- Visual computing is pretty heavily used, unreal engine, blender, houdini, etc. All have a very similar node based visual programming system. It seems to work pretty well (better than text) for most of what they use it for. I think because of the ease of jumping in the middle and making small understandable changes.
- Many programming languages today have a format that is like <tree of files, each containing> <set of items, each containing> <list of expressions>. It would be nice if that <set of items> step was treated as an unordered set instead of an ordered one, with editors having a better understanding of how to bring up relevant elements of the set onto your screen at the same time. Split pane editors, "peeking" in editors at code definitions, etc. hint at how this should work, but I don't feel like they do it as well as possible.
I feel like a lot of users on HN are producers rather than users of software, and haven't used node-based systems like in blender or nuke. They are extremely productive, and end up being very similar to functional programming while being super easy to pick up. It's a great "inbetween" representation for non-programmers that really need to do domain-specific programming.
Experience with tools like Blender or Nuke and particularly with visual programming in games engines is actually where a lot of the better informed dislike of visual programming comes from.
The biggest problem with these tools is scalability and maintainability. You will hear many stories in the games and VFX industries of nightmare literal spaghetti code created with visual programming tools that is impossible to debug, refactor or optimize.
Visual programming seems easy for very small examples but it doesn't scale. It has no effective means of versioning, diffing or merging and usually lacks good mechanisms for abstraction, reuse and hierarchical structure. It doesn't have tooling for refactoring and typically lacks tooling for performance profiling.
Some of these problems seem to be more fundamental and others like they could potentially be addressed with better tooling but that tooling never seems to emerge.
I've got a lot of experience with shader programming and have never found node based shader editors to be better than text over the long term, although there are some nice visual debugging features which are rarely implemented in text based IDEs (though I have seen it done). I've also found visual scripting to all too frequently get out of hand and have to be replaced with code due to being unmaintainable, undebuggable or unoptimizable.
I think there is possibly fertile terrain to explore in trying to get some of the benefits of visual programming approaches while avoiding all these downsides but many of us have been burned enough to be very skeptical of the majority of visual programming systems that don't even try to fix the worst problems.
> code due to being unmaintainable, undebuggable or unoptimizable.
I would argue that the shader editor in UE3 had none of these properties. It showed you cycle count and each step of the graph visually for debugging.
Also, I don't mean to be blunt but you aren't the target for those tools. Where they shine is when you have a level artist that needs to make a small tweak to how a shader looks. With those systems you don't have to loop in a dev to make it happen. You still need a solid tech artist to make sure things don't get out of hand and they're not a tool for every problem but in the domains where it aligns you see 10x gains on a regular basis.
I think rather than the shader editor (which uses a similar-but-different node based interface) they are referring to the Blueprint programming system in UE4 which effectively wraps C++.
It's extremely powerful, but it comes at a cost because it's nigh impossible to create diffs between different versions of Blueprints AFAIK.
That is neat, I'd never noticed that. Although in the context i've heard it discussed, it was more in the vein of "can't generate textual diffs/patch with them, as you can with C++".
I could be wrong but I believe the Blueprint assets are stored in a binary representation. So that rules out vanilla tools like patch/diff for the most part.
See the sibling poster, they did actually add a visual diff/merge tool in a much earlier version and I missed that.
Ascii is a binary representation. It's just that we've built up a lot of tooling around being to visualize/manipulate that representation. There's no reason that similar tooling couldn't arise for other binary representations
I'm not really sure what your point is. The point is ASCII/UTF-8 are a binary representation that is easily parsed by humans, which is why we use it for writing code. Sure, if you want, dump both files with xxd and do a diff on that instead.
There's been ways to diff binary files forever. Doesn't mean it is a great idea to store source code in that manner though. With UE4 you're not really supposed to be able to edit the Blueprint "code" outside the UE4 Editor.
> It has no effective means of versioning, diffing or merging
Color solve this one problem just like they solve the text equivalent better than annotations. This is not fundamental.
> lacks good mechanisms for abstraction, reuse and hierarchical structure
VLSI circuit designers have some abstraction mechanisms that are not that bad. This one is fundamental, but it's not as bad as most people say.
> It doesn't have tooling for refactoring and typically lacks tooling for performance profiling.
I can't imagine how those could be fundamental problems either.
In principle the largest problems of visual programming are our lack of capacity of understand complex images, compared to text, and the added information that most visual languages add (making the complexity worse) (that do not apply to things like GUI designing). I don't see any other showstopper, but those two are really bad.
> our lack of capacity of understand complex images, compared to text
I'm not sure I agree with this. Not as a fundamental law, at least. I find complex text pretty difficult to understand. Sure, I can read the words or even expressions, but to really understand how everything is connected and how the data and control flows through what's written, I find that incredibly difficult. A large part of programming is keeping that contextual information in my head so that I don't have to re-evaluate it all again.
Which is the reason why I love pen & paper and boxes & lines when I try to map out some code, a data structure, algorithm or idea. Obviously everyone is different, but for me, when things get too complex, I reach for images and diagrams to help me understand and form a clear mental model of what's going on or what I want.
Having said that, I've yet to find a visual programming language that does this. When I used Max/MSP a number of years back, I found it helped me think in "code" as I could map out ideas visually, reducing the need for pen and paper, but it had a ton of shortcomings. It gave me a glimpse of what it could be though, and I think the problems could be solved to a point where I can skip pen and paper altogether. We're not there yet, but if you think about how much time and effort went into making textual languages, its no wonder visual languages are so far behind. Also, its clear that not every task is well suited to visual languages, so the best environment would need to be a mix of both.
Good point about complex images. I do not think this issue will be solved anytime soon. An individual's mental image of a complex idea like inheritance or a data structure is subjective. Tying a specific visual GUI to a complex model (that many users would agree upon) is a very difficult design problem. Text allows the user to interpret the model using their own imagery.
I don't think I agree. We know that there are diagrams that come from category theory that behave very well, this is what statebox uses. It enforces certain constraints, so we pivot everything around this and see if we can recover some form of programming from it.
certain cases are still much better done in text and statebox itself is written in text, so nobody is claiming programming itself should be 100% pictures, but then again, I think it can be done and I think there is merit to it.
after all, text is also some sort of picture; on the screen but also in your head
Very much agree on these points. In my experience the pragmatic path for larger projects has been a hybrid of keeping visual programming graphs self-contained -- roughly within the "asset" boundary -- and then using a hierarchical format with textual representation to assemble those assets and drive their interface parameters. This is roughly how animation studios use USD (openusd.org), for example. Arguably this is just a strategy of combining a couple domain specific languages, with edges where the optimal tradeoffs of each domain flip. It's a very interesting question whether these limitations of visual programming are essential complements of their benefits, or if there is some good way to provide better abstraction, re-use, etc. Certainly Houdini, Nuke, Katana, etc. all provide limited forms of those things (ex: Houdini OTL's; scripts that version-bump nodes and try to auto-upgrade the parameters), and they do see lots of use in industry.
so I started my studies in animation actually, I used a lot of those tools, you can think of statebox as applying category theory to restructure aftereffects or https://en.wikipedia.org/wiki/Shake_(software)
when done right, we claim, you can target many different things ("semantics")
what we claim is something like, the compositional aspect of many such node based systems can be described as a certain type of mathematical object (monoidal category) ~ we can build an editor for that and then map that "dsl" to particular targets (image processing, state machines, etc)
> The biggest problem with these tools is scalability and maintainability.
This has been my biggest complaint with both Unreal and NI Reactor... you can build some brilliant things, but not without creating a mess of connections that becomes very difficult to reason about, let alone work on. A lot of production "visual programming" diagrams are spaghetti code, without comments or a changelog you can study.
While written code tends to the same way (just try diagramming the class tree in most software), at least we have tools for dealing with and reasoning about it in text form.
Indeed, spaghetti is a big deal. However, in systems like [Node-Red, Antimony, Apache NiFi] you can make function nodes that abstract out the actual data vs the function. And then, your function primitive can be called and instantiated for the particular purposes.
I know in Antimony CAD, you can even instantiate a function, edit the function's flow or individual python subroutines, and the delta is saved for that instance.
I know the hardest graphical programming I've had was with the Lego Mindstorms ev3. There were multiple "simplifications" that removed functions along with a nigh-unusable gui (the if block was this huge encapsulating thing, and other branch codes also had onerous things on screen).
the tools for reasoning about text can be limited if the text is in a language unsuitable for reasoning
this is why we work in a typed, purely functional setting.
spaghetti is difficult to deal with, for starters, you need "compositionality", so that you get no undefined or emergent behaviour.
then second you need some form of "graphical macros", or a "meta-language" for diagrams, code that generates diagrams or "higher order functions" for diagrams.
> ...and usually lacks good mechanisms for abstraction, reuse and hierarchical structure. It doesn't have tooling for refactoring...
Arguably, the whole point of having a diagrammatic representation with good formal properties is to provide new mechanisms for accomplishing these things. Of course these mechanisms, features etc. won't quite resemble the ones that are in use with text-only languages.
Read it as refactoring, or equivalent; the described functions all fall under organizational and editing tools, both of which are necessary in visual and text environments. Lacking decent mechanisms would make a full buy-in difficult for any larger project, regardless of the precise manner in which its done. Without it, you have a write-only language
You shouldn't generalize like this. Even in massive projects visual programming can be enormously helpful. Nobody seriously tries to script game levels in an IDE. Nobody tries to match sprite parameters, which eventually become code, to image files in an IDE. Nobody tries to design GUIs in IDEs.
The right tool for the right job. For 50% of a game's code visual programming is absolutely the right tool. For some other parts it probably isn't.
You seem to be using a different definition of visual programming than the normal one. The article and my comment are talking about visual programming as a graphical representation of code / logic rather than a textual one. Examples would be things like Unreal's Blueprint visual scripting, node based shader editors (Unreal has one of those too) or the Petri nets described in the article. Visual / GUI tools like sprite editors, level editors or GUI builders are not what is usually meant by visual programming.
Unity is a very popular game engine that doesn't have an official visual programming solution (they're previewing one in the very latest version). Unity has a powerful level editor that is used to lay out the levels in a GUI tool but no visual scripting / programming tools. The majority of Unity games that currently exist therefore do all level scripting in C# code. Many other games engines have no visual scripting solution and all level scripting is done in either a scripting language like Lua or in some cases in C++ code. Unity has sprite editors, visual GUI builder tools etc. but those are not what is generally meant by "visual programming". The closest Unity has had until recently was its graphical animation state machine editor.
awesome comments, really cool to read all of this.
anyway, I would argue both are valid examples is graphical progamming, but they happen at different levels.
the "node based" tools usually define some sort of function or system, ie. a "type"; for this you need category theory to describe how the diagrams look and this is not what any editor I know does, but it means a whole of difference.
And the map editors are for defining "terms of a type", given a definition of a "map datatype" there is a graphical way to edit it.
when we talk about graphical programming we are initially focussing on the first, well defined graphical protocol definitions. you can think of it as type checked event sourcing, where the "behaviour" or "type" is described by a (sort of) graph representing a (sort of) state machine)
but we have relatively clear idea's to extend this to the second case as well.
The difference with other (older) approaches is that in the last 20 years a lot of mathematics appeared dealing with formal (categorical) diagrams or proof nets, etc. that we leverage. I claim we (the world) now finally really understand how to build visual languages that do no suck.
Things like a GUI designer or level editor map a 2D or 3D domain to a 2D or 3D-projected-to-2D space. A 3D animation editor maps a 4D domain to a 2D projection of a 3D representation plus a timeline representing the 4th time dimension. These mappings are natural, intuitive and work well generally.
Visual programming tools attempt to map logic to a (usually) 2D domain where there is no natural or intuitive general mapping. The representation has both too many degrees of freedom (arbitrary positions of nodes in 2D space that are not meaningful in the problem domain) and too few (connections between nodes end up crossing in 2D adding visual confusion due to constraints of the representation that don't exist in the problem domain).
I've been exploring colored Petri nets for our product and they do seem to have promise for certain use cases though so I do think it's an interesting area to explore.
> Visual programming tools attempt to map logic to a (usually) 2D domain where there is no natural or intuitive general mapping. The representation has both too many degrees of freedom (arbitrary positions of nodes in 2D space that are not meaningful in the problem domain) and too few (connections between nodes end up crossing in 2D adding visual confusion due to constraints of the representation that don't exist in the problem domain).
In general this is true, but the diagrams we use at Statebox are different in the sense that there is a completeness theorem between the diagrammatic language and an underlying mathematical structure (a category). In this case the mapping is sound by definition.
Also, it is worth stressing that our diagrammatic calculus is topologically invariant, meaning that the position of diagrams in space is meaningless, everything that matters is connectivity. This is also the approach originally used by Coecke and Abramsky in the field of Categorical Quantum Mechanics, which is getting huge success to define quantum protocols :)
Why does category theory magically transform node diagrams into something usable from something not? Unreal blueprints/Reactor schematics/whatever are quite fine in their current form, even if their usage falls apart in advanced constructions. Is statebox going to magically make huge node-and-graph-designed programs reasonable?
Your writeup didn't convince me that "category theory" adds any significant value, and neither does it help inform as to what category theory actually is. How does statebox improve upon existing node-based programming implementations?
CS formality and big words misses the point of visual programming entirely, in that it is to simplify the process of software creation to make it more approachable to non-programmers. Unless your UX is absolutely top-notch you are going to lose these novice users as they struggle to deal with the constraints without a good reason or UX to do so.
Also- The memetastic design of statebox's main page is a pretty big turnoff :(
> Why does category theory magically transform node diagrams into something usable from something not? Unreal blueprints/Reactor schematics/whatever are quite fine in their current form, even if their usage falls apart in advanced constructions. Is statebox going to magically make huge node-and-graph-designed programs reasonable?
Your writeup didn't convince me that "category theory" adds any significant value, and neither does it help inform as to what category theory actually is. How does statebox improve upon existing node-based programming implementations?
nothing magical, just good engineering and UX design and solid theoretical underpinnings.
cat. th. does add value: there are many ways to build diagrams and build syntaxes for diagrams, but they are not all equivalently powerful or general. but it turns out that there are diagrams that _are_ suitable, and this is what we use.
It will improve upon existing diagram tools in that it gives a formal theory of how they work, so you can really build huuge diagrams and still be sure everything works.
I didn't write the blog post, but I could try to write one about the value of category theory, because it is often misunderstood. It is however very abstract and takes the mind a while to see the value off, which is not so easy to convey.
> CS formality and big words misses the point of visual programming entirely, in that it is to simplify the process of software creation to make it more approachable to non-programmers. Unless your UX is absolutely top-notch you are going to lose these novice users as they struggle to deal with the constraints without a good reason to UX to do so.
oh, yeah this is something often misunderstood, we are not trying to target novice developers (yet). we need to develop a lot of stuff and CS formality is right now still the simplest way to understand the system. I mean, we are not trying to be arrogant or puffy or something, but for instance the way we realise our compilation is with "functorial semantics". we have a functor between categories that does the trick. We could call it something else, but it doesn't help (at this stage).
anyway, if we do our job well then all the category theory would be under the hood and you just get a nice UX for coding with diagrams.
