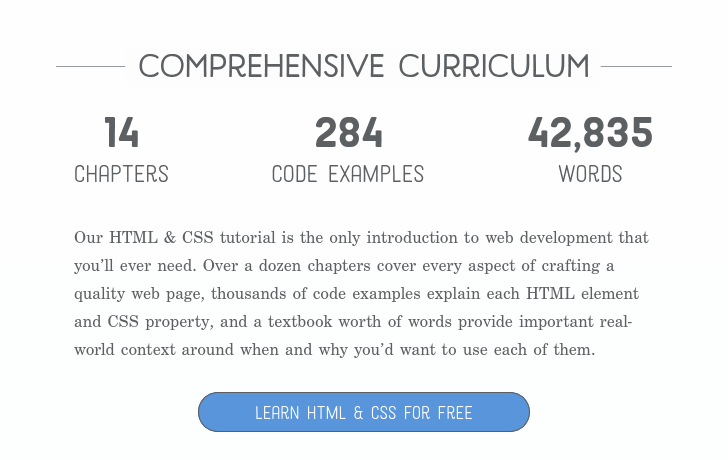
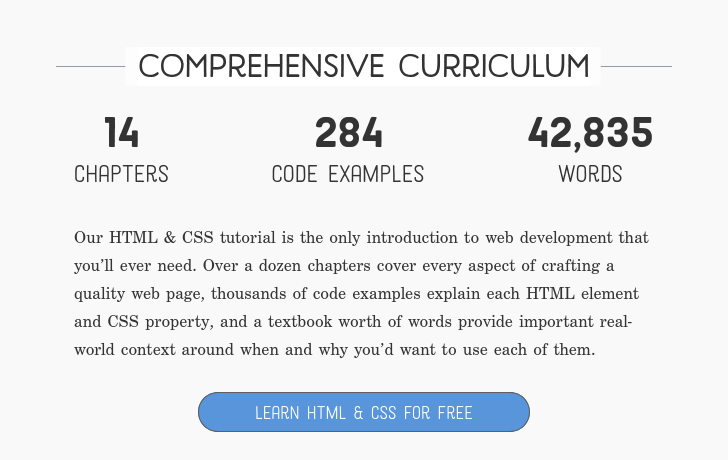
This is great. The decision to skip CSS by depending on https://simplecss.org/ is smart - CSS is a whole other thing, and having that on top of basic HTML would be pretty intimidating.
Not sure how best to approach that though. Having a whole chapter of the book explaining files and folders feels pretty redundant. Maybe there's something good you could link to?
It's crazy how bad the mobile epidemic has gotten. There are kids coming into a Computer Science degree that can't figure out how to unzip a zip or even finding out where files get downloaded to. (Fwiw, those I know dropped out before 2nd year)
My dad was asking me a question about backing something up onto Google Drive, or saving space on some cloud storage account, or something.
He was using the mental model of files and folders -- that files exist and refer to stored bytes, and that there can be one or several copies of a file. There can be links to a file that take very little space relative to the file.
I had to tell him that I have no idea what sort of storage model these services expose, if any, and that the concept of a file system backed by a storage device is not the analogy that applications expose to their users these days.
He eventually understood, but I could feel his frustration -- that the mental model he had was really just chosen by a past moment in application design, and that what replaced it is nebulous and disempowering.
When i use google drive, the interface appears to be folder/file structure. Whether it is or is made to look that way is irrelevant, i suppose, as long as it works that way. I can also increase storage by downloading/deleting things so Im a bit flummoxed.
In my opinion, Google Drive is basically the same as the traditional file structure. Where it gets very confusing for people is when it comes to collaboration. Before 2020 or so, there was confusion around copying the same Google Doc so it appears in multiple locations, and making shortcuts to it instead. Look up stuff around the “Shift + Z” keyboard shortcut if you want to learn more.
I don't remember if he was trying to save space on his Google Drive or on his phone. His question was, mostly, that if he deleted files in one place, where would the space savings appear? I immediately thought of Windows' OneDrive and how it's sort of an automated rsync setup. I didn't know enough about his phone, which apps he was using, or about Google Drive to give an answer better than "I don't know, and I detect that some of your assumptions are probably wrong."
It’s ridiculous how complicated it’s gotten to answer my parents’ questions about stuff like this. The old desktop metaphors are gone. Screens are difficult for older eyes to read. Every app has a cloud service. Really seems like huge step back in usability.
For my Dad, we got him a “simple phone” – it basically does calls and texts, has big buttons in pretty much the style of old Nokia phones but chunkier. The screen is larger and higher resolution than those, so the text is nice and clear. It works really well for him in terms of being able to cope with it with his eyes and getting the job done.
> Every app has a cloud service
And that phone doesn't run apps at all… For things beyond calls and texts¹ he uses a laptop, largely keeping with the files/folders metaphor and no extra apps.
----
[1] managing his banking, certain shopping though he often instead asks one of us to do that as he is wary or falling into scam sites, facebook for more passively getting news on what family a-far is getting up to, his collection of digital photos (he used to take a lot), and such
It gets confusing when you use all google services though, because while google photos technically use your drive space, they aren't really exposed that way. Android generally gives you a warning that when you delete a photo that it's also being removed from your cloud storage too though. But google photos will also constantly prompt you to let it delete your local copies and only have the cloud copies, so you end up having no idea what they are actually doing. Just drive itself is pretty straight forward though since it's mostly separate from the phone and deleting from the phone has no bearing on what's on drive, unless you deleting from within the drives app itself.
Try enabling Google Photos to automatically upload images from multiple devices to the same account.
If Google Photos is low on space, try deleting from Google Photos without causing it to delete from all other devices. Seems to require manually copying all those files to an untracked folder, then deleting from Google Photos.
Try managing which folders Google Photos syncs:
When it asks to add a newly found folder, the app doesn't give any way to find out where that folder is or what's in it, unless the folder's name only occurs once on the device.
Try removing folders from the app ("Whups, didn't mean to backup all the graphic assets of a random app that foolishly doesn't use 'nomedia'!"), where the folder name is not unique. It again gives nothing more than folder names and no indication of where they are or what's in them.
Try getting Google Photos to list where every file first came from, so you know where the originals are (for various reasons).
I take photos on my phone, and they are automatically backed up. I can access them on all my devices, and I have them even when I change my primary phone, so I am happy. I only backup my camera photos, so I guess my needs are simple. So it suits my needs. I can disable it from backing up any other folders, so random photos don't end up in my library. I never needed to find out where a photo was backed up from, because I only care about my camera photos.
I'd say half of my first-year CS students don't know how to create a folder with files, at the start of the school year. To me, it's nuts. But on the other hand, lots of students are very curious and come to learn. You can't blame them for not knowing something.
