$200 per month. Numerically this category wins, primarily due to the intense poverty of three billion people in India, Africa and China. This market alignment based on incomes probably won't change much in the coming decade, as ARM's ability to push into higher value office work environments as a primary will be very limited.
My Raspberry Pi 4 could be an entirely usable desktop replacement for casual usage if the GPU was a bit better.
My gf already uses her Samsung S8 as primary "computer". Only for a few things does she reach for her laptop, and that's mostly due to the screen and webpages not being mobile friendly.
That's hard to say. The timelines are too long. I don't think we'll see ARM primacy in PCs within the decade. If you read my reply to a sibling post of yours about what I mean by "nowhere close", you can see some of my thinking on the matter.
Isn’t the open rumor that Apple is gonna start switching over their Mac line next year? Apple switching from Intel to Arm across the board would drastically change the situation practically overnight.
Well, if you consider phones, sure. But for people who still need desktop/laptop computers for gaming, programming, video editing, photo editing, and heavy business use (spreadsheets, desktop publishing, etc), then Intel is still, by far, in the lead.
There are ARM Windows laptops. I don't think that they are successful. So I don't really see ARM becoming the primary consumer CPU for computers. It might change in the upcoming years, when Apple will release ARM computers.
Too bad they have only 2 channel memory controllers and same 32/32 L1 cache. That means all that power is still wasted waiting for memory (Max Memory Bandwidth 45.8 GB/s, seriously?).
Not sure why feeling so excited about those processors.
They also still only have 16 PCI-E lanes from the CPU, which is disappointing. Ryzen's 20 isn't exactly lavish, but it's enough for the pair of x16 for the GPU + x4 for the primary NVME drive.
For typical desktop workloads memory bandwidth is not that important. They likely will release Xeon-W counterparts later with similar frequencies but higher memory channels and PCI-E lanes for those who need it.
The i7-5820K is from the "high end desktop" line of chips, derived from Xeon workstation chips. The modern equivalent is chips like the i9-10900X (note X not K), which does have quad channel DDR4-2933 and 48 PCIe lanes. Clock speeds are a bit lower though.
Does anybody need those 5.3 GHz at 300 watts? I believe the next big thing is "massively parallel distributed processing": thousands or maybe even millions of tiny processing units with their own memory and reasonable set of instructions run in parallel and communicate with each other over some sort of high bandwidth bus. It's like a datacenter on a chip. A bit like GPU, but bigger. I think this will take ML and various number crunching fields to the next level.
Those are desktop processors. Most applications won’t even use 64 cores. But I agree this is this future, but today faster single core will speed up your day a lot.
There is, but keep in mind this is yet another refresh of Skylake, not really a "new" CPU.
Supposedly the new socket is PCI-E 4.0 capable, which the next CPU "Rocket Lake" will supposedly enable.
But since it's still 16 lanes from the CPU only, that means you'll only get PCI-E 4.0 to likely a single slot. And likely not any of the M.2 drives, which typically are connected to the chipset instead.
PCIe 4.0 is likely to be short lived given that PCIe 5.0 seems to be around the corner.
On the AMD side where they already have 4.0, few care for it (I do though - just ordered a mobo and processor that use it) - 4.0 nvmes aren't faster for common use cases, and it mostly matters when going multi-gpu which is only seen in some professional use (and even then you can use a threadripper and just have a lot of 3.0 lanes). Then next ~year ryzen 5000 which will require a new socket seems likely to already support 5.0. I'm guessing Intel will just altogether skip 4.0.
This may be just good enough to hold off AMD from further gaining market shares on Desktop. For certain group of user that doesn't need a GPU, the iGPU included is a good enough solution.
One thing that bothers me a lot is the 2.5Gbps Ethernet that is supposed to come with those new Intel motherboard ( assuming MB vendors uses it ). Why not 5Gbps Ethernet? How much more expensive is it? It seems we still dont have a clear path on how to move forward from 1Gbps Ethernet. Personally I would have liked 10Gbps, but the price is still insanely expensive.
How many people actually have internet faster than 1Gbps? Transferring large files around on LAN is not a particularly common use case either. The small number of people that actually need > 1gb ethernet can always add an expansion card.
It's actually a bit of a chicken and egg problem. ISPs can't offer it as there is no real way to push it to the customers from the router to the end user devices. Virgin Media in the UK's 1gigabit package is actually 1.2gbit after docsis overheads (they always overprovision it slightly for various reasons), but the router only has 1gig ethernet.
2.5 Gbps will be an intermediary standard for consumer ethernet applications because existing CAT5(e) cabling can usually carry 2.5 Gbps (but not 5 Gbps or 10 Gbps).
CAT5e is not in-spec for 10 Gbps but it will usually do it for short runs. Under ten meters, worth a try. The official spec is 100m and the transceivers are pretty solid at pulling a signal out of the noise.
Personally I'm with the other guy, I think this is a dumb half-measure and we should just move straight to 10 Gbps. Right now the single biggest cost in your household multi-gig deployment will be switches, a switch with 4-8 10Gbase-T ports will run you around $500, and this figure is not really any cheaper with multi-gig. You are paying through the nose for something that is a watered-down version of the "real standard".
Say you have two switches, one is upstairs and one is downstairs, are you really going to drop $1000 on a half-baked deployment? People need to try it, figure out if their existing cable is stable enough for their needs (maybe that segment can run at 5gbit speeds and it can be 10 gbit on your machines and on the switch), and just pull cable where it's not.
Multigig switches are expensive because they're new. The products have NRE expense to pay off and so do the chips inside them. There's not yet the volume to make them really cheap. They will get cheaper.