> Also- The memetastic design of statebox's main page is a pretty big turnoff :(
opinions differ :) I thought it was quite funny 2 years ago and many people thought so as well and then it got turned into this homepage.
at the moment we don't really have time to spend time on the site, but it will def. be changed in the future
Smalltalk would be an exception. The graphical elements are provided for you to make your own inside the image on the fly, or you can modify the IDE as needed.
> Experience with tools like Blender or Nuke and particularly with visual programming in games engines is actually where a lot of the better informed dislike of visual programming comes from.
Maybe the better informed dislike, but the bulk of the dislike in general is usually of the form "this kind of thing never works, nobody uses it", when in fact it is being used, in multiple disciplines.
> scalability and maintainability
> easy for very small examples but it doesn't scale.
this is very true, that is why we do it differently; we clearly define the semantics of our diagrams and take guidance from category theory in this. this is different from other graphical languages; we try to assume the minimum but then guarantee you that some stuff is always preserved.
think of it like deterministic, pure functional programming, but with diagrams.
> usually lacks good mechanisms for abstraction, reuse and hierarchical structure.
> f versioning, diffing or merging
very important points, we try to address this by having everything based on immutable, persistent data structures with built in content addressing; similar to git for instance.
diffing and merging is very complicated and still research but there are many hints that this can be done
I think those examples are a bit misleading in that nobody actually prints 100,000 lines of code and looks at them all at once. So those examples are showing probably the whole "program" at once, which is impressive and looks daunting, same as a big textual code base.
Rather, in order to understand a certain aspect of the system, I imagine picking just one of the nodes and then asking the IDE to show me, say, the immediate inputs. Some of these may be semi-hidden (code folding!), others may show more detail, etc.
BTW, I've been thinking it would be great if these systems had a textual representation in the vein of Graphviz' dot language. So one could have the best of both worlds. For diffing, a simple textual diff could do, but one could come up fancier semantic diffs in the same vein semantic diffs for code or XML exist.
When I used Max/MSP a few years ago, a lot of people's code snippets looked like this, however, an important thing to remember is that the target audience for most visual programming tools are not trained software engineers -- ie they don't know about encapsulation and abstraction and all of the other concepts we take for granted.
I found Max/MSP code could look extremely tidy, as I would group my functionality together in a similar way as I would in a textual language (short single-purpose functions and such). You can write horrible spaghetti code messes in textual languages too, its just we've used enough textual languages to have learned how to abstract our code and how to organise it for maintainability. Its not an inherent feature.
I did some programming in Max/MSP way back when, which was fun, and you have a point about the "functional" aspect. It was sort of the opposite of say, C, in that it was actually hard to create side effects even when you needed them.
But overall I agree with other people that I wouldn't want to maintain anything particularly large in that format. The Max "patches" were on the order of big scripts at most.
:) I also did a lot of Max/MSP and many similar systems, [nord modular](http://nmedit.sourceforge.net/) , and also wrote such tools back then, for audio and 3d and video, which is what led to statebox ultimately.
I would say the spaghetti aspect of max is the main complaint with visual programming.
To modularise it (small diagrams), you need to contain the behaviour of the boxes (ie. typed purely functional code).
And to generalise it (audio, video, microservices, ...) you need to separate the syntax from the semantics.
(took me about 15yrs to figure out a way to do this properly :-)
I don't know if any of them are extremely easy to pick up. Any re-use between applications are the domain-specific parts (knowing about color space, UVs, shaders, and cameras) not the UI. Node based interfaces are pretty limiting. A lot of the power of these systems are things like having a Python runtime or text representations of scene files that you can find/replace. The other pro/power features are shortcut keys and templates, just like other apps like Lightroom or Avid.
Node based systems is a great pattern for certain things, but large scenes get unwieldy quick. Even if the project files are text, diffing with version control is useless. Profiling is often difficult--a pet peeve of mine when apps load all the whole scene file and often the geometry when you just want to change a parameter.
You can see node based systems "grow up" by adding variables or attribute references, which means your data isn't just flowing down the graph, but you have to track references in this new dimension. You then often see encapsulation (hda/otl, Gizmos), which can really help with re-use but create more limitations.
The problems with visual programming have never changed: at one point you need functions, macros, identifiers, user-defined types, error paths, diffs...
(EDIT: it's an idea that doesn't work at all for _general purpose_ programming, but for some reason it sounds like a good idea from a distance).
Visual programming is also used a lot in plc programming (Siemens S7/TIA, Mitsubishi MELSEC, etc..).
Programming visually is usually called FBD or LAD. We use often FBD for simple logic. It's easy to read, even for inexperienced maintenance guys. LAD is a no go for me, but it seems a lot of guys still like it.
http://szirty.uw.hu/lang/Siemens_TIA_FBD.png
As long there is a simple and clear code structure, it is a good thing.
Today, special since Siemens made SCL (kind/like of Pascal for PLCs) usable and in there new IDE (old was Step7, new is TIA), we use it also a lot.
Today it's even possible to mix FBD/LAD and SCL. So you can make al simple logic in FBD or LAD, and then calculate things in between in a SCL network.
As user of both worlds in my job, I can say both worlds have a right to exist. It's just like is C better than C++ or is Python even the most best ... is a car better than a bike .. is a house better than a tent ..
>As long there is a simple and clear code structure, it is a good thing
I've seen sprawling, massive ladder logic jumbles that made no sense and were completely undocumented before. Once visual-style plc things reach beyond a certain level of complexity, if they are undocumented they can be a nightmare to use.
I don't know if this says more about the medium itself or that a lot of PLC guys just don't know or were never taught proper standards to follow in writing their code. Either way I've seen a lot of really bad PLC code.
Sure, I should have maybe made my point clearer and say PLC programmers in my experience are often guys with no programming background who have an Associates in automation technology or something similar from a local community college.
They have often not been taught basic things like don't name a variables or identifiers that have no significance like 'b123' and are in a workplace where as long as the lines are running properly nobody cares. There are leagues of difference between what I would consider a pretty messy codebase at say, some B2B enterprise software company, and a large codebase maintained by people who actively don't know how to program for lack of a better description.
As you can imagine, I've seen also a lot more or less funny ladder logic.
And yes is true, most plc programmer don't have a "just software" background and yes a lot of plc software is not super pretty but with the old IDEs it was also not so easy.
there is some pretty solid theory on how to translate between the kind of diagrams statebox uses and digital circuits. In fact we are doing some experiments with direct diagram to wafer (chip) translation using LibreSilicon http://libresilicon.com/
this is certainly not a done thing, but something we'd love to work more on in the future
It was possible since Simens Step 5 (since late 70s) to change your view between FBD/LAD and AWL. But AWL is just like Assembler, so .. yes. In old machines (we still have about 20 machines with Siemens S5) sometimes it's a must to use AWL.
Translate an IF statement you need to add jumps, so it's not really the same code.
Also for ex. the very simple Siemens LOGO controller has a simple software to program it. But if you use FBD, it's just possible to use a tag once. So if you need a tag multiple times, so you have to draw lines from the single tag. Even for super simple stuff it get's messy super quick.
Many programming languages today have a format that is like <tree of files, each containing> <set of items, each containing> <list of expressions>. It would be nice if that <set of items> step was treated as an unordered set instead of an ordered one, with editors having a better understanding of how to bring up relevant elements of the set onto your screen at the same time. Split pane editors, "peeking" in editors at code definitions, etc. hint at how this should work, but I don't feel like they do it as well as possible.
Back in the day, in VisualWorks, with the RefactoringBrowser, you could bring up a browser for a search, say, everyone who implemented
methodNamedFoo:
Then you could rapidly narrow that down (effectively and-ing it) to those methods which also sent
thisOtherMethod:
These were lightning quick operations, just right-click and done! But what's more, you could even compose little queries (think like you would in a SQL query client, but using snippets of Smalltalk code) that would be applied to/and-ed with the contents of each browser window. Done right, this resulted in a few accurate, complete, and highly focused sets of code applied to the exact problem you were working on.
What's more, you could write scripts to pop up such query browsers automatically. They would also be saved in the "image" and just pop up to the same state when you restarted the environment. On top of that, you could write syntactically accurate code transformations against all of the above, even writing ad-hoc code against the meta level or even runtime state from the middle of a runtime debug session.
A small amount of "visual augmentation" might benefit most programming languages
Agreed. Where various visual programming have fallen down over the past 3 decades:
1) Scaling complexity -- If diagrams get too busy, and there's no good way of managing complexity. This especially applies to multiple programmers changing the same diagram.
2) Scaling size/optimization -- Many visual programming systems in past decades could bog down and become marginally responsive or unusual when managing large systems.
If you can handle those two, you will have a huge leg up towards a viable visual programming augmentation.
I think the take away from existing visual languages is that they can be quite nice but the less they mimic imperative blocks with drag and drop the better. Functional programming is a better fit.
They work well for stream processing.
They can often be more elegant in how they define and consume inputs. Many more parameters can be supported in a visually pleasing way, which cleans up parameter over loading and makes it easier to compose function block together without making Tuple types.
This could very well exist but I think a visual Lisp would be interesting.
yep, the diagrams are like typed purely functional programs
also stream processing is possible, we can (at least in theory) use the same diagram to compose state machines or stream processing functions or DB queries or ...
Ordered <set of items> have the advantage of working well with the brain's ability to map its surroundings. "function foo is defined 5 arrow downs above function bar". When the <set of items> jump around our eyes in arbitrary order, we tend to experience disorientation.
OTOH I always wonder if it would not be beneficial if our brain and the code would not rely on spacial distances in code files, but on _call_ distances.
Should our spacial map of the code not be the call graph instead of the structure in files and disk?
I recently learned Smalltalk (Pharo), and since it's image based it treats classes/functions as more of a collection than trees of files. Of course, there's still structure, but the way you can navigate from function to function is great.
Smalltalk of course has its own problems. It suffers from one of the major problems of many less popular languages, namely the lack of libraries. But I agree that I wish more (or all) languages were as good at debugging, peeking at definitions, jumping to different things, searching code, etc. Of course editors can make up some of the problems, but it's not quite the same.
Depending on the use, I think it can be fantastic.
Jetbrains makes an editor called MPS that is used to make DSLs and you can include things like tables and diagrams into the code. In places where you have very specific requirements and structure, it can help experts in the domain produce the logic for it. That's the same with level editing, level editors need good creativity and views of spaces not experts in C++, so a DSL and graphical editing is great, because it lets them focus on something else.
That said, when it comes to the code behind things, text gives you an immense amount of expressibility that can't be replicated very well with graphical things. It's the same reason why a lot of developers prefer the command line to graphical configuration; you get far more expression for your expertise in a text environment. You get every combination of letters/symbols on the keyboard entered through a large physical interface; using the mouse to click on things feels slow by comparison.
What you say is true. Text is way more expressive, but sometimes it is difficult to spot the overall code structure just by using text. What Statebox does is this: It implements Petri nets as categories and maps them functorially to a "normal" functional programming semantics. What this means is that:
- You draw the structure of your code in a behavior-oriented way using petri nets. This step is completely visual.
- You use a ton of formal tools to verify that this net has nice properties.
- You map places and transitions of the net to datatypes and functions, respectively.
You see that in this approach nets serve the purpose of giving an high-level understanding of how the code behaves. You still have the freedom that you get by using text in filling the net with meaning, but you gain also this high-level overview that saves a ton of work!
It is certainly true that keyboard input can be much quicker when what you're trying to convey to the machine is logical rather than spatial/kinetic information. But it is entirely possible to use keyboard input to manipulate a graph instead of an array of characters.
Regarding visual augmentation, the Visual Studio XAML designer is another good example. You can edit the XAML markup and see the generated UI in another pane.
> It would be nice if that <set of items> step was treated as an unordered set instead of an ordered one, with editors having a better understanding of how to bring up relevant elements of the set onto your screen at the same time.
IDEs sorta move in that direction, though not too fast. You can list methods in a class, jump to the definition of a method, etc.
Not many seem to realize that Java's strict OOP structure is (or was) a mover of IDE functionality: you can statically describe the structure of the entire program at a high level, and code is only contained in methods, so you have methods as organizational units, to which you navigate and otherwise reason. So now we have IDE functionality that can move methods and variables around like they're toy blocks.
I do a bit of Clojure and it feels like manipulating an AST rather than text, especially with structural editing (because code is data). It applies to any Lisp I suppose
Visual programming of data-flow does not add much to programming, I think that's the lesson of history.
That said, I think that visual programming which is not aimed to data-flow can be very interesting. For example Lisp is pretty visual (or topological) in a sense.
I think saying that most programmers don't like FP is a bit more extreme than the actual case here, which is that I think most programmers aren't familiar with FP (although this seems to be growing rapidly due to introduction in Java and other places).
That said, I think many of them seem to find it harder, especially in the beginning. But I think we have to conquer familiarity first.
This idea comes back around every few years. It was most popular in the 80's when it was called CASE, Computer Aided Software Engineering. Since it's been around for a while, we have to ask why it hasn't taken off in a more mainstream way.
I think the best answer is that text, being more dense, is actually the simpler way to represent a complex program. Big applications written in diagrams tend to wind up being harder to read than the equivalent in text. Visual diagrams are also difficult to search, scan, or replace programmatically.
I'm with you. Any attempt at visual programming I've seen has been:
1. Limited in what you can do.
2. If you need to do anything out of the norm it's either impossible or very difficult to find which menu entry you have to set in which way.
3. Doesn't have a proper diff.
4. Needs a slow compile process to actual code to work, making TDD strategies impossible.
5. Attracts the wrong kind of developers (those who don't look into the generated code and make all kinds of mistakes, those that don't understand anything about how computers work, etc.).
6. Hard to debug, because there's little to no debugging support.
7. Impossible to use with the wealth of great tools available for text manipulation.
8. Impossible to search properly, because it's not just simple text.
9. Very prone to vendor lock-in.
10. Doesn't interact well with versioning systems.
I don't remember when I saw this presentation. But it hit the nail on the head. If you go into a Korean McDonald's you have a visual menu. It enables even a foreigner who doesn't speak a bit of Korean to order a bacon cheeseburger. However if you want anything special (like no tomatoes), all of a sudden you need the language interface.
Language and text has evolved because it's necessary to describe the kind of complexity we have in the real world. That's why text is amenable as a representation of programs. They eventually represent a similar level of complexity as the real world. Of course it's easier to teach somebody to point at the McDonald's menu, but they won't get anything complex done, and they need somebody to work the abstraction for them (i.e. a real programmer).
I mean, GraphViz can have a diff. You could even go as far as taking the graph of the program, generating a GraphViz graph out of it and then taking the diff and simply colouring the nodes that made it into the diff.
That's true, but I would say GraphViz is a textual interface for programming graphs. Not a GUI for modeling graphs.
I'm very much for using something like GraphViz for visualizations (for exmaple integrated in AsciiDoc) to have a very good diffable plain text documentation that's nice to look at.
Well, my question is essentially this: what difference is there between visual programming and it's representation as a GraphViz graph?