I try not to get overly-annoyed at this kind of thing too, but to me it just demonstrates an incredible lack of self-drive, or curiosity, especially in the CS domain.
If the students are genuinely curious, there is nothing to stop them learning about pretty much any topic in CS - really. There are few university subjects where the entire syllabus is freely available online in almost every format imaginable the way CS often is, and very often the computer you already have works just fine to learn it on.
When I was a kid, this wasn't something I could afford or that my parents were willing to pay for. I did oftentimes use the library computers, but they were locked down (of course, half the fun was finding ways around that.)
I was very lucky that my middle school (in a fairly low-income area) was given a grant by NASA that allowed them to supply all of us with laptops during the school year. I surely wouldn't be where I am today without it.
In some respects, a modern mobile phone has more in common with minicomputers than minicomputers had with computers before keyboards and file systems. Being able to interact with computers in a meaningful way transformed computers from programmable calculators and data processing machines into something entirely different. I would imagine that more people have seen those archaic computers in museums than during their service life simply because there was no need to interact with those computers back in the day. Even a web developer has more direct control over a server in a data centre than most early programmers had over early computers. (At least those used in businesses. Computers used for research were a different story.)
Ya, I have to agree. Although you may learn, it's clearly not the primary intention of a University to teach anything but your ability to do whatever it takes to score well or do publishable research.
>To keep that line of reasoning going, what is the purpose of the university, if you're supposed to learn everything on your own?
It's not that you have to learn everything on your own though, it's that if you enter a program without having some understanding of the basics, you're going to have to pay to take a bunch of remedial classes.
It'd be like going for a mathematics degree when the highest class you took in high school was algebra, where the normal degree students would be starting with Calc 3 or Differential Equations. You might be ok in the major or you might not, but you don't even know enough to start on the path at that point.
A good CS course isn't really about programming in that sense. A CS degree is to programming what a maths degree is to, say, statistics methods, or at least it should be. You are expected to learn the “hum-drum details”¹ yourself (perhaps with guidance of course) or already know some of them, with the course exploring wider or deeper concepts (the why, wherefore, and therefore, of those details).
Your maths degree probably did as much as a CS degree would have done (expanding your ability to learn, analyse & problem solve, etc.) allowing you to learn the technical details of programming on your own. CS was essentially birthed from a branch or two of mathematics, after all!
People who want/need a programming course (which is perfectly valid, I don't mean to denigrate the position in the slightest) are probably not best served by a traditional CS degree.
--
[1] “hum-drum” sounds a bit too negative for what I was intending, but my brain isn't firing on all cylinders this morning and I can't think of a better term for what I was thinking there!
Not everything, but university is a big shift towards self directed learning.
Lack of understanding coming into the courses causes issues, when I started we had to delay things because some students hadn't encountered matrixes and the maths around them.
So sure, they can teach these things but it adds to what they already are trying to teach. A lowered base means less of the advanced content can be taught.
CS has always been a lot more like the arts/music than most other majors, in this regard. If you don’t come in with way more knowledge about and skill with computers than the median college-bound high school graduate, you’re gonna have a bad time.
It’s kinda shitty, but for a long time PC gaming as a gateway drug for young kids let universities just assume a fat pipeline of already-computer-savvy applicants.
I'm probably old, but we used to learn DOS prompt basics (and folders and files and stuff) in what would be the equivalent of junior high school in the US. And not in special courses, it was "normal". Heck, I was even introduced to Microsoft Basic at school while in the equivalent of 4th grade on these funny Thomson MO5 computers.
But that's not what they are taught now. They are taught to use social media and cloud services, which is completely useless since they figured this out themselves already.
The education system here just keeps them early in a consumer mind state. It has absolutely no ambition and is just a race to the bottom.
>I'd say half of my first-year CS students don't know how to create a folder with files, at the start of the school year.
I learned CS ~20 years ago and it was mostly the same. Half of the first year is people that are vaguely interested in computers, video games, or heard it was a good way to make money, and didn't really have any real skills going into it.
It is somewhat different now, because there are students that think they are good with technology but really have no idea how things work, they just think they know because they are slightly better than their peers at using phones and tablets.
At one point, every member of a CS program started without having ever seen or touched a computer. Everyone has to start somewhere. We do not reject new biology majors because they had never touched a microscope before entering the program.
Sure, but I think the typical path for those who survive and strive in a CS program is to have touched a computer for the first time well before starting work on a college degree for it.
That's like trying to learn a foreign language by picking reading War and Peace in that language, without ever having seen a single translation to that language, or having already read War and Peace in your own. There are a lot of steps you need to take before then.
I would also be pretty surprised if a biology undergrad had never touched a microscope, possibly with the exception of the most impoverished among us. I imagine most people have tried one at some point along the K-12 journey, and there are more introductory treatments of e.g. life science on the way as well.
Starting CS without having "seen or touched" a computer would be like a biology undergrad who wouldn't be able to tell you whether a dog or a tree is a plant or animal.
The difference is that these days the people are surrounded by computers and probably interact with a computer many hours every day, yet they are barely more tech savvy than that first lot who had never seen a computer before.
If you're saying that at one point in history, a given cohort of new CS students had never seen or touched a computer, I have my doubts, but it depends on how you define CS program. Before computer science was a formalized education stream, it had a variety of other names like "Business Computing" or something related to information technology, but you'd have to go pretty far back imo before you find a whole classroom of entrants into such a program that had never seen or touched a computer. By the time it was called CS, I do find it a bit of a reach that you'd find less than say 10% of students opting into taking it without that low bar being passed.
Likewise the biology example seems strange; sure maybe people haven't used a microscope specifically (unlikely imo), but they very likely have used any number of other implements and taken at least one secondary school biology course
>We do not reject new biology majors because they had never touched a microscope before entering the program.
No but you'd presumably make them take some remedial classes that the mainstream students wouldn't be required to take. Or maybe not, I'm not sure how it works in biology, but in the harder STEM majors, you're generally expected to have some basic knowledge beyond what the 'easy' track at high school required for graduation.
Calling it an "epidemic" isn't really helpful. The reason there's this shortcoming isn't because it's some problem inherent to those darn kids, it's because the state of computer education is expect them to just figure it out on their own when they have no need or reason to do so.
I've seen younger generation only use Google Docs and streaming services (music/video) and not even understand what a "file" is, because everything is just on the internet.
Mm, that's not exactly true. Having done a bit of Android development, these days you're rarely operating on a "home directory" structure like you might be familiar with from Windows, Linux, etc. Instead you're saving files to a "container" filesystem that's exposed to the user in a few facets: Downloads, Photos, Music, etc.