The question is will they get cheaper faster than 10G? Perhaps. Despite being 14 years old 10G is just starting to get put into reasonably priced prosumer switches so it doesn't have that much of a head start practically.
I have been thinking for a long time if having Switches that is limiting in total bandwidth would help save cost. Example you dont need 40Gbps on a 4 Port 10Gbps switch, or a 20Gbps on a 4 Port 5Gbps Switch. For Consumer usage, you only really need to be able to sustain Maximum speed on 1 port, while others working at a lower speed or next speed grade down.
Well yes, but there are also a whole lots of CAT6x cables. CAT6 is now close to 20 years standard, and CAT6A or in earlier cases CAT6e is now 12 years +. As a matter of fact within consumer Home usage distance CAT5e may well be good enough for 5Gbps as well.
Having 5Gbps End point gives you much more flexibility, instead we got 2.5Gbps. Unless the BOM cost made a lot of difference I dont understand this trade offs. Especially considering we have 802.11ax potentially offering 5Gbps+ and 802.11ay that runs faster then 10Gbps. We are coming in an age where a cheaper Wireless equipment is outrunning our wired counterpart.
For 100 meters. A typical consumer doesn't need that much length, and can use higher speeds even over bad cables. Especially if the cables aren't bundled for a significant distance.
Intel has been backed into a corner by AMD, so they’re pushing clockspeed over balancing against TDP and bus.
Also, the multi-year delays in the next process shrink gave them lots of time to improve yields and micro-optimize the fabrication generation these are running on.
is this 5.3GHz with, or without spectre, RIDL, meltdown, zombieload, fallout, MDS, TAA, and whatever other mitigations for vulnerabilities inherent in Intel chips?
That is still IPC, which refers to instructions per clock as an average throughput and not the instruction latency.
> Circa P4, an instruction took around 40-50 cycles to complete
Different instructions can have wildly different latencies. Even then an instruction taking 50 cycles sounds like double precision division or an 80 bit floating point operation. Most operations on the P4 had a latency of 1 - 7 cycles, but the P4's high clocks made memory latency and branch mispredictions a bigger issue.
Some instruction latency might have been part of the overall pipeline shortening that made the core architecture fast, but this is an oversimplification, and the numbers here don't apply to the vast majority of common instructions. Caches, deep out of order buffers, prefetching and branch prediction all play a part.
You are of course correct, but it's a very important point - theoretical performance on paper is +-meaningless, only real, end performance after things are set safely is relevant to normal use cases. Which is basically all of us.
Strangely, not all cpu reviews take this into consideration.
This is still inferior to AMD's high-end offerings in terms of price/performance and performance/watt, but it does have one edge: single-threaded performance. There are certain applications where that matters a lot. Other than those, I'd pass.
Seems to me that all Intel can do at this point with their 14nm++++ is pump the Ghz and power consumption (when actually turboed to that high clock) up as far as they can.
The power consumption isn't going up quite as quickly as we'd expect; we're seeing a return to high frequencies partly because we're seeing high-end CPUs manufactured on a vastly more mature process than we typically have part.
"Users wanting the 10-core 5.3 GHz will need to purchase the new top Core i9-10900K processor, which has a unit price of $488, and keep it under 70 ºC to enable Intel’s new Thermal Velocity Boost. Not only that, despite the 125 W TDP listed on the box, Intel states that the turbo power recommendation is 250 W – the motherboard manufacturers we’ve spoken to have prepared for 320-350 W from their own testing, in order to maintain that top turbo for as long as possible."
Power is going up and by a lot to hit that 5.3Ghz. And requires a much lower temperature to do it.
Keeping a CPU under 70 °C while dissipating 300+ Watts is going to be tough even for high end custom loops. Air just isn't an option for these CPUs at all.
Look at the clockspeeds and power consumption of Intel's original 14nm process. In comparison to that, the power consumption is low for a given clockspeed.
That they've got the power consumption down is precisely what allows them to then increase clockspeed which then brings it back up.
I'm kind of surprised at this point that Intel didn't just bite the bullet and go with TSMC or Samsung for fabrication for a year or two until they figured their in-house sub-14nm story out.
What’s the betting that when Apple move to ARM processors AMD and Intel both start developing their own ARM CPUs. I have a feeling it’s going to be extremely hard for x86 to compete once Apple show the way on this.
Why would they? Instruction set is basically irrelevant. Almost nothing about the CPU design has anything to do with ARM or x86 or whatever.
Apple may drag the OSX ecosystem kicking and screaming, battered & bloody over to ARM so Apple can control more of the stack, but why would that have any impact whatsoever outside of Apple's corner of the market?
So about 400,000X faster than my first computer console, the 8bit 1Mhz Atari 2600, which cost $200 at that, time 40 years ago. Or 600X faster than the 64-bit 80 MHz Cray-1 which was $8mm at the same time.
Frequency is no longer a good proxy for speed, what with advancements in ipc. Also, note that the amount of memory in a cray-1 is similar (within 1-2 orders of magnitude) to the amount of cache in a modern cpu.
Frequency is still very much a good proxy for speed, especially in the context of a chip which has the same deep pipelines and sophisticated scheduling that made "frequency is no longer a good proxy for speed" a popular retort. The benefits of improved IPC are dwarfed by the frequency gains as compared to those older chips.
Not really. Straight FLOPS might increase pretty-much linearly, but that's not representative of a typical workload. Cache latency (as measured in clock cycles) and size in a modern core is comparable to memory in an older CPU, as I mention in the parent. But speculative execution means you can effectively use the 'slower' medium (memory) for intermediate computation.