These are two ways of representing the same concept: you could save the visual representation as a text document.
So what makes Visual Programming not have a textual representation? What makes them inherently incompatible with each other?
Because as of now, what I am seeing are the comments from people who used primarily proprietary tools, and those proprietary tools don't allow you to edit textual representations of the graphs directly because it makes the vendor lock-in so much easier.
>So what makes Visual Programming not have a textual representation? What makes them inherently incompatible with each other?
Nothing really, but you would need a Visual programming environment that maps one to one to your language. So that you could switch between coding in code and looking at or modifying the visual representation when it's helpful.
This would probably limit what you can do in the GUI, just as GraphViz limits control of the graph in favor of automatic layouting.
The vendor lock-in is one of the main issues I mentioned above.
If you have a good idea how to visually represent and modify C# or some other language I wouldn't mind that as an additional tool. I would think it's even very helpful for getting an overview. However the code should still be the master. And open-source is probably the only way to have such a tool that's actually good.
And if you can map one language to the GUI you could probably port this to many languages.
I was mostly concerned with what we have right now (LabView, Simulink and others).
You're absolutely right. Visual programs are much harder to generalize because they've been pre-abstracted for you to a specific use case.
Building controls are a popular field for visual programming because the "wires" seem like they'll be intuitive to non-programming tradespeople.
If we have a little visual program that controls the temperature in a room with a thermostat block and a baseboard heater, that's fun. We can play all kinds of games hooking up limit blocks and schedule blocks and whatever. Intuitive.
Imagine we have seven thousand rooms and some of them have only a baseboard heater but some have an air conditioner, some have a lighting interlock, some have a heat recovery unit. 16 possible configurations of a room and you have rooms in each set.
Now... apply a visual program across all of those sets.
In traditional programming this is simple. A data structure representing room configurations and few conditional statements in your function or loop or whatever. In visual programming you're mostly looking at either making 16 versions of the program and applying each to its associated rooms manually or else passing a bunch of conditional variables around.
Those variables aren't visual anymore. So now you have a whole layer of abstraction that's no longer visual. And really, the parts that fit into the visual model are usually the easy bits. The hard parts still require abstract reasoning about stuff that isn't linked together. Pretty soon you're just using the visual language to draw the inside of your "functions" but your high-level datalinks or scripts are entirely non-intuitive and might as well be in text.
Why can't conditional variables be "visual"? This is not clear to me - data flow and control flow are both visual (albeit their flavors of "parallel" composition and the like are incompatible, so they must never be conflated when shown diagrammatically) and conditional variables can be accounted for in control flow.
Say I have 100 rooms. Each room has 10 characteristics that might vary. Those 10 characteristics are going to be shown or referred to by about 10 different blocks... some are making decisions about the temperature, some are showing it on graphics, some are logging data.
That's 10,000 links. You can't actually draw lines for each of those links to the room information. It's literally impossible to put them on a screen, let alone process them visually. So you have to refer to the variables by name and you still end up with 100 links to draw between variable names and function blocks.
Once you refer to variables by name the relationship between the source and destination is no longer visual. The visual part is just inside any given encapsulated function. So now you're programming with parameter passing but instead of just typing text you're also pulling away to move the mouse and try to line blocks up on a grid all the time.
This should be pretty obvious while coding in text. Imagine every time a you call a function there has to be a line somewhere that represents that function call. It's too much visual information. You can abstract away some of it by saying "oh, we have a block here that goes out and grabs all the room numbers", but now a lot of the logic starts to depend on the contents of those blocks and it's no longer clearly visual.
Visual diagramming is great for roughing out an idea of how something works but enforcing a rigorous correspondence between the diagram and the function of the program turns out to be a lot of trouble for not very much gain.
> Visual diagrams are also difficult to search, scan, or replace programmatically.
This. Whenever I investigate a new authoring tool, the first thing I want to know is whether there is a plain text (preferably json) serialization that I could import and export. A particular tool I otherwise love where this is sorely missing is Zapier.
exactly, every picture represents an "equivalence class" of expressions (or code).
I say equivalence class, because the picture represents many formulas: by topologically distorting the picture you get different code. however, they all behave in the same way. 2+3 = 1+4 = 5
I don't agree that text is the simplest way to represent a program. In fact, from experience in other areas of knowledge, the opposite is true. Math and physics has evolved from use of pure text to the use of diagrams and non-textual symbols. The problem with CS is that we don't have a shared, simple way to represent symbols and images. We feel that text files are simpler because it has become the universal way to represent computer code, and practically all tools we have are designed to work with textual representations.
I don't think that works. I think most of us here would have similar understandings of something like https://tex.stackexchange.com/questions/19941/example-of-sys..., similar to what physicists might have from a Feynman diagram. I assume physicists could illustrate a proof with one, but would actually run through the QED equations, also. Similarly, we could deeply understand a system from an architectural diagram, but we wouldn't use them as source code.
now you can. ok, well soon :) but the theory is in place and works. Also stochastic Petri nets are actually equivalent to Feynman diagrams in a precise sense (https://johncarlosbaez.wordpress.com/2012/12/20/petri-net-pr...), they could be the Feynman diagrams of functional programming :)
Well perhaps it's mathematics that could benefit from an update to its representation. Mathematical symbols have evolved over hundreds of years and aren't really suited to modern systems of representation. When it comes to computers is it really easier to look up the unicode symbol '∩' or its LaTeX representation when you're trying to write 'A ∩ B' -- or would it be better to begin noting mathematics online in a portable way such as: (intersection A B)
One of the reasons for infix notation in math is actually that it provides a 'visual' reminder of useful properties such as associativity, and possibly others e.g. commutativity or distributivity. If all we ever used was a strict LISP-like, function-based notation, such a reminder would be lost and understanding or manipulating non-trivial expressions would be quite a bit harder. The effort in OP is actually a way of generalizing this idea to broader settings, where one is dealing with something more complex than a single domain of number-like values, and a handful of operations on them. This is arguably how one should think of "graphical linear algebra" as well: the 'diagrams' one's dealing with there can be thought of as generalized expressions, so there's nothing overly strange in being able to manipulate those formally according to well-defined rules of some sort.
this is exactly where the statebox project comes from, there is updated syntax for mathematics in the form of diagrams. of course not for all of it, but certainly very applicable to CS stuff
Lots of good ideas come back around every few years. That usually means they are in fact good ideas, but simply that the rest of the industry hasn't caught up yet -- either the hardware isn't fast enough, or operating systems can't support it, or the tooling and infrastructure isn't there yet.
For example, GC was conceived in the 1950's, and through at least the late 1990's it hadn't taken off "in a more mainstream way", and people were saying "this idea comes back around every few years" as evidence that it never would. It turns out that GC is actually a pretty good idea, but the average computer prior to 2000 or so wasn't so good at it, either in hardware or software. That didn't make it a bad idea. It was a good idea that we weren't yet great at implementing.
What I'm hearing about visual programming today sounds very similar. Everyone has a list of complaints, but they're very specific, and very fixable. No good editors -- agreed! The solution, then, is to write a good editor, not to throw out all of visual programming. (Remember what the machine language programmers said about compilers, back before we had decent text editors?) No good diff tools -- agreed! But once upon a time, text didn't have good diff tools, either, so we wrote them. And so on.
If you start with the premise that visual programming is bad, then you will see a list of 10 problems as evidence that it's insurmountable. If you start with the premise that visual programming is good, then a list of 10 problems is your TODO list for the next year.
How do you talk about them? How do you write about them?
It may well be solvable - I'd like it to be, I spent a couple of years of my spare time toying with visual languages, and I still think as an idea there is a lot of potential. But you need a notation that can be read out in a way that makes semantic sense, the way mathematical notation (despite my very many reservations about mathematical notations) can. And mathematical notation is a good example of all the problems it brings in terms of tool support to even ensure you can reliably typeset it without having to include images of it.
I think it's more likely that we'll see improved interfaces to decorate or explore a textual code-base better, though, possibly with some languages starting to be designed with such tools and representations in mind if/when we start to see something closer to a standard emerge.
in general it is harder to build tools for graphical languages, I think this has been prohibitive. parser are hard, but diagrams require constraint solvers and what not, on top of the parsing.
but we came a long way since 1990, both on our actual abilities to build the stuff (JS and the browser can do powerful visual things) but we also understand functional programming and it's relation to mathematics much better.
anyway, thanks for your comments! Nice thread and you are 100% right with the TODO list; we actually build a tool (here is a basic pre-version https://github.com/wires/roadmap-viewer) to manage the intricate roadmap needed for this big project. Stay tuned! :-)
There's a benefit to both. There's a reason why humans talking about a problem so often get up and walk to the whiteboard to diagram a solution. There's a reason Visio has a process flow diagram template built in. There's a reason infographics are more popular than text articles.
It's easier to reason when you have a visual representation of the solution, even if text is a more concise way to represent complex relationships.
But when we diagram we rarely fill in all the details.
On the contrary, we often diagram to abstract away from details.
That is the challenge a visual programming tool needs to overcome: Most likely we'd need to diagram only some parts. Most likely the level of details and which details we want will depend greatly on who we're talking to and what we're trying to address.
This is exactly why we use petri nets and then we map them to a semantics. Drafting a net represents the "diagram part". You draw what your code is supposed to do as you would do on a whiteboard. But this time you have a lot of formal tools to do checks on the net (is it deadlock? Is it live? Does it have nice properties?). Once you are satisfied with the net, you populate it with meaning: Places of the net get mapped to datatypes and transitions to functions. This is the stage where you start typing stuff in. What you gain is that the translation between ideas (diagrams) and code is formal, so way less prone to error.
The most useful visual programming tools I've seen have either been hyper specific to their use cases or relatively thin abstractions over a workflow engine. IBM's BPM is basically the latter, and iirc it would let you drop in a node with a skeleton function that you'd implement yourself. Very useful for non-technical people, but maybe not what you'd use if you're a software shop.
An aspect that I feel is often ignored, or at least forgotten, is the law of leaky abstraction.
The whole point of visual programming seems to be to abstract more, but inevitably they always hit the exact same problem. The abstraction leaks, and now you have to implement an ugly hack.
The only case I see for visual programming is as a standing for a DSL. If you have a very specific domain where you need a nontechnical person to be able to rewire some things often and autonomously, you might need visual programming (although you might be better off with a 50 line text file)
I think you're right. Another angle is that complex programs have a structure that is difficult to draw on a 2-dimensional plane without a whole lot of cris-crossing. There's just too much interconnectedness. Even if you stick to purely functional code, which is typically fairly easy to represent as a DAG, you'll still get lines cris-crossing whenever you have two or more different values each getting used 2 or more times.
The nice thing about visual programs, is they have less requirements on long term memory, working memory, and use more recognition of items instead recall from memory - which is harder.
They are also more concrete and less abstract, which again, is easier, memory wise.
And maybe because of all of those, they also require less focused attention.
On the other hand, it's possible that it's incidental, that textual languages designers don't care deeply about that niche, or that textual languages(and their libraries) seem to evolve towards power/complexity, or that such requires deep work on an IDE, which is a big barrier-to-entry.
I believe that it's mostly because you need to abstract away from the visual form, be it a picture or text, and that, for complex programs, it's easier to abstract away from text than a picture (being more dense may help, but I suspect it's more than that - the apparent visual structure may be a distraction).
The phrase "CASE" covered a lot more things, but the term itself has vanished because nobody would dream of developing software without a computer unless they absolutely had to. Emacs is a CASE tool, for example.
Your response and most others are biased because we have invested years and years of training in reading text.
Fundamentally though, icons and pictures are easier to understand. We can train ourselves to recognize other constructs that don't need to be represented with a fixed set of runes and left to right reading order.
Create a master of two languages one visual and another textual and he will have a real unbiased datapoint of which is better.
Luckily we do. Our diagrams are sound and complete for free symmetric monoidal categories, meaning that every diagram can be converted to a morphism in a category. :)
Because anything programmed in a visual language that is successfull has to scale, and when you scale with these tools- the
system.out.print.and.hang.to.the.fridge moment comes.
Because its a rewrite by the guys who write REAL software.
True. We implement scalability by being able to glue nets together. This allows for a modular design where you can put together many sub-nets doing different things. This is again a purely formal process: It is graphical, yes, but what you are really doing under the hood is manipulating categories (precisely, gluing things together is done via cospans of monoidal categories, I suggest to check Brendan Fong's work about this if you want to know more. There's also a nice paper by John Baez and Jade Master about gluing Petri nets together using something akin to the cospan construction!)
Well, I think it's not really possible to divide a concept from the way it is realized. Many implementations of visual languages were badly done, for sure. This doesn't mean we can go from "this implementation of a visual language is bad" to "for all implementations of visual languages it is that they are bad". :)
To paraphrase Ansel Adams (who was speaking of cameras), there's no one best language, only the one best language for what you're doing. Javascript is the best language ever invented by mankind for the one thing that people do with it, which is write applications that can run anywhere. That's a pretty important use case, not a random external factor. This is a great example of the "worse is better" principle.
I agree if your goal is to destroy your brain use brainfuck. If your goal is to use the best language of all time that has ever existed use javascript.
I used visual programming many years ago, in the form of LabVIEW, and encountered the following issues:
1. The sheer physical labor involved in creating and maintaining programs. I was going home each evening with severe eyestrain and wrist fatigue, due to the fine mouse work and clicking through menus.
2. Programs are more readable until they get bigger than one screen, then all hell breaks loose. You can arrange things in sub-programs, and use the equivalent of subroutines / classes. These are good techniques in any language, but it compounds the physical trauma problem exponentially.
On a separate note, I wonder if text based languages persist because it's just easier to create them. As a result, people are more likely to experiment with new languages, libraries, and so forth, if the format of a program, and its inputs and outputs, are text. If you want to invent a new graphical language, you have to create a full blown graphical manipulation package, and make it work on multiple platforms, just to get started. That's a huge amount of work, and it doesn't necessarily attract the same people who are interested in language development. The result is a more vibrant pace of development in languages if you're willing to give up graphical representation.
#1 sounds like an issue with bad support for keyboard navigation, not an issue with visual programming.
#2 sounds like you might want to take a look at https://en.wikipedia.org/wiki/DRAKON. Albeit Petri nets, as described in the OP article, also address many of these grievances.
I also worked on LabVIEW for a couple of years for our assembly line QA testing. In our case, all of our programs fit on a screen with only a few needing SubVIs.
As long as the programs are relatively simple or are amenable to subroutines, it is one of the easiest languages to learn, teach, and make simple changes. My only complaint for our use case was lack of good source control.
The Fibonacci diagram isn't any clearer than the code. The Petri net animation seems as likely to obscure as it is to enlighten.
I think there's space for making better use of graphical environments, and modern IDEs are already stepping up this kind of capability - code folding, mouseover hints, small automatic parameter annotations. I still haven't seen any case for visual programming.
I've been pleasantly surprised with Microsoft Flow and the related Azure Logic Apps services - for certain classes of problems they seem to work really well.