What's even more confusing is that some apps save images directly to the "Gallery" which is separate from the "file and folder" view you get otherwise. So (as an inaccurate example), Fujifilm's app might download directly to your "Camera Roll" while GoPro's app might create a "GoPro" directory to dump photos/videos in, which offers more separation but doesn't appear in the "Photos" app by default.
Some apps even have toggles to switch between these two methods of saving files - though if I recall correctly, the non-Gallery/Camera Roll method (while desirable to many users) of saving images has technically been deprecated for a while.
My apologies, what I meant was "saved" to. Different applications have different default locations without ever prompting for it. I did figure out where FF mobile downloads files.
But attempting to save an attachment (from Telegram, WhatsApp, Viber...) and then either open it or attach it from another program leaves me perplexed. I generally rely on "share with" to avoid this, but I am guessing not all apps register proper MIME types or detect them properly so the option I need doesn't show up every time.
I guess the fact that I mostly moved from DOS to Linux never really got me away from thinking about files and directories, and inconsistency in Android really bothers me.
>I guess the fact that I mostly moved from DOS to Linux never really got me away from thinking about files and directories, and inconsistency in Android really bothers me.
Been there too. After some (maybe a lot) investigation I learned that this "inconsistency" in Android happens, because some apps use "private" directories which you (or other apps) aren't allowed to look at. Think of these as directories of user Linux users who turned off read access for others, i.e. "chmog og-r $HOME"
After finding apps like Solid Explorer and especially Termux, I learned to comprehend what's going on. But I still hate it that apps (and Android) prevent me from looking at my data the way I like to do it. For "security reasons" I not allowed to view things on my devices? Sheesh!
Nice apps like Markor or Diary (from Bill Farmer) store their data in user visible directories. As such apps exist, I tend to ignore those with limiting my access.
I get your frustration, that was an inconsistency I disliked about Android too. I felt like it was fairly normal for "power users" to have an 3rd party file browser with more functions to help manage the files on the phone.
One thing I appreciate about iOS is there's a Files app/UI, and if your app wants to save some user-facing data, it can go into the Files app. From there it's a simplified Explorer/Finder type file browser. It's not perfect but its consistent to me.
It’s also just what people are familiar with and had to learn.
I know incredibly competent web developers who don’t know what SSH is or how to use it. Boggles my mind, but I grew up with it so it’s what I’m used to.
> can't figure out how to unzip a zip or even finding out where files get downloaded to.
I have issues with that. FF doesn't show the path in the list of downloads. There is a button to start a file manager, but I have no file managers installed, so button doesn't work. In some cases I didn't find the better way than to copy the link and to download again with wget.
Well, I manage it sometimes, but I then I forget how I did it. I think the way to do it, is to try to download something with ff again, but stop at the file chooser dialog to figure out where it points to.
Click the folder icon on the right-hand side of the entry in the download list (it should have "Show in Folder" hover text). If the file is still in the place where Firefox originally saved it, Firefox will instruct your file browser (Explorer on Windows; whatever else on Linux - for me, it's Nemo) to open a window for the containing folder. Otherwise it will add "File moved or missing" text to the entry.
As frustrating as I imagine it is to be in the position of having to figure out how to teach students things that seem like basics they should be aware of, I'd also argue that this issue actually stems from two circumstances that are worth this cost: the filesystem abstraction is increasingly unnecessary for non-technical people, and incoming students who want to study computer science aren't required to already have technical knowledge beyond that of their non-CS peers. The alternatives to where we're currently at would be either regressing the usability of interfaces for the overwhelming majority of people or taking away access to computer science education to people who didn't or couldn't go out of their way to learn topics that only matter to technical people in advance.
The growing irrelevance of the filesystem for the average computer user isn't a ln "epidemic" any more than the obsolescence of the CLI for the average person; it's just additional progress towards adapting computers to be more human-friendly rather than the reverse. We didn't used to have cars with automatic transmissions, cruise control, or blinkers that turned off on their own once you've finished turning, and no one describes the evolution evolution of the way we drove cars from decades ago to the present in the same language as a public health emergency.
Over time, technology becoming simpler to use by parts of the interface getting pushed down into implementation details is a good thing for the vast majority of people in the long run, and it's important for those of us who are technical not to mistake the requirement of a certain feature for the ability to access it. I think the biggest concern with the dominance mobile computing isn't that users might not need to know about the filesystem but that users might not have control of their own devices in the long run if the ability to access the filesystem is removed. There's precedent in getting support from the non-technical public to care about technical details when they understand how it affects them (e.g. right to repair, the pushback against SOPA/PIPA, net neutrality), but I that we'll miss the window to influence things similarly here if we focus on the wrong thing.
We need freedom, not paternalism. And yet, somehow, despite this nanny state utopia, my data gets leaked approximately once every 17 minutes. Security my entire ass.
It should be like a physicist studying Carnot Engines not knowing what neutral is; but for some reason Computer Science degrees are also expected to be developer certificate programs.
The distinction probably came from Macintosh though it was more pronounced in Windows 95 - also it is the other way around: something can be a folder but not a directory. Classic example would be the "Computer" (or "My Computer") in Windows which is a folder but not a directory. The Windows Shell maintains some sort of VFS that exposes these.
Generally a folder is a directory-like thing that groups file-like things but not necessarily mapped to real on-disk directories and files - and more often than not, it is exposed via GUIs rather than command line applications. Of course that is just common use not anything inherent - after all on Linux it is common to expose stuff via the filesystem (sometimes in addition to VFSs) that still uses the terms directories instead of folders with the only difference for when one is used or the other to be if it is done via a command line application or a GUI application.
> Classic example would be the "Computer" (or "My Computer") in Windows which is a folder but not a directory
This sounds backwards to me, going by the real life counterparts for these terms. A directory is a list of pointers to items located anywhere (eg. a phone directory for a business may contain corporate and other remote numbers alongside local extensions), but a folder contains actual files that are physically located inside it; you can put references to remote items inside, but only by placing a physical representation/reference inside of it.
I was first introduced to "directory" as a type of signage at malls or clusters of shops, listing where things are. Usually also having a map, with a red triangle labeled "You are here.". Then I learned that telephone books could also be called be called directories.
My first exposure to computers that had a file hierarchy used the term "folder". When I eventually encountered "directory" in computer usage, I was confused because I thought first of signage in malls.
It still "feels wrong", so I usually use "folder". (-:
I was always a little disappointed with how most web browsers choose to render HTML pages that had no explicit styling information. I'm not necessarily saying web browsers should have defaults as opinionated as simple.css, but the default page margins, padding, text styles, headings, etc that they picked aren't particularly attractive.
Opinionated web developers will override the defaults no matter what they are, but if the convention was to have more attractive defaults I wonder if that would have resulted in a larger share of personal websites and blogs created using plain HTML.