To clarify, the problem is not 'clocks give X% improvement to performance, but architectural improvements give Y%, and Y is bigger than you give it credit for.' The problem is that CPU performance is not practical to reason about for humans. Hasn't been and probably won't ever be until/unless computers get massively rearchitectured. The speed-of-light limit means that 'fast' memory (accessible within a couple of clock cycles) will always be limited, and 'big' memory (gigabytes-terabytes size) will always be at least 100 cycles delayed. This in turn means that the cpu architecture must be asynchronous, which means it does not have consistent or intuitive performance characteristics.
tldr: 6502 is very similar to 8086 and doing a binary translation is fairly straightforward. But, it turns out that many instructions that took multiple cycles on the 6502 now execute in a single cycle on x64 and pipeline deeply with other ops. So, the effective performance of a 4Ghz x64 resembles that of a 15Ghz 6052.
My first computer was a TRS-80 Color Computer with 4KB. The pace of doubling has been a part of my life since home pong. And now a generation provides <20% boost over the previous leaves me with an uneasy feeling.
I get excited as much about economic and eco-political axes in technology, with this multidimensional perspective there is still so much room to grow. Look at how interesting OS's became when Richard Stallman started to open source them. Look at the price difference between the Atari and Cray in terms of $/speed, albeit a 70's example. Chips are still in patent-impregnable territory, they are proprietary and boring. In the next years, if these technologies open up, we could see some amazing stuff...
And the CPU in your Atari might have to chew over an instruction for several clock cycles while a modern CPU will often be able to sustain multiple instruction per cycle in good stretches of code.
You've broken the site guidelines, both here and in other comments. We ban accounts that do that, so would you please review https://news.ycombinator.com/newsguidelines.html and use HN as intended?
It's publicly known that Nvidia and AMD pay game developers to optimize for their chips; you can see the logos when the game launches. Yet you're presenting this as some kind of conspiracy with a persecution complex tacked on.
Words run short some times. I know the history though, didn't mean to pin it as a conspiracy, but in desparate times, which I do not keep track of, things can happen, since I follow histories. Don't take this as a rebuke, is that the word, yeah, don't whatever man. <3 Who cares
For my computer graphics and processing work, multithreaded tasks scale amazingly well with the number of cores so single core performance doesn't matter all that much. A single thread isn't even be able to process all the data that's streamed from an SSD. I need three threads just to process/prepare the data in the background, in addition to the main thread that keeps rendering.
I suspect it's only a matter of time until multithreading is a must for games. The additional programming effort may not have paid off if players only have 2 or 4 core CPUs, but now that 8 cores with 16 threads are increasingly common, it's going to make a difference.
Do they use those cores? Sure. But when I’m playing a game (even a game that feels like it should be ripping threads like Factorio) I usually see that one core is pegged at 100% while the others are chilling around 40-60% (I have an overclocked 8700K). In my experience, single core performance is still the bottleneck (as far as CPUs are concerned) for gaming.
the underlying simulation in factorio is pretty difficult to parallelize, since there is so much interdependent state. some systems that don't interact directly (eg, trains and belts) can be parallelized almost trivially, but subdividing these update jobs further is very tricky.
Yep, games like factorio and dwarf fortress are generally more memory bandwidth limited than direct CPU limited, and it can be very hard to split up those behaviors.
It is exceptionally unlikely that a game is both limited by memory bandwidth and not able to be parallelized further.
You might mean memory latency bound from serial simulations that need to calculate one piece to move on to the next, like an emulator or scripting language.
Factorio is an indie game, I guess it might not be easy for indie developers to make use of multithreading, whereas AAA game developers have entire teams dedicated to engine development and multithreading.
Anyway, traditional graphics APIs like OpenGL are practically single-threaded. Modern APIs like DX12 and Vulkan have been designed with multithreading in mind and support scaling with number of cores much better (with added overhead of having to do manual synchronization).
> AAA game developers have entire teams dedicated to engine development and multithreading
Unity has been introducing a lot of features (Job System, ECS) that make excellent use of parallelism. Additionally, a lot of the engine internals are being rewritten with that as a base (and some of the old features get patched with APIs that allow access from multithreaded jobs). It's a lot of fun when the code you write by default runs on all of the cores, with (almost) none of the usual parallel programming headaches.
Pretty soon you should start seeing all kinds of indie titles making use of those features.
An 8700k has 12 threads. If the game was only capable of using 4 threads effectively, I would expect to see something like 1 thread at 100%, and the other 11 threads at 300/11 = 27%.
If all your threads are sitting at 40-60% you're using more than 4 threads worth of execution... (if all 12 threads were at 50% that would be 6 threads worth).
Usually operating system rotates threads between cores, so while you might see 60% on every core on average, on a given snapshop there will be 1-2 cores active at 100% while rest idle. Remember that CPU can't really work at 60%, core either works at 100% or sleeps.
The PS4 is described as having 8gb of main memory. Unlike computers and older consoles, there isn't even a distinction between what is "System RAM" and what is "Video RAM". Can you elaborate how that is NUMA?
That's a very simplistic view of the architecture. Consoles in general have multiple CPU complexes and caches that do not straddle the boundary, and also multiple memory buses.
Are you referring to the multiple CCXs as different "NUMA" nodes? Because they aren't, they still share the same memory controller. There isn't a shared cache, true, and that does have performance implications but that doesn't make it NUMA.
If you can point to anything to support your NUMA claim that'd be highly interesting, but all the block charts & teardowns I can find show it's clearly UMA.