The trick seems to be recognising when this class of tool are applicable and when they aren't. In particular, I've seen some horrific things built in "visual" integration tools that apparently "didn't need developers" but were far more complex than some normal code would have been.
Frankly the Fibonacci diagram looked way less clear than the code because much of the important details seemed to be invisible.
I think much of what makes VP fail at some point is in the details. Programming is often mostly about the details which is why abstractions seem to leak all the time.
When you have think about the details then a denser representation is extremely helpful. Visual Languages don't generally do good at showing enough of the details at once.
> I still haven't seen any case for visual programming.
Aerodef, automotive, etc all use some form of visual programming. Controls engineers rarely write code, the systems are way too complex. E.g. I highly recommend watching this video from JPL to give you an understanding of where such tools excel. It's about simulating, iterating and then having scientists and engineers autogenerate the code they couldn't possibly write or test
I'm curious to see what you mean, but the link goes to "The Challenges of Getting to Mars" which doesn't show any example of visual programming by controls engineers?
I don't have access to JPL's models obviously, but here's a simple student project 'reverse engineering' the rovers in some of the same tools JPL uses. Note the control diagrams towards the end. These are the very same languages that are used to design & program in all but a handful of cars, are used by every plane manufacturer, to name a few applications
> I still haven't seen any case for visual programming.
Unreal 4 blueprints I guess :)
For low-level code such as "add two and two together" they are pain. But for expressing "get complex entities, retrieve, mix and match required components, and output a set of complex entities as a result", it's surprisingly good. If used correctly :)
Disclaimer: only judging from Youtube videos and tutorials
That is pretty much correct. Even with the pretty good workflow in the UI, creating the nodes for the baby steps that mathematical expressions need can be very tedious. But I find it faster than digging through the C++ reference when I need to call some complex high level function to get some game logic going. Casting a ray for a hit test is a nice example for a functuon that is easier to use from a blueprint with its ~10 different parameters that you need to provide.
Many years ago, I spent a fair amount of time coding in LabView. This is a graphical programming environment initially written to allow (presumably electrical) engineers to write code to drive various data acquisition and control tasks. (I'm almost entirely a software guy, so I'm not the target audience.)
The general approach LV takes is to model computation as a data flow graph. Constructions like iteration, selection, etc. are (were?) all modeled as rectangular regions within the graph where portions of a graph can be swapped out for others or run multiple times. Graphs can also be nested to provide a means of abstraction. Execution has gone through changes over the years, but it's efficient: compiled to machine code with LLVM, and there are also versions that compile LV code to run directly on FPGA's (on some of the hardware products sold by the same company). It also takes advantage of the implicit parallelism that sometimes crops up in data flow graphs.
All in all, LV is theoretically quite impressive. (And since it's been sold for I think over thirty years, commercially quite impressive too.)
As a software engineer, though, I never fully acclimated to the way it worked. If laying out textual code is a challenge, laying out a 2D graph is much worse. The same thing goes for defining sub-graphs - 'naming a function' becomes the much worse problem of 'drawing an icon', or maybe even drawing a family of icons with a common theme. (Although I think LV's been extended with a nicer icon editor to help with this.) Input is similarly a challenge... textual tasks that can be split across two hands and ten fingers become focused on a single hand/finger. (I had to rethink my input devices both during and after the time I was using LV to avoid RSI issues.) And there are also issues with source code control. LV has some stuff baked in, but there are many years of industry-wide experience managing textual representations of code and some good tools for doing it. Switching to a different representation for code means, necessarily, deviating from that base of wisdom and practice.
So, while I think it's a powerful tool (and something more engineers should be familar with) it's nothing I'd want to do my daily work in.
I was a sysadmin for a small EE firm that developed test stands with LabView. The biggest common problem I had -- beyond the EEs not having the technical knowledge to understand how networks or operating systems work -- was that source control was a nightmare because everything was a blob.
It made sense to the EEs because they were used to staring at wiring diagrams. I think we'd have a lot more programmers if we could develop similar programming methods that appeal to different ways that people think.
> I think we'd have a lot more programmers if we could develop similar programming methods that appeal to different ways that people think.
I think this is very well put. I occasionally present on programming topics to my sons' classes. Even as early as 8 or 9, programming is well within their intellectual capacity (and often their desires). So programming tools that don't erect huge barriers to entry... maybe lots of latent value.
I use to make a living creating LabVIEW solutions for a few years in manufacturing test applications and in laboratory applications before that.
It works marvelously if you want put together a UI to process measurements from a fairly wide variety of instruments. Someone who is very skilled in LabVIEW can run circles around most expert Python or VB/C# .NET programmers trying the same thing. Seriously it's awesome. You get parallelism "out-of-the-box" with no problem at all. BUT... these benefits only hold true within the problem domains that LabVIEW is good at.
Once you try to use LabVIEW for truly general-purpose tasks it becomes either unwieldy or no better than open-source tools. Eventually, I had to drop LabVIEW when more and more work involved databases, dealing with network protocols, and heavy integration with API's outside of the NI ecosystem. The $3-5K per developer "seat" is also a barrier to entry for some orgs.
I think there's a place for visual programming for certain types of DSL's. Version control, diff'ing, modularization and some of the other things folks are complaining about here are just technical obstacles that can be overcome or worked around with a bit of creativity.
> The $3-5K per developer "seat" is also a barrier to entry for some orgs.
Agreed. In a world where so many good developer tools are essentially free of charge, this aspect shouldn't be overlooked. Neither should the fact that it's fundamentally a proprietary language offered by a single vendor.
As someone who is part of the target audience of LV, every experience I've had with the software have been terrible. I guess it's mostly aimed at industrial automation applications, but the development environment is buggy and coding with rectangular regions gets old fast.
I anecdotally see people moving towards Matlab and Python for automation these days, though its harder without the incredible amount hardware support provided by NI
> I anecdotally see people moving towards Matlab and Python for automation these days,
For a while, NI provided tools in that space too. There was a product called LabWindows, which was centered around C, and a product called Hi-Q that I remember as being similar to Matlab. I assume that the non-LabView story these days is mostly a public API combined with other people's development tools. (At least that's what I'd hope it would be, given the expense of developing programming langauge tooling.)
> though its harder without the incredible amount hardware support provided by NI
Agreed... the hardware offerings are rather amazing and growing every day (even into some fairly specialized and high-end domains).
I had a very similar experience using SCADE. Especially the trouble with version control put me off. That made it basically impossible for multiple engineers to work at the same time on a SCADE project. It also made code review much harder: you'd have to visually diff the rendering.
Maybe we should spend a few thousand years coming up with a compact, information-dense manner of expressing thoughts. We could call these individual units something like "glyphers" or something, and we could combine them into more meaningful expressions.
Text is a graphical, visual representation. While there are sometimes alternate ways of expressing things, this idea that text is not visual is weird. "Non-textual" representations is better, because we already have a rich, complex capability in good ole symbols.
while text is 2D, together with rich formatting options, program code is only 1D. have a look at the 'subtext' programming language concept that combines tables and graphs together with text based procedures, finally getting away from the constraints of program code that is designed around teletypes.
Code is always written with "indentation" and other things that demonstrate that the 2d canvas distribution of the glyphs you're expressing actually does matter for the human element. You're almost writing ASCII art. The ( ) and [ ] are even in there to evoke other visual types.
It's ultimately 1D for the computer (a string); but so is an image (which according to you would encode 2D media) and any other media expressible in a countable number of bytes.
This seems wrong. A view of your program is 1d. Conceptualizing a program is often n-dimensional. This is a large part of the difficulty. And is why some visualizations work. They effectively act as dimensional reductions, and draw on known visual metaphors.
That was exactly the point I was trying to make. If you have a 2D problem and you want to represent it in today's commonly used code you either
1) flatten it down to 1D (e.g. a table becomes a JSON array of objects)
2) move it into a higher dimensional structure like a database. Now you have two problems.
If your programming paradigm supports higher dimensions to tackle your problems, it just gives you a higher level platform to start tackling your problems. Before you could maybe deal with 4 dimensions at the same time at most, now you can deal with up to 5 or even 6 - we don't yet know what new solutions to problems smart people could come up with when being given such tools.
Just as an example, how often do you see binary logic problems in the form of complex if-then-else procedural structures - what if you could represent two decision factors in a tabular form and let the IDE work out the missing cases for you? That's one of the ideas behind subtext.
Point is I think we agree - if you think I'm fundamentally wrong I'd like to know more exactly where.
I guess I just don't agree that those are your only two options. Consider, a nested JSON structure is essentially N-dimensional. Even something as simple as a list of people is effectively multidimensional. You have the dimension of the list, and then you have the dimension of the the structure representing the people. Which, itself, my have multiple dimensions.
Depends on the program. Anything you use to "index" into data is effectively a dimension. This is obvious with arrays, since you can have multidimensional arrays. However, even structs can just be seen as arrays with symbolic indexes. Usually bound by a given cardinality.
i sure there is probably a term for this type of argument, but this seems hopelessly dismissive on the basis of some pedantic definition of visual in this context. visual programming basically already means non-textual programming. it is about searching for new syntax and paradigms of programming that break out of the idea that one needs to inform the computer with a series of lines of text. text-based programming was born out of convenience and heavily influenced by the underlying implementations. it isn't the result of any detailed study or investigation of how to best represent ideas and concepts or how to properly describe a computation.
That's not really accurate. Visual programming systems have been around for a long time and there have been many studies of programmer productivity in various languages. Those studies have shown that programmers prefer (and perform better with) the languages where they have to type the least. Dragging things around the screen or filing-in dialog boxes (property programming) is appealing to non-programmers but, in practice, seasoned developers nearly always choose text.
Visual programming hasn't taken off because it isn't as good as text for the majority of use cases. This is borne out by more than 50 years of people writing computer programs.
what isn't accurate? there has been extremely little research done in the way of visual programming in comparison to text-based programming.
> Visual programming hasn't taken off because it isn't as good as text for the majority of use cases. This is borne out by more than 50 years of people writing computer programs.
...writing computer programs with text. this bias is massive because nearly no one writes visual programs. a lot of that is due to availability of visual environments, some of which are quite expensive (e.g., labview). most of it is due to bias.
if every single computer science and computer engineering major starts of their education with being taught "this (i.e., text) is how you program and interact with computers" then that sets up a massive bias that is nigh impossible to overcome. any study that does not address this bias is flawed. hence, we have people, who have never even programmed in a visual language, proclaiming visual programming doesn't work. i constantly hear text-based programmers say "oh, visual programming is good for niche things or trivial examples, but it doesn't scale", but yet i have developed large, complex applications with visual programming environments. you know why? because i treat it as real software. i modularize. i take data abstraction seriously. i accept the dataflow paradigm as the key paradigm and build things off of that.
and that leads me to another point. the dataflow paradigm does not map well to text-based languages at all, but it is a very powerful paradigm. visual programming languages are very good at the dataflow paradigm, and so from that alone, they seem to be required if we are to efficiently program dataflow-based systems.
Scratch, the MIT visual programming environment is free. How complex of an app would you like to write with that?
Visual programming is inefficient in its use of screen or paper real estate. How many screens full of Scratch would it take to represent a complex program? Too many to realistically read or scan.
Here again, visual programming is not new. If there were some great advantage in it, it would be more widely adopted. This is a solution in search of a problem.
i completely dismiss scratch as an actual visual programming environment. i honestly don't think of it as visual programming at all because it simply takes a text-based language and replaces the syntax with blocks rather than spaces, semi-colons, brackets, etc. i personally feel it is misguided. dynamicland is more of a visual programming environment than scratch is.
so here, you are taking what amounts to a toy and something directly marketed towards children as your shining example of a visual programming language.
in my opinion, labview is the most complex, general-purpose visual programming environment, and people have clearly written rather large, complex applications with it. why isn't it adopted more? a lot of reasons, one of the biggest ones being cost. the other the association with a particular domain, but i consider it a general-purpose language. even if one gets passed that, there is still a huge bias that text is still THE way to program and interact with computers.
"Scratch" is simply a visual representation of structural editing, with the well-known advantages and drawbacks of the latter. Whether you think of that as "visual programming" is up to you, but the general use case should not be dismissed.
> i completely dismiss scratch as an actual visual programming environment.
well put, couldn't agree more, I often use scratch as an anti example of diagrammatic programming.
visual programming has this topological aspect to it (move a box around and don't change the program), and it demands compatibility with this from the underlying thing, whatever it is, state machines or stream processing functions or whatever.
labview is a great example of a practical use of it, which some relatively minor, but critical modifications you can use it for so many more applications... maybe one day statebox can fill that gap, but we have a lot to do still
I agree completely. Scratch is a snap-together UI for traditional code. Just because the programming text is embedded inside draggable blocks doesn't make it a visual language, its a different UI for a text editor. Sure, its visual, but it doesn't actually change the language at all in any way. It could be just as easily represented as text, the semantics are the same. Its a more beginner-friendly mouse-centric IDE basically.
You've made my point... All languages compile to assembly so every visual editor is just an IDE for a text-based language -- the one actually run by the computer.
That's not what I said at all. I said that Scratch is akin to writing your words on pieces of paper and then arranging them into sentences, instead of writing them as individual letters. Its a text editor that represents words and expressions as draggable boxes instead of giving you a freeform text input. You seem to be saying that since everything is essentially a turing machine, all languages are basically just an IDE for programming a turing machine.
Having a language compile to C (as many languages do) does not at all mean that writing in that language is the same as writing in C and that the compiler is essentially just an IDE or for C. Languages, visual or textual, encourage us to think in a certain way. Even though a visual language compiles down to the same thing as a textual language does not necessarily make them equivalent and certainly doesn't say anything about the kinds of problems they help you solve or the type of thinking that they encourage.
I agree it is dismissive, but disagree that it is hopelessly so. Much of the visual or "graphical" programming hype over the years comes from a lack of understanding what text is and how well it works. The core of the issue with visual programming, is that as soon as you scale to a non-trivial example, it has (almost) always fallen apart.
I actually really, really like the idea of non-textual interpretations of data and code, and use them when text is cumbersome. But they are difficult to do well. Jupyter is an excellent step in the right direction, and a reason it has taken off, I think. Albeit within the statistics subset of software development.
I think it is hopelessly dismissive to denigrate the efforts of software researchers over the past 50+ years and say that they didn't try to figure out better ways of representing ideas. There have been great minds trying to figure out a better way to describe computation. Math and textual programming languages are what they keep coming back to! However, I think we should definitely keep trying, but the basis of new efforts has to be an understanding what text (and math formula) gives us.
> The core of the issue with visual programming, is that as soon as you scale to a non-trivial example, it has (almost) always fallen apart.
people always say this, but it almost always come from people who haven't actually tried to do so or seriously programmed in a visual language before.
> comes from a lack of understanding what text is and how well it works.
i don't think that's the case at all. i am a proponent of both text-based and visual programming languages, hoping to understand hybrid approaches better. if anything, i know where text really doesn't work. for example, text-based languages are terrible at representing the dataflow paradigm and are often more complex than they need to be. visual languages are rather good at this. so we have the situation that text-based languages are terrible at dataflow and no one cares about visual languages, so the dataflow paradigm remains relatively unused, only showing up implicitly in actor-based systems and in minimal ways (simply as pipes) in functional programming languages.