Oh absolutely, that ship has long since sailed, it's just me lamenting a world that could have been if something closer to simple.css or tufte-css had been the norm.
Though with "reader mode" becoming more popular I wonder if there's a place for a browser with more opinionated defaults.
There's a lot of sites between pure html and modern css. "Simply" rendering things differently would definitely break a lot of sites. Just imagine if browsers started defaulting to *{box-sizing: border-box;}.
There's a reason why the CSS ["reset"][1] is still with us - the lower level user-agent stylesheet never really adopted any of this stuff. Presumably, this was to reduce the delta between browser engines (vendor prefixes, etc, etc.) but it would be nice to see some movement in this area.
Good article, but the reason is obvious: When opening an app or a web app stopped opening a new document and started to present a list of recent documents, that was the beginning of the end. If someone wants a file, they open the app for that file and scroll down. They have never needed to make sense of a file existing independently of the app in which it was create and may be viewed. This process was cemented by iOS's absence of a file manager.
> the iOS Files app has allowed access to local files since 2019
Huh. I just opened my Files app on my iPhone 12 and went to On My iPhone (which was 2-3 more taps once arriving in the app). I don't see many of my files though, just a few. Some PDFs and a Spotify folder. But I don't see my pictures there? Or are pictures no longer stored as 'files'? Or do you mean that the app has allowed access only to some local user files? It's not all local files. And it's not all non-system local files. And it's not all user files. In fact it is missing > 99% of my user-space files (specifically ones created with default-OS applications on device, by the user).
And if I make a Note in the Notes app, will it show up as a file in the Files app? Probably not, I would guess. Because the note probably isn't really a file anyway. So pictures aren't files, and notes aren't files. What would a file be then? Are files only PDFs? That's the only thing that shows up for me. I guess PDFs are the only things that are files then!
Super confusing experience. I'm a mobile app developer by the way - on Android. Android sucks at this too of course. But the iOS Files app is much too limited to enable users to 'get' the concept of a file.
Photos taken on the camera, shared to you, or “saved to photos” will live in the Photos app. The files app primarily contains things you download from your web browser, including images downloaded and not “saved to photos” and images extracted from zip, etc. I guess some apps can save data there too. It would be nice if there was a back road to images stored in Photos app via Files app, but the distinction is otherwise well defined.
Aha! So some photos are actually 'files', but some are not! The confusion continues! I get why Apple has it this way - current iPhones are very very popular and selling them with the current UX makes Apple a lot of money.
But it's pretty clear that the Files app is not meant - in any way - to help users understand computers, what files are, etc. It is obtuse and confusing as soon as the user wants to leave the iOS ecosystem (even to go use a Mac).
My girlfriend had the craziest workflow. No laptop, only iPhone and iPad Pro. She had an external USB-C hard drive, she couldn't connect it to her iPhone but could to the iPad.
What she would do is airdrop photos from her iPhone to her iPad. Copy them from the gallery to the Files app. Move them in the files app to the hard drive. Then delete them from the gallery app, delete them from the Files app and the trash.
For some reason, deleting files in the Files app didn't free up space on the iPad. So she had to uninstall and reinstall the Files app to get the space back.
As a Linux user that grew up DOS, the whole thing just broke my mind. She was frustrated and I was frustrated I couldn't help her.
you're jumping to conclusions. One does not follow from the other.
(a) apple doesn't show users all the files on their iPhone
(b) apple makes lots of money
There is no evidence that a causes b. It's possible showing the files would make them even more money. It's also possible showing the files would have no effect on how much money they make.
It may not go over well but I don't think this is some generational thing. Its just plain pure laziness that has become epidemic.
>Joshua Drossman, ..the laundry basket where you have everything kind of together, and you’re just kind of pulling out what you need at any given time,” he says, attempting to describe his mental model.
>I try to be organized, but there’s a certain point where there are so many files that it kind of just became a hot mess
Yeah.....need I say more? Other than gross. I think those statements prove my point better than I can.
Like most on HN I'm extremely computer savvy and I've yet to find a way to avoid dealing with file/folder models and I've tried. All other ways fall apart no matter how "advanced" they are. Maybe it will change with LLMs but so far there is no way for the computer to anticipate what you do/don't want and organize for you.
As someone who is involved in a community run wiki, people will say "that page is wrong" and when you say "please edit it" will say "its too hard" or "I do not have they time".
They will, however, write a long Facebook comment explaining what is wrong and explaining that they cannot edit a wiki.
I'm probably around the average age on HN, so I grew up with early Windows. Yet after years of trying and failing to get into different note-taking/productivity apps, I finally found inner peace by using Obsidian and embracing the exact millenial "laundry basket" approach the article talks about. Maybe 10% of my notes are in a folder, the other 90% all together in the root. Turns out what mattered was 1. the lowest possible entry barrier to writing a note and 2. speed.
Yeah, I think you're right about that. I'm not sure whether I want to write something of an appendix myself and link to it, or find something else on the web and link to that.
I think the fundamental approach being taken by this project is immensely valuable to the world. This kind of education about open standards might actually be the most powerful tool that can help us take steps in the direction away from giant opaque corporations and back towards the systems based on open standards that the internet originated from. I really hope this project continues to be updated and get more and more eyes and contributors. If you feel the same way, I'd say at least throw it a GitHub star. https://github.com/blakewatson/htmlforpeople
(Note: I have nothing to do with this project thus far and have nothing to gain from saying this.)
HTML for People is waaaay more approachable than this. My wife could follow the HTML for People tutorial. It shows you how to create a real web page in a real browser without first bogging you down in coding details.
The MDN tutorial is talking about img alt attributes before you even create a single .html file! That's how to put people off.
As a technical person who recently taught myself frontend from scratch, I found https://web.dev/learn way more structured and thorough. The CSS lesson covers all the essentials and actually made me enjoy working with CSS.
web.dev doesn't get as much love as MDN, but it totally should!
That’s the website my high school used in engineering sciences classes to give students an introduction to HTML. I don’t see the point of your comment (I think it’s sarcasm, but I’m not even sure), can you be a little bit more constructive?
The point may be that OP's guide is not meant for high school/engineering students, it is meant for everyone. MDN's "introductory" sections have too many big words to be of use to laypeople.
I really hope so too. I really wonder what would happen if there was an alternative like... instead of spending X dozen hours learning how to use WordPress, or MS Word for that matter, people (in the general population) felt like spending those X dozen hours learning HTML was a viable and useful alternative to achieving their goals!
Will you add on to it to include custom CSS, or maybe a section for using different CSS templates (and where to find them), to make a slightly larger website like your own (blakewatson.com)?
No I think I will probably keep it focused on HTML. I think my "CSS basics" chapter is as far as I want to go with styling. But I would love to see other folks publish easy-to-understand CSS tutorials.