Not utilizing all cores fully means that the CPU is more powerful than the game needs, not that the game is unable to exploit many cores.
For example, at 3 GHz and 30 FPS, there are 100 million cycles per frame. If the game requires 250 million cycles per frame spread between a few threads, it will never need more than two cores and a half in aggregate, plus waiting; and with 10 cores used 10% there's more time to wait without dropping frames than with 3 cores over 80% load.
That's nitpicking semantics. They mean anything less than a quad core (excepting some hypothetical ultra high clocked single core cpu that doesn't exist) would heavily bottleneck most modern games to the extent that only pretty low end GPUs would even be worth using.
They said "require" as shorthand for that because they (apparently wrongly) expected people to follow the "strongest plausible interpretation" rule.
So the latest games require the latest CPUs? Well, no shit. The points I'm referring to are where the comments above say that games need multi-threading, or need multiple cores. Both are absurd statements. They try hard to do multiple threading only because multiple cores is what they CPU manufacturers are giving us. Nobody wants, much less needs, multiple cores.
CPU manufacturers are giving us multi core CPUs because it's no longer practical (because of heat and power draw) to just keep scaling frequencies. People are saying that you need multi core CPUs because there are no single core CPUs in existence that are fast enough.
You're talking past everyone because you're arguing hypotheticals, and assuming everyone else is also talking about hypotheticals, but they're not.
Just check the original context. "Best single core performance, which is what matters". There are no hypotheticals. Single core performance exists.
Look at the other replies. People who don't understand the difference between concurrency and parallelism. These people actually think multiple cores are a good thing.
What you don't seem to understand is that CPU manufacturers could have scaled up performance while still delivering a single core. They went the multi core route because it's much easier for them.
Assuming the same power budget, same cooling, same semiconductor process, both x86, etc. the best single core you could make would lose to just two cores off a desktop chip you can buy today, let alone 8/10/12.
It might actually be useful to have a second core, to service hardware and peripherals. This way you'd have smoother performance, because you would not need to flush the cache on every interrupt.
The gap is pretty small, even now, and Zen 3 comes out in a few months.
The value proposition of these chips is pretty bad, as well. Enormous power and cooling requirements, short-lived motherboard sockets, and sheer price/performance ratio are all not great in comparison.
Matters for whom? For a lot of use cases (web servers, compiling, databases...) having lots of cores matters (and total = performance of core * number of cores), for others it doesn't.
No, it does not matter. That's a common misconception. If you double your core count you can run double the number of threads in the same amount of time. That's it. If you double your single core speed you can still run double the number of threads in the same amount of time or the same amount of threads in half the time.
Single core performance is always preferable for CPUs.
The CPU manufacturers basically conned everyone into thinking multi-core was "good enough". Software people who knew what they were talking about back in the day called them out on it but nobody listened. Now here we are on Hacker News in 2020 and people still not understanding this.
We all know that a single core with twice the performance and twice the cache space is generally better than two cores (though a sibling comment does raise a good point that poorly written software can lock up an entire core regardless of it's Hz, also some VM scenarios would prefer extra cores over faster cores).
We also all know that a single core with twice the performance and twice the cache space costs a lot more than two cores. It's a lot more expensive than even 3 cores.
I'd rather have 3 4Ghz cores than 1 8Ghz core (except for the novelty value).
We all know that a single core with twice the performance and twice the cache space is generally better than two cores
I'm not sure that's actually true, even if you want performance (although it's dependent on whether your workload can use more than 1 thread, of course): A single core at a higher clock speed might be better if it can hold that clock speed. But the faster you run, the more power you use and the more heat you produce, and worse, the relationship isn't linear. So ex. 1 core at 4ghz won't stay at 4 ghz, where 2 cores at 2 ghz can hold that speed forever.
Right, when I say an xGhz core I'm pretending to live in a simpler world where they can all hold that speed forever. Consider an 8Ghz core to be a core + cooling that can consistently hold a speed twice as fast as the 4Ghz core + cooling can hold.
> We also all know that a single core with twice the performance and twice the cache space costs a lot more than two cores. It's a lot more expensive than even 3 cores.
I'm a programmer, I don't care how much it costs the hardware manufacturer. I want a single core. Multi-threaded programming sucks. I don't care if that's implemented via multiple cores acting together and only presents itself as a single core. I just want a single core.
> I'd rather have 3 4Ghz cores than 1 8Ghz core (except for the novelty value).
I'd much rather avoid multi-threaded programming and get the 8GHz core. But your comment is missing the point, really, which is that single-core performance matters. If the 8GHz core existed then you'd still be able to get 3 8GHz cores. Still want the 3x4GHz?
> If the 8GHz core existed then you'd still be able to get 3 8GHz cores.
Well no. Right now you can get ~5GHz cores and they draw close to 300 watts per core, which is why they can't run all cores at 5GHz on threaded programs. For the same amount of power as one core at 5GHz you can get 64 cores at almost 3GHz, e.g. ThreadRipper 3990X.
An 8GHz core would presumably draw 500+ watts per core and maybe even a lot more than that. To get the same performance as the 3990X, you would either need a single 185GHz core (basically impossible) or >23 8GHz cores (expected power draw >11kW). That would cost thousands a year in electricity, but a normal 20 amp household circuit breaker would trip before you hit 2.5kW anyway.
More than that, by the time you write code that can scale to 16+ threads, 64 isn't that much harder, and 256 isn't much harder than that. So get used to it, because in a few years there are going to be 256-core mobile devices and 1024+ core desktops and servers.
8Ghz cores do exist if you have enough money to hire someone to deal with the overclocking for you (or enough liquid nitrogen and time to do it yourself).