> I think it is hopelessly dismissive to denigrate the efforts of software researchers over the past 50+ years and say that they didn't try to figure out better ways of representing ideas.
i don't think so at all because i really don't think they've tried to specifically understand visual paradigms. i haven't seen efforts to do so, but i would love to see examples if they exist. i have spoken to a rather well-known computer scientist at a conference, and when i mentioned my interest in visual programming, i was immediately cut off mid sentence with the exact phrase "i don't believe in it".
It's worth noting, though, that text is a serial or linear way of encoding information through symbols. In that respect it inherits its structure from spoken language. The significant visual aspect of text is the forms of the glyphs. Typographers definitely do interesting visual things with text, but this hardly ever happens in programming language syntax.
On a similar note, I get annoyed when Eugenia Cheng claims that the diagrams of category theory are "visual"[1]. They are graphs of nodes and edges, which means that they convey topological information, i.e. they are not images of anything in particular. Category theorists deliberately use only a tiny, restricted set of the possibilities of drawing diagrams. If you try to get a visual artist or designer interested in the diagrams in a category theory book, they are almost certain to tell you that nothing "visual" worth mentioning is happening in those figures.
Visual culture is distinguished by its richness on expressive dimensions that text and category theory diagrams just don't have.
[1] "Visual representation has always been a strong component of my work in category theory, which is a very visually driven subject: we turn abstract ideas into diagrams and pictures, and then take those pictures seriously and reason with them."
> Visual culture is distinguished by its richness on expressive dimensions that text and category theory diagrams just don't have.
I think I understand what you mean, but I'd say this unbounded "richness" is precisely what you must avoid in a programming language. In a programming language you want constraints, not freedom. Your visual language must convey specific, unambiguous information and not be open to interpretation or confusion. A program is inherently closer to a formula than to art.
As a complete and irrelevant aside: I wouldn't assume visual artists will consider category theory diagrams artistically uninteresting. Artists are an unpredictable bunch, capable of finding beauty in the most unlikely things ;)
I'm an artist myself, so I said "almost certainly" to qualify what I believe is an almost universal opinion. I don't think category theory diagrams on the wall of a gallery would fly as visual art, though I can imagine an artist (of a more conceptual variety) referencing category theory. I'm not saying there's no possible intersection between category theory and art—just that whatever that intersection is, it's not really about the visual, because we know how constrained the language and appearance of the diagrams is.
Name-dropping category theory via including a diagram in artistic work doesn't mean that the diagram itself is visually relevant. It would essentially be functioning as a sign rather than an image. (Feynman diagrams are a totally different story.)
As far as richness goes: I don't think programming languages have to be austere. "Richness" might be a divisive term to use for it. I just mean high degree of expressiveness. Also, I guess, a high degree of elaboration. A rich type system is not necessarily a dangerously self-indulgent, inconsistent, dangerous one—it might instead be the end result of a rigorous process of elaboration according to strict criteria.
When I was learning how to use a debugger, most of my "uhhh what?" moments were discovering the next line the debugger would jump to when I clicked "step into", "step out", "step over" etc.
I remember thinking, "this can probably be visualized as a little graph in a frame in the corner."
Now that I'm far more comfortable, I doubt I'd use one. But I think visual tools are a brilliant idea for spanning the gap between beginner and expert. At some point you just stop using tools and you disable them in your editor.
Bonus anecdote: I vividly remember making a leap at around 9 or 10 years old from the LEGO Mindstorms visual programmer to writing nonsense AppleScripts and having one of those emotional floods of epiphany about my power over my computer.
People are (rightly) skeptical of this, but I think the first paragraph has the right idea:
> diagrammatic reasoning in particular, is a formidable tool-set if used the right way. That is, it only seems to work well if based on a solid foundation rooted in mathematics and computer science
Code is formal: the symbols have a nearly-unambiguous interpretation as a running program. If there are to be diagrams they must be formal and systematic in their use of notation.
In particular, the author is right that some control systems and interactions are best thought of as state machines, and statecharts are the traditional tool for reasoning about these.
However, the bitcoin ATM example gif in the middle also shows what the weakness is: that's not a complete diagram! It lacks all the error and early return states, timeouts etc that would be needed in a real system. Admittedly this plagues traditional programming as well - qv. exceptions vs. Go style mandatory error checking.
Trying to do a whole program this way also seems like a bad idea; that's the hell of UML that was briefly a fad (qv Rational Rose). Maybe we can just sprinkle a bit in the right places?
Having the diagram represent "control flow" seems to be an anti-pattern, since it gets bogged down in detail. Either dataflow, event flow or state transition seems to work better.
I sometimes wonder if the right way forward would be something a bit like the old "pic" language: https://www.oreilly.com/library/view/unix-text-processing/97... ; SVG is too complex and too XML to cleanly interleave in a program, but pic might work well.
The Idea of statebox (From glancing over the paper on their homepage) is that you draw architectural diagrams. And then these Petrinets have some kind of category-theoretical encoding. Which allows us to interpret the high level architectural diagram to a low level program, by telling what exactly the nodes and arrows do. These interpretations then fill in the gaps on whatever the architectural diagram has (like error handling, UI drawing, whatever).
This is similar to free monads, where the choice of specific interpretation of the DSL is delayed, and even multiple interpreters can exist
> ...you draw architectural diagrams. ...Which allows us to interpret the high level architectural diagram to a low level program, by telling what exactly the nodes and arrows do
This is not a new idea at all - I'm strongly reminded of the whole Model Driven Architecture brouhaha back in the 1990s and early 2000s. Needless to say, it didn't work. You can't do "code generation" from a high-level architectural diagram and expect to end up with a functioning system! At best, if you really do it right, the high-level design might enable you to specify type-like properties that constrain the low-level implementation in a broadly helpful way[1]. But you still have to write all the low-level code!
[1] And this is in actuality incredibly optimistic - MDA and UML didn't even manage that! Instead, all the pretty diagrams (1) were inherently fuzzy, so they did not embody any actual constraints on the implementation, and (2) even in the best of cases, got immediately out of sync with the ground-level truth of the actual implementation.
yep UML and such don't have what we think of as sensible semantics.
> if you really do it right, the high-level design might enable you to specify type-like properties that constrain the low-level implementation in a broadly helpful way
so this is exactly what we do. we have a general way to specify boxes and wires and if you give me some sort of type system and a functor and voila, we can produce some well behaved code. nothing is hand-wavy about it, or "complex", like specialized flags or properties of boxes, just some simple mappings
Hi, the ATM is mega simplified, we tried modelling the entire machine and it not easy. But we are quite convinced it is possible, but it demands features from the language that we have not implemented yet tho.
Error handling is not really a problem, in fact, a lot of the time is spend thinking hard about each and every error that can occur and modelling it out ~ making sure the machine behaves well.
Problems are rather about machine synchronisation and how processes communicate (or rather, can we autogenerate proofs about their behaviour under communication).
Yes it does suck. Not for writing but for maintenance.
I once got dumped a BI project that was written in a visual tool. Simple things like tracing how a field was derived was impossible, because there was no search function. I could search the XML file it produced but that was impenetrable.
It sounds like you're judging all of visual programming based on one project, written in one language. You don't even say what language it was.
Am I allowed to condemn all textual programming based on the last textual program a company asked me to maintain? It had a single function over 1500 lines long, which took over a dozen parameters, had well over a dozen exit points, re-used variable names and values (sometimes unintentionally) between otherwise independent sections, and had zero documentation. And I had to fix a bug in it. "Impenetrable" does not begin to describe it. Text-based programming is a disaster.
That is how it is in every visual language though. It's too much hassle to add comments, so nobody does, and it's too hard to organise things nicely, so nobody does that either. You end up with literal spaghetti code.
I don't say because I don't remember. It was about 10 years ago and I've pushed it completely out of my mind. I do remember it was a Microsoft product. I never want to see it again, and due to a job change between then and now I doubt that I ever will.
Maybe you're right that it's unfair for me to dismiss the paradigm as a whole based on one bad experience. But it just seems to me that the mindset lends itself to a write-only environment.
but this is mainly because those BI tools themselves and the graphical languages they use have issues.
when done properly, diagrams can be searched similarly to Haskell's hoogle, Purescript's pursuit, etc... in addition you could specify a template diagram it should match
True that. I saw a factory whose production schedule was maintained in an Excel spreadsheet - the consultant who put together and maintained that spreadsheet made more than the plant manager.
My experience with simulink and labview suggests that there can be a place for visual programming at the architectural level. Taking Matlab modules and linking them together into some sort of feedback loop pipeline can be very useful for explaining to non-technical team members, and I find that little bit of 2d visualization latches itself into my brain much differently than if it were text. With simulink/Matlab, I think this is partially because Matlab is such a bad language from a software engineering perspective (it's really not meant for large programs).
Maybe there's a place for for text and visual languages together, I'm not sure. Sometimes I have the feeling while staring at an editor with 3 text files on screen that a huge chunk of my brain is sitting on the wayside collecting dust. Yes, there is some amount of visual/spatial thought involved in navigating text, and maybe even mapping that text/project onto an abstract visual space, but I doubt this really takes full advantage of our extremely powerful visual cortex.
While most people don't write networks visually, they often the most effective tools to communicate one's results (whether it is a neural network architecture or just a single block).
Moreover, in particle physics people you Feynman diagrams a lot. And they are nothing more or less than a graphical representation of summations and integrations over many variables.
When it comes to languages, while there are some interesting approaches (e.g. https://www.luna-lang.org/) the only one I actually used was LabView (in an optics laboratory, where it is (or at least: was) a mainstream approach). For some reason, even https://noflojs.org/ didn't catch enough traction.
I wonder if part of the problem with visual programming isn't I/O?
Coding uses the keyboard. Once you get good at using it a keyboard is a much faster input device than a mouse or a touch screen, especially for complex highly structured input like text or code.
Visual programming relies on the mouse or the touch screen so you spend an inordinate amount of time clicking, tapping, dragging, positioning, etc., all of which is irrelevant to what you're trying to achieve.
Maybe a visual programming system that used readily learnable keyboard input or even some novel form of touch panel or mouse input that eliminates the need to futz around with dragging and dropping and positioning would be the way to go?
If you are a very experienced programmer, you program LabVIEW (one of the major visual languages) almost exclusively with the keyboard (QuickDrop).
Let me show you an example (gif)
I press "Ctrl + space" to open QuickDrop, type "irf" (a short cut I defined myself) and Enter, and this automatically drops a code snippet that creates a data structure for an image, and reads an image file.
If you are efficient at this type of input, the "dragging/dropping/rearranging" is similar to refactoring that you would do in an IDE.
The only difference is that there is something called secondary notation in many visual languages (people are not aware of that, I'm only familiar with it because I've done research on the topic - it is how the code is visually arranged).
How code is arranged is kind of a quality parameter for visual code (google examples for "spagetti code"). There are typical patterns that are instantly recognizable to an experienced user, ways of using distance and direction to group connected parts..
I actually played with alternative forms of input for LabVIEW, mainly gesture control and "drawing" on tablets. It sounds like a fantastic idea, but only for 5 mintues. After that, your hands start to hurt. The reality is that keyboard and mouse are heavily optimized tools for input (minimal movement of fingers, and we have lots of muscle memory), and don't restrict you. It's like saying "I can type xxx word per minutes" and thinking that typing faster would help you code faster..
I totally agree with you & thanks for that nice GIF! I used LabVIEW a lot and always enjoyed it... so anyway we have keyboard input for the diagrams / blocks, its very important.
also a minimum of wires, they are annoying to draw
Totally agree. For me any such system would have to come with vim bindings. This pretty much rules out "wires". All wires would need to come from some kind of geometric locality. For example, I have often dreamed of a programming language that uses horizontal and vertical compositions of tiles. It would be easy enough to layer this on top of a language like python, assigning semantics to the horizontal and vertical directions. But it would probably be a bit arbitrary.
The first one is concerned about solving problems (domain experts). They don't really know much about programming, they know how to solve problems though. Once in a while someone clever creates a visual tool for them and they become magically super productive relative to their peers. Be it business process automation (BPMN, workflow automation), signal processing, simulation programs, webscraping, even Excel. However as these people get proficient, in their top-down learning of programming, they start to hit limits of the tool. Then you can see the typical spaghetti code, because the visual tool lacks basic programming constructs like looping, functions and conditional which would nicely compose the mess away. Additionally it can't scale beyond RAM and is hard to put into version control, because they are not in control of the text representation of objects they work with, even though the software uses it under the hood.
The second group of people are programmers. They start learning bottom-up, ie. from conditionals, loops, functions, threads, etc. to actual problem solving. They know all the stuff about proper branching, version control, how to structure the code, programming paradigms, etc. They don't get stuck in spaghetti code, because they have super composable functional languages, where any pattern or duplication can be abstracted away as a function.
There is a huge gap between the problem-solvers and program-creators.
Anything which can be represented as a visual language can be also represented as a text. Unfortunately we don't have textual programming languages powerful or intuitive enough to cater to top-down folks.
I would go as far to suggest that our current formalisms are insufficient for this task. Lambda calculus is very bad abstraction for working with time and asynchronous processes for example. Workflow automation, where 99% of cpu time you just wait for real world tasks, doesn't map to lambda calculus well. Other formalisms like pi calculus or petri nets are much better suited for this and unsurprisingly the visual programming tools often resemble a petri network.
Bottom-up text-based programming leads to much greater complexity because most programmers don't properly model their software (e.g., with state machines, statecharts, Petri nets, activity diagrams, etc.).
But it's not entirely their fault -- code is inherently linear. Mental models are not - they're graph-based (i.e., directed graphs, potentially hierarchical). Text-based code is merely trying to shoehorn graph-based mental models of what the code should do into a linear format, which makes it less intuitive to understand than a visual approach.
Correct, it was an exaggeration. Bottom-up programmers are supposed to have the tooling not to end up with convoluted code, but they somehow manage to do it anyway.
> Bottom-up text-based programming leads to much greater complexity because most programmers don't properly model their software (e.g., with state machines, statecharts, Petri nets, activity diagrams, etc.).
I'd argue that these text-based programming languages and computation models don't correspond to human intuition when they solve a problem and that is the main problem.
> But it's not entirely their fault -- code is inherently linear. Mental models are not - they're graph-based (i.e., directed graphs, potentially hierarchical). Text-based code is merely trying to shoehorn graph-based mental models of what the code should do into a linear format, which makes it less intuitive to understand than a visual approach.
This is one of the limitations of bottom-up code. It is easy to represent linear program flow. It is not sufficient though, as you point out, problems in real world are graph based in general.
On the other hand not all code is linear. Eg. looping is a typical cycle in a computational graph, or petri net when you represent a data flow graph.
init --> loop body --> end
| |
\_________<_____________/
I'd describe parent as a control flow graph, not a data flow graph. Control flow makes clear the interpretation of that cycle as an iterative "loop". In data flow, the cycle shown in your parent comment would instead represent an arbitrary fixpoint: the output of 'end' would be some value x = end(loop_body(init(x))). This inherent ambiguity where the same constructs are given different semantics is actually one reason why visual representations can sometimes be confusing.