::backdrop was useful to me. Right now I am learning the last two years of stuff, refreshing my frontend skills. Things like scoping are a dream come true.
I haven't got all the way through it, but seeing the contents drop-down made me feel at home.
I put document structure first so the content looks good with no styling and no class attributes. I use no divs, just the more sensible elements. Sections, Articles, Asides and Navs work for me. There should be headings at the start of these elements, optionally in a Header and optionally ending with a Footer. The main structure is Header - Main - Footer.
Really there should be a need to keep it simple, and that begins with the document structure. It is then possible with scoping to style the elements within a block without having to use any classes except for at the top of a block.
It infuriates me that we have gone the other way to make everything more and more complex. We have turned something everyone should be able to work with into an outsourced cottage industry. Nowadays the tool chain needed for frontend development is stupid and a true barrier to entry. Whenever you look under the hood there is nothing but bloat.
My approach requires strict adherence to a document structure, however, my HTML content is fully human readable and the content looks great without a stylesheet, albeit HTML 1.0 pre-Netscape looking.
Tim Berners Lee did not have class attributes in HTML 1.0 but he did want content sectioning. Now that there is CSS grid it is easy to style up a structured document. However, 'sea of divs' HTML requires 'display: contents' to massage the simplest of form to fit into a grid.
I feel that a guide is needed for experienced frontend developers that are still churning out 'sea of div' content. In the Mozilla guide for 'div' it says that it is the element of last resort. I never need the 'div' because there is always something better.
The CSS compilers are also redundant when working with scoping and structured content. Sadly my IDE is out of date so I have to put the scoping in at the end as it does not recognise @scope. Time to upgrade...
Anyway, brilliant guide, in the right direction and of great interest to me and my peculiar way of writing super neat content and styling.
Well done! I really like how you make people write bare text, publish it and bam, that works, just like this, and how you ease into html.
The text is very well written, straightforward, welcoming, well structured. It seems easy and enjoyable to read.
I believe that putting html in non professional hands is a good goal.
Some feedback:
- About <meta charset="utf-8">, it seems to be introduced quite late. People comfortable with English but wanting to write their website in their own language might be surprised. Or even people with accents in their names (you are putting your name in the title, people will probably try this). You also say that it's for special characters like emojis, but you should probably say it's essential for most languages that are not purely ASCII (event English with words like cliché). Maybe you could introduce that earlier and say that it's there for historical reasons and that without it, you may have issues with characters. To be checked but it might be better to put it before <title>.
- body, head, html tags are mostly useless, except for html because of the lang attribute (accessibility + some browsers incorrectly offering to translate)
- vscode is a bit unfortunate because of the telemetry part, and seems quite heavy and complex for the task. On Windows, notepad++ is a great option. On Linux, any default text editor that's already installed will do. There's always codium, which is code without the bad parts. The intended target doesn't know about the bad parts, so they are installing spyware without knowing.
I didn't know about the aria current page feature, I'll start using this.
Don't you actually need to set something in the text editor to save it as UTF-8 in the first place if you are going to put that tag? Wouldn't Notepad for example use UTF-16 by default like the rest of Windows?
> People comfortable with English but wanting to write their website in their own language might be surprised.
A main complication here is that people don't even know about character encodings, so you can't reasonably expect them to save index.html in UTF-8 in the first place. (For example Windows notepad would use the active code page by default.) I agree that it should be featured prominently if that saving issue can be also addressed.
I love the idea and I'm thrilled to see more sites like this out there. But I do think this assumes a level of computer literacy that isn't consistent with typical, non-technical users.
Step 1 starts with:
> Pick a location on your computer and create a folder. Call it my-site or something similar.
You've already lost the vast majority of people right here. There are a shockingly large number of people out there that use computers EVERY day that won't know how to do this.
It's weird seeing this getting emphasized over and again in this thread.
> There are a shockingly large number of people out there that use computers EVERY day that won't know how to do this.
That's very hard to believe. Even my mom, who doesn't use computers at all, would know what folders and files mean.
The people who don't know what files and folders are - can't immediately be beneficiaries of this guide, right? They have a lot more fundamentals to cover before anything like this.
As far as I've noticed, it's not older people who have the issue but younger. The average 22 year old today has been using mobile devices as their primary device for 10+ years. This is especially noticeable amongst poorer families, where a $20 a month low end financed android phone is much more of an option than a $300 computer.
It's a bit of both, really. The typical computer or mobile user doesn't have general purpose computing knowledge or expertise. They don't know how their computer works or what any of the things in it ARE. They know how to follow a particular defined sequence of steps to get an outcome.
I worked over the phone tech support for a few years about 20 years ago, and it really opened my eyes to how far the gap is between the tech literate and everyday computer users.
I think this guide is terrific, for what it's worth. I just also think there's a lot more people out there that this guide SHOULD help, that it won't, because of that fundamental gap.
So what? It is mentionned in the introduction that it is meant for computer users:
"What do I need?
You need a computer with internet access. I wrote this book in a generic way so that it would be applicable for people using macOS, Windows, or Linux. If I point you toward software to install, it will be free (or have a usable free tier) and will be cross-platform (or I will offer platform alternatives)."
https://htmlforpeople.com/intro/#what-do-i-need%3F
If this is true then it's very sad. Is this what people have been reduced to? I would have been able to follow these instructions as a child (in fact I did build my own website when I was 10).
Are you sure it's this bad, though, or are you not giving people the benefit of the doubt? How can it be this way? Is it due to people using cloud apps for everything?
It seems to be the case. See the other thread of people not knowing what a file system is.
In the past tech education felt useless because teachers were so far behind, maybe it’s time to revisit now because now the younger generation is far behind.
OP here. Yeah, I was a bit worried about this, and even though I kind of mentioned it in the introduction, I think it deserves more attention. I'm not sure if I want to write something and host it myself, or maybe just point people to some kind of primer on creating files and folders.
If you're concerned about this I think the only solution is to get feedback from your audience somehow. Watching someone try to follow the instructions can be enlightening. I personally doubt it's that bad, I think people know how to create folders, but I might be wrong. If not, directing them to "<os> for dummies" might be a good move.
I have tried so many times to convince non-technical people that they can put together their own website quite easily, but so often they think I'm joking and that it requires a lot of effort.
Next time I'll refer the to this site and ask them to give it half an hour and see what they can create in that time. I know that so many would get hooked if they just get that first taste of "wow, i just published something on the actual web!"
@blakewatson: Any plans to add i18n to the site and accepting pull requests for translations?
Yes! I would love that. I need to update the readme, but I think my strategy would be to place translated chapters in a subfolder, (eg, "/es"). I can configure Eleventy to generate a different nav menu based on the subpath.