I, on the other hand, care about the cost of my computers a bit more than that, not having infinite money. Which is why even if 8Ghz cores were commercially available I suspect I would still be buying 3 times as many 4Ghz ones.
A Bulldozer FX barreling down the highway at over 8 GHz is actually still slower than any modern CPU at less than half the clock speed. The latter also doesn't require LN2 cooling and doesn't draw more than 100 W for a single core.
You seem to be arguing about a hypothetical situation where an 8ghz single core CPU is a thing that exists, whereas everyone else is talking about reality. Good luck scaling a single core to match the performance of 16 ~3.5ghz cores (That's a thing that exists for not unreasonable cost in the Ryzen 9 3950x for example)
Turns out this has been tested, and the results are clear: Running a single core 9900k is pretty bad in comparison to 8 heavily downclocked cores on the same CPU. While single threaded tasks are obviously slower, frame rates are much more stable, windows is more usable with 8 cores. Several games simply didn't work with a single core, or took ages to load. Reference: https://youtu.be/feO54CBUJCk
The video you linked is pretty weak; there was (understandably) no performance tuning done on both configurations (Windows scheduler, game scheduling).
This is because for a fair comparison you need to scale the L1/L2 cache size as well. More cores - more cache. It is also important to not scale below 2 cores, because servicing interrupts causes performance hiccups. It is enough to have the second core heavily downclocked, and you'll still have better performance then with just a single core.
Sure, if you forget all the additional cache evictions, memory
reads and writes and TLB flushes caused by all the competing threads on a single core. Not to mention that one shitty bit of code in one thread can poison the cache enough to re-read the data from memory every context switch.
So say I'm close to maxing out my 8c/16t CPU, would a better alternative be a 16*4; 64Ghz single core processor? Why?
You wouldn't have true parallelism then, would you? So if you have something, for whatever reason, blocking further processing, the entire computer would lock up. Why is this a better scenario again?
> You wouldn't have true parallelism then, would you? So if you have something, for whatever reason, blocking further processing, the entire computer would lock up
That doesn't occur because the OS scheduler will eventually pre-empt your thread and swap to another task. You don't really have control over that. All modern OSs use pre-emptive multitasking and there's not a ton you can do to prevent it.
(read: anything in the last 30 years, last cooperative multitasking I remember was MacOS Classic (probably like OS7 or so.)
Single-core processors were the norm up until 15 years ago, and people routinely ran more than one process on them. Yes, we ran Discord (we called it Roger Wilco or Teamspeak back then) and played music in the background too, without 4 dedicated cores for the background tasks.
Yes, in the abstract it would be preferable to have a 64 GHz processor instead of 16 4 GHz processors, because then you can have all that speed devoted to a single task. Context switching is not that expensive (particularly if you have hyperthreads/SMT to soak up the wasted cycles). The physics of transistors make that impossible, but we absolutely would not do any of this multithreading crap if we didn't have to. Single-threaded code is easier to write and usually faster (in terms of less total cycles - multithreaded programs waste extra cycles on synchronization, overhead, spinning for locks, etc that single-threaded programs don't have to).
Looks like it was cooperative until OSX actually. I just remembered that it was a loooooong time compared to other desktop OSs.
> With the release of System 7, the MultiFinder extension was integrated with the operating system, and it remains so in Mac OS 8 and Mac OS 9. However, the integration into the OS does nothing to fix MultiFinder's inherent idiosyncrasies and disadvantages.[11] These problems were not overcome in the mainstream Macintosh operating system until the MultiFinder model was abandoned with the move to a modern preemptive multitasking Unix-based OS in Mac OS X.
While I agree this post should be downvoted I do think it's worth mentioning at least two different reasons why higher clock speed would push me to intel this generation: AutoCAD and Europa Universalis IV. Those are my two principal demanding softwares where they cannot see any real means of moving past single core for the vast majority of processing.
Are there actually games that take advantage of a CPU this fast? I would imagine that all the game developers would be targeting the more modest hardware that most of their players actually have.
Anything high refresh rate(120+Hz) benefits immensely from these high clock rates.
The high clocks result in less pipeline stalls meaning your high frame rates are more achievable as well as significantly reducing the dips (0.1% lows is what every reviewer hates).
This isnt about "average", this is about having the best experience possible, which Intel provides in this very specific scenario.
Intel has three things going for it(in the consumer space), which matter a lot or not at all to different folks:
- better idle/low usage power consumption than AMD (low load laptop battery life)
- Intel's QuickSync is fantastic for media encode/decode (NVENC is typically better, AMD is basically non-existent)
- Intel has the highest clock rates.
Outside of these niches, AMD is dominating at every level of the product stack.
It's certainly closer than it has ever been, the mobile Ryzen 4000 series is a massive improvement across the board. At the high and medium end, it completely dominates Intel.
Where Intel still rules (in x86 land) is that all day battery life. They're simply better, for now. I think mobile Ryzen 5000 may take over even that niche, but it remains to be seen.
From all the tests I've seen, AMD has a power consumption advantage compared to intel. This directly translates into longer battery life. While there's probably situations where Intel has better battery life due to software maturity, we've already seen tests where in low load situations amd is beating intel. During high load it's not even a competition at this point.
Simulation games like Factorio, Rimworld, Kerbal Space Program, Dwarffortress etc use 100% of single CPU and <10% of others. In factorio, I can make ginormous factories that are bottlenecked by a single CPU. Sometimes say my factory produces X rockets per game-minute. I make a bigger factory that produces Y rockets per game-minute where Y >> X but since now CPU cannot handle the load I now produce <X rockets per real-time minute. So making my factory bigger was a net negative in terms of rocket per real-minute.