The same applies to parallelism - does it represent divergent choice, or a fork/join structure where independent computations can be active at the same time? You can't make both choices simultaneously within the same portion of a diagram! Of course you could have well-defined "sub-diagrams" where a different interpretation is chosen, but since the only shared semantics between the 'data flow' and 'control flow' cases is simple pipelining that's so limited that it isn't even meaningfully described as "visual", it's hard to see the case for that.
Disclaimer, I'm a bottom upper that became a top downwer.
The top down folks in math disciplines have Matlab Julia and R. Visually they often use simulink or labview. These last are more library than language.
Because of their math background the Matlab usually gets done in a functional style which Matlab supports really well. No spaghetti.
right! statebox tries really hard to strike a balance between these two.
in order to make diagrams _as_ composable as functional code, you need proper theory of diagrams and a "compiler" that checks your diagrams for "type errors"
I had slightly more difficulty understanding the diagram than the regex string. But then I'm pretty fluent in regex and that visual representation was new to me.
The big advantage I can see is isolating the visual noise. I'm now surprised that we don't have syntax coloring for regex built into our editors...
Syntax coloring for regex adds noise. When you're reading the non-regex code, having rainbow strings interspersed is not helpful. The best way to approach this problem is to build your regexes in a dedicated regex building environment and then move them into your code at text. Integrating them in-line is not great. (But some people love IDEs, so maybe if you click on a string and have it open up a regex editor...)
The issue with that regex and others I've used is you might be matching on characters that match regex control characters. In that case, it would be nice to know if you're looking at a control character or a properly escaped value. Two colors would be sufficient.
But I agree a full regex builder sort of makes that entirely moot.
That's such a weird way to represent the +, wouldn't it be better to say 'One or more of' or 'At least one of' instead of 'One of' with the loop? I don't see the value of the loops in that expression.
I think visual languages have been vastly unexplored. Sure, textual languages do have some great features (e.g., can be edited by many, many different tools).
In academic research, visual languages have largely been used to study non-programmers performing programming-like tasks (e.g., [1]), but I think that is just the tip of iceburg!
When I started out there was talk of Java Beans that could be used to program visually. Since then I have encountered a number of visual programming tools, and none of them have been much good and generally don't make things any easier.
The best visual programming I have used was MS Access in that you could actually produce something useful without touching a lot of code. But you did need to understand database design to anything useful with it.
The access query builder is a perfect example, it took an understanding of relational databases to use it. Instead of SQL you would drag and drop the tables together. And set up the conditions in dropdown menus. So basically swapping typing for dragging and dropping. Overall it was about as much cognitive overhead as SQL (maybe a little less for not needing to remember the exact syntax for a left join).
Plenty of [bad] visual programming tools have existed. They are often tacked on top of some existing system.
I'm saying that there has been little work that investigates how to design effective visual programming tools. The visual component has to be a high priority in the system's design, not just an afterthought.
I once had a demo from an architect at a <well known technology company> where he freely admitted that the "visual" part of their product was only there as a sales tool so that they could claim it "didn't require developers" when demonstrating it to non technical executives.
The famous promise of no developers needed. What non techies don't realize is that code syntax is actually a relatively easy part of software development.
> What non techies don't realize is that code syntax is actually a relatively easy part of software development.
I don't disagree, but it absolutely is the most overwhelming part to newbies, and is responsible for keeping more people out of the field than pretty much any other aspect of software development.
It's interesting that a lot of sound programming environments are primarily visual -- I'm thinking pd, Max/MSP, and Reaktor. Probably because many audio synthesis concepts trace back to when people literally had to wire hardware modules together with patch cords.
Anyway, I don't think the problem is that the idea of visual programming hasn't been around. It's all over the place, if you look. And has been for ages. The problem is likely that it doesn't solve a problem that developers who use text-based programming languages have.
My main concern would simply be: What do I lose by going visual?
With text-based code I can read every single character and make sure it's all precisely how I want it. Would that be easier or harder in a visual environment?
Or: What if I need to do something not explicitly planned for in the visual environment? Am I stuck cracking open the visual modules, anyway, and writing in hacky Javascript or something that then becomes difficult to see because it's stuffed awkwardly inside of some visual element? (This happens fairly often in the above-mentioned sound programming environments.)
If the gains can't definitively offset those sorts of costs, then I'm not going to be very interested.
> It's interesting that a lot of sound programming environments are primarily visual -- I'm thinking pd, Max/MSP, and Reaktor. Probably because many audio synthesis concepts trace back to when people literally had to wire hardware modules together with patch cords.
Visual sound environments are also tools that are taught to music students in conservatories, who don't have any programming ability. These are tools to make sound / art, and people who make sound / art aren't necessarily programmers.
> With text-based code I can read every single character and make sure it's all precisely how I want it.
and when you make art you aren't necessarily looking for the precise. Some people just throw random objects on their patches and wire them almost randomly until it sounds good ; writing the patch is entirely part of the artistic process. That's a completely different mindset that "client wants feature X in Y time, what's the most easy way for me to achieve it".
> and when you make art you aren't necessarily looking for the precise. Some people just throw random objects on their patches and wire them almost randomly until it sounds good ; writing the patch is entirely part of the artistic process. That's a completely different mindset that "client wants feature X in Y time, what's the most easy way for me to achieve it".
You're right in that art is guided by a different set of goals than client work -- it's inherently more exploratory.
But it's inaccurate (and unfair) to call it imprecise. (Also unfair to assume artists work "randomly.") If you're an artist who cares about your work, you put a tremendous amount of effort into achieving your vision just as you see it. If a tool fails to work as you need it to, you'll abandon the tool, whether it's a paintbrush, a chisel, or Max/MSP.
The fact that two major commercial sound programming environments are visual doesn't necessarily mean people who use them don't understand computers and are just randomly throwing crap at the wall: It means they work best for the professionals who use them to get their creative work done. They are, after all, relatively expensive pieces of software.
(It's also inaccurate to assume artists and musicians don't ever have programming ability. I'll point to myself as an example.)
I don't think that art and precision in the way that the comment you're responding to are compatible. I haven't experienced any artistic situations that haven't involved throwing random impressionistic shit at the wall, then precisely shaping, reducing, and exaggerating aspects of that random shit to make something new.
Precision comes in after the randomness, in the craftsmanship; that's what differentiates a skilled person from an unskilled person; both can do the first part.
When you're programming, or participating in any craft that doesn't prioritize uniqueness or expression, the precision starts from the beginning, though. The only randomness sometimes is where you start, not what you start.
also, ideally the precision in the statebox kernel is hidden from the user.. nobody needs to really know about profunctors or monoidal categories, unless you want to work on the language tooling itself.
I think the problem is visual systems make it harder to create your own abstractions. You can't have all the complexity exposed in a single level, you need to be able to hide details at a lower level.
For example, each module in an audio program you're wiring together is basically a function with a ton of internal state. But you also need to be able to create your own modules composed of other modules, and maybe some lower level functions, e.g. EQ, signal sources, delay/reverb, etc.
The only visual system I've used is GNU Radio, which requires XML/Python/C++ to create your own blocks AFAICT.
- macros for diagrams, n-bit-adder for any n
- "boxing up" diagrams, or some sort of nesting of diagrams
- management of state
there are separated concepts in our tool, macros are a 'meta language', in principle one can write functions in the host language that generate diagrams and then proof that those diagrams are well behaved in some way. there is theory on how to do this for diagrams, but we have not implemented any of this yet
boxing up is a natural operation of the system; we get that for free sort of
state is handled by folding functions over the history, so you get a nice and clean way of dealing with state
but you are right, this ability is very important; it is a lot harder to do tho, but it's possible now I think
You are right about this, it is exactly what is hard to do!
it is possible to do some form of this, where you have well behaved "macros" that create diagrams of particular shape "at runtime" (forall n. the diagram with n copies of n)
Pure Data, VVVV, they have shown that data-flow programming works. They even occasionally look like circuits. Max/Msp, Reaktor, luna-lang, they show there is real demand for it.
I hope more people bring those languages into the rest of the programming communities.
totally what statebox is trying to do, we take some theory to put the diagrams in the right place and take it from there! thanks for mentioning these tools, they are all awesome to use
As a linear medium, text is good for chronology. Visual is multidimensional and much better for topology. It's no accident that many succesful visual DSLs mentioned in the comments are dataflow langs. I also think some of the pessimism regarding visual languages is due to how much better text editor tooling is. Still, it would be a good idea to avoid convincing ourselves that our current local minimum is the deepest of 'em all.
Thanks for putting it in such clear words. I thought about "micro" vs "macro", but chronology vs topology is much much better. There are micro algorithms that i wouldn't try to put in diagrams, and huge data mappings that i would perfectly understand with simple arrows and boxes.
Thanks for the kind words! My doctorate was about a DSL for musical signal processors [1]. Current post doc is about programming interfaces - I hope to Show HN in a couple of months!
There is a long history of research that the author would benefit from reviewing and citing, e.g. this article from 1995: "Why Looking Isn't Always Seeing: Readership Skills and Graphical Programming"
Visual Programming doesn't suck, but it doesn't really help either. It's still programming. Non-toy examples are going to be just as tricky to understand and debug as text-based programming.
I think text scales slightly better but it could just be that we don't have the tools to scale graphical programs yet. But in the end, the hard bit is figuring out what you want the computer and then explaining it correctly to the computer. The exact symbols you use to explain it are much less important.
I agree. Regarding tooling (and lack there of) and mention that Unreal Engine has a visual programming language called Blueprint [1] and part of why that is popular is that it reduces the initial friction for non-developers and has good tooling (auto-complete and other IDE like functionalities). So I do think that with more tooling might pave the way for visual programming. Additionally, Blueprints are conducive to prototyping. So I think there is a market value in visual programming; though still not sure how stuff "scales" as you mentioned. There is also a consideration of "focus". I think Unreal Engine team is focusing more on Blueprints which has made some people feel like its hard to GSD [2] with programming as the support/documentation is not as good.
I think UE4 and its Blueprints are very nice and cool but with regards to how stuff might or might not scale I feel compelled to link this site called UE4 Blueprints from Hell haha https://blueprintsfromhell.tumblr.com/
Of course anyone can make spaghetti in any language, text-based or visual, so don’t think of that site as “proof” or anything. Just a little bit of entertainment that’s all.
I don't know blueprint, but I'm wondering if after some time using it you begin to pick up patterns from looking at zoomed out code. One thing that strikes me is that each of these "nightmare" examples has a very definitive and recognizable form. There are certain structures that one can pick out and recognize between diagrams. It reminds me of being able to discern nested loops and long switch statements in traditional text code minimaps. It might be the case that these code maps look like a spaghetti mess to the untrained eye, but the variety of structure in the code allows skilled developers to zoom in on a bit of code the way you can zoom in on your house in Google Earth without any help.
I can think of one example that while more concrete is still pretty niche - Quartis Style block diagrams for instance.
It is an easier way to organize than just a table of pin numbers as opposed to "make programming so we can get a job but without the math or other gross technical stuff that" clueless advocates.
Also more for field programmable gate arrays than code although you can work with gates directly along with some analog inputs and outputs.
Easy: because it's meant to be consumed by people who don't yet agree with the claim, and they are more likely to consume it as text. Same reason you wouldn't write an article about why "You should learn Italian because it's the most beautiful language" in Italian.
The probable reason that this is not a video is that video production is not only more expensive than text production, but also involves entirely different skills. As a rule, visual programming does not require you to buy a video camera or learn how to present yourself on camera so I don't really think that your argument follows.
Disagree. While there are reasons, this comparison isn't apt. Videos suck because of their linear format and inability to search/reference, which doesn't plague visual programming. I could just as easily write "Why are there images and not all texts in these articles? That same reason is why visual programming can, in fact, not suck".
Visual programming suffers from the same low information density as video. I've actually had to work in visual programming environments and anything of moderate complexity (lets say a single average source file length) is simply visually untenable. A simple class you can page through in 1 minute is 20 screens in each direction represented visually.
I think that's more of an indictment on the specific environment/software you used than visual programming in general. One could argue thinking in terms of classes is invalid. Visual programming has value at a higher level of abstraction e.g. workflow management/stitching of components.
I used class as an example but the product was for workflow management and stitching of components and it was, frankly, ridiculous. Nothing was wrong with the product itself, it was sound. But the entire concept of representing working software visually that is unmanageable.
Honestly people can read and process text much easier then they can follow active visual nodes and lines. And I'm not talking about an abstract diagram; we are talking about visually designing something detailed enough to be executable. I think most people imagine visual programming based on pretty high-level abstractions but that's not the reality of programming.
Anything even moderately complex is too big to see all at once but could easily fit on a few screens of text. Making changes is even worse. I can easily move to the top of this paragraph and add another paragraph (which I just did). Have you ever tried moving around 20 visual nodes? Almost impossible to do easily. I just re-wrote a few sentences; easily 6 clicks and typing in a visual environment.
You are talking about deficits in the tools to work with graphical representations and lack of language support to contain behaviour to a single box (like a decent type system and separation of effects from pure computation)
I am the first person to admit that visual programming goes wrong about 95% of the time, but it doesn't have to... also nobody is expecting everyone to swap out their tools for statebox haha
check back in a few weeks... we are working hard on the tools and you should be able to try it yourself.
I definitely want a good demo video on the page.
but listen, I get it, I tried literally 50 different such tools, they all suck. Nobody in their sane mind decides to write one if you don't have a good reason. Certainly not in Idris :-)
but we have good reasons:
1) compositional theories of diagrams exists
2) such diagrams can express many "topologically equivalent" expression in the same diagram, this is a huge win! and very different from (AFAIK) all existing node-based editors
3) use cases in decentralised computing require fault-free tools that work like this
but really, I think generally applicable usable 2d-syntax exists...
I think most people here disagree with general applicability but if you had simply sold it for your specific use-case/domain you'd probably have much more positive responses.
OTOH, a side-effect of working categorically is that we really assume very little, so we can apply the system is many things (at least the core doesn't restrict us, of course you still need to write code etc).
this is unlike all other systems which are domain specific.
you should think of it much more like an alternative syntax for bits of constrained Haskell code... anyway, thnx for the feedback, I am mainly surprised to see this on HN =)
None of the examples he shows are clearer than text code. None of the examples are quickly and easily modifiable - call it malleable, if you will - as text code for debugging.
Sure, visual programming might “not suck”, but it sure as heck isn’t a viable tool for serious software development outside of a few specialized cases.
This thread is a little perplexing. There's some great commentary going on here, and some fantastic references.
However, why does it have to be a binary Text OR visualization? Code gets loaded from a file into an AST, from there you can transform between textual AST representation and other visual representations.
I expect the right answer in the end will be both AST based code views and visual tools to show flow, time/space requirements, interfaces/coupling and such.