Schools should really be doing this. I had to make several personal websites in high school and college, that were just HTML and maybe a little CSS (or just old HTML styles). This should be everyone’s first step, imo. It’s a great way to write something and see results quickly and easily. It doesn’t even need a server.
Why, “Start coding already!” rather than something like, “Start writing already?” I think half the barrier to people building sites is that they think they need to know how to code, and that seems scary, but they do know what they want to write, and that seems more approachable.
OP here. Oooh that’s a good suggestion. Yeah it’s hard to shed the webdev persona and see it through fresh eyes—even though I specifically tried to do just that!
This is great. I love you how started with a tiny HTML file and didn't immediately ask the user to install NodeJS and VS Code and a ton of other webdev shit.
This is a lesson that a lot of professionals could stand to relearn. They don't actually need hundreds of MBs of JS to display basic text and images. Accessibility and failing gracefully are way too often ignored.
Isn't doctype still required by the spec in HTML5 in order to be "proper"? Perhaps I'm mistaken but I thought I remembered that it's technically 'required'.
It is, but I'd argue that people wouldn't even notice that the document is in quirks mode.
I think you'd really only want a TITLE tag so that it appears as a tab name. Anything else is really optional for people and you'd only really need BR, A, and IMG
This is a brilliant endeavour and incredibly well executed! I’ll certainly be bookmarking it to share with others.
I’ve recently decided to start adding to my website with just hand-written HTML, and slowly migrating the back catalogue. I love its directness, its ability for ad-hoc changes to a page and its robustness. After trying almost every system for publishing on the web under the sun; I’ve concluded HTML is the right tool for the job, even if it means a little extra work up front.
As a retired developer I’m happy to tinker with Rust or SQL or something embedded when the mood strikes, but when I want to write, I just want to write - and HTML kind of lets me do that. I think if more people saw HTML as a document to author rather than just a build target then we’d have a lot simpler systems. This mindset has resulted/allowed for a huge dumbing down of average computer/web users and huge headaches for developers. I can’t think who all the complexity we’ve brought into the world serves 99% of the time.
This resource might be one of the things that nudges us back on track.
Thank you for being one of the few people who realize TextEdit on the Mac supports plain text. The number of “experts” who say it doesn’t support it and tell people to download some other app drives me nuts.
An absolutely great tutorial and something I wish I had when I first started playing around with HTML about 11 years ago (I’m 26, quite late to the party).
Even though I’ve been working as a full-stack for quite a few years now I’ve been hooked while reading just imagining and remembering how magical building my first few websites used to be.
I’m hoping this will get some more people to realize how easy it is to build your own webpage and how much fun it can be building your own little place on the internet.
I still remember creating my first html page back in the 90s. It felt really magical creating it with just Notepad - changing the bgcolor of a page to red or blue or whatever, was amazing.
This is great, but most people don't care about coding or building their websites for scratch. Most people don't work on their own cars. Authors don't bind their own books.
People want to share their thoughts, stories, and photos. In my opinion, we need better tools to allow people to create their own sites without needing to code.
While you're right, I like to think that people, especially kids, would greatly benefit from seeing this stuff once or twice in their lifetime. They don't need to learn it or use it, but they will forever recognize it. And maybe one day they'll have to write that closing tag someone forgot.
This can be applied to all topics. Knowing the basics of everything is better than knowing nothing.
People who don't care can continue to not read the things they don't want to read. But those same people should be prepared to pay money for someone else to care for them. This is not a new situation.
Yeah I agree that is true for most people, but there are also people who do want to code their own website from scratch, and for them this is a really good introduction.
The concept is great, my father, which is a doctor, bought a minibook at a newsstand about HTML for dummies. At the time (maybe 98 upto 2000) explaining the good old markee, blink and other tags besides the basic HTML document composition. So, I think learn HTML is for everyone!
I plan to dig in deeper, but this looks like a great introduction to building websites.
I teach a one semester high school Web Design class and currently use a mixture of lessons from these two for learning the basics of making pages by hand with HTML and CSS:
I have to say, for me, https://internetingishard.netlify.app has uncomfortably pale body text.
It is #5d6063 on an #fdfdfe background where I sampled it.
(The background is `linear-gradient(0deg,#f9fafb 0,#fff)`.)
The serif typeface looks too thin on a low-res display.
I think that if you want to lower the contrast of a dark-on-light page—well, first, don't lower it too much [1],
but second, it is better to make the background darker than the text lighter.
Avoid thin faded text.
This is how I learnt to program as a kid around 1997. My dad taught me to do exactly this. I didn't have it up on Neocities, though, in fact I didn't put something on the public web till years later, should've done it sooner! So I just had my own little website with multiple pages that were meticulously maintained.
However, I did become quite lazy and would never have continued maintaining it as raw HTML. I discovered PHP which gave me superpowers, but it is quite a paradigm shift. I wish I knew about static site generators sooner.
A few months back, someone asked for suggestions on which new AI options to learn to beef up his marketing career. I told him to learn HTML first. That will be useful for a long time and will likely last his lifetime. After that, he can start learning others.
> I don’t think websites were ever intended to be made only by “web professionals.”
I absolutely agree with this, in both directions - the tools we have kind of suck if the web WAS meant for professionals, but also that I remember learning HTML from tutorials in 1995, and back then there wasn't much of a difference between a good website or a great website except that a good website used a table based layout and didn't have prev/next navigation.
I think this is great, my biggest stumbling block is deploying what I've created. I have a domain and need a host. The paragraph about deploying only covers hosting by a service you can't use you own domain on (as far as I can tell). It mentions netlify, which I assume would be an option if you have your own domain, however their website talks about shit but tells you nothing.
Is HTML ever actually defined in the beginning of this book? There’s a reference to what the acronym expands to when tags start getting introduced but the chapters before this never come out and say “HTML stands for HyperText Markup Language, and here are three sentences that very briefly explain what that means; we’ll be exploring that in much more detain in the coming chapters.”
I’m getting downvoted for this question but I think that is a pretty important thing to be getting out of the way in a book for someone who might not know what the heck HTML is, and why they might want to learn it!
We sorely need more of this. HTML was the first language I actually understood (although BASIC was my first ever), and left me feeling empowered to carve out my own survival on the internet. While layering CSS and Javascript aren't bad decisions on their face, I do think they combine to create a steep barrier to entry for most newcomers as they're believed to be "Core" to the language of HTML itself.
Kudos to the author(s) for the site. I'll have to add it to my arsenal as a "next step" for folks who want something more custom than WP/Ghost on PikaPods w/ a theme, or who just really want to be totally independent.
I think CSS and JS should be things the user graduates to when they decide they need them, if they ever do.