Simulation titles and open world titles tend to be very sensitive to per-core performance and memory latency (there is in fact noticeable performance scaling on these titles with faster memory even on Intel architectures - Fallout 4 is up to 20% faster going from DDR4-2133 to DDR4-4000).
I've seen some people on Reddit running modded Skyrim (can probably throw Fallout 3/4/etc into that bucket as well) who are really mad about the performance of their Zen2 processors. ARMA3 probably runs poorly. That kind of thing.
Also, DAW performance is not very good on Zen.
That said, even in games that use more threads, there is often noticeable performance scaling from having faster per-thread ("single core") performance because there is one thread that is bottlenecking everything else. No real-world game ever has the magical 0% serial code necessary to scale perfectly according to Amdahl's law. It is just a question of whether that scaling starts dropping off at 6 cores, or 8 cores, or maybe 10 cores. Very few games can saturate a 3900X or 3950X yet, maybe Ashes of the Singularity but I doubt much else.
Why is this? It's something I've heard a lot but I don't understand why. Is it something fundamental about audio, or is it simply the case that The Application With the Mindshare isn't architectured in a way that multithreading works well?
Personally, my day job is working on a program that could support 4-16-64 threads just fine, but since a lot of the core architecture is from the 90s and there's a giant ball of globals, component object model/single threaded apartment spaghetti deep under the hood, multithreading even trivially parallelizable tasks is fraught with peril. Fortunately for my employer, we are an entrenched 800 pound gorilla, and we can skate on momentum while these issues get fixed. So I totally understand if it's the same in a specialized space like DAW.
re: Skyrim. That engine is a fork of a fork of an engine that was written in 1997. Skyrim ran like garbage when it was released in 2011. It has nothing to do with open world or so forth, it's just run of the mill legacy architecture problems. ARMA3 (released 2013) is in a similar boat- it's a very old game engine written by a very small (they're not indie, but they're close) development studio. Both of these studios have the same problem my employer has- they have a bunch of legacy cruft that's difficult to migrate away from.
There's a tipping point somewhere. With two physical cores, you don't gain that much from farming stuff out to the different cores. A lot of multithreaded stuff from that era had a sequential-concurrent model. Your one large task was broken down in a sequential series of subtasks. (usually it was gather input, do AI, do physics, do drawing) Sometimes those subtasks would break out into N threads, which do a small amount of stuff in parallel, then there's a "join the world" event, you move on to the next subtask. Think links of sausages; sometimes it's wide, sometimes it's narrow, but you never have two sausages at the same time. This model is very sensitive to single threaded performance, because all of the join the world events are single threaded, and at the end there's a giant pile of single threaded calls to OpenGL which is a single threaded API.
We're steadily moving away from that. First of all, the game loop went from having a giant mutable ball of state, to having a generational immutable world state. One pile of threads would compute world state generation N+1, and a second giant pile of threads would draw world state generation N. Both would depend on generation N, but since generation N was immutable, that was fine. This can be broken down further- it's fine to generate new AI priorities for gen N+1 using the physics state from gen N, and use the AI priorities defined in gen N to do physics to generate gen N+1. So AI and physics can happen on independent threads. This can be broken down further- chop the world up into zones, and give responsibility for each zone to individual jobs. We're also switching from OpenGL (with its internal state machine, single threaded API) to Vulkan, which has completely blown open the drawing steps. I think Valve did some benchmarking where where the single threaded chunk of OpenGL took 5ms, (which is an eternity) but the single threaded chunk of Vulkan was ~1 microsecond. The 4.999ms of CPU time still exists under Vulkan, it didn't just go away- but now it can happen in parallel on multiple threads. Instead of having 3-20 join the world events each frame, there's only one, and the only thing that happens there is a pointer swap.
The industry is moving away from single threaded engines like ARMA3's and Bethesda's in house engines. For the most part, AAA games since ~5 years ago properly utilize multiple cores. ARMA3 and Skyrim are dinosaurs, and they've aged about as well.
Generally those with the top end CPU have the top end GPU and the top end monitor. In that regard all the game has to do to "take advantage" of the CPU is support high or unlocked framerates and high resolutions.
> Generally those with the top end CPU have the top end GPU and the top end monitor
I sort of doubt this is true, if only for the reason that most people don't buy a new CPU, GPU, and monitor at the same time. monitor and pc are probably going to be on different upgrade cycles, unless the monitor came with the pc (in which case, probably not "top end"). for DIYers, the GPU and CPU+RAM+mobo are likely also on different upgrade cycles.
I bought my current 4K monitor about four years ago, but I ran most games at 1080p until I had enough spare cash to buy a 1080 ti. I finally upgraded my CPU, RAM, and motherboard this year, mainly because I was tired of having 8GB of DDR3.
in any case, it's usually not a rational use of funds to buy the fastest CPU and GPU for a 4K monitor unless your budget is unlimited. with a constrained budget, it's usually better to drop a tier or two on the CPU if it gets you the next higher tier GPU.
Minecraft comes to mind. People looking to host a server usually need good single core performance depending on how many players there are and mods installed
VR games, and simulation games tend to have high single-core CPU speed requirements for smooth play. Mostly though this is due to outdated engines (in the case of sims) or inexperienced/indie devs using premade engines like Unity and Unreal in a way that loads mostly a single core. Some tasks like physics, sound, texture loading is pretty easy to put on separate threads but thats usually a small fraction what bottlenecks a CPU in a game.