Imagine writing code, then using the scroll wheel to reference the overarching project graph. Perhaps with:
- edge size/colour representing function call frequency,
- vertex size/colour representing time/space complexity
- some other cue to represent datatypes.
- another view to represent and inspect datatypes in your application/query them. Ala Quantrix or Lotus improv "spreadsheets".
- Another view showing state changes and functional code.
Things don't always need to be binary decisions. Instead of saying "visual code doesn't work", perhaps we should try "Great artists steal!".
"Luna is the world’s first programming language featuring two equivalent syntax representations, visual and textual. Changing one instantly affects the other. The visual representation reveals incredible amounts of invaluable information and allows capturing the big picture with ease, while the code is irreplaceable when developing low-level algorithms."
It might not suck, but the cost benefit analysis ends up washing out any value it might have.
Text is glorious and portable. I can run emacs in a terminal. I need a software stack just to look at my code like I need a hole in my head.
The thing I really hate about visual programming is that programs are fundamentally tree structured and 2d space introduces extra degrees of freedom which, for me, impose additional cognitive load.
Christopher Alexander (the architect) wrote a paper called A City Is Not A Tree. I don't know of any paper called A Program Is Not A Tree, but one could be written. Programs are fundamentally messy tangles of references, as far as I can tell! Compile-time structures are utterly different from run-time structures. Some languages have both dynamic and lexical scoping. Etc.
you can reduce an individual function to a a directed graph (not a tree). But once you have more than one function? That's graphs referencing graphs. That definitely doesn't reduce to a tree.
The only parts of a program that reduce to a tree are incidental to their functionality - the nesting-block structure of procedural, C-derived languages, and the tree structure of a filesystem.
> the cost benefit analysis ends up washing out any value it might have.
For you, apparently yea, but for others maybe not. We don't all value the same things. Visual languages are especially friendly toward new and young learners of programming.
> programs are fundamentally tree structured and 2d space introduces extra degrees of freedom which, for me, impose additional cognitive load.
Interesting, you say this, because I draw most trees in 2d, whereas text is a 1d list of statements. To me, a 2d space better maps to the programs I tend to build.
I've had to use a number of visual programming tools and I never truly appreciated this argument until I had to deal with all of the trade-offs.
Most visual tools handle version control poorly. Refactoring and reuse is a joke. They often require a lot more work to do simple things that can otherwise be expressed with a simple expression.
What I do like about this article is how the author shows many different projections of code and I think that's really the key. I personally think before we try to tackle the difficult problem of building a visual editor, a better problem to solve would be projecting code that's written in a simple text editor into different graphical formats.
There are a few challenges with that because turning existing languages into visual representations is a challenge itself. One can imagine the challenges of projecting a function in your code base into a graphical representation.
Let's say you wanted to project a class's method to a sequence diagram. In order to keep your diagram clean, you'll want to display and emphasize method calls to external services and elide local method calls, which aren't so relevant in your diagram. How do you solve that? Do you require the programmer to annotate the various aspects of their code? Do you assume some sort of convention? That might work with green field projects, what about existing code that already violates conventions? What if you want to have different projections of the same code? Do you litter your code with annotations?
The key point is different diagrams communicate and emphasize some things often at the expense of other things, and automatically figuring out what needs to be communicated is hard for humans, let alone tools.
Personally, I'd be interested in a set of DSLs that would not only project the different aspects of your program, but would work together to verify the correctness of your program. You might have a simple predicate DSL you'd use to describe what invariant conditions must always hold. Maybe you'd have a DSLs to describe how services communicate with each other.
I would really like to see people who are researching visual programming to take these issues seriously and not discount the value of text. There's not one reason why text prevails, there are many reasons. If that's not convincing, consider The Lindy Effect which suggests that the future life-expectancy of a technology tends to be proportional to it's current age. In other words, if something has dominated for 50 years, knowing nothing else, it's likely to continue to dominate. Forks, chopsticks and wheels are elegant solutions that have been around for thousands of years. I'm not saying text is the same, but I feel like a lot of people (not all) working the on visual programming tend to underestimate text.
My experience: a few years of (intermittent) work with webMethods Flow Services (which is "Visual").
Conclusions: text-based programming allows you to:
- grep for all files where you used "Inc x".
- use diff to compare two or more versions of the same module
- comments are easily integrated with "code".
None of this is true for Visual programming.
Also, in my experience even if you are "visually arranging blocks" and "connecting these with arrows" in reality a lot of properties or parameters to the blocks themselves are specified by manipulating strings and numbers.
Except that those cannot reliably be grepped or diffed...
Well, I'll just say that a graph is not bad datastruct for diffing and versioning [1].
The other problems may be true for now but also seem pretty low-hanging fruit?
I do not understand if you have actual practical experience with medium-complexity projects with visual languages.
Also, wM have been around for more then 10 years now. I am not using it anymore but I have colleagues who do. The "low hanging fruit" stays unpicked, so maybe it is not so easy to provide the things I listed?
From the end-user perspective, you are likely correct. I was musing with my PL designer hat on. The difficulty is the huge amount of work that has gone into the entire unix way or developing software. That's the seductive local minimum.
I think Visual programming is OK when your control flow is linear, and doesn't have too many branches. However, when your control flow contains primitives like break/continue/try-catch, it can get pretty messy very quickly.
On the other hand, I think visual programming is much better suited to tasks where your dataflow is multidimensional. For instance, linear pipelines are simple to construct and read in commandline form, but try reading a multidimensional dataflow with commandline.
Lots of people seem to think that Visual / Textual programming is an either or. The idea behind statebox is to build a bijection between a (structured text)-editor and a Petri net that shows the program diagrammatically, editing either will edit also change the other so you can pick the perspective that best fits the change you'd like to make.
The original paper defining Petri nets was intended as a new foundation information systems based on communicating automata so that the fallacious "global state" idea is not a prerequisite. It makes a lot of sense for there to be a programming language based on this formal system for expressing computation.
There has also been a lot of progress in understanding the mathematical structure of Petri nets which is something like a symmetric monoidal category but I'm no expert so fact check me.
That's nice, but all I see on the statebox.org website is vaporware. Where's the MVP? Even just having one component available (structured text editor or diagrammatic editor for the underlying Petri net) would help a lot.
we are working on the MVP, getting there, this wasn't supposed to blow up yet, don't want to give any wrong impressions.
currently a lot of our efforts are going into a core component of statebox, https://github.com/typedefs it is library similar to protocol buffers, but it fits well with proof assistants / functional languages / category theory
I agree. I've been working for a few years on my own interpretation of whether it's feasible to have a visual system aid in creating a real program output. Here is an example that I'm still refining: https://github.com/kyleparisi/pagination-layout#pagination-l....
The translation of the above project really caused me to think hard. My hope was that visual programming would make the cognitive load easier. This might have been because I had not determined the subtle rules required to write a flow. I need more practice, but I think it will be a different flavor of thinking. Not better, not worse, different.
I appreciated reading all of this; it's a topic that obviously brings lots of opinions to the table. Here are my thoughts on the matter, honed over many years of using visual programming languages and system, starting in the mid 1980s.
Consider this. The visual system in animals has been in development for hundreds of millions of years. And yet, most animals don't think at a high level, demonstrably.
The biggest jump in human cognition is tied to the invention of speech. Speech is a fairly slow mechanism, and serial. Communication could be multi-channel and use position, tone, color, odor and movement. And yet, communication through speech dwarfs all of that. It's what let us bootstrap ourselves above other hominids and other animals. While multi-channel communication holds out the promise of high bandwidth, it's also incredibly imprecise. What exactly is being communicated in non-speech channels? That's up to far more interpretation and guessing than through the apparently more limited mechanism of speech.
Then, sometime around 10,000 to 5,000 years ago, writing was invented. Writing is even more constrained - most people can speak faster than they can write, and yet the increase in pace of development of human abilities is tied to the ability to express and manipulate thoughts in writing. It's not just that writing can be one to many (far more so than speech). It's that writing is more precise, and we can build up far bigger thoughts in writing that we can comprehend. It's likely that analogies are bootstrapped through use, first in speech, and then in writing.
So, in this framework, visual programming is doomed. It's a throwback. Despite the very large number of neurons devoted to visual processing, the amount of summarization and guessing in the visual system employed to reduce the flood of data to something manageable is also part of its weakness when it comes to forming precise and complex thoughts, and to manipulating them.
We will always visualize things in order to help understand them, because we use more of our brain when we do that. But it's the very limited and narrow mechanism of speech (and writing started as "record that speech") that makes it far more powerful when it comes to complex thoughts. If you look at all the visual programming systems that have been developed, they only work in narrow and prescribed modes. They are not open-ended, and they literally fall apart at moderate levels of complexity.
Without text (speech being the system that jump-started text), we would not really be thinking animals.
Every visual programming system I’ve seen makes easy things even easier and hard things much harder if not impossible.
Visual programming makes simple logic easier to code, as well as making it quicker and more intuitive to compose plug and play modules / functions. But that isn’t the hard part in ordinary programming. The hard part is adapting libraries that don’t just plug and play with your system out of the box, or dealing with asynchronous calls / services, or trying to transform complex data formats into what you need. That is where most coding work goes, and visual programming systems offer nothing of value.
I've said a lot about the struggle with diffing visual code but I think one the other beefs I have with visual coding is ultimately the same reason I hate whiteboard coding:
If you try to build code top-down, even happy path first, or iteratively (over a long enough time horizon, all code is developed iteratively), the whiteboard is completely unforgiving about squeezing more code into the middle of a block of existing code. This is basically a non-issue within a text editor.
How do you avoid invalidating your 2d layout of visual code while adding new conditional behaviors to the middle of an inner block of code?
And on a related topic, any tool that fights 'extract method' is not for me. Refactoring is painful enough as it is without adding speed bumps along the way.
I think some of these problems are solved within game AI path finding heuristics, but I know of only a couple of visualization tools that had an automatic layout algorithm that wasn't worse than nothing (dbviz as I recall had a fairly decent heuristic for 'flattening' a graph so that very few lines crossed).
Valid point, but this is why there is category theory. That is really about the "compositionality of systems", we need that more than diagrams. Just turns out diagrams are a good way to do things with categories
Used to work with Rational Rhapsody. Big project with a lot of fancy state charts - that was nightmare. Visual programming does suck (unless it's Simulink).
Some of what the author advocates for was incorporated in Rhapsody and other tools (LabView) a decade ago or more.
The response to critics is basically:
> ...tooling they’re accustomed to can’t be used properly.
I think that understates the pain of peer reviewing WSYWIG diagram changes (the closed diamond is now an open circle!) that affect production software.
Look, I love text a whole lot. But I want to program without a desk and without sitting. In 2019, programming should be as portable as guitar playing. The thing holding us back is reading and manipulating text.
We should take the things that text does well, and find an alternative that offers the same functionality in non-desktop contexts.
> Look, I love text a whole lot. But I want to program without a desk and without sitting. In 2019, programming should be as portable as guitar playing.
But without holding or playing a guitar?
Programming is already as portable as guitar playing; it's just far less linear so it involves a lot of backtracking. How do you handle backtracking on your guitar? Somebody, sitting at a desk, scrolls backwards, changes some parameters, and edits.
> In 2019, programming should be as portable as guitar playing.
It is, a netbook is great for coding and much smaller and more portable than a guitar. If you want to do it without sitting then you'll probably want to get a strap to hold it, much like guitars do.
You captured my thoughts perfectly. Many times I've been sitting outside with my phone or tablet in hand, wishing there was a natural way for me to get application logic from my head to the computer without a keyboard.
Well, I can guarantee that's not going to happen anytime soon. Phones & tablets fundamentally have lower bandwidth into the device. You need something that doesn't cost much, or even increases the bandwidth while still being portable. A touch-screen only interface isn't going to be it.
Note I'm making an information theoretic argument here, not a wishy-washy humanish discussion of "information". You literally have fewer bits/second you can input meaningfully on a touchscreen. This is something objective, not just an opinion. The fundamental sloppiness of the inputs, which is the fundamental reason for things like mobile interfaces having larger buttons than non-mobile interfaces, for instance, contributes to the lower bit rate.
(I would remind people who wish to dispute this of at least the following things: Information is a log-based number, so for instance "I have four types of swipes" does less than you might think, and you need to account for real information that can go in by a human, not just what theoretically something else could do. You are not a robot individually manipulating every capacitance sensor on the screen, nor does your finger teleport around and tap ten distinct selections per second at an accuracy of less than two pixels. Nor can you build an interface where a swipe in this direction does that, but if it's two degrees farther counterclockwise, it does something else entirely, nor are you going to be using an interface where every slight variation of a curve is meaningful. Swype-like tech is pretty much the upper limit of what you can count on, and honestly, at times that pushes it.)
I wish I could remember the name, but there was a demo of an experimental IDE for phones and building up blocks of odd shapes and directions that fit together like a stone wall. It wasn’t Scratch based. I think it was declarative rather than procedural.
> Nor can you build an interface where a swipe in this direction does that, but if it's two degrees farther counterclockwise, it does something else entirely
Two degrees, of course not. But https://en.wikipedia.org/wiki/Pie_menu are a thing. Swype text input is nowhere near the best we can do, it does not have context-driven feedback of any sort. The most annoying issue with touchscreen-only input, IME, is actually recovering from input errors, and (relatedly) confirmation for irreversible actions. Low-level environments for "modding" Android devices get this right - every destructive action always requires confirmation by issuing a full swipe, and it's only destructive actions that require this. Of course, porting this paradigm to more traditional environments (such as typical GUI applications) would require quite a bit of work.
In ETL there are some tools to visually manipulate the data flow from one end to another. Some ETL software even allow you to visualize the effect of the changes on the fly, much like the Mario game. Solutions developed like this are easily understandable and maintainable by others even with minimal documentation (but require understanding of the business problem). But, much like normal programming, once you want to do something that exceeds the capabilities of the ETL software you are using, or when performance is an issue, you have to understand how the underlying software works under the hood. You can become really good at solving one set of problems with a ETL software once you have mastered it, but this is limited to one domain of problems. Likewise, specialized software allowing easy visualization and manipulation is usually very domain specific.
You can tackle complexity in programming hiding it behind libraries and databases that do the heavy lifting while the programmer integrates the pieces and accounts for particularities of the problem he is solving. I could envision representing library functions as black boxes and connecting arrows to integrate them, having input validation and strong typing or automatic typecasting. Still, when you get too far from the machine, you miss the edge cases, the things you can't imagine when you visualize whatever you are creating in your head, the problems that only arise when you externalize and codify the knowledge. I think this is at the core of the issue; in order to instruct the computer to do something, you have to externalize tacit knowledge. In doing so you come across problems you just can't see from too high up.
It probably depends on whether you are visual type (40%), emotional type (40%) or audio-textual type (20%, dominating academia). I am clearly a visual type with perfect color vision and my brain can do "search" on the screen in literally one "frame", i.e. localizing term I am searching for instantly instead of going line by line. So YMMV and whatever works for you instead of "there is only one true way and everybody needs to follow it".