Show someone basic HTML and most people will eventually look at their page and think, “this is neat, but how to I make this title red and change the background?” This is when to introduce the very basics of CSS.
If someone has a goal the learning process is easier and more exciting, because it’s relevant and allows them to learn something to give them a result they already want. Learning to learn is hard.
I think teaching all 3 at once is better. You can take a really simple vertical slice to demonstrate how they interact to compose the DOM. Then, spend the next 2 weeks inside dev tools explaining how to navigate the DOM and browser state. Establishing mapping between dev tools and the examples is where self sufficiency becomes feasible.
I agree you can pretty much get there with plain HTML academically and in concept work, but this is not a helpful (or exciting) perspective for someone who is likely to be tasked with building non-trivial sites for others. A little bit of color and movement can go a long way in keeping the apprentice's attention.
If we are talking about non-technical people simply making documents for the web, I don’t think they ever really need to know what the DOM, dev tools, or state is. They’ll never really run into that, as the sites will be rather trivial, and that’s ok.
For someone looking to be a web developer, I can see where some would need a faster ramp up to hold their interest, but they should also still know that it can be this simple. I saw a video not long ago where someone asked a bunch of people who just finished a web dev bootcamp to make a basic HTML file and put it on the web, much like what this tutorial does in the first couple steps. Most of them couldn’t do it. If someone can make a page using React, but can’t make a simple HTML page, I think that’s a problem. It leads to a lot of overly complex solutions, because they were never taught how simple it can really be.
Even for technical folks, their area of expertise may fall outside of the web, but they still want a web page to share information. The basics are perfect and often used. Dennis Ritchie’s page was a perfect example of that. A lot of people from this era have similar sites.
I'm not sure we want to onboard non-technical people into such things right off the bat. Keeping things simple - notepad and HTML - gives everyone the ability to carve out a rudimentary niche for themselves, which is the goal. If they're still interested in this field - either just as a hobby, or as a career - then they'll at least have a solid understanding of the foundational topic and know where they want to go from there.
Remember, the goal isn't to make everyone a competent developer, just enabling everyone to participate without going through a corporation for basic web services.
I love making stuff like this accessible for many people. Giving it a quick read and while I do find it more readable I think you can still lose people when you define terms. More fun analogies and simple silly (non technical looking) pictures could really help a concept sink in faster. Great work overall though.
Don't coding LLMs kind of fill this gap? I can't imagine anyone who isn't a pro wanting to spend time learning HTML when they can just describe what they want in plain text and get something good enough.
I don't need to read farther than this, I'm never going to recommend this over freecodecamp. Let alone that a lot of people are usually on mobile during learning time, it just makes it too scary, too easy to mess up, too hard to share what you are doing to get help.
I 100% believe online sandboxes are the way to teach coding to people who aren't already comfortable with technical problem solving.
So basically you want to train a generation of copy/paster who don't understand what they are actually doing and who will never actually deploy anything because it is scary.
it's not about knowing the basics of using a computer, it's about eliminating the possibility of tiny mistakes like 1 typo in a file name causing everything to break, which can put someone off coding forever
> tiny mistakes like 1 typo in a file name causing everything to break, which can put someone off coding forever
One typo in your math or chemistry homework will quite likely give you the wrong final answer, but hopefully that wouldn't "put you off science" forever. Otherwise none of us would be here as I'm sure we have all made hundreds or more.
Are we not expecting students to be resilient and solve problems anymore? One of the Common Core standards that used to be on the classroom wall was "persevere in problem solving." I say it's great for students to make a few easy mistakes like forgetting a semicolon to get in the habit of reading error messages and troubleshooting while they are still straightforward to fix.
The important context here is that this book is not "HTML for programmers," it's "HTML for people who are probably pretty damn scared about the word HTML right now"
In this case, the single most important thing is *early successes*. Kids spend years learning about the number line and what is the difference between + and - before they ever do 2+2=4. Or if they learn 2+2=4 first, it's just some abstract syllables they were taught to parrot, and they probably don't understand.
For a new programmer, who is ALREADY SCARED OF PROGRAMMING, the single most important thing is early successes. If they can make something work on their first attempt, without realtime help from a friend fixing their mistakes, they are SO much more likely to have the needed self-confidence to keep learning.
For a concrete example, every time I teach regular expressions to people I say, `cat` is a regular expression! Let's search for `cat` in `catastrophe` and turn "regex" mode on! Congrats, you have now written and used your first ever regex!! And this goes over SO well. It's SO much better than trying to start out with a symbol, because I give them an initial win that they achieved and that they were able to do. And if they get stuck later, they can always go back to knowing that `cat` is a regular expression and search for `cat` in `catastrophe`. And if it doesn't work, there's a different problem.
In other words, not only is giving people an early success like this good motivation, it's also teaching them the negative control that they'll use for the rest of their programming careers, even if they don't know it.
"Make a file on your computer" is not useful by itself. It's not a negative control. It's not an early success. It can be learned later, once you have the other things.
If making one mistake is enough to put one off forever then they’re really not going to like programming which is just a sequence of writing bugs and fixing bugs. :)
I'm sorry, but I learned on a garbage Windows 98 machine when I was like... seven, and I actually got quite far without someone padding the entire computer and handwringing about f*cking _typos_. My god, what happened to this industry? Yes, learning is hard! Sometimes you make mistakes! That is how you learn! This is why my coworkers submit garbage pull requests full of obvious errors, because they've been coddled to death and never allowed to accidentally typo a directory name. Christ...
this is a great tutorial even for experienced programmers, many of them even don't understand the nature of website behind the coding , but this tutorial leads a wise way to illustrate this concept
> Imagine if Word documents were only ever created by “Word professionals.”
But they are! OP explain how to create websites using basic text editors, and nobody is able to create a Word document using simple text or binary editors, apart from maybe a handful of gurus in Richmond.
If you really want to democratize HTML, an HTML editor is what you need. Otherwise, your teaching site will not attract much more people than any other teaching site.
I mean, HTML is a plain text format, it was literally made for people to write, and people wrote websites with it, by hand, for years. Literal children with almost no technical skills taught themselves to do it.
There was a time when it was easy. Even Javascript was easy. All of this stuff was made for people, but we've abstracted it away so only machines ever touch it and what used to be easy is now a dark art.
You think something that starts with "less than exclamation point" is made for people? "less than exclamation point minus minus" ah yes it just rolls off the tongue. HTML was clearly designed to add "semantic web" to the existing text data of the internet, no matter the cost to human readability. If it's "made for people" it's only in the roundabout fashion that eventually it gets hidden away by the interface to change the font color, etc.