Eh, my i5-4440 had zero trouble running current VR games at 90hz, including while doing other things like playing Spotify or running music from a web browser, or even streaming and recording.
Just the fact that it's yet another socket for basically the same process is insane. On AM4 I've been able to use their low-end to very-high end CPUs for the last several years and most likely will be able to use the ones coming out this year too.
Looks like GN already has a video out, so I imagine the rest of the big hardware channels will follow along quickly. Don't have time to watch GN's video now, but I bet they'll have taken a nice in-depth look at the performance.
I think part of the reason why you may be being downvoted has to do with the tone you're using in making your statement as well as the newness of your account.
Also, though you're statement is technically correct, it fails to account for the nuance that increasingly across all applications, not just gaming, multi-threaded processing performance is becoming the far more important benchmark to look at.
crushing adjective [usually before noun]
used to emphasise how bad or severe something is
I had to check the dictionary just in case. And in this case neither was it technically correct, or downvoted because of the tone. I downvoted it because it was factually wrong.
Zen 2 actually has better IPC than Skylake in many cases, on a sustained single thread performance they are likely to be on a similar level despite having a slightly lower clock speed disadvantage on a much lower TDP.
Not really... If you look at the FPS numbers, sure AMD is slightly lower. However AMD can also perform other functions like encoding/decoding. If you want pure FPS, sure Intel will win. For general computing AND gaming, AMD wins every time per dollar.
When people say "single-threaded performance" they don't mean literally one single thread will ever be used. The single-core performance is a proxy for performance-per-core and that's a certainly a very important number.
Intel's per-core performance is decently higher in gaming, between their lower latency giving them slightly higher IPC in gaming tasks[1] (as these are latency sensitive) and the much higher all-core clocks they are pushing (at least 10% higher than AMD at present). That still gives them an edge in gaming, although certainly much less of an edge against Zen2 than it was against Zen1 (which was much worse than people were willing to admit at the time, people at the time were benching it with a GTX 1080 (the fastest card available at the time) at 1440p and 4K and claiming there was "no noticeable difference", but faster GPUs showed the weakness).
I think the 10700F looks good, 4.6 GHz all-core 8C16T part for under $300 looks compelling for gaming customers if you can keep it cool. The 10900K fills the "I want the top gaming performance first and foremost, with as many cores as I can get, and I'm not super concerned about budget" but is definitely on the expensive side. Other than that, nothing terribly impressive here IMO, the other chips fall into a range between "not fast enough" and "not cheap enough".
> The single-core performance is a proxy for performance-per-core
A very bad proxy then, since performance-per-core with multiple cores in use will almost certainly be limited by constraints on (1) memory bandwidth and (2) power/thermals. "Single-core performance" only applies when you're literally pegging one core at 100% cpu.
Well, all I can say is that enthusiasts expend a lot of effort getting per-core performance as close to single-core as they can ;)
Pure single-core turbo is usually a bit higher than all-core turbo, but as a proxy it's surprisingly close. A 9400F (so, no hyperthreading, we are removing that variable) scores 2380 in CB R20 (AVX2 aware). As a 6C, that means its per-core performance is 397. Since single-core is 4.1 and all-core is 3.9, if we adjust the per-core by that amount, we come up with a per-core equivalent of 417. The actual single-core score is 430, so using single-core as a proxy introduces less than 3% expected error to true "per-core" performance. That is the impact of thermals, more cache available to that thread, etc - all of that adds up to less than 3% difference, in a full AVX2 heavy task.
AMD boost clocks are not as neatly defined as Intel but the 3500X has let's say 4.1 single-thread boost (the advertised single-thread boosts tend to be "ephemeral" at best under actual loads) and 3.9 all-core. It scores 2650 all-core, that's 441 per-core, adjusted for speed that's a per-core equivalent of 464. The actual single-core score is 467, so basically dead-nuts on.
AMD people just don't like "single-core" because it's not a metric they currently win in. In practice it correlates pretty damn closely to expected per-core performance, and that is a critical metric that has a world of performance impact on a variety of tasks (Amdahl's law says many real-world tasks are dominated by one bottlenecked thread, the faster you run that one single thread, the faster the whole thing runs).
Once we see AMD move into the open lead in various workloads (which is very possible with Zen3), overnight we're going to see a lot of people suddenly rediscover the merits of empirical testing under non-bottlenecked conditions. The arguments about "well you would need a RTX 3070 running at 1080p" are going to fade away, just like the whining about the irrelevance of "single-core".
----
Generally speaking most home tasks are not memory-bandwidth bound. It depends, but generally they're not. As far as power/thermals, it depends on the board, if you're running a really crappy board with a weak VRM then all bets are off, but in practice it is not a problem with normal workloads. Gaming is not at all intense and can clock high even on some pretty mediocre boards if you've got some airflow. Something like video encoding (lots of AVX2) is the next step more intense, if you are going to sit there all day crushing video and you won't have airflow then yeah, you do need to buy at least something in the $170-200 tier.
Prime95 is not a realistic real world workload and will definitely overheat anything.
They mean game FPS will be bottlenecked by single CPU's speed. E.g. in factorio all logic is single-threaded, so you'll be bottlenecked by single CPU, even though it uses other CPUs for minor tasks.
To be fair, that's exactly the target market for high end desktop CPUs like this. This isn't a datacenter part, and other parallel workloads tend not to make up much share of the personal workstation market.
If you want to max out gaming benchmarks right now, this is your CPU. And there are a decent number of people who do, so heavily tuning existing dies (I mean, let's be honest, this a rebinned and overclocked 10900X) makes sense.