It's interesting to explore what an "emotional type"-optimized programming paradigm might look like. Perhaps something like word problems in school math, where you target understanding by rephrasing what's originally a mathematical statement into a "social" problem, involving real-world agents (such as people or firms) who might interact with one another in some well-defined way? I assume this is an underexplored area, albeit social scientists have no doubt started addressing it with things like "game semantics" and the like.
Visual programming systems I’ve used seem to have problems that are still present in traditional text based languages. Most of the value seems to be entirely built around helping non-programmers provide value to programming related output
- Modularity / reuse is tough
- Tracing is difficult to do as a system increases in complexity.
- Distributed systems including primitives like locking semaphores are difficult to express visually and are thus still difficult to author. How would you demonstrate to anyone that you don’t have deadlocks and race conditions across modules?
Data flow and perhaps control systems (AI scripts and GUIs built around something declarative and event-driven come to mind) indeed seem to be the only commercially successful examples of visual programming thus far.
If these visual programming environments serialize to normal languages then the tooling to validate them is pretty straightforward. Instead, most visual programming systems seem to be entirely domain-specific and are made custom for a specific set of needs so formats tend to be proprietary and not applicable across different domains. It’d be cool to see a visual programming language based upon something like Squeak but this approach seems to have not caught on.
> Data flow and perhaps control systems (AI scripts and GUIs built around something declarative and event-driven come to mind) indeed seem to be the only commercially successful examples of visual programming thus far.
I strongly disagree. Here's an incomplete list of commercial software in VFX for visual "programming" for artists:
IMO "GUIs built around something declarative and event-driven" covers systems like Houdini and Massive - they're "declarative" in the sense that the scene graph is defined beforehand, and "event-driven" in that they react to external inputs with everything from behaviors in Massive to demand-driven lazy calculation in Katana.
I know a rookie who have been playing a game called While True: learn () on steam. It looks like circuit board simulation, player is supposed to direct colored blocks to the specific destinations depending on what's exercise about. It appeared to be more of a railroad station simulator to me.
When I was making my first steps, in DOS, all programming for rookies was about chess boards. Almost every programming environment for beginners was a derivative of a chessboard, we moved pieces, found paths, backtracked here, beeped with 0x07 there...
Today, when chess-autists are retiring, maybe the new waist-deep-into-networks generation coming is more lenient on how developer tools should look like. I don't believe they will've substituted actual coding with grandma's embroidery, but a handful of daredevils who will create more powerful tools like DDD debugger are surely welcomed with open arms.
To me the thing that visual programming excels at is parallelism. Traditional procedural languages are fundamentally one-dimensional, and parallelism is difficult to view in 1D.
The biggest challenge is how much of our tech stack is based on raw text. Anything that isn't text-obsessed means you can't use diff, git, grep, vi, etc.
Outsystems is good. I have programmed in it for 2 years, and we also built a product having some very dense UI. But in my experience it is still not perfect. It lacks some mainstream features and has limitations. It does not model web apps as SPAs but for mobile app it does. Granted we can mix JS but that only complicates things.
How do I do multithreading in Outsytems? I know there is BPT - but BPT and timers have their own limitations.
I could go on.. also Outsystems these days only keeps C# as backend stack. I should have the choice of Java as backend with multiple other runtimes.
Yes its not vendor lock in, but this is technology lockin.
I had great hopes from Outsystems and to an extent it hits the sweet spot. But cant recommend it for modern, complex distributed web apps .
On the SPA front, I believe there will some movement on that front this year. Look out for "Modern Web Apps" as a new application category.
For multithreading, I take your point and agree. A heavily multithreaded component is not the best use case for OutSystems and if you want to use one, it is probably best written as an extension in C#.
As for dropping Java support, here's the rationale: Trying to support .Net and Java was costing engineering resources and also leading to inconsistent user experiences. Additionally, there are lots of other languages/platforms out there beyond C# and Java so the approach going forward to integrate with heterogeneous languages/platforms is to integrated into them using containers which is supported from version 11.
As for lock in, that's true of any proprietary product. However, it's worth noting that if you terminate your subscription you get all the source code and can run it up independently of OutSystems. Of course, you might argue that it's not as easy to change, which is true - but if you want to do lots of changes quickly, why not just stay with OutSystems? :)
So finally for complex web apps, I would argue you can do it (and you can check lots of references of places that have) but the tech is old and this will be improved starting this year. You can also build hybrid (i.e. Cordova based) mobile apps easily too - almost a third of new apps built on the platform are the latter.
Visual Basic 6 was a real sweat spot of low-barrier-to-entry visual tools and simple scripting with enough of an escape hatch through COM to do really crazy stuff if you needed to. Complete pain in the ass to manage large projects, but then, it wasn't that much easier in Visual C++ 6 at the time.
Visual Basic is one of those tools that looks very different when it's mostly in the past than it did when it was mostly in the future. For its time, VB was a huge, amazing, incredible simplification of what had formerly been about that much of a pain. This is part of why it tends to be reviled today, but it opened up the door for a large number of people to address a large number of problems that were heretofore mostly unreachable for them.
That type of tool... the tool that lowers the barrier to entry and makes more problems addressable by more people... that's a good thing.
(But, FWIW, VB is not really a visual programming language... more of a visual development environment built around an almost completely textual language.)
I think that was the point of the original article. That we can use more visual told to augment code, rather than trying to reinvent programming from scratch.
Have you played with Racket at all? There is another concept from the DrRacket tool that I really enjoy. Images have their own print mode, i.e. getting displayed in the REPL just by referencing them. Similarly, Matlab and Octave make printing matrices and graphs just a natural part of the experience.
There are probably a lot of good reasons for storing code as text, not the least of which are diffing as well as transmitting to/from other authors with their own toolsets. Merge visualization is a type of visual task related to programming.
Unix and its shell concept were supposed to, kinda, be this. But I think it got lost in the need to build production server environments. Who is the modern Symbolics with their LISP machines?
> Have you played with Racket at all? There is another concept from the DrRacket tool that I really enjoy. Images have their own print mode, i.e. getting displayed in the REPL just by referencing them.
I haven't played much with Racket, but I have worked with other systems that do this. (I've also developed a feature like this feature myself, many years ago, in a system I was building as a small-scale data analysis tool.) And yes, I agree that the combination of a REPL that both uses the full capabilities of the output device and renders objects that 'know what they are' is transformative. It makes entirely different classes of work that much more interactive.
In addition to the graphics, it still seems like a miss that I can't type 'ls' or 'find' at a terminal prompt and drag a filename from the list into a finder window to move or copy the file. (But getting to that point is work on several different levels... ls would need to produce output that somehow annotates each output filename with the fact that it's a file with a specific full path. Then the terminal would need to be able to intelligently work with those sorts of annotations.)
> There are probably a lot of good reasons for storing code as text, not the least of which are diffing as well as transmitting to/from other authors with their own toolsets.
I think part of it is history... both inside and outside the field of computing. It was technical limitations at the beginning of the field that made text more or less the only choice for early programming systems. (Unless you count the even earlier plugboard machines.)
Outside the field, images alone don't tend to be used to represent the sequences of events that are so common in programming. There's always a convention for imposing a sequence layered atop the visuals. This text, by convention, reads left to right. Pictographic languages have an ordering by convention. Comic books have both a convention to the ordering of frames and (mostly) the text within the frames. I mentioned LabView elsewhere in this thread... it's a visual programming language, but it has an explicit sequence construct (that models a sequence visually as frames of film that can be paged through).
I guess my point is that textual representations have a lot going for them out of the box... including an historically natural modeling of the notion of sequence and a huge volume of tooling and process optimized for the purpose of manipulating text. For a visual language to succeed, it has to offer compelling enough advantages to outweigh the cost of walking away from those things.
Hi, Statebox founder here :-) awesome to see this on the HN frontpage. Will read your comments and give feedback, meanwhile, feel free to ask me things!
Thanks for linking to graphicallinearalgebra.net . I finally sat down and read it today, and (loveheart-emoji). This stuff looks more complicated than just writing a bunch of matrices, but it really does go to the deep of linear algebra.
Awesome stuff right? Pawel is great at explaining things!
It is certainly more complicated in the beginning, partly because it is a paradigm shift, and partly because of the abstract nature. But then again, linear algebra isn't particularly natural when you see it the first time, I'd say..
But graphical linear algebra gives other powerful insights, such as the meaning of division by zero. btw. we use a very similar calculus
Visual Programming also isn't just for "programming". The tool that Matt Keeter made, called Antimony, is a node -and- graphical interface for making 3d designs. https://www.mattkeeter.com/projects/antimony/3/
One really cool effect this tool has, is that it shows you the direct dependencies on geometries and how shapes interact with each other.
So far, it brings me to 3 tools I use on a weekly basis that are node and flow based: Node-Red, Apache NiFi, and Antimony CAD.
Visualizing how the process you want to express in software works is a great technique for clarifying what you want to accomplish, but I'm skeptical that it is a good way to actual do programming. The simple reason why is that error conditions and corner cases are hard to express visually. That said, I think drawing out what you're trying to accomplish is helpful. It's basically a form of lightweight specification.
it is in fact very helpful to model out your error states, esp. if you can see it on a screen in some sort of flow. this is why people do modelling, to understand better what you want to code.
But you are right, there are many things that are difficult to express graphically (at the moment) but I think this can be solved in the near future
If "Visual Programming" is the possibility of generating code from a "Diagrammatic Reasoning" design, then I (and I suppose everyone here) do it all the time. Like drawing sketches, boxes and arrows in paper before/during programming.
But... I doubt there would be a system able to pick any kind of design and generate code/programs.
Stay tuned! It is not any kind of design but specific diagrams and for a certain large class of programs we can do it. It might take a while before we've implemented all the needed runtimes, but JS should be release sometime this year
It does suck. It totally does. Because when you sell VP, you sell VOP (visual-only programming).
If you offer a visual interface as an add-on to my favorite programming language, be my guest. I don't have a problem with that and I might even try it on a nice sunny weekend afternoon.
Just don't try to lock me in on a VOP platform and expect me to sing praises for it.
the diagrams are just different ways to draw expressions, you are actually editing text, it's really the same data. one diagram implies many different but behaviourally equivalent expressions, so the diagram is actually the more efficient way to encode the thing
this is ignoring all the UX issues of course. but we are quite confident eventually everyone will use such diagrams as at least sidekicks in their text-based-code
Sometimes I wonder if a hybrid approach could work. Specifically, a language that generally looks like Python or JavaScript, but also allows emoji as variable or function names. You could keep the advantages of text-based languages, since you can still search and diff, but also lets you use higher-level visual abstractions that images provide. I've started experimenting with something like this, but it's still not ready for real-world use: https://github.com/hugs/wildcard/blob/master/example/konami....
I’m a bit late to the discussion, but having adopted Node-RED for home automation and some bot prototyping work, I concur that it’s very quick to get some stuff done, but that modularity and versioning are a constant pain.
I don’t see visual programming at sucking, but I think the idea of having diagrams as a quick panacea for the mental overhead of maintaining complex processes just doesn’t scale (I’ve had a number of discussions about this kind of thing since the rise of UML, for instance, and never saw UML docs being maintained after their creator left a project...)
One place where visual programming works really well is in Blender, specifically the shader editor comes to mind. Connecting and adjusting shader parameters could be done in code, but the UI works very well.
Just look at Unreal Engine's blueprints. You can code an entire game in visual programming without writing a single line of C++. And it will perform really well as it gets compiled down in production.
FWIW, I found that we can develop a "business process" with a client and get very valuable feedback from the domain expert, who might know very little about computers. I don't really see myself live coding with a non technical client
Frameworks don't suck if they meet your requirements either, however, you often don't find out a killer requirement until your up to your neck in framework!
I think the Petri net is a great example, but I disagree with the conclusion that we should express something like a Petri net primarily as a diagram. The ideal model is still textual, but as a DSL that compiles both to something like DOT format and to a programming language of your choice. This gives you all the many benefits of textual formats, along with the visual economy of a diagram.
I think the conclusion is because one diagrams has many different syntactical expressions, but the theory tells us they all behave the same, so we can just pick the most efficient, most compact, whatever. ie. the diagram is the best representation, not the syntax.
so we can go: diagram -> expression -> code of your choice
from expression we can go back to diagram, but code to expression not necessarily.
the problem now is that if the picture is the leading representation, then we need to lift all the tools to the diagram realm, so comments, higher order diagrams, grouping, closures, variables, etc
I think that this type of tool can produce a much readable program without a large change to how writeable the program was. Tools like state diagrams can be similar - by using an automata of some type you generate an artifact that can make your logic very easily explained to a nonprogrammer, but the restrictions of the format aren't easily understood.
I like Nifi, but would be a lot easier for me to write code to achieve the same results from many of my experiances. Also ended up with the typical, how do get something that this doesn't have a plugin for to work ... ohh I need to go understand their plugin architecture and etc invest in a load of stuff which quite frankly isn't really of interest to me.
Its well worth using though because at the other end I've seen all sort of hand cranked code and maintenance for something that I know Nifi could achieve (however I only know that from using Nifi and learning where it doesn't fit).
Its the above pain which makes many people reticent to try out such tools.
{kind=link}
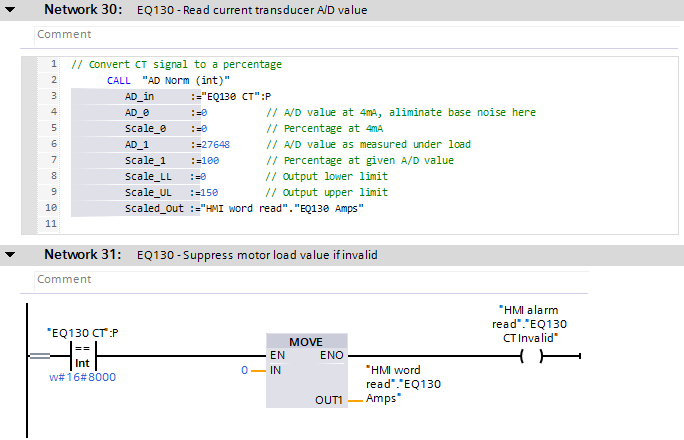{kind=link}
{kind=link}
{kind=link}
- Visual computing is pretty heavily used, unreal engine, blender, houdini, etc. All have a very similar node based visual programming system. It seems to work pretty well (better than text) for most of what they use it for. I think because of the ease of jumping in the middle and making small understandable changes.
- Many programming languages today have a format that is like <tree of files, each containing> <set of items, each containing> <list of expressions>. It would be nice if that <set of items> step was treated as an unordered set instead of an ordered one, with editors having a better understanding of how to bring up relevant elements of the set onto your screen at the same time. Split pane editors, "peeking" in editors at code definitions, etc. hint at how this should work, but I don't feel like they do it as well as possible.
- A small amount of "visual augmentation" might benefit most programming languages, I'm not sure I can explain this better than linking to a few images of what emacs auctex package does to latex http://lh6.ggpht.com/_egN-3IJO0Xg/SpIj6AtHOTI/AAAAAAAABj8/O1... https://upload.wikimedia.org/wikipedia/commons/4/42/Emacs%2B...