Human beings are capable of dealing with abstract forms of expression other than natural language. Musicians deal with music notation. Stenographers write in shorthand. Mathematical notation. No programming language with its brackets and parentheses "rolls off the tongue" either but human beings nevertheless write code. HTML is just one such abstraction, concerned with adding markup and hyperlinks to a digital simulation of a paper document.
HTML is "made for people" because it's a text-based markup format intended to be edited by people when designing a web page, simple as. If it were made for machines it would be a binary bytecode format. It isn't because it's meant for human beings to read and write. And human beings are capable of reading it and writing it.
I don't know what to tell you. This is simple, straightforward fact, but you seem weirdly offended by the mere premise.
<!-- strong disagree -->
All I'm saying is that if you were to make a semantic markup of English today, would you really want to use keyboard-convenient glyphs just because it's hardware-convenient?
What would be the best way to add markup to English? It seems like an unexplored question. And if we were to explore it, we would find many alternatives, ranking much higher on the "for people" scale than HTML.
>All I'm saying is that if you were to make a semantic markup of English today, would you really want to use keyboard-convenient glyphs just because it's hardware-convenient?
HTML is not a semantic markup of English, it's a semantic markup of digital text documents. Yes, you would want to use keyboard-convenient glyphs to express this markup because the keyboard is the primary means by which a human inputs text into a computer, which itself is the primary means by which HTML documents are viewed. Also because HTML operates primarily within the context of typography, in other words, because the data that HTML marks up also consists of keyboard convenient glyphs. It only makes sense to use text glyphs to describe the transformation of text glyphs within the context of a textual medium of communication.
Even Markdown is essentially the same thing. There's little real difference between surrounding a word in asterisks versus <strong> or <b> tags to denote bold text, other than aesthetics.
>And if we were to explore it, we would find many alternatives, ranking much higher on the "for people" scale than HTML.
Like what? Interpretive dance? Arcane gestures? Singing the markup into being?
People have been using written language for thousands of years, representing written language with type for centuries, and using keyboards as an interface for generating text since long before computers were invented. It all seems to work just fine for many people. I'm curious what you think would be better.
IF it is not a challenge to invent new glyphs and manufacture new keys, then perhaps we can rethink the markup as well. It is a rather open-ended question and I appreciate your asking. I have some thoughts, mainly inspired by the original inspiration to things like cascading styles, which was an inheritance of concepts and a jumble loosely associated with how magazines are structured and arranged / composed on a series of pages that flip together and have images and text. It seems that there are, by now, largely, conventions that are stuck to in the online realm, so maybe there is an amazing shorthand we could develop to get the same point across, now. What we are discussing is becoming closer and closer a reality because the amount of code pressing TAB will output (autocomplete) is increasing, and evening time and sunset time on actual "coding" might happen in our lifetimes. Perhaps not for microprocessors on solo devices requiring direct register access and pointer circuiting, but the trend is that less or fewer keystrokes can produce just as rich content. The markup language makes it "hypertext," right?
꜐expandꜘourꜛglyph꜅workꜝ Wikipedia has something closer to what I envision as what the dudes who done did CSS done thought. Someothing closer to arranging your magazine on the page for others to surf, and also link it with other pages. The soothing letters of English and their stradivarian font-signatures so carefully plucked and delicately labored on in the ethers of Apple headquarters, are bruised and battered by slashing and elbowing />
>Alternatively, you can launch your browser first, click File > Open File…, then navigate to your index.html file.
Uh, I don't think browsers have had the File toolbar for a long time, I just checked to make sure I'm not crazy and Firefox and Chrome on my system certainly don't.
> It’s for anybody, the way documents are for anybody. HTML is just another type of document.
You don't ask anybody to learn XML tags to edit a Word document in a plain text editor even though it's technically possible. Similarly, HTML is not "just another type", but one of the many poorly designed (especially so if CSS is added) document formats that no non-tech "anybody" should be exposed to
You need to learn WYSIWYG "codes" and "language" too. It's just that you probably already did so. "Select, then click on the B button to make it bold", or "click B, type, then click B again" is probably not straightforward at first.
I don't know why people shouldn't be exposed to markup.
I also don't see how HTML is a poor format. It has its issues but fundamentally? Seems fine.
It's cool someone tries to make it reachable to more people.
First, it's not a "just", but a huge benefit for the audience of "everyone"
Second, it's much more straightforward vs any tags (and remembering having to close them without any help in your plain text editor)
And is also much more discoverable in the intuitive interface with the full list of available styles right there with styled buttons so you don't need to think whether <u> is underline, underscore, or something else entirely.
That's the whole point of why this can't ever be for "everyone" - it requires too much knowledge that's not generally useful.
But yeah, with such a trivialization of the effort required, you'll never understand why people shouldn't be exposed to markup.
> It's cool someone tries to make it reachable to more people.
I'd really like for there to be a WYSIWYG editor that works on HTML, something the level of complexity of like WordPad (which can make RTF files). But supporting the full range of HTML tags like <details>, <table> etc.
Yes, that most people already know WYSIWYG has value, of course. And it takes effort to learn. But people can see for themselves if it's for them. Nobody is forcing anyone to do anything. Most likely, people even starting to read this are probably ones who are already a bit curious or interested in this.
This is for people would could be thinking "HTML is code, it's impossible for me" when really they can understand and like. This things tells them "look, it might not be as complicated as you might be thinking. Try and see for yourself".
I don't see the drawback of doing this actually. I don't see the harm. However, I see value in making people realize that computers are not magic and that they can leverage them in other ways, and putting such tools within their reach.
So yeah, maybe not anybody, but probably many more people than one could think (professional or not).
It's also easy to underestimate people (ourselves included) and to think code like HTML is too complicated to understand for most people. It's actually not. Most people would understand the basics quite easily and making them realize this is quite nice.
What do you have so special that you could learn HTML? Nothing, actually. And it is quite important to be aware of this.
Yeah the implication that I guess I didn't make well enough is that it's for anybody who wants to learn it. It’s attainable without needing highly specialized or intensive training.
With OpenAI and other LLMs, web development is accelerating. For example, I put together a AI call center demo ( https://www.youtube.com/watch?v=Vv7mI_qRrhE ) by using Open AI o1-preview. There I could take a lot of different files on typescript and backend server stuff written in python. I would add logs into the mix to make one massive prompt, and then I would let the AI work on reasoning in the cases where I needed to accelerate the writing of additional code.
{kind=link}
{kind=link}
I did worry a bit about https://htmlforpeople.com/zero-to-internet-your-first-websit... - "Step 1. Create a folder on your computer" - because apparently a large number of people these days don't understand files and folders at all! https://www.theverge.com/22684730/students-file-folder-direc...
Not sure how best to approach that though. Having a whole chapter of the book explaining files and folders feels pretty redundant. Maybe there's something good you could link to?