> AFAIK, there is not yet a web browser core that can parallelize tasks in a meaningful way.
Firefox is getting there. The CSS style engine is parallelized already, and graphical compositing+rendering will follow shortly (already enabled experimentally in some configurations). Other parts of the browser will be next, including the DOM.
Mozilla has been making pretty good progress with parallelization of firefox with their oxidation project. All browsers are splitting different tabs into different processes which means they are taking advantage of multithreading if you have more than one compute intensive tab/window open.
You only need the focused tab to be snappy, but to let it be snappy you need to keep all the other work away from that core. Gmail updating emails, youtube playing a video in the background, discord pinging chat messages at you, and so and and so forth.
With a modern javascript engine you can throttle the activity of tabs that are not focused. (And browsers do indeed do that. Pretty aggressively, too.)
I have a crappy old Celeron 847 laptop, and my browsing experience is very much okay, not that different from even i3-8100. Yeah, I do sometimes hit very heavy sites, like bloomberg.com, but overall, experience is very much satisfactory.
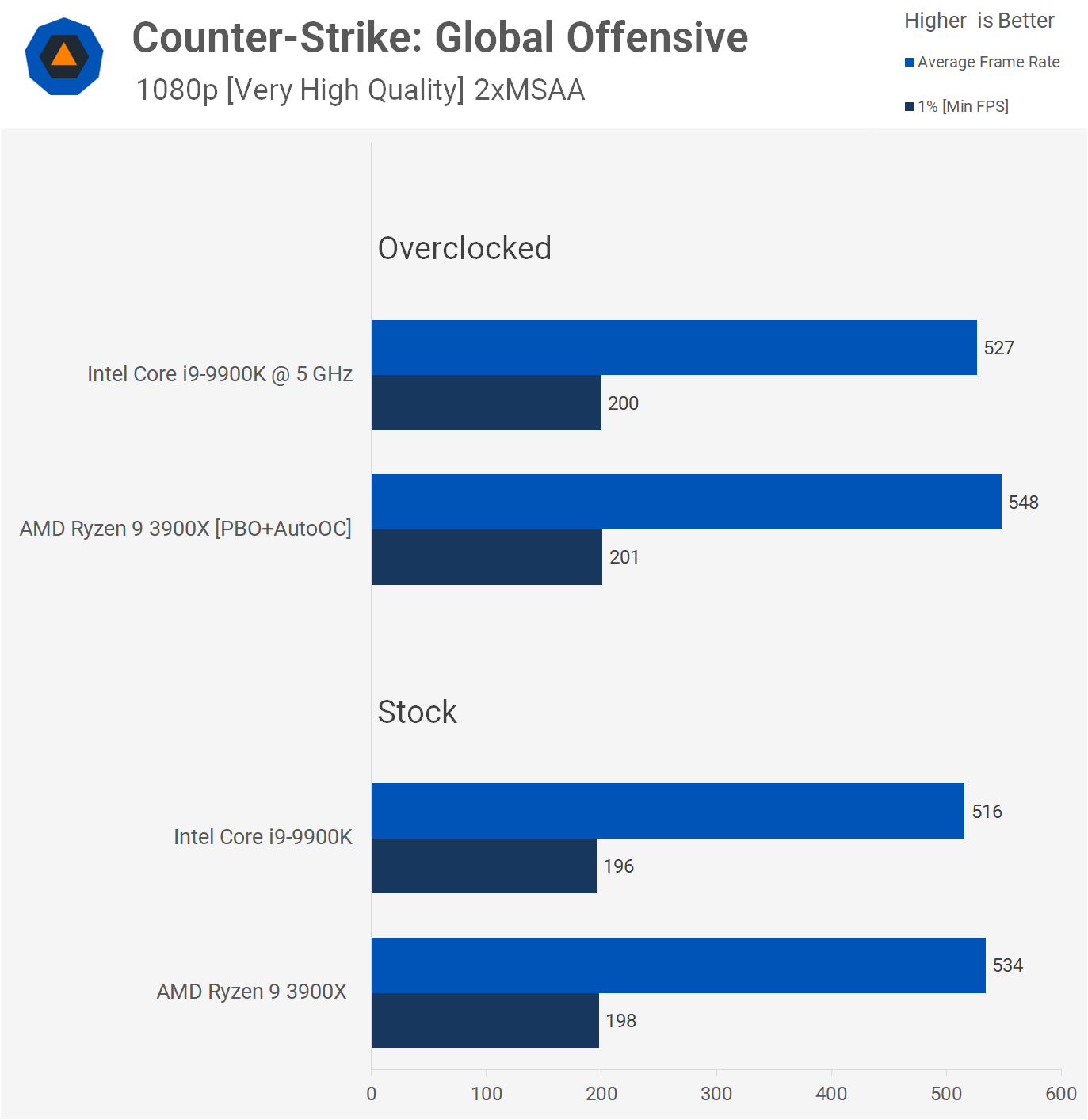{kind=link}
{kind=link}
> The 10900K has a 125-watt TDP, for example, while AMD's Ryzen 9 3900X's is just 105-watts.
My understanding from other articles (like [1]) is however that Intel had to _massively_ increase the amount of power the CPU consumes when turboing under load:
> Not only that, despite the 125 W TDP listed on the box, Intel states that the turbo power recommendation is 250 W – the motherboard manufacturers we’ve spoken to have prepared for 320-350 W from their own testing, in order to maintain that top turbo for as long as possible.
Somehow it feels like back in the Pentium 4 days again.
[1]: https://www.anandtech.com/show/15758/intels-10th-gen-comet-l...